クラウドネイティブ AI スイートは、Container Service for Kubernetes (ACK) 上で AI および機械学習ワークロードを構築・運用するためのフルスタック基盤を提供する ACK ソリューションです。リソース管理、ジョブスケジューリング、データアクセラレーション、ライフサイクルツールを一元的に処理することで、チームがクラスター管理ではなくモデル開発およびトレーニングに集中できるよう支援します。
このスイートは、CLI、多言語 SDK、ACK コンソールを通じてすべての機能を公開しており、同一のインターフェイスから Alibaba Cloud の AI サービス、オープンソースフレームワーク、およびサードパーティ製 AI ツールと統合されます。
サポート対象のワークロード
クラウドネイティブ AI スイートでは、以下の AI/機械学習ワークロードタイプをサポートしています。
| ワークロード | サポート対象ツール |
|---|---|
| 分散モデルトレーニング | TensorFlow、PyTorch、DeepSpeed、Horovod、Kubeflow |
| バッチ(オフライン)推論 | Apache Spark、Apache Flink |
| リアルタイム推論 | vLLM、Triton Inference Server、KServe |
| ML パイプラインオーケストレーション | Kubeflow Pipelines、Argo Workflows |
| 対話型モデル開発 | Jupyter ノートブック、PAI Data Science Workshop (DSW) |
| セルフマネージドエンジン | 任意のカスタムランタイムまたはフレームワーク |
アーキテクチャ
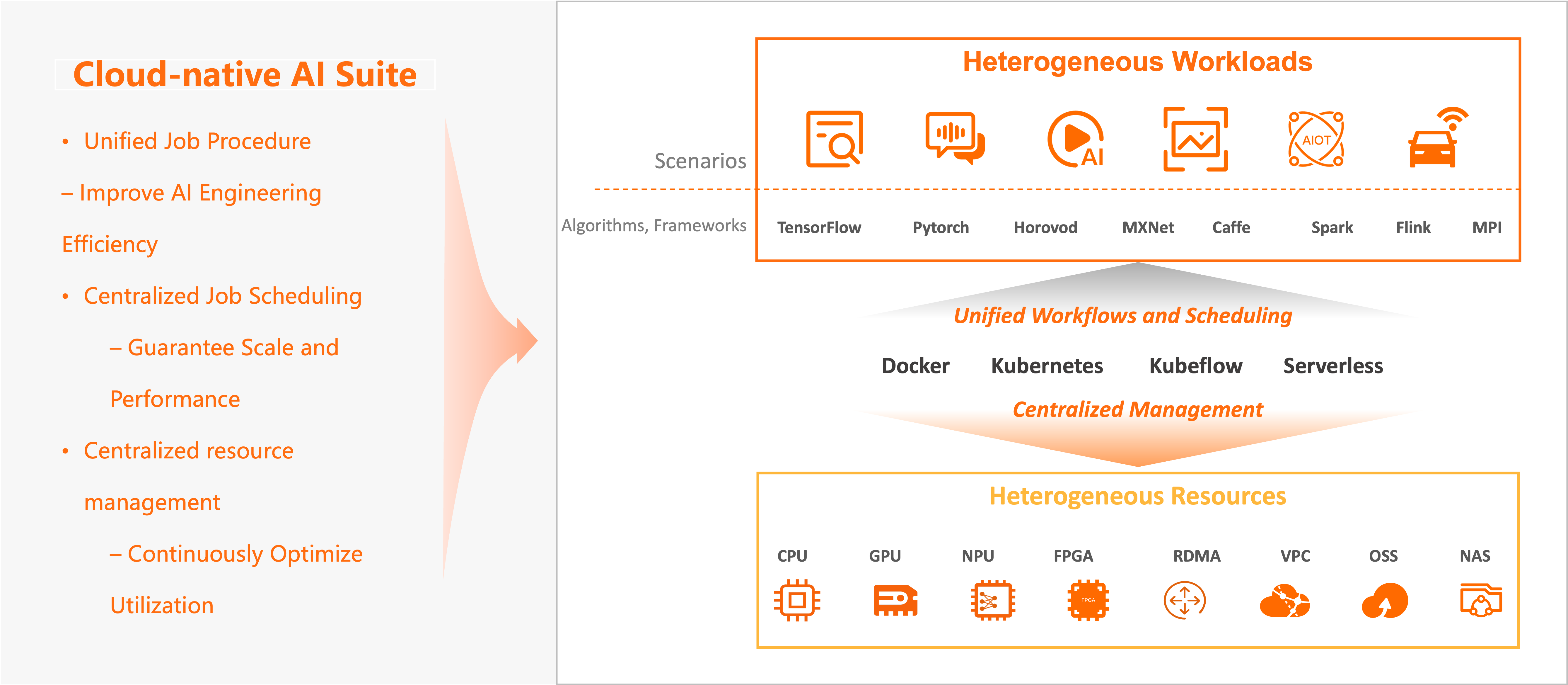
Container Service for Kubernetes (ACK) を基盤として構築されたクラウドネイティブ AI スイートは、下位層でヘテロジニアスなコンピューティング、ストレージ、ネットワークリソースを一元管理し、上位層で標準的な Kubernetes クラスターおよび API を提供します。この基盤の上に、AI ワークロードに必要なスケジューリング、データオーケストレーション、ワークフロー、ライフサイクル管理コンポーネントを実装しています。

PAI との統合。 このスイートは Platform for AI (PAI) と統合され、高性能かつ弾力的な AI プラットフォームを構成します。ACK は、PAI サービスである Data Science Workshop (DSW)、Deep Learning Containers (DLC)、Elastic Algorithm Service (EAS) の弾力性および効率性を向上させます。数回のクリック操作で ACK クラスター内に Lightweight Platform for AI をデプロイすることで、PAI の高度に最適化されたアルゴリズムおよびエンジンをコンテナ化ワークロードに組み込み、トレーニングおよび推論の両方を高速化できます。詳細については、「Platform for AI (PAI) とは」をご参照ください。
主な特徴
| 特徴 | 説明 | 関連ドキュメント |
|---|---|---|
| ヘテロジニアスリソース管理 | NVIDIA GPU、NPU、FPGA、VPU、RDMA を標準 ACK リソースと併せて一元的にスケジュールおよび管理します。GPU の割り当て状況、使用率、健全性を複数ディメンションでモニタリングします。GPU シェアリング、GPU メモリ隔離、トポロジー認識型 GPU スケジューリングを有効化することで、リソース利用率を向上させます。 | ヘテロジニアスコンピューティング向け ACK クラスターの概要、ACK クラスターにおける GPU モニタリングの有効化、GPU シェアリング |
| AI ジョブスケジューリング | 分散トレーニングジョブ向けに Kubernetes ネイティブスケジューリングフレームワークを拡張します。サポートされるポリシーには、ガンスケジューリング(コスケジューリング)、先着順(FIFO)スケジューリング、キャパシティスケジューリング、フェアシェアリング、ビンパッキングおよびスプレッドがあります。テナントごとに優先度ベースのジョブキューおよび弾力的クォータを設定できます。また、Kubeflow Pipelines または Argo Workflows を用いて複雑なパイプラインをオーケストレーションできます。 | GPU シェアリング、AI ワークロードのスケジューリング |
| 弾力的スケジューリング | 分散ディープラーニングジョブ実行中に、トレーニングを中断したりモデル精度に影響を与えたりすることなく、ワーカーおよびノード数を動的にスケールできます。アイドルリソースが利用可能になるとワーカーが追加され、リソースが不足するとワーカーが解放されるため、ノード障害の回避、ジョブ起動待ち時間の短縮、クラスター全体の利用率向上が実現されます。 | Kubernetes を基盤とした弾力的トレーニング |
| AI データオーケストレーションおよびアクセラレーション | Fluid は、ヘテロジニアスなストレージバックエンド上でデータセット抽象化を導入します。ack-fluid は、さまざまなストレージサービスからデータを取得し、クラウド上およびオンプレミスのストレージをハイブリッドクラウド環境で統合した単一のデータセットに集約します。データセット単位の分散キャッシュサービスにより、データセットのウォームアップ、キャッシュ容量のモニタリング、弾力的スケーリングが可能となり、リモートデータインジェストのオーバーヘッドを削減し、GPU コンピューティング効率を向上させます。 | 弾力的データセット、サーバーレスクラウドコンピューティングにおけるデータアクセスの高速化 |
| AI ジョブライフサイクル管理 | Arena は、データ管理、モデル開発、トレーニング、推論サービスデプロイという全プロダクションワークフローをカバーし、リソーススケジューリング、環境構成、モニタリングを抽象化します。TensorFlow、PyTorch などの主要な AI スタックと互換性があり、多言語 SDK をサポートします。ack-arena は、コンソールから ACK クラスターへ直接デプロイ可能な最適化済み Arena インストールです。可視化されたダッシュボードおよび AI Developer Console を使用すれば、CLI を使わずにクラスター状態のモニタリングやトレーニングジョブの送信が可能です。 | Arena クライアントの構成、AI ダッシュボードへのアクセス、AI Developer Console へのログイン |
ユースケース
ヘテロジニアスリソース利用率の最大化
このスイートは、クラウド上のすべてのヘテロジニアスリソース — コンピューティング(CPU、GPU、NPU、VPU、FPGA)、ストレージ(Object Storage Service (OSS)、Apsara File Storage NAS、Cloud Parallel File Storage (CPFS)、HDFS)、ネットワーク(TCP、RDMA) — を統一された管理レイヤーに抽象化します。一元的な割り当て、スケーリング、ソフトウェア/ハードウェア最適化により、利用率を継続的に高水準に維持します。
大規模なヘテロジニアス AI ワークロードの実行
このスイートは、TensorFlow、PyTorch、DeepSpeed、Horovod、Apache Spark、Flink、Kubeflow、KServe、vLLM、Triton Inference Server などの主要なオープンソースエンジンおよびセルフマネージドエンジン・ランタイムと互換性があります。トレーニングパフォーマンス、効率性、コストを継続的に最適化するとともに、開発および運用保守(O&M)体験を向上させます。
ユーザーロール
| 役割 | 責務 |
|---|---|
| O&M 管理者 | AI インフラストラクチャを構築し、日常の管理を担当します。 詳細については、「クラウドネイティブ AI スイートのデプロイ」、「ユーザーの管理」、「エラスティッククォータグループの管理」、および「データセットの管理」をご参照ください。 |
| アルゴリズムエンジニア、データサイエンティスト | モデルを開発し、トレーニングジョブを実行し、推論サービスをデプロイします。 詳細については、Kubernetes クラスターでの「モデルのトレーニング」、「MLflow Model Registry でのモデル管理」、および「モデルの分析と最適化」をご参照ください。 |
クイックスタート
お使いのロールに応じて、以下の手順に従ってください。
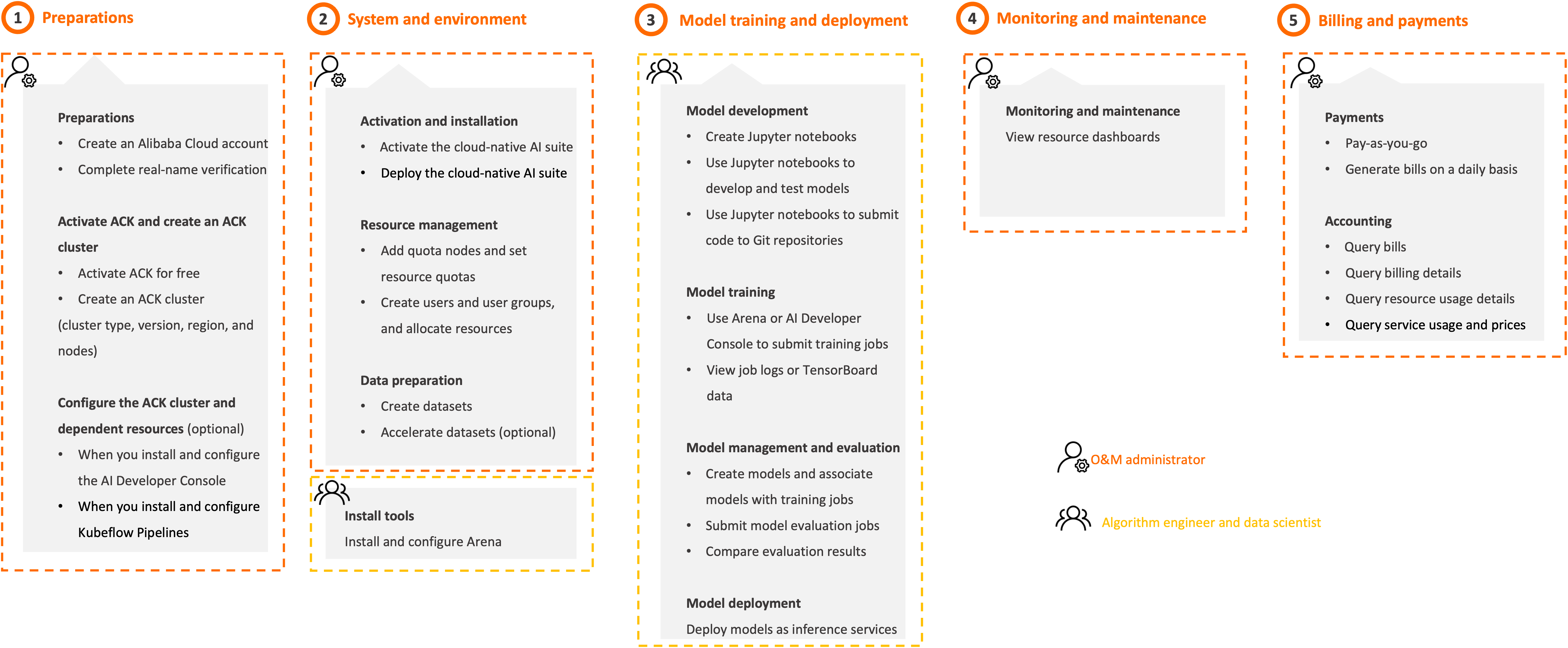
ステップ 1:事前準備(O&M 管理者)
Alibaba Cloud アカウントの作成
Alibaba Cloud アカウントを作成し、実名登録を完了してください。「Alibaba Cloud アカウントの作成」をご参照ください。開始するには、Alibaba Cloud 登録ページへアクセスしてください。Alibaba Cloud アカウント登録ページ
ACK クラスターの作成
ACK を有効化し、以下の構成でクラスターを作成してください。「ACK マネージドクラスターの作成」をご参照ください。
クラスタータイプ: ACK Pro マネージドクラスター、ACK Serverless Pro クラスター、または ACK Edge Pro クラスター
Kubernetes バージョン: 1.18 以降
リージョン: ACK を有効化したリージョン
クラスターを作成するには、ACK コンソールACK コンソールACK コンソールへアクセスしてください。
(任意)クラスター依存関係の構成
スイートコンポーネントのデプロイ前に、以下の依存関係を構成してください。
AI ダッシュボードおよび AI Developer Console
クラスター内に Prometheus エージェントおよび Logtail をインストールします。
クラスターのリソースアクセス管理 (RAM) ポリシーを作成します。権限付与をご参照ください。
ドメイン名経由で AI ダッシュボードおよび AI Developer Console にアクセスする場合は、NGINX Ingress コントローラーをインストールし、内部またはパブリックアクセスを有効化します。
プリインストール済みの MySQL データベースをストレージとして使用する場合は、クラスターノードに ESSD (エンタープライズ SSD) をアタッチします。
ApsaraDB RDS をストレージとして使用する場合は、ApsaraDB RDS インスタンスを購入し、
kubeai-rdsという名前の Secret をkube-ai名前空間内に作成します。
完全なセットアップについては、「AI ダッシュボードおよび AI Developer Console のインストールと構成」をご参照ください。
Kubeflow Pipelines
プリインストール済みの MinIO をストレージとして使用する場合は、クラスターノードに ESSD をアタッチします。
Object Storage Service (OSS) をストレージとして使用する場合は、OSS を有効化し、バケットを購入して、
kubeai-ossという名前の Secret をkube-ai名前空間内に作成します。「OSS の有効化」および「Kubeflow Pipelines のインストールと構成」をご参照ください。
ステップ 2:システムおよび環境の構成(O&M 管理者)
クラウドネイティブ AI スイートの有効化およびインストール
有効化ページへアクセスして、スイートを有効化します。
スイートおよびそのコンポーネントをインストールします。「クラウドネイティブ AI スイートのデプロイ」および「コンポーネントの概要およびリリースノート」をご参照ください。
インストールの管理には、ACK コンソールACK コンソールACK コンソールをご利用ください。
ユーザーおよびクォータの管理
クォータノードを追加し、リソースクォータを設定します。
ユーザーおよびユーザーグループを作成し、リソースを割り当て、クォータグループに関連付けます。「ユーザー管理」、「ユーザーグループの管理」、「弾力的クォータグループの管理」をご参照ください。
各新規ユーザーに対して kubeconfig ファイルおよびログイントークンを生成します。「新規作成ユーザーの kubeconfig ファイルおよびログイントークンの生成」をご参照ください。
これらのタスクは、AI ダッシュボード および kubectl を使用して完了できます。
AI Console(AI ダッシュボードおよび AI Developer Console)は、2025 年 1 月 22 日よりホワイトリスト方式で展開されています。それ以前の既存デプロイは影響を受けません。アカウントがホワイトリストに登録されていない場合は、オープンソースコミュニティ経由で AI Console をインストールおよび構成してください。「オープンソース版 AI Console」をご参照ください。
データの準備
データセットを作成します。
(任意)データセットをアクセラレーションします。「弾力的データセット」をご参照ください。
ステップ 3:モデルトレーニングおよびデプロイ(アルゴリズムエンジニアおよびデータサイエンティスト)
開始するには、Arena CLI または AI Developer Console をインストールしてください。「Arena クライアントの構成」および「AI ダッシュボードおよび AI Developer Console のインストールと構成」をご参照ください。
AI Console(AI ダッシュボードおよび AI Developer Console)は、2025 年 1 月 22 日よりホワイトリスト方式で展開されています。それ以前の既存デプロイは影響を受けません。アカウントがホワイトリストに登録されていない場合は、オープンソースコミュニティ経由で AI Console をインストールおよび構成してください。「オープンソース版 AI Console」をご参照ください。
あるいは、Lightweight Platform for AI をご利用ください。
モデルの開発
Jupyter ノートブックを作成および使用します。「Jupyter ノートブックの作成および使用」をご参照ください。
ノートブック内でモデルの開発およびテストを行います。
ノートブックから Git リポジトリへコードをコミットします。
モデルのトレーニング
AI Developer Console または Arena を使用してトレーニングジョブを送信します。
ジョブログまたは TensorBoard データを表示します。
詳細については、「モデルのトレーニング」をご参照ください。
モデルの管理
モデルを作成し、トレーニングジョブに関連付けます。
AI Developer Console または Arena CLI を使用してモデルを管理します。「MLflow Model Registry におけるモデル管理」をご参照ください。
モデルのデプロイ
モデルを推論サービスとしてデプロイする。「AI サービスのデプロイメント」および「」をご参照ください。
トレーニングおよびデプロイのタスクには、AI Developer Console および Arena をご利用ください。
ステップ 4:モニタリングおよびメンテナンス(O&M 管理者)
すべてのモニタリングおよび管理タスクには、AI ダッシュボード をご利用ください。
リソースのモニタリング
クラスター、ノード、トレーニングジョブ、リソースクォータのダッシュボードを表示します。「クラウドネイティブ AI ダッシュボードの使用方法」をご参照ください。
クォータの管理
クォータグループおよびそのリソースの作成、照会、更新、削除を行います。必要に応じてリソースタイプを変更できます。「弾力的クォータグループの管理」をご参照ください。
ユーザーの管理
ユーザーおよびユーザーグループの作成、照会、更新、削除を行います。「ユーザー管理」および「ユーザーグループの管理」をご参照ください。
データセットの管理
データセットおよびデータの作成、照会、更新、削除を行います。必要に応じてデータセットをアクセラレーションできます。「データセットの管理」および「弾力的データセット」をご参照ください。
エラスティック ジョブの管理
弾力的ジョブおよびジョブ詳細を表示します。「弾力的ジョブの表示」をご参照ください。
ステップ 5:課金(O&M 管理者)
クラウドネイティブ AI スイートは、2024 年 6 月 6 日 00:00:00(UTC + 08:00)より無償提供されています。「クラウドネイティブ AI スイートの課金」をご参照ください。
請求書、課金詳細、リソース使用量、サービス価格を照会するには、課金管理へアクセスしてください。
課金
クラウドネイティブ AI スイートは無償提供されています。「クラウドネイティブ AI スイートの課金」をご参照ください。
関連ドキュメント
| 参考情報 | 説明 |
|---|---|
| クラウドネイティブ AI スイート 開発者ガイド および クラウドネイティブ AI スイート O&M ガイド | 開発および運用保守(O&M)作業のエンドツーエンド実践例 |
| リリースノート | クラウドネイティブ AI スイートのリリースノート |