MaxCompute が提供するビルトイン関数がビジネス要件を満たせない場合、ユーザー定義関数 (UDF) を作成して、多様なビジネス要件を満たすことができます。このトピックでは、DataWorks で視覚化された方法で MaxCompute UDF を作成する方法について説明します。
背景情報
UDF は、既存の関数ライブラリを拡張して、より多くのデータ処理機能を提供するために使用されます。クエリのビジネス要件に基づいて、タスクのコードロジックと計算メソッドを指定できます。詳細については、「概要」をご参照ください。DataWorks で UDF を作成するために使用できる視覚化されたメソッドに加えて、MaxCompute Studio または MaxCompute の CLI を使用して UDF を作成することもできます。詳細については、「MaxCompute Studio を使用して UDF を作成する」および「MaxCompute の CLI を使用して UDF を作成する」をご参照ください。
前提条件
MaxCompute UDF を作成する前に、既存のリソースをアップロードするか、リソースを作成して視覚化された方法で DataWorks にリソースを追加する必要があります。詳細については、「MaxCompute リソースの作成と使用」をご参照ください。
MaxCompute リソースを作成する際、「Java で UDF を開発する」および「Python 3 で UDF を開発する」を参照して、必要な MaxCompute リソースファイルを準備できます。
制限事項
DataWorks では、DataWorks コンソールで視覚化された方法でアップロードされた UDF のみを表示および管理できます。MaxCompute Studio などの他のツールを使用して MaxCompute コンピュートエンジンに UDF を追加する場合、DataWorks DataStudio の [MaxCompute 関数] 機能を使用して、UDF を DataWorks に手動でロードする必要があります。ロードが完了すると、DataWorks で UDF を表示および管理できます。詳細については、「MaxCompute 関数を管理する」をご参照ください。
関数の登録
DataStudio ページに移動します。
ワークフローを作成します。詳細については、「自動トリガーワークフローの作成」をご参照ください。
関数を作成します。
目的のワークフローを展開し、[MaxCompute] を右クリックして、[関数の作成] を選択します。
[関数の作成] ダイアログボックスで、[名前] と [パス] を入力します。
[作成] をクリックします。
表示される構成タブの [関数の登録] セクションで、次の表で説明されているパラメーターを構成します。
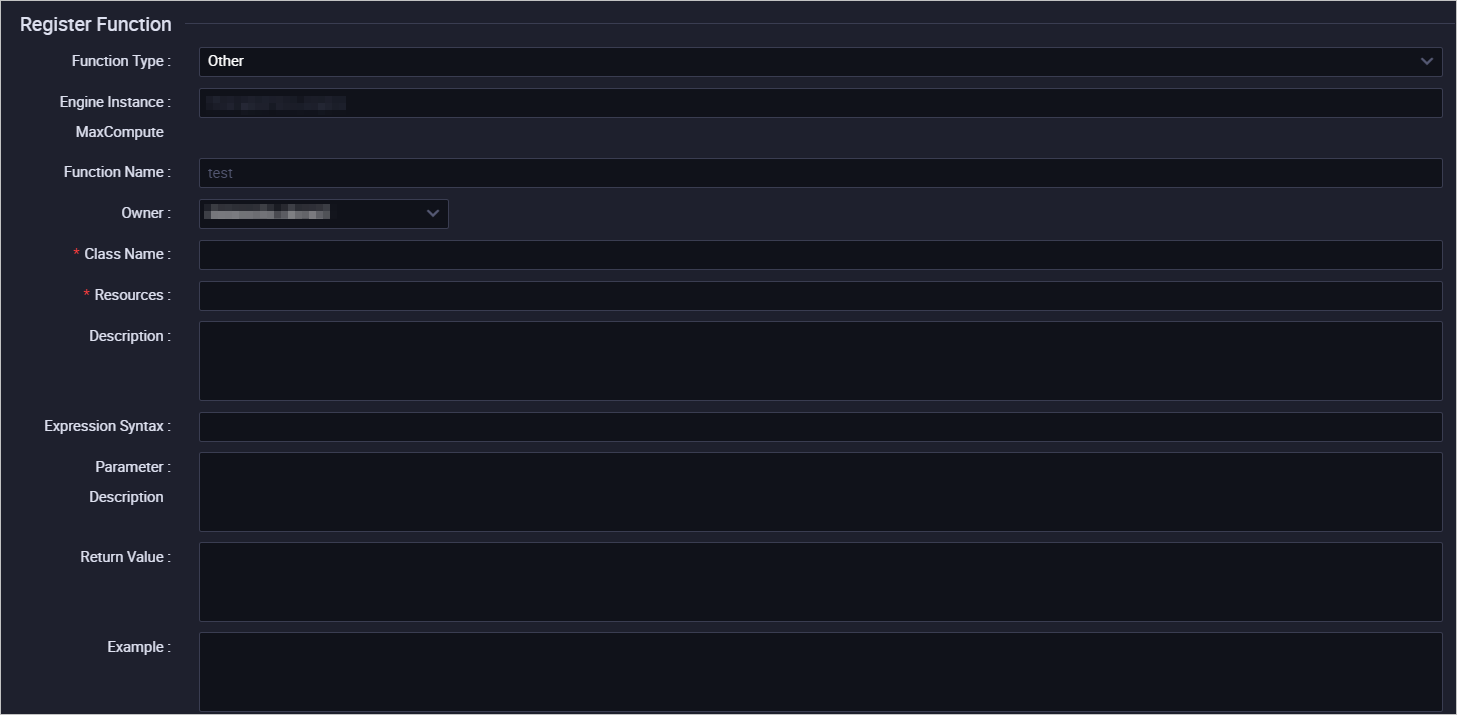
パラメーター
説明
関数タイプ
関数のタイプ。有効な値: 数学演算関数、集計関数、文字列処理関数、日付関数、ウィンドウ関数、および その他の関数。詳細については、「ビルトイン関数の使用」をご参照ください。
エンジンインスタンス MaxCompute
MaxCompute コンピュートエンジン。このパラメーターの値は変更できません。
関数名
関数の名前。SQL 文で関数を参照するために関数名を使用できます。関数名はグローバルに一意である必要があり、関数の登録後は変更できません。
オーナー
関数のオーナー。デフォルトのオーナーは、DataWorks コンソールへのログインに使用されるアカウントです。このパラメーターの値は変更できます。
クラス名
UDF を実装するクラスの名前。このパラメーターは
リソース名.クラス名のフォーマットで構成します。リソース名は、Java または Python パッケージの名前にすることができます。DataWorks コンソールで UDF を登録する際、JAR パッケージや Python リソースなどの MaxCompute リソースを参照できます。このパラメーターの値のフォーマットは、リソースタイプによって異なります:
リソースタイプが JAR の場合、[クラス名] パラメーターを
JAR パッケージ名.実際のクラス名のフォーマットで構成します。IntelliJ IDEA でcopy reference文を実行してクラス名をクエリできます。たとえば、
com.aliyun.odps.examples.udfが Java パッケージ名で、UDAFExampleがクラス名の場合、[クラス名] パラメーターの値はcom.aliyun.odps.examples.udf.UDAFExampleです。リソースタイプが Python の場合、[クラス名] パラメーターを
Python リソース名.実際のクラス名のフォーマットで構成します。たとえば、
LcLognormDist_shが Python リソース名で、LcLognormDist_shがクラス名の場合、[クラス名] パラメーターの値はLcLognormDist_sh.LcLognormDist_shです。説明リソース名に .jar または .py サフィックスを含める必要はありません。
リソースは、コミットおよびデプロイされた後に使用できます。MaxCompute リソースの作成方法の詳細については、「MaxCompute リソースの作成と使用」をご参照ください。
リソース
関数を登録するために使用するリソースを選択します。
ビジュアルモード: このモードを選択した場合、DataWorks にアップロードまたは追加されたリソースのみを選択できます。
コードエディター: このモードを選択した場合、MaxCompute コンピュートエンジン内のすべてのリソースを選択できます。
説明追加されたリソースのパスを指定する必要はありません。
UDF で複数のリソースが参照されている場合は、リソース名をコンマ (,) で区切ります。
説明
UDF の説明。
式構文
UDF の構文。例:
test。パラメーターの説明
サポートされている入力および出力パラメーターの説明。
戻り値
任意。戻り値。例: 1。
例
任意。関数の例。
上部のツールバーにある
 アイコンをクリックして UDF を保存します。
アイコンをクリックして UDF を保存します。UDF をコミットします。
上部のツールバーにある
 アイコンをクリックします。
アイコンをクリックします。[送信] ダイアログボックスで、[変更の説明] フィールドにコメントを入力します。
[確認] をクリックします。
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発へ] をクリックします。
MaxCompute コンピュートエンジン内の関数を表示する方法、関数の変更履歴、およびその他の操作を実行する方法の詳細については、「MaxCompute 関数を管理する」をご参照ください。
関数バージョンの表示と関数のロールバック
スケジュールされたワークフローペインのビジネスフローセクションにある MaxCompute フォルダで、MaxCompute 関数の名前を右クリックし、[以前のバージョンを表示] を選択して、関数の以前のバージョンを表示するか、関数をロールバックできます。

ノードでの UDF の使用
ノードで UDF を使用する場合、ノードのコードで UDF の名前を直接参照できます。具体的には、スケジュールされたワークフローペインで UDF を見つけ、UDF 名を右クリックして [関数の挿入] を選択します。これにより、UDF がノードの構成タブに表示されます。
付録 1: UDF の表示
SHOW FUNCTIONSコマンドを実行して、データソースとして DataWorks ワークスペースに追加された MaxCompute プロジェクトに登録されているすべての UDF を表示できます。MaxCompute は、さまざまな種類のビルトイン関数を提供します。詳細については、「ビルトイン関数の概要」をご参照ください。
// 現在のプロジェクトの関数を表示します。
SHOW FUNCTIONS;付録 2: UDF の詳細の表示
DESCRIBEまたは省略形のDESCコマンドの後に UDF 名を続けて実行すると、UDF の詳細を表示できます。// 省略形の DESC コマンドを使用して UDF の詳細を表示します。 DESC FUNCTION <function_name>;DataWorks で、ワークフローで必要な処理ロジックが既存の関数を使用して実装できない場合、MaxCompute UDF を作成し、JAR パッケージや Python ファイルなどの対応するリソースをアップロードして関連付けることで、データ処理機能を管理および拡張できます。詳細については、「MaxCompute リソースを管理する」をご参照ください。
ベストプラクティス
UDF を作成した後、「特定の UDF へのアクセスを特定のユーザーに許可する」で説明されている手順に従って、UDF のアクセスの制御を実装できます。
リファレンス
MaxCompute では、Java プログラムを JAR ファイルにパッケージ化し、JAR ファイルを MaxCompute リソースとしてアップロードし、数回のクリックで MaxCompute UDF を登録できます。詳細については、「Java プログラムのパッケージ化、パッケージのアップロード、および MaxCompute UDF の作成」をご参照ください。
Java で作成された MaxCompute UDF に関するよくある質問については、「MaxCompute Java UDF に関するよくある質問」をご参照ください。
Python で作成された MaxCompute UDF に関するよくある質問については、「MaxCompute Python UDF に関するよくある質問」をご参照ください。
よくある質問
Q: DataWorks コンソールでアップロードされた特定のリソースに基づいて UDF が登録された後、その UDF は DataStudio の ODPS SQL ノードで使用できます。その UDF は DataAnalysis の SQL クエリでも使用できますか?
A: はい、その UDF は DataAnalysis の SQL クエリで使用できます。DataWorks コンソールで登録された UDF は MaxCompute プロジェクトに保存されます。したがって、UDF は ODPS SQL ノードだけでなく、DataAnalysis の SQL クエリでも使用できます。