LangStudio アプリケーションフローでナレッジベースノードを使用するには、まずナレッジベースを作成する必要があります。ナレッジベースの作成は一度だけで、複数のアプリケーションフローで再利用できます。ナレッジベースは、検索拡張生成 (RAG) アーキテクチャにおいて、外部のプライベートデータソースとして機能します。Object Storage Service (OSS) からソースドキュメントを読み取り、データを前処理してチャンク化し、チャンクをベクトルに変換します。生成されたインデックスは、ベクトルデータベースに格納されます。このトピックでは、ナレッジベースの作成、設定、および使用方法について説明します。
仕組み
LangStudio のナレッジベースの主な機能は、OSS データソースのファイルを大規模言語モデルが取得できる形式に変換することです。このワークフローは、3 つのコアステップで構成されます。
データの読み取りとチャンク化:指定した OSS パスからソースファイルを読み取ります。
非構造化ドキュメント:解析され、より小さく意味的に完全なテキストチャンクに分割されます。
構造化データ:行ごとにチャンク化されます。
イメージ:チャンク化されず、全体として処理されます。
ベクトル化 (埋め込み):埋め込みモデルを呼び出し、各データチャンクまたはイメージを、その意味内容を表す数値ベクトルに変換します。
ストレージとインデックス作成: システムは生成されたベクトルデータをベクトルデータベースに保存し、効率的な取得のためのインデックスを作成します。
クイックスタート:ナレッジベースの作成と使用
このセクションでは、ドキュメントタイプのナレッジベースを作成し、ワークフローで使用するためのクイックガイドを提供します。
ナレッジベースの作成。 LangStudio に移動し、ワークスペースを選択します。 Knowledge Base タブで、Create Knowledge Base をクリックします。 次の主要なパラメーターを設定し、他のパラメーターはデフォルト値のままにして、[OK] をクリックします。
パラメーター
説明
Basic Configuration
Name
ナレッジベースのカスタム名を入力します。例:
test_kg。Data Source OSS Path
ナレッジベースのソースファイルが格納されている場所。例:
oss://examplebucket.oss-cn-hangzhou-internal.aliyuncs.com/test/original/。Output OSS Path
ドキュメント解析から生成された中間結果とインデックス情報を格納します。最終的な出力は、選択したベクトルデータベースのタイプによって異なります。例:
oss://examplebucket.oss-cn-hangzhou-internal.aliyuncs.com/test/output/。重要ランタイムに設定されている [インスタンス RAM ロール] が PAI デフォルトロールである場合、このパラメーターを 現在のワークスペースのデフォルトストレージパス の OSS バケット内のディレクトリに設定することをお勧めします。
Type
[ドキュメント] を選択します。
Embedding Model and Database
Embedding Type
Alibaba Cloud Model Studio Service を選択し (事前に接続を作成しておく必要があります。接続設定をご参照ください)、次に作成した接続とモデルを選択します。
Vector Database Type
クイックテストには [FAISS] を選択します。
ファイルのアップロード。
Knowledge Base タブで、作成したナレッジベースをクリックします。Overview ページで、[ドキュメント] タブに切り替えます。このタブには、ナレッジベースのデータソースに指定された OSS パスからのドキュメントが表示されます。
ページで Upload ボタンをクリックするか、データソースの OSS パスにファイルを直接アップロードすることで、ファイルを追加または更新できます。 たとえば、ページから rag_test_doc.txt をアップロードできます。 サポートされているファイル形式の詳細については、「ナレッジベースのタイプ」をご参照ください。
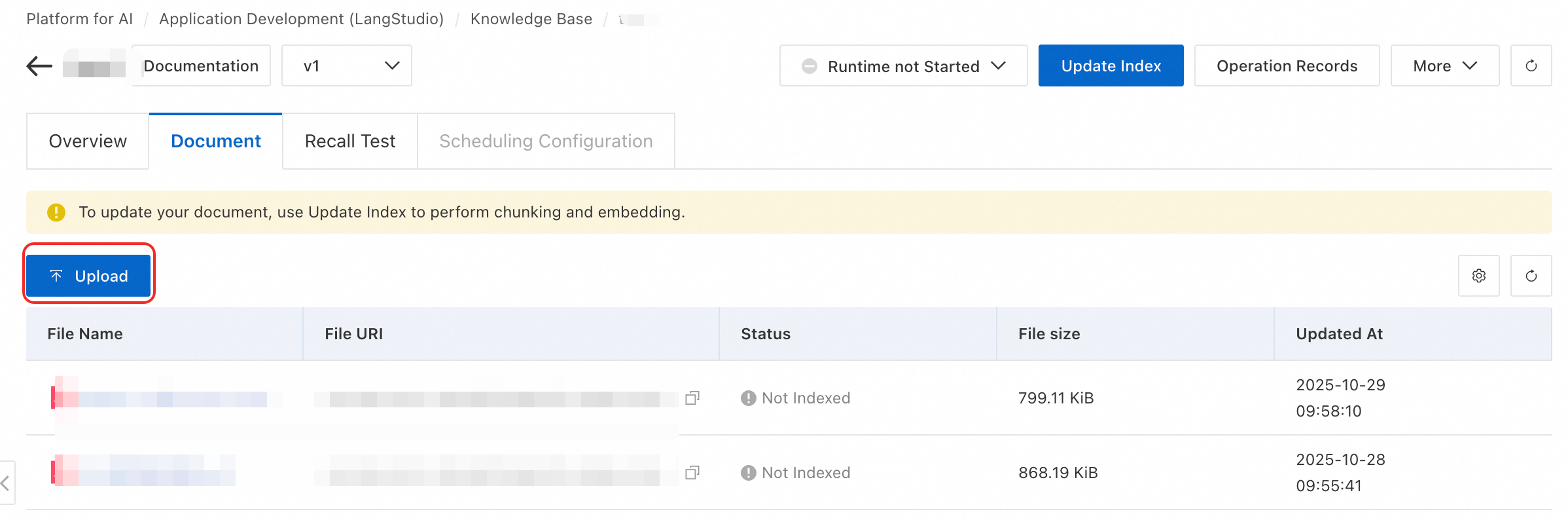
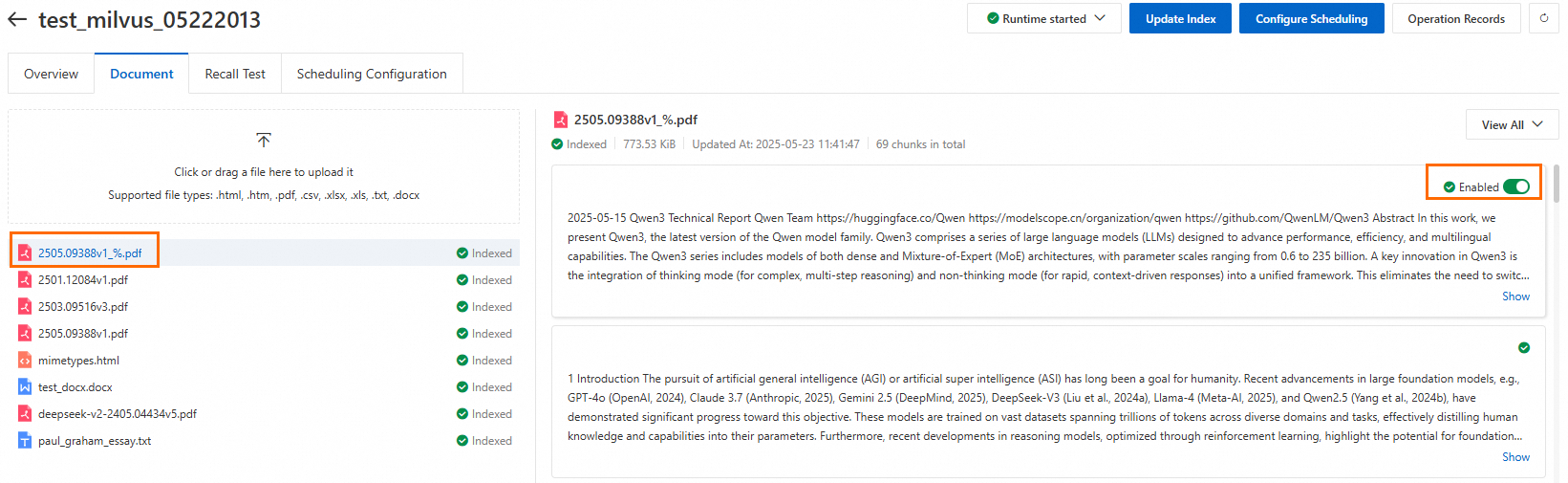
インデックスの更新。ファイルをアップロードした後、右上隅にある Update Index をクリックし、表示されるページで計算リソースとネットワークを設定します。インデックス更新タスクが完了すると、ファイルステータスが「インデックス済み」に変わります。その後、ファイルをクリックしてドキュメントチャンクをプレビューできます。イメージナレッジベースの場合、代わりにイメージのリストが返されます。
説明すでに Milvus に保存されているドキュメントチャンクについては、個別にステータスを有効または無効に設定できます。無効化されたチャンクは取得されません。
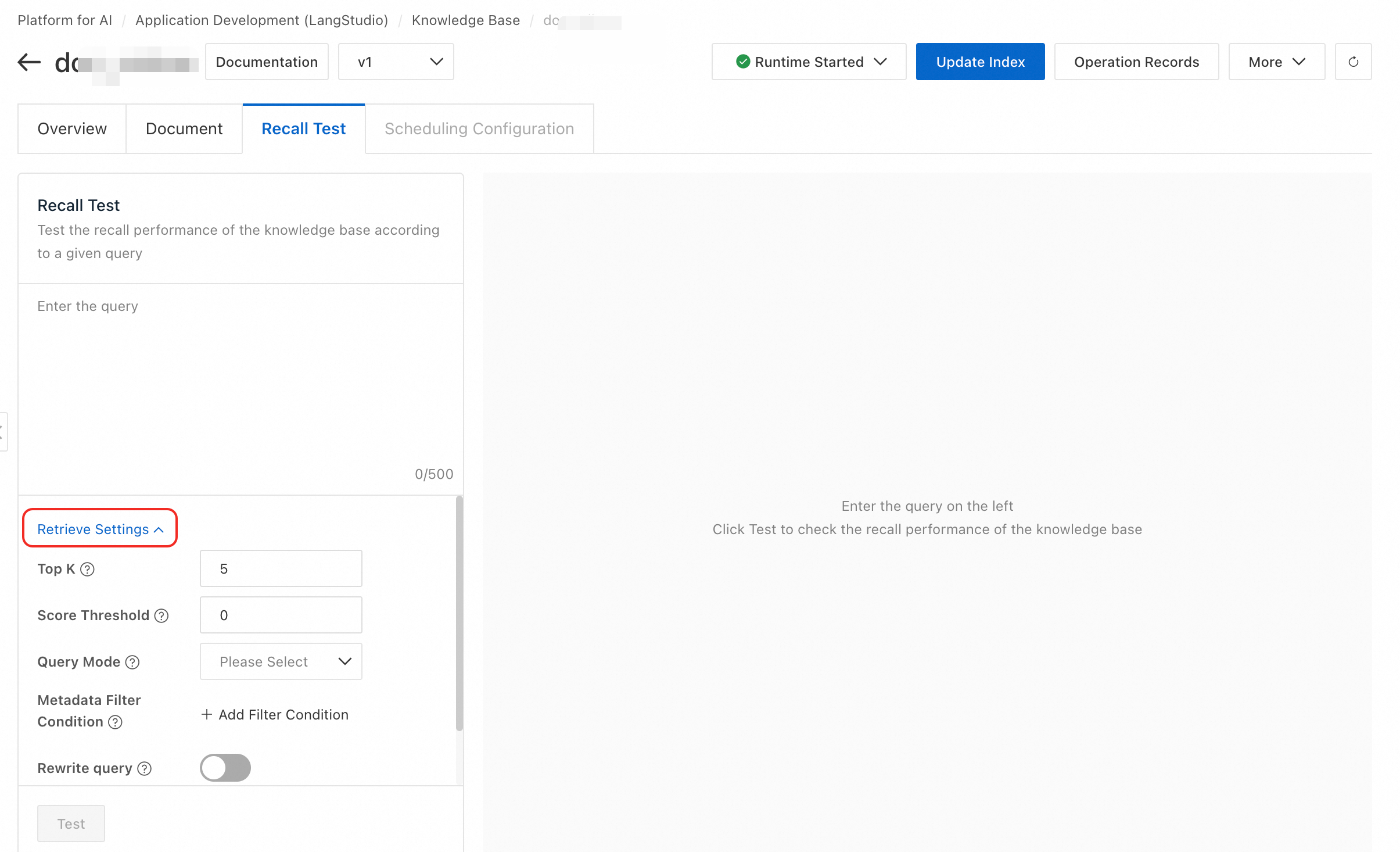
取得テスト。 インデックスが更新されたら、Recall Test タブに切り替え、質問を入力し、取得パラメーターを調整してパフォーマンスをテストします。
アプリケーションフローでナレッジベースを使用する。テストが完了したら、アプリケーションフローでナレッジベースから情報を取得できます。ナレッジベースノードでは、クエリ書き換えと結果のリランキング機能を有効にし、ノードの実行詳細で書き換えられたクエリを表示できます。

結果は List[Dict] で、各辞書にはドキュメントチャンクの
contentと入力クエリとの類似度scoreが含まれます。[ { "score": 0.8057173490524292, "content": "パンデミックによる不確実性のため、XX銀行は中国または中国本土の経済動向と予測に基づき、貸付金、前渡金、および非信用資産の減損損失引当金を積極的に増加させました。また、引当金カバー率を向上させるために、不良資産の償却と処分を増加させました。2020年には、純利益は289億2800万人民元に達し、前年比2.6%増となり、収益性は徐々に改善しました。\n(百万元) 2020 2019 変化率 (%)\n経営成績と収益性\n営業収益 153,542 137,958 11.3\n減損損失前営業利益 107,327 95,816 12.0\n純利益 28,928 28,195 2.6\n経費率(1)(%) 29.11 29.61 0.50 パーセントポイント低下\n総資産利益率 (%) 0.69 0.77 0.08 パーセントポイント低下\n加重平均自己資本利益率 (%) 9.58 11.30 1.72 パーセントポイント低下\n純金利マージン(2)(%) 2.53 2.62 0.09 パーセントポイント低下\n注: (1) 経費率 = 営業経費および管理費 / 営業収益。", "id": "49f04c4cb1d48cbad130647bd0d75f***1cf07c4aeb7a5d9a1f3bda950a6b86e", "metadata": { "page_label": "40", "file_name": "2021-02-04_XX_Insurance_Group_Co_Ltd_XX_China_XX_2020_Annual_Report.pdf", "file_path": "oss://my-bucket-name/datasets/chatglm-fintech/2021-02-04__XX_Insurance_Group_Co_Ltd__601318__China_XX__2020_Annual_Report.pdf", "file_type": "application/pdf", "file_size": 7982999, "creation_date": "2024-10-10", "last_modified_date": "2024-10-10" } }, { "score": 0.7708036303520203, "content": "72億人民元、前年比5.2%増。\n2020\n(百万元) 生命保険・健康保険事業、損害保険事業、銀行事業、信託事業、証券事業、その他資産管理事業、テクノロジー事業、その他事業および連結消去、グループ連結\n親会社の株主に帰属する純利益 95,018 16,083 16,766 2,476 2,959 5,737 7,936 (3,876) 143,099\n少数株主持分 1,054 76 12,162 3 143 974 1,567 281 16,260\n純利益 (A) 96,072 16,159 28,928 2,479 3,102 6,711 9,503 (3,595) 159,359\n除外項目:\n 短期投資の変動(1)(B) 10,308 – – – – – – – 10,308\n 割引率変更の影響 (C) (7,902) – – – – – – – (7,902)\n 経営陣が日常の営業収益および支出の一部ではないとして除外した一時的な重要項目およびその他 (D) – – – – – – 1,282 – 1,282\n営業利益 (E=A-B-C-D) 93,666 16,159 28,928 2,479 3,102 6,711 8,221 (3,595) 155,670\n親会社の株主に帰属する営業利益 92,672 16,", "id": "8066c16048bd722d030a85ee8b1***36d5f31624b28f1c0c15943855c5ae5c9f", "metadata": { "page_label": "19", "file_name": "2021-02-04_XX_Insurance_Group_Co_Ltd_XXX_China_XX_2020_Annual_Report.pdf", "file_path": "oss://my-bucket-name/datasets/chatglm-fintech/2021-02-04__XX_Insurance_Group_Co_Ltd__601318__China_XX__2020_Annual_Report.pdf", "file_type": "application/pdf", "file_size": 7982999, "creation_date": "2024-10-10", "last_modified_date": "2024-10-10" } } ]
機能詳細
ナレッジベースのタイプ
ナレッジベースは、ドキュメント、構造化データ、イメージの 3 種類に分類されます。ファイル形式に対応するナレッジベースのタイプを選択してください。
ドキュメント:
.html、.htm、.pdf、.txt、.docx、.md、および.pptxをサポートします。構造化データ:
.jsonl、.csv、.xlsx、および.xlsをサポートします。画像:
.jpg、.jpeg、.png、および.bmpをサポートします。
特別な設定:
ドキュメントタイプのナレッジベースでは、Chunk Configuration で以下のフィールドを設定する必要があります。詳細については、「チャンキングパラメーターのチューニング」をご参照ください。
Chunk Size:各テキストチャンクの最大文字数を指定します。デフォルト値は 1024 です。
Chunk Overlap:隣接するテキストチャンク間で重複する文字数を指定します。これにより、取得された情報の一貫性が確保されます。デフォルト値は 200 文字です。
構造化データのナレッジベースにはField Settingsが必要です。animal.csv などのファイルをアップロードするか、手動でフィールドを追加し、インデックス作成用と取得用に個別に指定することができます。
ベクトルデータベースの選択
本番環境:大規模なベクトルデータの処理をサポートするため、本番環境では Milvus または Elasticsearch の使用を推奨します。
テスト環境: FAISS は個別のデータベースを必要としないため、使用を推奨します (ナレッジベースファイルと生成されたマニフェストは Output OSS Path に保存されます)。機能テストや少量のファイルの処理に適しています。ファイル量が大きいと、取得と処理のパフォーマンスに大きな影響を与えます。
説明イメージナレッジベースは FAISS をサポートしていません。
インデックス更新戦略
更新方法 | 説明 | 注意事項 |
手動更新 | コンソールで手動でUpdate Indexをクリックします。このメソッドは、ファイルが頻繁に変更されないシナリオに適しています。 | 各更新では、データソース内のファイルに対して完全または増分処理が実行されます。 |
自動更新 | コンソールで自動更新を有効にすると、システムは EventBridge にイベントルールを自動的に作成し、OSS ファイルの変更メッセージを転送してインデックスタスクを自動的に作成します。 | 重要 自動更新サービス中にメッセージ料金が発生します。
|
定期更新 | DataWorks の定期タスクを設定して、毎日など指定した頻度でインデックスを更新します。 | この機能は DataWorks サービスに依存します。DataWorks の定期タスクは通常、翌日 (T+1) に有効になります。つまり、今日行われた設定は明日初めて実行されます。 |
設定方法は以下の通りです:
手動更新
ファイルをアップロードした後、右上隅のUpdate Indexをクリックします。 その後、PAI フロータスクが送信され、OSS データソース内のファイルが前処理、チャンク化、ベクター化されてインデックスが構築されます。 このタスクのパラメーターは次のとおりです。
パラメーター | 説明 |
計算リソース | ワークフローノードタスクの実行に必要な計算リソース。パブリックリソースを使用するか、リソースクォータを通じてLingjun リソースと一般的なコンピューティングリソースを使用できます。
|
VPC 設定 | 内部ネットワーク経由でベクトルデータベースまたは埋め込みサービスにアクセスする場合、選択した VPC がこれらのサービスの VPC と同じであるか、接続されていることを確認してください。 |
埋め込み設定 |
|
自動更新
EventBridge コンソールに移動して EventBridge をアクティブ化します。
自動インデックス更新を設定するには、ナレッジベースの詳細ページに移動します。Overview タブの右下隅にある Automatic File Indexing エリアで [編集] をクリックします。
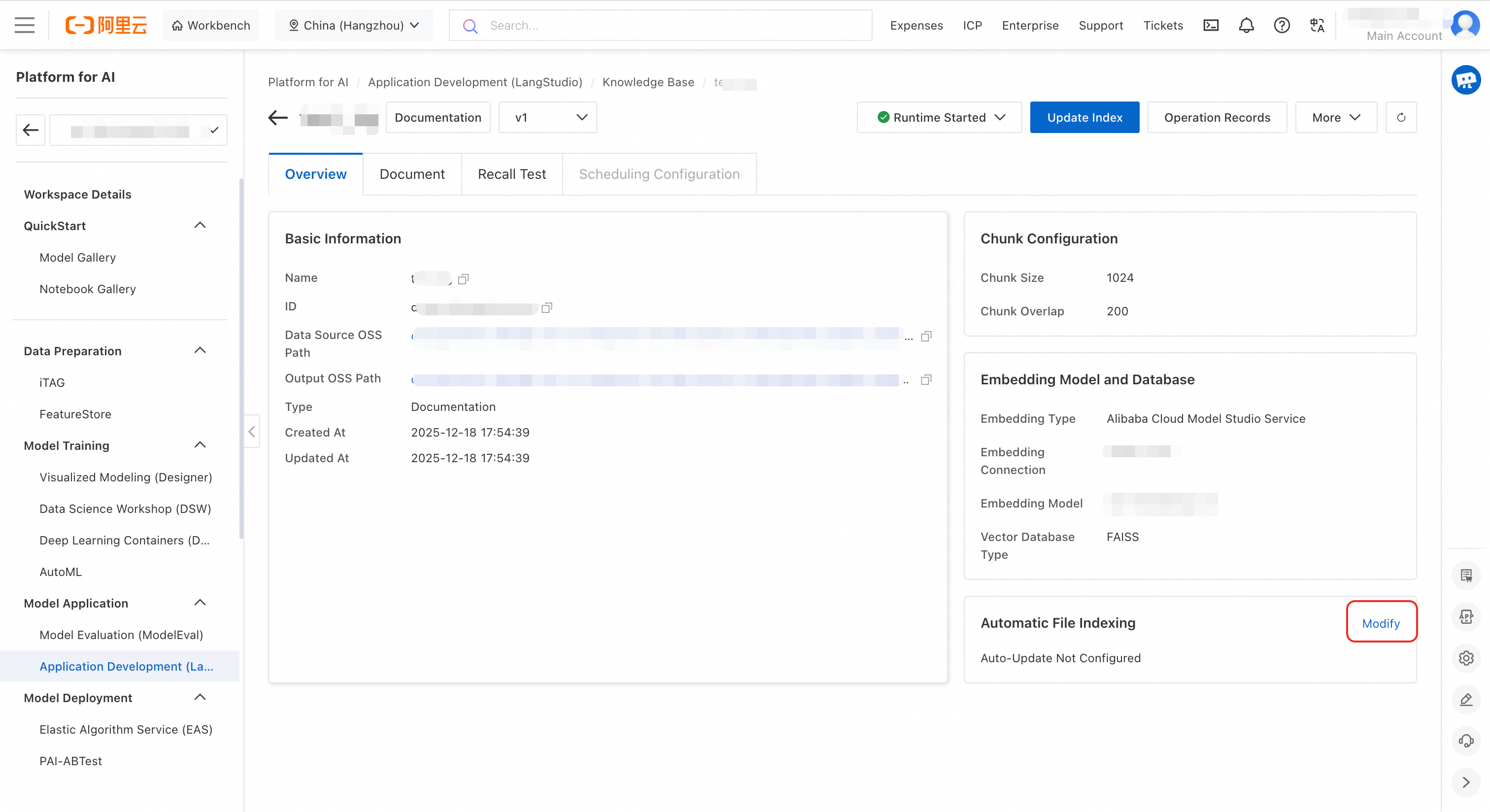
計算リソースと VPC を設定し、[OK] をクリックします。これにより、ファイルの変更が自動的にインデックスタスクをトリガーするため、手動でトリガーする必要はなくなります。
重要ここで設定された計算リソースは、ファイルが更新されるときにのみ使用されます。リソース料金は、ファイルが更新されるときにのみ発生します。
OSS ファイルの変更
ファイルの自動更新を設定した後、ルールが有効になるまで数分かかります。ファイルを変更する前に、少なくとも 3 分待つことを推奨します。
OSS API を使用してファイルを削除する場合、バージョンを指定する必要があります。そうしないと、変更メッセージがトリガーされません。
コンソールでファイルを削除するには、ファイルを選択し、下部にある [完全に削除] をクリックします。
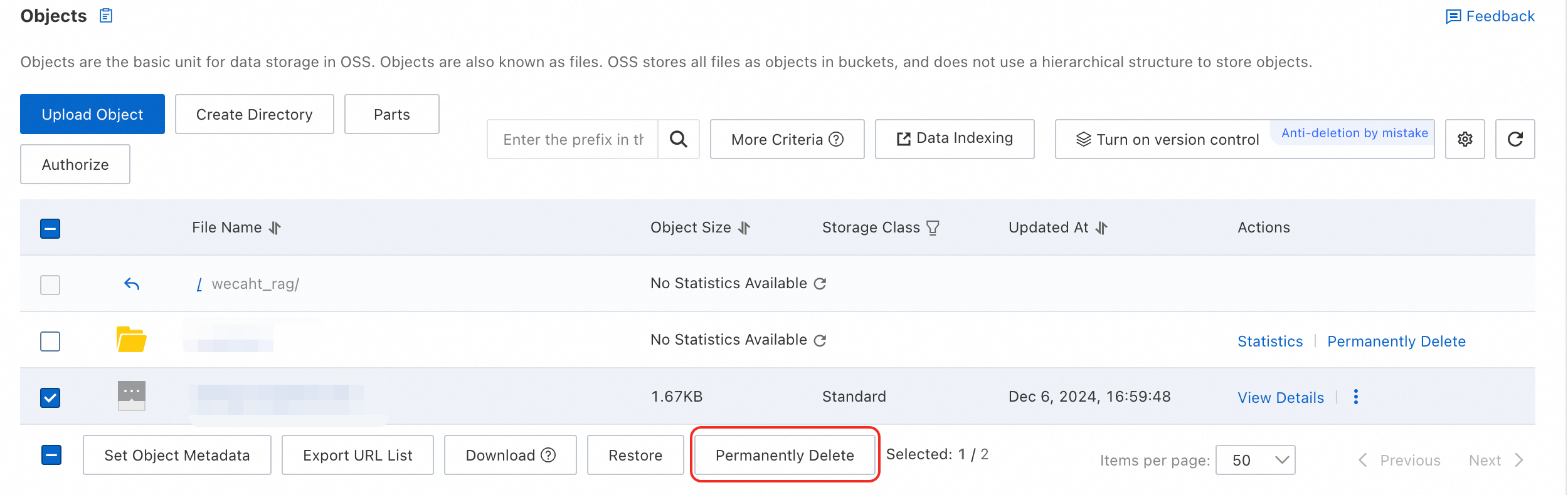
インデックスタスクの表示。ファイルが変更された後、約 3 分待ちます。その後、[操作レコード] リストで自動的にトリガーされたインデックス構築タスクを確認できます。
定期更新
時間指定スケジューリング機能は DataWorks に依存します。サービスをアクティブ化していることを確認してください。サービスがアクティブ化されていない場合は、「DataWorks サービスのアクティブ化」をご参照ください。
ナレッジベースの詳細ページで、右上隅の をクリックします。次に、構成を完了し、[送信] をクリックします。
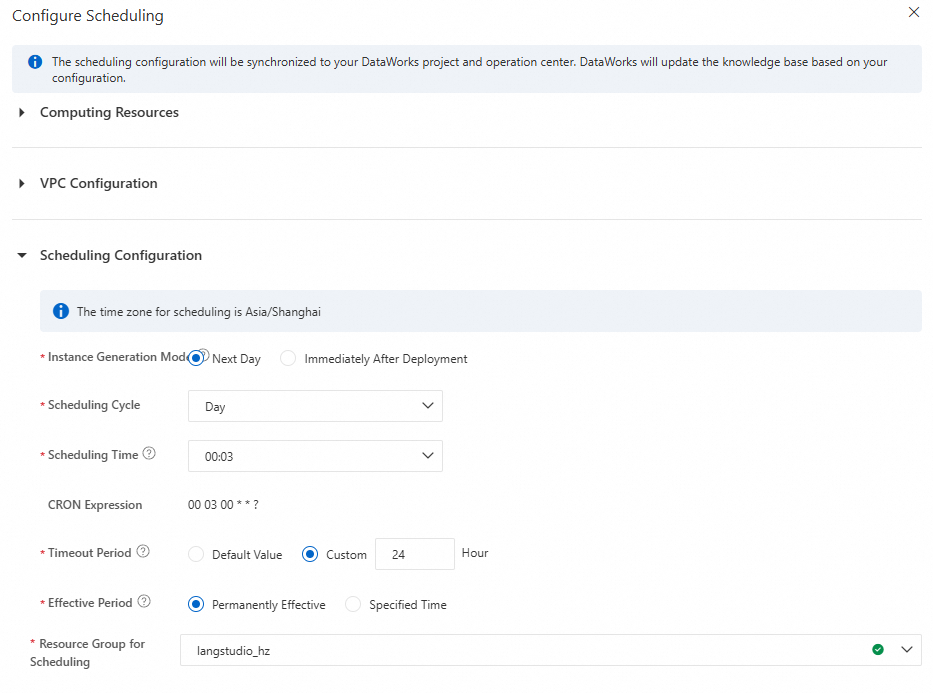
スケジューリング設定と定期タスクの表示
フォームを送信すると、システムは DataWorks のデータ開発センターにスケジュールされたワークフローを自動的に作成し、DataWorks のオペレーションセンターで定期タスクとして公開します。この定期タスクは翌日 (T+1) に有効になり、設定した時間にナレッジベースを更新します。ナレッジベースのスケジューリング設定ページで、スケジューリング設定と定期タスクを表示できます。
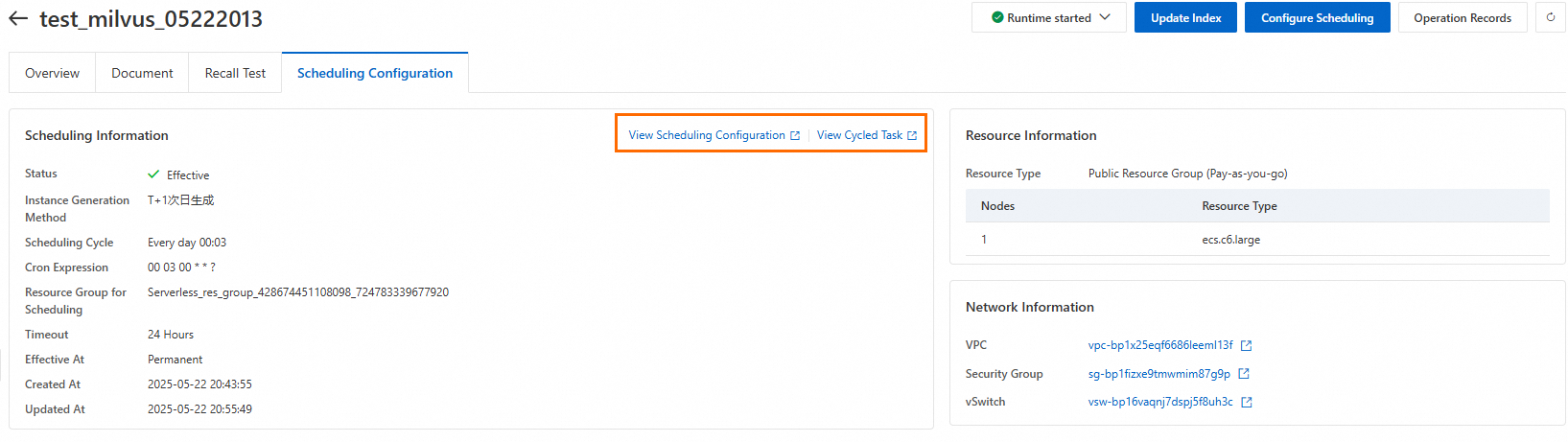
時間指定スケジューリングのパラメーター説明
スケジューリングサイクル: 本番環境でノードが実行される頻度を定義します。この設定により、定期インスタンスの数とその実行時間が決まります。
スケジュール時刻:ノードが実行される特定の時刻を定義します。
タイムアウト定義:ノードがタイムアウトして失敗するまでの最大実行時間を定義します。
有効日: ノードが自動的に実行されるようにスケジュールされる時間範囲を定義します。この範囲外では、ノードは自動的にスケジュールされません。
スケジューリングリソースグループ: DataWorks の時間指定スケジューリング機能用のリソースグループです。リソースグループがない場合は、ドロップダウンリストの [今すぐ作成] をクリックして作成します。リソースグループを作成したら、現在のワークスペースにアタッチします。

スケジューリングパラメーターの詳細については、「時間プロパティ設定の説明」をご参照ください。
データセットの表示
インデックス更新タスクが正常に完了すると、システムは自動的にOutput OSS Pathをデータセットとして登録します。データセットはAI アセット管理 - データセットで表示できます。このデータセットはナレッジベースと同じ名前で、インデックス構築プロセスからの出力が含まれています。
ランタイムの設定
ドキュメントチャンクのプレビューや取得のテストなどの操作を実行するには、ランタイムを選択する必要があります。これらの操作には、ベクトルデータベースと埋め込みサービスへのアクセスが必要です。
次のランタイム設定に注意してください:
内部ネットワークエンドポイント経由でベクトルデータベースまたは埋め込みサービスにアクセスする場合、ランタイムの VPC がデータベースとサービスの VPC と同じであるか、接続されていることを確認してください。
インスタンス RAM ロールにカスタムロールを選択する場合、そのロールに OSS アクセス権限を付与する必要があります。AliyunOSSFullAccess 権限を付与することを推奨します。詳細については、「RAM ロールへの権限付与」をご参照ください。
ランタイムバージョンが 2.1.4 より前の場合、ドロップダウンリストに表示されないことがあります。この問題を解決するには、新しいランタイムを作成してください。
マルチバージョン管理
バージョンクローン機能を使用すると、v1 などのテスト済みのナレッジベースを新しい公式バージョンとして公開できます。これにより、開発環境と本番環境が分離されます。
バージョンのクローン作成に成功すると、ナレッジベースの詳細ページで異なるバージョンを切り替えて管理できます。また、アプリケーションフローのナレッジベース取得ノードで目的のバージョンを選択することもできます。

バージョンのクローンはインデックスの更新に似ています。この操作はワークフロータスクを送信します。操作レコードリストでタスクを表示できます。
取得パラメーターの設定
Top K: ナレッジベースから取得する関連テキストチャンクの最大数。値の範囲は 1 から 100 です。
スコアしきい値: 0 から 1 の範囲の類似性スコアのしきい値。このしきい値を超えるスコアを持つチャンクのみが返されます。値が高いほど、テキストとクエリ間の類似性要件が厳しくなります。
取得パターン:デフォルトのパターンは Dense (ベクトル検索) です。ハイブリッド検索 (ベクトルとキーワード) を使用したい場合、ベクトルデータベースは Milvus 2.4.x 以降、または Elasticsearch である必要があります。取得パターンの選択方法の詳細については、「取得モードの選択」をご参照ください。
メタデータフィルター条件:メタデータを使用して取得範囲をフィルタリングし、精度を向上させます。詳細については、「メタデータの使用」をご参照ください。
クエリ書き換え:大規模言語モデルを使用して、曖昧、口語的、または文脈に依存するユーザークエリを最適化します。このプロセスは、クエリをより明確で完全なものにすることでユーザーの意図を明確にし、取得精度を向上させます。使用シナリオの詳細については、「クエリ書き換え」をご参照ください。
結果のリランキング:リランキングモデルを使用して初期の取得結果を再順位付けし、最も関連性の高い結果を先頭に移動させます。使用シナリオの詳細については、「結果のリランキング」をご参照ください。
説明結果のリランキングにはリランキングモデルが必要です。サポートされているモデルサービス接続タイプには、Model Studio 大規模言語モデルサービス、AI Search Open Platform モデルサービス、および一般的なリランカーモデルサービスが含まれます。
トラブルシューティング
インデックス更新またはバージョンクローンタスクが失敗した場合は、次の手順でトラブルシューティングを行ってください:
操作履歴の表示: ナレッジベースの詳細ページで、Operation Records で失敗したタスクを見つけ、[タスクの表示] をクリックします。
タスクログの確認:システムは PAI ワークフローページにリダイレクトします。失敗したノードのログを確認してください。
 たとえば、ドキュメントナレッジベースのインデックスを更新するためのワークフロータスクには、次の 3 つのノードが含まれます。read-oss-file ノードを除き、各ノードは PAI-DLC タスクを作成します。ログの Job URL を使用して DLC タスクの詳細を表示することもできます。
たとえば、ドキュメントナレッジベースのインデックスを更新するためのワークフロータスクには、次の 3 つのノードが含まれます。read-oss-file ノードを除き、各ノードは PAI-DLC タスクを作成します。ログの Job URL を使用して DLC タスクの詳細を表示することもできます。read-oss-file: OSS ファイルを読み取ります。
rag-parse-chunk: ドキュメントの前処理とチャンク化を処理します。
rag-sync-index: テキストチャンクの埋め込みとベクトルデータベースへの同期を処理します。
取得の最適化
チャンクパラメーターの調整: 取得の基盤を構築
指導原則
モデルのコンテキスト制限: チャンクサイズが埋め込みモデルのトークン制限を超えないようにして、情報の切り捨てを回避します。
情報の完全性:チャンクは完全なセマンティクスを含むのに十分な大きさであるべきですが、情報が多すぎて類似度計算の精度が低下するのを避けるために、十分に小さい必要があります。テキストが段落ごとに構成されている場合は、チャンク化を段落に合わせて設定し、恣意的な分割を避けることができます。
連続性の維持:チャンクサイズの 10% から 20% 程度の適切なオーバーラップサイズを設定し、チャンク境界で重要な情報が分割されることによるコンテキストの損失を効果的に防ぎます。
反復的な干渉の回避: 過度の重複は重複した情報を導入し、取得効率を低下させる可能性があります。情報の完全性と冗長性の間でバランスを見つける必要があります。
デバッグの提案
反復的な最適化:チャンクサイズ 300、オーバーラップ 50 などの初期値から始め、実際の取得と質疑応答 (Q&A) の結果に基づいてこれらの値を継続的に調整・実験し、データに最適な設定を見つけます。
自然言語の境界: テキストに章や段落などの明確な構造がある場合は、これらの自然言語の境界に基づいて分割を優先し、セマンティックな完全性を最大化します。
クイック最適化ガイド
問題 | 最適化の提案 |
無関係な取得結果 | チャンクサイズを大きくし、チャンクの重複を減らします。 |
結果のコンテキストが不整合 | チャンクの重複を増やします。 |
適切な一致が見つからない (低い取得率) | チャンクサイズをわずかに増やします。 |
高い計算またはストレージのオーバーヘッド | チャンクサイズを小さくし、チャンクの重複を減らします。 |
次の表に、さまざまな種類のテキストに推奨されるチャンクサイズと重複サイズを示します。
テキストタイプ | 推奨チャンクサイズ | 推奨チャンク重複 |
短いテキスト (FAQ、要約) | 100~300 | 20~50 |
通常のテキスト (ニュース、ブログ) | 300~600 | 50~100 |
技術文書 (API、論文) | 600 から 1024 | 100~200 |
長い文書 (法律、書籍) | 1024 から 2048 | 200~400 |
取得モードの選択: セマンティクスとキーワードのバランス
取得モードは、システムがクエリをナレッジベースのコンテンツとどのように照合するかを決定します。異なるモードにはそれぞれ長所と短所があり、さまざまなシナリオに適しています。
Dense (ベクトル) 取得: セマンティクスの理解に優れています。クエリとドキュメントの両方をベクトルに変換し、これらのベクトル間の類似性を計算することでセマンティックな関連性を判断します。
Sparse (キーワード) 取得: 完全一致に優れています。BM25 などの従来の用語頻度モデルに基づいており、ドキュメント内のキーワードの頻度と位置に基づいて関連性を計算します。
ハイブリッド取得: 両方を組み合わせます。ベクトル取得とキーワード取得の結果をマージし、Reciprocal Rank Fusion (RRF) や線形重み付けやモデルアンサンブルなどの重み付け融合などのアルゴリズムを使用して再ランキングします。
取得モード | 長所と短所 | シナリオ |
Dense (ベクトル) 取得 |
|
|
Sparse (キーワード) 取得 |
|
|
ハイブリッド取得 |
|
|
メタデータの使用: 取得のフィルタリング
メタデータフィルタリングの価値
正確な取得、ノイズの低減:メタデータは、取得中にフィルター条件またはソートに使用できます。これにより、無関係なドキュメントを除外し、生成モデルが無関係なコンテンツを受け取るのを防ぎます。たとえば、ユーザーが「劉慈欣が書いた SF 小説を探す」と尋ねた場合、システムはメタデータ条件
author=劉慈欣とcategory=SFを使用して、最も関連性の高いドキュメントを直接特定できます。ユーザーエクスペリエンスの向上
パーソナライズされた推奨をサポート: メタデータを使用して、「SF」ドキュメントを好むなど、ユーザーの過去のプリファレンスに基づいてパーソナライズされた推奨を提供できます。
結果の解釈可能性の向上: 作成者、ソース、日付などのドキュメントメタデータを結果に含めることで、ユーザーはコンテンツの信頼性と関連性を判断しやすくなります。
多言語またはマルチモーダル拡張をサポート: 「言語」や「メディアタイプ」などのメタデータにより、複数の言語とテキストと画像の混合を含む複雑なナレッジベースを簡単に管理できます。
使用方法
機能の制限:
ランタイムイメージバージョン: 2.1.8 以降である必要があります。
ベクトルデータベース: Milvus と Elasticsearch のみがサポートされています。
ナレッジベースタイプ: ドキュメントまたは構造化データをサポートします。画像はサポートされていません。
メタデータ変数を設定します。 Milvus のみを使用するナレッジベースでは、Overview タブの Metadata セクションで [編集] をクリックして、
authorなどの変数を設定できます。システム予約フィールドは使用しないでください。
ドキュメントのタグ付け。 ドキュメントチャンク詳細ページで、Edit Metadata をクリックして、
author=Alexなどのメタデータ変数と値を追加します。 その後、概要ページに戻ると、メタデータのリファレンスステータスと値の数を表示できます。
フィルターのテスト。 Recall Test タブで、メタデータフィルター条件を追加し、テストを実行できます。
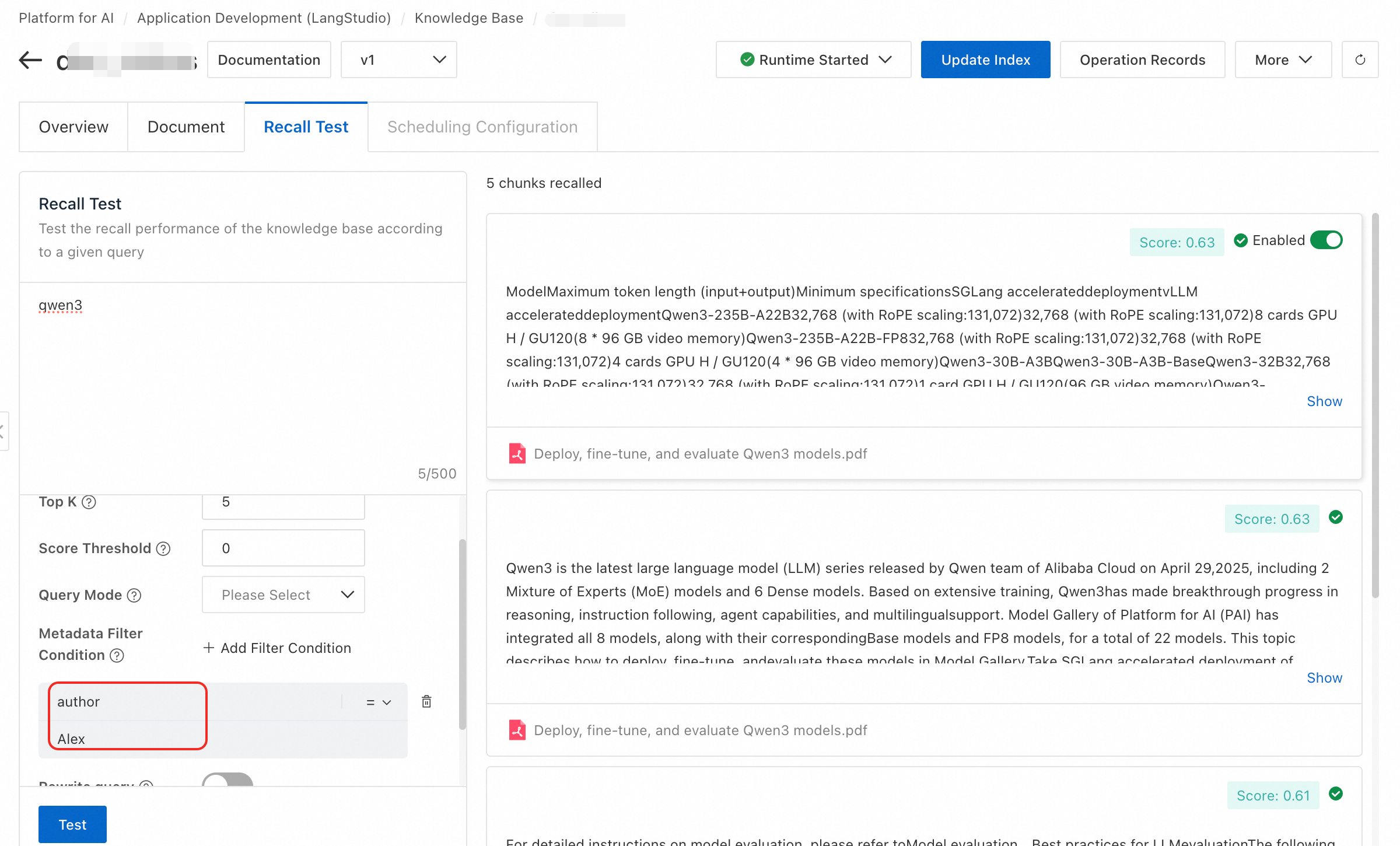
注: 画像で取得されたドキュメントは、ステップ 2 でタグ付けされたドキュメントです。
アプリケーションフローで使用します。ナレッジベースノードでメタデータフィルター条件を設定します。
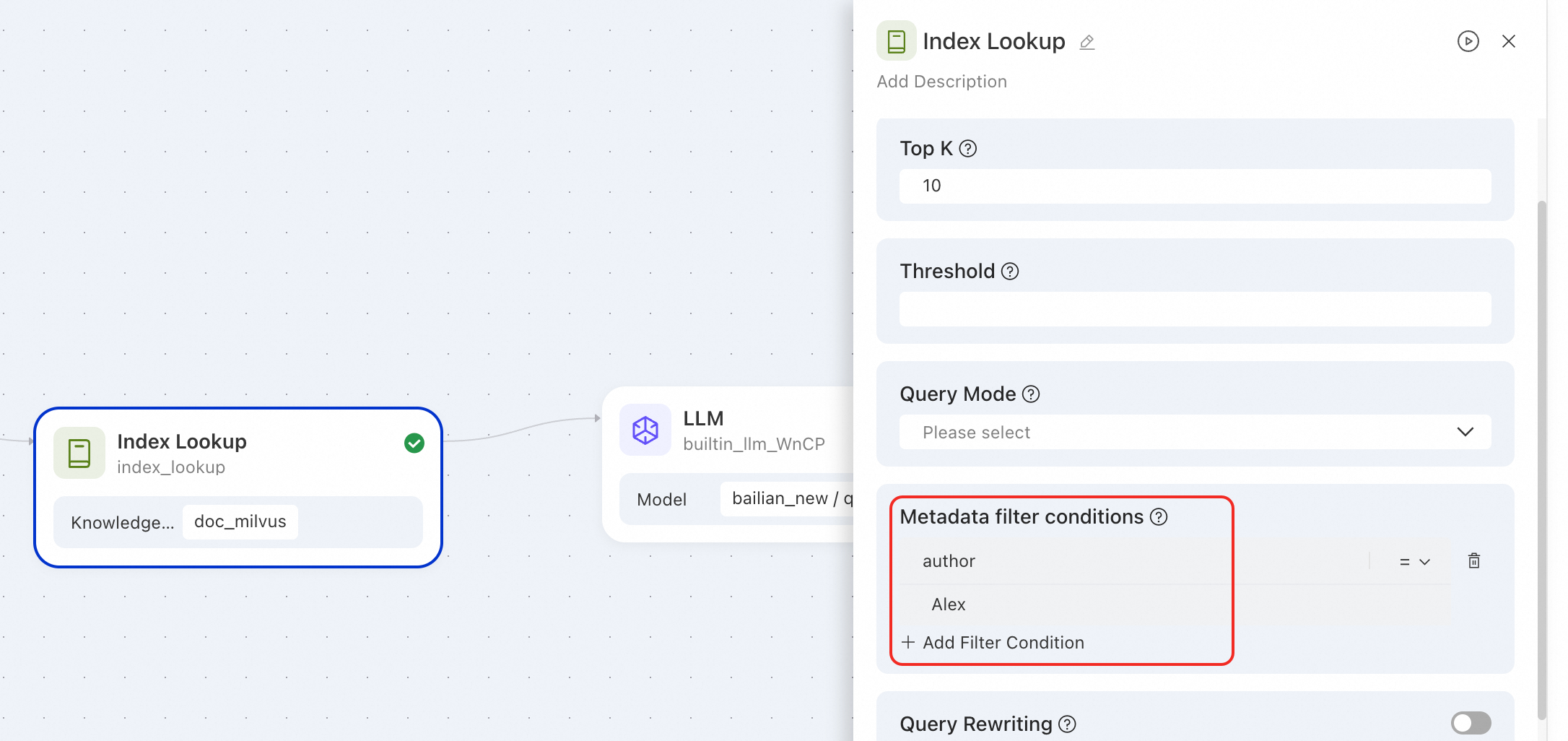
クエリの再書き込みと結果の再ランキング: 取得チェーンの最適化
クエリの再書き込み
大規模言語モデルを使用して、ユーザーの曖昧、口語的、または文脈に依存するクエリを、より明確で、完全で、独立した質問に書き換えます。これにより、後続の取得の精度が向上します。
推奨されるシナリオ:
ユーザーのクエリが曖昧または不完全である場合 (例: コンテキストなしの「彼はいつ生まれましたか?」)。
マルチターン対話で、クエリがコンテキストに依存する場合 (例: 「その後、彼は何をしましたか?」)。
取得機能または LLM が元のクエリを正確に理解するのに十分な能力がない場合。
セマンティック取得ではなく、BM25 などの従来の転置インデックス取得を使用している場合。
推奨されないシナリオ:
ユーザーのクエリがすでに非常に明確で具体的である場合。
LLM が強力で、元のクエリを正確に理解できる場合。
システムが低レイテンシーを必要とし、書き換えによる追加の遅延を許容できない場合。
結果の再ランキング
取得機能によって返された初期結果を再ランキングして、最も関連性の高いドキュメントを最初に表示し、ランキングの品質を向上させます。
推奨されるシナリオ:
BM25 や DPR などの初期取得機能からの結果の品質が不安定な場合。
検索や Q&A システムなど、Top-1 の精度が要求されるシナリオのように、取得結果のランキングが重要な場合。
推奨されないシナリオ:
システムリソースが限られており、追加の推論オーバーヘッドを処理できない場合。
初期取得機能がすでに十分に強力で、再ランキングによる改善が限定的な場合。
リアルタイム検索シナリオなど、応答時間が非常に重要な場合。