DataWorks は、さまざまな種類のコンピュートエンジンのタスクをさまざまな種類のノードにカプセル化し、ノードを作成してデータ開発タスクを生成できるようにします。DataWorks では、リソース、関数、およびさまざまなロジック処理ノードを使用して複雑なタスクを開発することもできます。このトピックでは、データ開発タスクの一般的な開発プロセスについて説明します。
前提条件
必要なデータソースが DataStudio に関連付けられています。詳細については、「データソースの追加またはクラスターのワークスペースへの登録」をご参照ください。
[開発] ロールの権限が付与されています。詳細については、「ワークスペースに RAM ユーザーをメンバーとして追加し、メンバーにロールを割り当てる」をご参照ください。
DataStudio ページに移動する
DataWorks コンソール にログオンします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発に移動] をクリックします。
次に、次のセクションで説明されている手順を実行して、目的のノードを作成できます。
開発プロセス
次の図と表は、データ開発タスクの一般的な開発プロセスを示しています。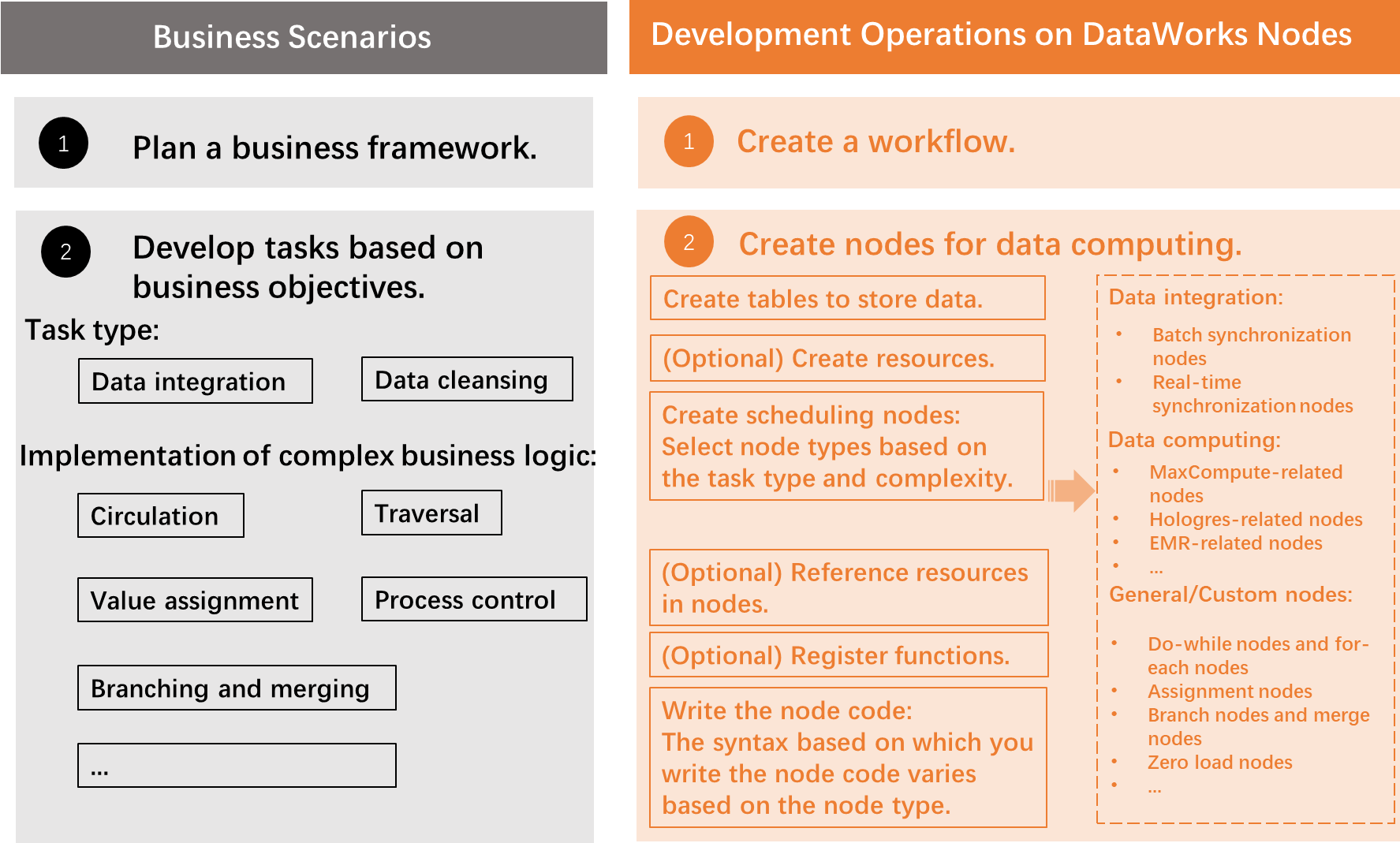
ステップ | 説明 | 参照 |
ステップ 1:ワークフローを作成する | DataWorks でのデータ開発は、ワークフローとコードに基づいて実行されます。開発操作を実行する前に、ワークフローを作成する必要があります。 | 「ワークフローを作成する」をご参照ください。 |
ステップ 2:テーブルを作成する | DataWorks では、DataWorks コンソールでテーブルを作成し、ディレクトリ構造でテーブルを表示できます。 DataWorks コンソールでテーブルを管理できます。 ワークスペースでデータを開発する前に、生データを格納するテーブルと、ワークスペースに関連付けられているコンピュートエンジンでデータクレンジング結果を受け取るテーブルを作成する必要があります。使用するコンピュートエンジンに基づいて、必要なテーブルの種類を決定できます。 | テーブルの作成と使用:
テーブルの表示と管理:
|
ステップ 3:(オプション)リソースを作成してアップロードする | DataWorks では、テキストファイルや JAR パッケージなど、さまざまな種類のリソースを指定されたコンピュートエンジンにアップロードし、データを開発するときにリソースを使用できます。データ開発に既存のリソースを使用する必要がある場合は、DataWorks コンソールで操作を実行してリソースをアップロードし、コンソールでリソースを管理できます。 説明 DataWorks コンソールで、リソースを作成できるコンピュートエンジンと、コンピュートエンジンでサポートされているリソースの種類を表示できます。 |
|
ステップ 4:スケジューリングノードを作成する | DataWorks でのデータ開発はノードに基づいており、さまざまな種類のコンピュートエンジンのタスクは、DataWorks のさまざまな種類のノードにカプセル化されています。ビジネス要件に基づいてノードタイプを選択してノードを開発できます。 ノードで管理操作を簡単に実行することもできます。たとえば、ノードグループを使用して、一度に複数のノードを複製できます。削除されたノードをゴミ箱からすばやく復元できます。 | DataWorks は、次の種類のコンピュートエンジンをサポートしています。 さまざまな種類のコンピュートエンジンのタスクに対して、さまざまな種類のノードを選択できます。さまざまな種類の DataWorks ノードの詳細については、「DataWorks ノード」をご参照ください。 ノードで実行できる管理操作の詳細については、以下のトピックをご参照ください。
|
ステップ 5:(オプション)ノード内のリソースを参照する | DataWorks ノードでリソースを使用するには、まずリソースをノードの開発環境にロードする必要があります。 |
|
ステップ 6:(オプション)関数を登録する | 関数を使用してデータを開発するには、まず DataWorks コンソールに関数を登録する必要があります。関数を登録する前に、関数に必要なリソースを DataWorks にアップロードする必要があります。 説明 DataWorks コンソールで、関数を登録できるコンピュートエンジンを表示できます。 |
|
ステップ 7:ノードコードを記述する | コンピュートエンジンと関連データベースでサポートされている構文に基づいて、ノード構成タブで特定のコンピュートエンジンのタイプのタスクに対応するノードのコードを記述できます。ノードコードを記述する際の構文は、ノードタイプによって異なります。 説明 コードを記述した後、 | さまざまな種類の DataWorks ノードの詳細については、「DataWorks ノード」をご参照ください。 一般的なコンピュートエンジンの使用上の注意: |
後続の手順:コードのデバッグとスケジューリングプロパティの構成
ノードコードが開発された後、ビジネス要件に基づいて次の操作を実行できます。
コードのデバッグ:ビジネス要件に基づいて、単一のノードまたはノードが属するワークフロー全体をデバッグして実行します。デバッグが完了すると、デバッグ結果を表示できます。詳細については、「デバッグ手順」をご参照ください。
スケジューリングパラメーターの構成:ノードのスケジューリングパラメーターを構成します。ノードは、スケジューリングパラメーターの構成に基づいて定期的にスケジュールされます。詳細については、「基本プロパティを構成する」をご参照ください。
ノードのコミットとデプロイ:ノードが開発されたら、スケジューリングと実行のために関連する環境にコミットする必要があります。標準モードのワークスペースを使用する場合、ノードをコミットした後、ノードの構成タブの右上隅にある [デプロイ] をクリックしてノードをデプロイする必要があります。詳細については、「ノードをデプロイする」をご参照ください。
ノードでの O&M 操作の実行:ノードがデプロイされると、デフォルトで本番環境のオペレーションセンターにノードが表示されます。本番環境のオペレーションセンターに移動して、ノードの実行ステータスを表示し、ノードで O&M 操作を実行できます。詳細については、「オペレーションセンター」をご参照ください。