標準ディメンションテーブルには、ビジネスエンティティとその属性が記述されます。たとえば、メンバーディメンションテーブルには、メンバー名、メンバー ID、メンバーのメールアドレスなどのデータが含まれます。このトピックでは、標準ディメンションテーブルの作成と設定について説明します。
制限事項
Data Standard モジュールをサブスクライブしていない場合、テーブル内フィールドのフィールド標準は設定できません。
Asset Security モジュールをサブスクライブしていない場合、テーブル内フィールドのデータセキュリティレベルまたはデータ分類は設定できません。
Data Quality モジュールをサブスクライブしていない場合、プライマリキーフィールドのUnique 制約およびNot Null 制約は適用されません。
前提条件
ビジネスエンティティを作成する必要があります。詳細については、「ビジネスエンティティの作成と管理」をご参照ください。
操作手順
ステップ1:標準ディメンションテーブルの作成
Dataphin ホームページのトップナビゲーションバーで、[開発] > [データ開発] を選択します。
上部メニューで、[Project] を選択します。Dev-Prod モードを使用している場合は、[Environment] も選択する必要があります。
左側のナビゲーションペインで、[標準モデリング] > [ディメンションテーブル] を選択します。
右側のディメンションテーブルリストで、
 [新規作成] アイコンをクリックします。
[新規作成] アイコンをクリックします。[ディメンションテーブルの作成] ダイアログボックスで、以下のパラメーターを設定します。
パラメータ
説明
[ビジネスオブジェクト]
[標準オブジェクト] を選択します。
[テーブルタイプ]
ビジネスオブジェクトに [標準オブジェクト] を選択した場合、テーブルタイプは自動的に [標準ディメンションテーブル] に設定され、変更できなくなります。
[データセグメント]
プロジェクトに関連付けられたデータセグメントがデフォルトで設定されます。この設定は変更できません。
[サブジェクトエリア]
ビジネスオブジェクトのサブジェクトエリアがデフォルトで設定されます。この設定は変更できません。
コンピューティングエンジン
Dataphin インスタンスに Hadoop コンピューティングエンジンが設定されている場合、Hive、Impala、Spark などのエンジンを選択できます。
重要コンピューティングエンジンを選択する前に、そのエンジンを有効化する必要があります。詳細については、「Hadoop コンピューティングソースの作成」をご参照ください。
コンピューティングエンジンが TDH 6.x または TDH 9.3.x の場合、このパラメータは設定できません。
コンピューティングエンジンには以下の制限があります。
Hive:Kudu 形式で格納されたソーステーブルを読み取ることができません。
Impala:Kudu 形式のソーステーブルを読み取ることができますが、論理テーブルを Kudu に格納することはできません。Kudu 形式のソーステーブルがない場合は、Impala の使用は推奨されません。
Spark:Kudu 形式で格納されたソーステーブルを読み取ることができません。
[データタイムリネス]
ディメンションテーブルのデータのタイムリネスを指定します。オプションとして、日次の [T+1]、時間単位の [T+h]、分単位の [T+m] があります。
説明ArgoDB、StarRocks、SelectDB、および Doris コンピューティングエンジンは、オフラインの [T+1](日次)テーブルのみをサポートします。
[論理テーブル名]
論理テーブルの名前を入力します。名前は最大 100 文字です。ビジネスオブジェクトを選択すると、システムは
{データセグメント名}.dim_{ビジネスオブジェクトコード}_{データタイムリネス}形式で名前を自動生成します。重要名前には、英字、数字、アンダースコア (_) のみを使用できます。英字で始める必要があります。名前は大文字と小文字を区別せず、大文字は自動的に小文字に変換されます。
label_はシステム予約のプレフィックスです。名前をlabel_で始めないでください。AnalyticDB for PostgreSQL の場合、テーブル名は 50 文字以内である必要があります。
{データタイムリネス}サフィックスは、選択したデータタイムリネスによって異なります。df:日次フルスナップショット (T+1)。当日までのすべての履歴データを格納します。
hf:時間次フルスナップショット (T+h)。現在の時刻までのすべての履歴データを格納します。
mf:分次フルスナップショット (T+m)。15 分ごとに、直近の 15 分間隔までのすべての履歴データを格納します。
[表示名]
命名規則は以下の通りです。
128 文字以内である必要があります。
任意の文字を使用できます。
[説明]
ディメンションテーブルの説明を入力します。最大 1,000 文字です。
[OK] をクリックして、標準ディメンションテーブルを作成します。
ステップ2:フィールドの設定
[テーブル構造] 設定ページで、フィールド、データ型、およびフィールドカテゴリを含むテーブル構造を定義します。
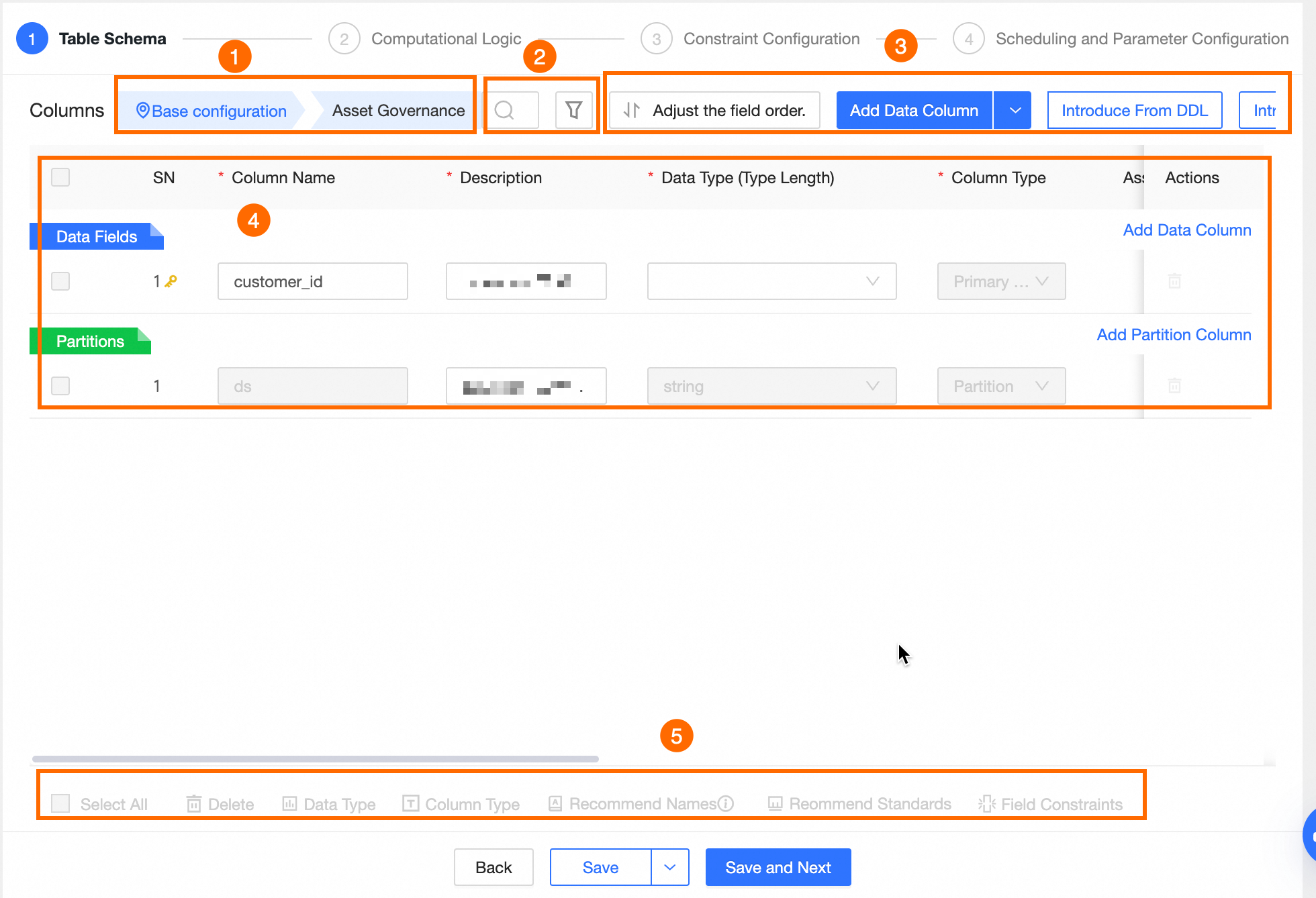 説明
説明論理テーブル名の横にある
 アイコンをクリックすると、基本情報を表示できます。
アイコンをクリックすると、基本情報を表示できます。エリア
説明
① テーブルフィールドの検索
クリックして、フィールドリストの[基本設定]または[データガバナンス]セクションに移動します。
② 検索とフィルター
フィールド名で検索できます。
 をクリックすると、[データ型]、[フィールドカテゴリ]、[関連ディメンションの有無]、[関連ディメンション]、[フィールド制約]、[データセキュリティレベル] でフィールドを絞り込めます。
をクリックすると、[データ型]、[フィールドカテゴリ]、[関連ディメンションの有無]、[関連ディメンション]、[フィールド制約]、[データセキュリティレベル] でフィールドを絞り込めます。③ フィールドリスト操作
[フィールド順序の調整]:データエラーを防ぐため、フィールドを並べ替える前に、この論理テーブルに依存する下流ジョブが
select *クエリを使用していないことを確認してください。[フィールドのインポート]:[DDL ステートメントからインポート] または [テーブルからインポート] を使用してフィールドを追加できます。 詳細については、「ディメンションテーブルのフィールドをインポートする」をご参照ください。
[フィールドの追加]: [データフィールド] または [パーティションフィールド] を追加します。 [名前]、[説明]、[データ型]、[フィールドカテゴリ]、[関連ディメンション]、[フィールド標準]、[フィールド制約]、[データ分類]、[データセキュリティレベル]、および [備考] を編集できます。
説明MaxCompute エンジンの場合、最大 6 レベルのパーティションフィールドを作成できます。
ArgoDB、StarRocks、SelectDB、Doris コンピューティングエンジンでは、パーティションフィールドを追加できません。
④ フィールドリスト
フィールドリストには、各フィールドの[シーケンス番号]、[フィールド名]、[説明]、[データ型]、[フィールドカテゴリ]、[関連ディメンション]、[フィールド標準]、[フィールド制約]、[データ分類]、[データセキュリティレベル]、[備考] などの詳細情報が表示されます。
[連番]:フィールドの連番です。新しいフィールドごとに 1 ずつ自動的に増加します。
フィールド名:フィールドの名前です。フィールド名またはキーワードを入力すると、システムが一致する標準フィールド名を自動的に提案します。
[説明]:フィールドの説明です。最大 512 文字です。
[データ型]: サポートされているデータ型には、[string]、[bigint]、[double]、[timestamp]、[decimal]、[テキスト]、[数値]、[日付/時刻]、[その他] が含まれます。
[フィールドカテゴリ]:[プライマリキー]、[パーティション]、または[属性]に設定できます。
説明プライマリキーフィールドは 1 つしか設定できません。
STRING、VARCHAR、BIGINT、INT、TINYINT、SMALLINT 型のフィールドのみをパーティションフィールドとして使用できます。
[関連ディメンション]:詳細については、「関連ディメンションの追加」をご参照ください。
[フィールド標準]:フィールドの標準を選択します。標準を作成するには、「データ標準の作成と管理」をご参照ください。
[フィールド制約]: フィールドの制約を選択します。サポートされている制約は [一意] と [Not Null] です。
[データ分類]:フィールドのデータ分類を選択します。データ分類を作成するには、「データ分類の作成」をご参照ください。
[データセキュリティレベル]:データ分類を選択すると、システムが自動的にデータセキュリティレベルを決定します。
[備考]:フィールドの備考を入力します。最大 2,048 文字です。
[操作] 列でフィールドを [削除] することもできます。
説明フィールドの削除は元に戻すことができません。
ディメンションテーブルのプライマリキーおよびシステムパーティションフィールドは削除できません。
⑤ 一括操作
選択したフィールドに対して、以下の一括操作を実行できます。
[削除]:
 アイコンをクリックして、選択したデータフィールドを一括で削除します。
アイコンをクリックして、選択したデータフィールドを一括で削除します。[データ型]:
 アイコンをクリックして、選択したフィールドのデータ型を一括で変更します。
アイコンをクリックして、選択したフィールドのデータ型を一括で変更します。[フィールドカテゴリ]:
アイコンをクリックして、選択したフィールドのフィールドカテゴリを一括で変更します。[基数ベースの命名]:
 アイコンをクリックします。システムは[説明]の内容をトークンに分割し、既存の基数と照合して、フィールド名を推奨します。次の図に示すように、[基数ベースの命名] ダイアログボックスで、選択したフィールドの名前を推奨値に置き換えることができます。説明
アイコンをクリックします。システムは[説明]の内容をトークンに分割し、既存の基数と照合して、フィールド名を推奨します。次の図に示すように、[基数ベースの命名] ダイアログボックスで、選択したフィールドの名前を推奨値に置き換えることができます。説明推奨フィールド名がニーズに合わない場合は、[修正後のフィールド名] 入力ボックスで編集できます。
[リセット] をクリックして、[変更後のフィールド名] をシステムの基数一致によって提案された名前に戻します。
[フィールド標準]:
 アイコンをクリックします。システムはフィールド名に基づいてフィールド標準を推奨します。[フィールド標準] ダイアログボックスで、推奨された標準をフィールドに適用できます。
アイコンをクリックします。システムはフィールド名に基づいてフィールド標準を推奨します。[フィールド標準] ダイアログボックスで、推奨された標準をフィールドに適用できます。[フィールド制約]:
 アイコンをクリックして、選択したフィールドに一括で制約を設定します。重要
アイコンをクリックして、選択したフィールドに一括で制約を設定します。重要子ディメンションテーブルにはフィールド制約を設定できません。
[保存して次へ] をクリックします。
フィールドのインポート
テーブルからインポート
ディメンションテーブルの設定ページで、[テーブルからインポート] をクリックします。
[テーブルからインポート] ダイアログボックスで、[ソーステーブル] を選択し、追加するフィールドを選択します。
パラメータ
説明
[ソーステーブル]
読み取り権限を持つ、現在のテナント内の任意の物理テーブル、論理テーブル、またはビュー (パラメータ化されたビューを除く) を選択できます。これには、Dataphin によって自動生成された物理テーブルは含まれません。
物理テーブルの読み取り権限を取得する方法については、「テーブル権限の申請、更新、解放」をご参照ください。
[フィールドリスト]
追加するフィールドを選択します。
説明異なるソーステーブルを切り替えて、複数のテーブルからフィールドを選択できます。
[選択したフィールド]
追加したフィールドがここに表示されます。このリストからフィールドを[削除]できます。
[追加]をクリックして、物理テーブルのフィールドをディメンションテーブルにインポートします。
追加すると、[新しいフィールド] エリアで、新しいフィールドの名前、データ型、フィールドカテゴリ、関連ディメンションなどを編集できます。
DDL ステートメントからインポート
ディメンションテーブルの設定ページで、[DDL ステートメントからインポート] をクリックします。
[DDL ステートメントからインポート] ダイアログボックスで、DDL ステートメントを入力し、[SQL を解析] をクリックします。
フィールドリストから、必要なフィールドを選択し、[追加] をクリックしてディメンションテーブルに作成します。
関連ディメンションの追加
ディメンションテーブル設定ページで、[関連ディメンション] 列の
 アイコンをクリックして、[モデルリレーションシップの編集] ダイアログボックスを開きます。
アイコンをクリックして、[モデルリレーションシップの編集] ダイアログボックスを開きます。[モデルリレーションシップの編集] ダイアログボックスで、パラメーターを設定します。
エリア
パラメータ
説明
[Null 置換値]
メインテーブル (現在のディメンションテーブル) が関連ディメンションテーブルと結合できない場合、Dataphin は結合フィールドに自動的に -110 を入力します。
[ディメンションテーブル]
[関連エンティティ]、[ディメンションテーブル]
既存の[関連エンティティ]と[ディメンションテーブル]を選択します。
[結合ロジックの編集]
[結合ロジック]
ソースフィールドと関連ディメンションテーブルのプライマリキーとの結合を表示します。これは変更できません。
[ディメンションテーブルのバージョンポリシー]
メインテーブルと結合する関連ディメンションテーブルのパーティションを指定します。デフォルトでは、同じスケジューリングサイクルのパーティションを使用します。
[同一周期のディメンションを使用]:メインテーブルと関連ディメンションテーブルは、計算に同じ時間パーティションを使用します。
たとえば、ビジネス日付が 20220101 で、メインテーブルと関連ディメンションテーブルの両方の
ds=20220101パーティションをクエリする必要がある場合は、このオプションを選択します。[最新のディメンションテーブルを使用]:関連付けられたディメンションテーブルの最新のパーティションを計算に使用します。
たとえば、商品カテゴリが頻繁に変更されるとします。10 日前は携帯電話カテゴリでしたが、今日では家電カテゴリになっています。現在の家電カテゴリを使用して 10 日前のデータを再処理する必要がある場合、ディメンションテーブルのバージョニングポリシーを [最新のディメンションテーブルを使用 (最新のパーティションを使用)] に設定する必要があります。
[結合失敗時のポリシー]
このポリシーは、ソーステーブル (左テーブル) には存在するが、ディメンションテーブル (右テーブル) には存在しないデータに対する計算ロジックを指定します。[結合されなかった元のデータを保持する] または [結合されなかったデータをデフォルト値に置き換える] を選択できます。
[元の未結合データを保持]: 派生メトリックを作成する際に、左テーブルの元のデータを保持します。
[結合されていないデータをデフォルト値に置き換える]: メインテーブルのフィールドに、ディメンションテーブルで一致するエントリがない場合、その値はデフォルト値の -110 に置き換えられます。
[ディメンションロールの編集]
[ロール英語名]、[ロール名]
ディメンションロールはディメンションのエイリアスとして機能し、同じディメンションを異なる名前で複数回参照できるようにします。[ロール英語名] と [ロール名] を定義する必要があります。
[ロール英語名]は、プレフィックス
dimで始まる必要があります。カスタム部分は、以下のルールに従う必要があります。英字、数字、アンダースコア (_) のみを使用できます。
64 文字以内である必要があります。
[ロール名]は、以下のルールに従う必要があります:
中国語文字、数字、英字、アンダースコア (_)、ハイフン (-) のみを使用できます。
64 文字以内である必要があります。
[OK] をクリックします。
ステップ3:コンピューティングロジックの設定
[コンピューティングロジック] 設定ページで、ソースデータをディメンションテーブルのフィールドにマッピングします。
[ソース設定] をクリックし、[ソース設定] ダイアログボックスで [+ソースオブジェクトの追加] をクリックしてソースパラメーターを設定します。
説明フィルター条件またはカスタム SQL にイベント時刻の追加のフィルターを追加しないことを推奨します。
パラメータ
説明
[ソースタイプ]
サポートされているソースタイプには、[物理テーブル]、[カスタム SQL]、[論理テーブル] が含まれます。
ソーステーブルタイプの説明:
プライマリキーを持つソーステーブル:プライマリキーを持つ論理テーブルは、複数のソースを持つことができます。最初のソースは常にプライマリソースであり、論理テーブルの総行数を決定します。
プライマリキーを持たないソーステーブル:プライマリキーを持たない論理テーブルは、1 つのソースしか持てません。ソースが複数のテーブルを含む場合は、カスタム SQL を使用して事前に結合する必要があります。
説明複数のソースオブジェクトを設定するには、[ソースオブジェクトの追加]をクリックします。
[ソースオブジェクト]
[物理テーブル]: 現在のテナント内で読み取り権限を持つ任意の物理テーブルまたは物理ビュー (パラメーター化ビューを除く) を選択できます。これには、Dataphin によって自動生成された物理テーブルは含まれません。
物理テーブルの読み取り権限を取得する方法については、「テーブル権限の申請、更新、解放」をご参照ください。
[カスタム SQL] を選択し、
 アイコンをクリックして、エディターに SQL ステートメントを入力します。例:
アイコンをクリックして、エディターに SQL ステートメントを入力します。例:select id, name from project_name_dev.table_name1 t1 join project_name2_dev.table_name2 t2 on t1.id = t2.id[論理テーブル]: 現在のテナント内で、読み取り権限がある任意の論理テーブルを選択できます。
テーブルの読み取り権限を取得する方法については、「テーブル権限の申請、更新、解放」をご参照ください。
重要論理テーブルを別の論理テーブルのデータソースとして使用すると、コンピューティングロジックとメンテナンスの複雑さが増します。
[オブジェクトエイリアス]
ソーステーブルのエイリアスを定義します。例:t1、t2。
[オブジェクトの説明]
オブジェクトの説明を入力します。最大 1,000 文字です。
[フィルタ条件]
カスタム SQL のフィルタ条件を定義します。
アイコンをクリックし、エディタで内容を入力します。例:ds=${bizdate} and condition1=value1[結合フィールド]
論理テーブルのプライマリキーに対応するソースオブジェクトのフィールドで、等価結合に使用されます。
[削除]
プライマリソースは削除できません。
プライマリキーを持たない論理テーブルの場合、ソースを削除すると、すべてのフィールドのコンピューティングロジックがクリアされます。
ソース設定を保存するには、[OK] をクリックします。
ソースを設定した後、[ソースフィールド] を計算ロジック式にドラッグします。 また、[同じ名前のフィールドをクイックマッピング] をクリックして、ソースフィールドを同名の論理テーブルフィールドに自動的にマッピングすることもできます。
 アイコンをクリックして、エディタでコンピューティングロジック式を編集します。sum、count、min などの集計関数はサポートされていません。例:
アイコンをクリックして、エディタでコンピューティングロジック式を編集します。sum、count、min などの集計関数はサポートされていません。例:例 1:
substr(t1.column2, 3, 10)例 2:
case when t1.column2 != '1' then 'Y' else 'N' end例 3:
t1.column2 + t2.column1
コンピューティングロジックを設定した後、下部の
 アイコンをクリックして式を検証します。
アイコンをクリックして式を検証します。[SQL プレビュー] をクリックすると、計算ロジック用に生成された SQL を表示できます。
[保存して次へ] をクリックします。
ステップ4:制約の設定
フィールド制約に基づいて、システムは Data Quality モジュールで現在の論理テーブルの品質ルールを作成します。各フィールドの [ルールの重大度] を設定でき、[強ルール] と [弱ルール] から選択できます。詳細については、「データテーブル品質ルール」をご参照ください。
説明論理テーブルフィールド制約のルールの重大度は、ここでのみ設定でき、Data Quality モジュールでは編集できません。
[保存して次へ] をクリックします。
ステップ5:スケジューリングの設定
[スケジューリングとパラメーター設定] ページで、ディメンションテーブルの データ遅延、スケジューリングプロパティ、スケジューリング依存関係、スケジューリングパラメーター、および ランタイム設定 を設定します。
パラメータ
説明
データ遅延
データ遅延を有効にすると、システムは [最大遅延日数] で指定された期間内に、このロジックテーブルのすべてのデータを自動的に再実行します。 詳細については、「ロジックテーブルのデータ遅延を設定する」をご参照ください。
スケジューリングプロパティ
本番環境でディメンションテーブルをスケジュールする方法を指定します。スケジューリングタイプ、サイクル、実行ロジックなどのプロパティを設定できます。詳細については、「論理テーブルのスケジューリングプロパティの設定」をご参照ください。
上流の依存関係
この設定は、スケジューリングタスクにおける論理テーブルのノードを定義します。Dataphin はこれらの依存関係を使用して、ビジネスプロセスのノードを順序正しく実行し、タイムリーで有効なデータ出力を保証します。詳細については、「論理テーブルの上流の依存関係の設定」をご参照ください。
パラメータ設定
この設定では、コード内の変数に値を割り当てます。これらの変数は、ノードのスケジューリング中に、対応する値に自動的に置換されます。スケジューリングパラメーター設定ページで、パラメーターを [無視] するか、[グローバル変数に変換] するかを選択できます。詳細については、「論理テーブルのパラメーターを設定する」をご参照ください。
ランタイム設定
タスクレベルのランタイムタイムアウト期間とタスク失敗時の再実行ポリシーを設定できます。これにより、長時間実行されるタスクによるリソースの浪費を防ぎ、タスク実行の信頼性を向上させます。詳細については、「論理テーブルのランタイム設定の構成」をご参照ください。
リソース設定
現在の論理テーブルタスクのスケジューリングリソースグループを設定できます。タスクは、スケジューリング中にこのグループのリソースクォータを消費します。設定の詳細については、「論理テーブルのリソースの設定」をご参照ください。
[保存してコミット] をクリックします。
ステップ6:保存とコミット
標準ディメンションテーブルを設定した後、[保存してコミット] をクリックします。
システムは、[テーブル構造]、[コンピューティングロジック]、[スケジューリングの依存関係]、および [ランタイムパラメーター] の設定を検証します。[チェック結果] に基づいて、失敗した設定を確認し、修正してください。
すべてのチェックに合格したら、送信コメントを入力して [OKしてコミット] をクリックします。
コミット時に、Dataphin はデータリネージ分析とコミット前チェックを実行します。詳細については、「標準モデリングタスクのコミットに関する注意事項」をご参照ください。
シングルテナント、マルチエンジンのシナリオ
テーブルからインポートメソッドでフィールドをインポートする場合、同じエンジンタイプのプロジェクトからのみテーブルをインポートできます。
ソーステーブルリストからは、現在のプロジェクトと同じクラスター内にあるプロジェクトのテーブルのみを選択できます。
次のステップ
プロジェクトが Dev-Prod モードの場合は、論理テーブルを本番環境に公開してください。詳細については、「公開タスクの管理」をご参照ください。
論理テーブルを本番環境に公開した後、O&M センターで関連タスクを表示および管理できます。詳細については、「O&M センター」をご参照ください。