DataStudio は、定期的なタスクを開発し、スケジューリングするための DataWorks のモジュールです。オペレーションセンターと統合されており、MaxCompute、Hologres、E-MapReduce (EMR) などのコンピューティングエンジン向けの視覚的な開発インターフェイスを提供し、インテリジェントなコード開発、マルチエンジンハイブリッドワークフロー、標準化されたタスク発行をサポートします。DataStudio は、オフラインデータウェアハウス、リアルタイムデータウェアハウス、アドホッククエリシステムの構築を支援します。
DataStudio への移動
DataWorks コンソールにログインします。 左側のナビゲーションウィンドウで、 を選択します。 表示されるページで、ドロップダウンリストから目的のワークスペースを選択し、[DataStudioに移動] をクリックします。
DataStudio は、PC の Google Chrome 69 以降でのみサポートされています。
概要
機能
次の表では、DataStudio の主な機能について説明します。主要な用語は、「付録: 概念」で定義されています。

|
タイプ |
説明 |
|
オブジェクトの整理と管理 |
DataStudio は、以下の方法でオブジェクトを整理および管理します。
「ワークフローの作成」および「管理モード」をご参照ください。 説明
DataStudio では、ワークスペース内に作成できるワークフローとオブジェクトの数に以下の制限が適用されます。
現在のワークスペース内のワークフローまたはオブジェクトの数が上限に達した場合、新規に作成することはできません。 |
|
タスク開発 |
利用可能なすべてのノードタイプは、「サポートされているノードタイプ」に記載されています。 |
|
タスクスケジューリング |
「時間プロパティの設定」および「スケジューリング依存関係の設定ガイド」をご参照ください。 |
|
タスクのデバッグ |
DataStudio は、個別のタスクとワークフロー全体のデバッグをサポートしています。詳細については、「タスクのデバッグプロセス」をご参照ください。 |
|
プロセス制御 |
標準化されたタスク発行とプロセス制御を提供します。
|
|
その他の機能 |
|
UI の概要
データ開発インターフェイスと各モジュールの機能の使用方法については、「DataStudio 機能ガイド」をご参照ください。
開発プロセス
DataStudio は、さまざまなコンピューティングエンジンに対して、リアルタイム同期タスク、オフラインスケジュールタスク (同期と処理を含む)、および手動トリガータスクをサポートします。データ同期機能については、「Data Integration」をご参照ください。開始する前に、各コンピューティングエンジンの開発要件を理解し、適切なタスクタイプを選択してください。
-
コンピューティングエンジンの開発ガイド:DataWorks はさまざまなデータソースとコンピューティングエンジンをサポートしています。設定要件はエンジンによって異なります。主要なコンピューティングエンジンのガイドは次のとおりです。
-
一般的な開発プロセス:DataWorks ワークスペースは標準モードと基本モードで実行されます。開発プロセスはモードによって若干異なります。
標準モードのワークスペースにおける開発プロセス。

基本モードのワークスペースにおける開発プロセス。
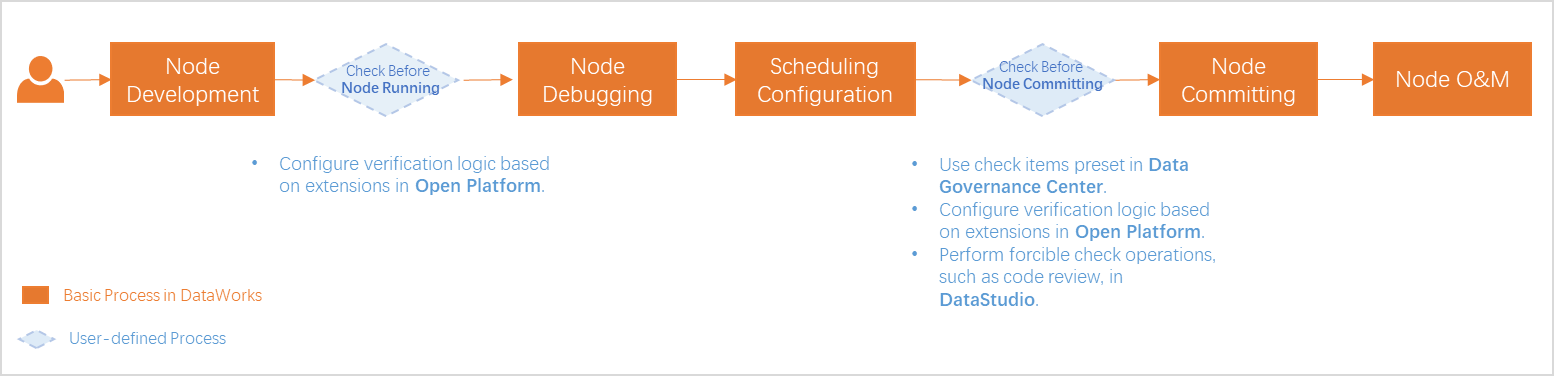
-
基本プロセス:標準モードでは、スケジュールタスクのライフサイクルには、開発、デバッグ、スケジューリング設定、コミット、発行、O&M が含まれます。詳細については、「データ開発プロセスのガイド」をご参照ください。
-
プロセス制御:組み込みのコードレビューとスモークテスト、データガバナンスセンターの事前設定チェック、およびオープンプラットフォーム拡張機能によるカスタム検証を使用して、標準への準拠を徹底します。
説明プロセス制御のオプションはワークスペースのモードによって異なります。コンソールで利用可能な機能が優先されます。
-
整理
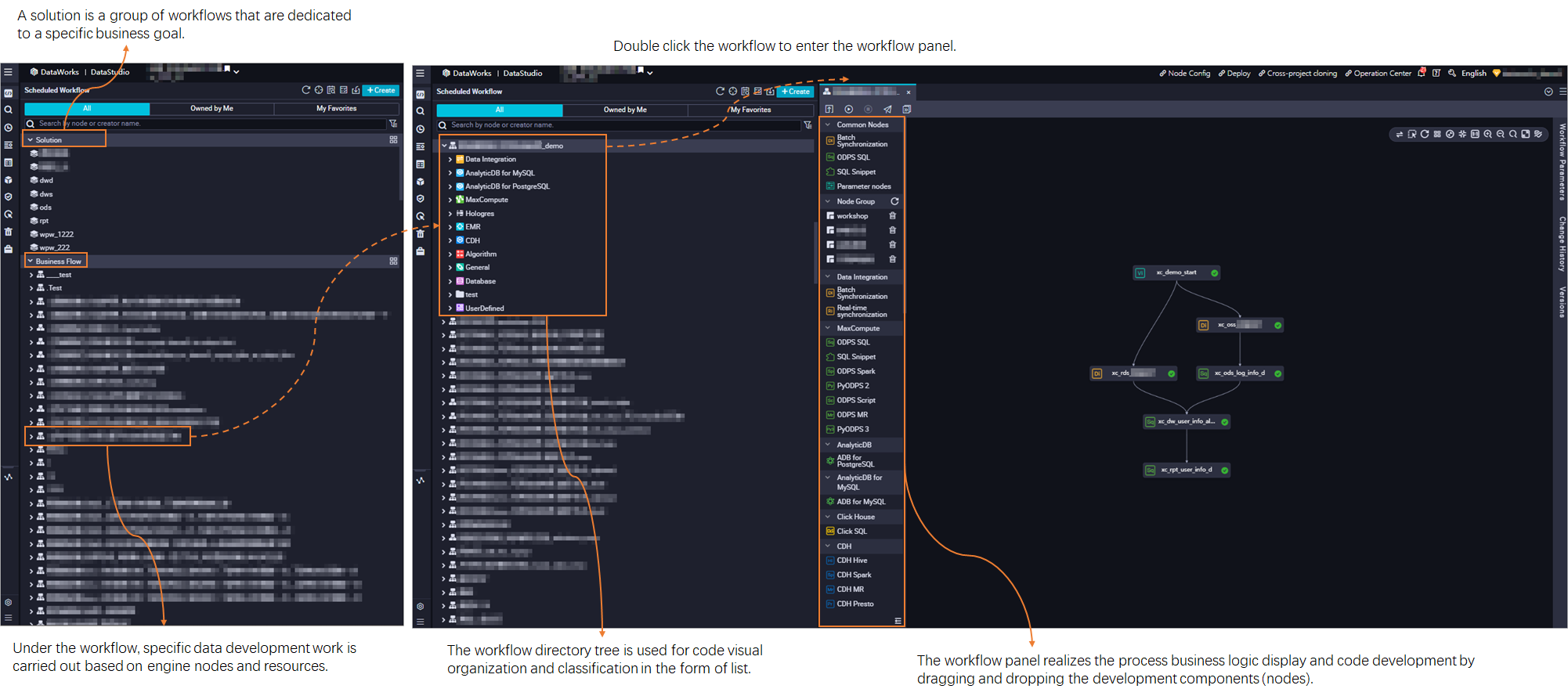
DataStudio では、ワークフローがコード開発とリソースの整理の基本単位です。ワークフローとタスクノードは各ワークスペースで独立して開発され、互いに影響しません。詳細については、「ワークフローの作成」をご参照ください。
ワークフローはディレクトリツリーと操作パネルとして表示され、ビジネスの観点からコードを整理するのに役立ちます。
-
ディレクトリツリー構造:タスクタイプに基づいてコードを整理する方法を提供します。
-
ワークフローパネル:ビジネスロジックをプロセス指向で表示します。
はじめに
前提条件
DataWorks でタスクの開発、データのモデリング、または定期的なタスクのスケジューリングを行うには、データソースまたはクラスターを DataStudio のコンピューティングリソースとして関連付ける必要があります。この関連付けがないと、データ開発ノードを作成できません。
-
計画しているタスクタイプに必要なデータソースまたはクラスターを作成します。
データソースまたはクラスター
説明
DataWorks は最初の MaxCompute データソースを自動的に関連付けます。それ以降のものは手動で関連付けます。
作成後、これらのデータソースを手動で関連付けます。
DataWorks は登録されたクラスターを自動的に関連付けます。手動での関連付けは不要です。
DataStudioページに移動します。
DataWorks コンソールにログインします。 左側のナビゲーションウィンドウで、 を選択します。 表示されるページで、ドロップダウンリストから目的のワークスペースを選択し、[DataStudioに移動] をクリックします。
-
左側メニューで、[コンピューティングリソース] をクリックします。
左側のナビゲーションペインにComputing Resource モジュールが表示されない場合は、[個人設定] の [モジュール管理] から追加してください。
-
コンピューティングリソースを関連付けます。
Computing Resource ページで、Computing Resource Name または Computing Resource Type で対象のデータソースまたはクラスターを検索し、Associate をクリックします。関連付け後、開発にデータソースを使用できます。
説明データソース情報が変更された場合は、ページを更新して変更内容を表示してください。

-
場合によっては、データソースまたはクラスターが DataStudio に関連付けられないことがあります。
-
関連付けは設定に依存します。たとえば、AccessKey ペアを使用するデータソースは関連付けできません。制限については、関連付けページで確認してください。
-
データソースに開発環境または本番環境がありません。
-
MaxCompute コンピューティングリソースは、同時に複数の DataWorks ワークスペースに関連付けることはできません。
説明プラットフォームには、関連付けに失敗した理由が表示されます。
-
-
DataStudio に関連付けできるのは、MaxCompute、EMR、Hologres、AnalyticDB for MySQL、ClickHouse、CDH/CDP、および AnalyticDB for PostgreSQL のみです。
-
関連付け可能なデータソースのタイプと制限は、DataWorks のエディションによって異なります。詳細については、「DataWorks の各エディションの機能」をご参照ください。
-
チュートリアル
「データ開発の開始」では、基本的な操作と開発プロセスについて説明しています。
サポートされているノードタイプ
DataStudio はさまざまなノードタイプを提供しており、その多くは定期的なスケジューリングをサポートしています。ビジネスニーズに基づいてノードを選択してください。詳細については、「サポートされているノードタイプ」をご参照ください。
付録: 概念
-
タスク開発
用語
説明
ソリューション
まとめて管理されるワークフローのコレクション。ワークフローは複数のソリューションで再利用でき、共同作業が可能です。
ワークフロー
ビジネス要件に応じたタスク、テーブル、リソース、関数のコレクション。タスクはスケジュールに従って実行されます。
手動トリガーワークフロー
特定のビジネス要件に応じたタスク、テーブル、リソース、関数のコレクション。
通常のワークフローとは異なり、手動トリガーワークフロー内のタスクは、スケジュールに従って実行されるのではなく、手動でトリガーする必要があります。
DAG
有向非巡回グラフの略語です。ノードとその依存関係を表示します。DataStudio では、ワークフロー内のすべてのタスクが 1 つの DAG を共有します。タスク
DataWorks の基本的な実行単位。タスクは依存関係に基づいて順次実行されます。
ノード
DAG 内のタスクを表します。ノードは依存関係に基づいて順次実行されます。
-
タスクスケジューリング
用語
説明
依存関係
タスク間の実行順序を定義します。タスク B がタスク A の完了後にのみ実行される場合、A は B の上流の依存関係です。DAG 内では矢印で表示されます。
出力名
ノードのグローバルに一意な識別子。1 つのノードは複数の出力名を持つことができます。DataWorks は、スケジューリングの依存関係を定義するために出力名を使用します。
出力テーブル名
タスクの出力テーブルの名前で、下流のタスクが正しいデータソースを確認するのに役立ちます。自動生成された出力テーブル名は変更しないでください。この識別子は実際のテーブル名には影響せず、実際のテーブル名は SQL ロジックによって決定されます。
説明ノードの Output Name はグローバルに一意である必要がありますが、Output Table Name にはこの制限はありません。
スケジューリングリソースグループ
タスクのスケジューリングに使用されるリソースグループ。詳細については、「DataWorks リソースグループの概要」をご参照ください。
スケジューリングパラメーター
日付や時刻などの実行時の値を動的に取得するための、コード内の変数です。DataWorks でスケジューリングパラメーターを定義して、実行時にコード変数に値を割り当てます。
業務日
ビジネストランザクションが発生した日付。オフラインコンピューティングでは、これは通常、タスクが実行される前日です。デフォルトでは、DataWorks はこれをタスク実行の前日に設定し、日付単位となります。たとえば、昨日の売上統計を生成する場合、昨日が業務日となります。
スケジューリング時間
タスクが実行される予定の時刻で、秒単位で正確です。実際の開始時刻は、さまざまな要因により異なる場合があります。