本番環境にデプロイする前にモデルがデプロイメント基準を満たしていることを確認するために、クラウドネイティブ AI スイートでサポートされているモデル分析および最適化コマンドを使用して、モデルのベンチマーク、分析、および最適化を行うことができます。このトピックでは、PyTorch によって提供される ResNet18 モデルを例として使用し、V100 GPU を使用してモデルを高速化します。
前提条件
Container Service for Kubernetes (ACK) Pro マネージドクラスターが作成されており、クラスターの Kubernetes バージョンは 1.20 以降です。クラスターには、少なくとも 1 つの GPU アクセラレーションノードが含まれています。ACK クラスターの更新方法の詳細については、「ACK クラスターを更新する」をご参照ください。
Object Storage Service (OSS) バケットが作成されています。永続ボリューム (PV) と永続ボリューム要求 (PVC) が作成されています。詳細については、「静的にプロビジョニングされた OSS ボリュームをマウントする」をご参照ください。
最新バージョンの Arena クライアントがインストールされています。詳細については、「Arena クライアントを構成する」をご参照ください。
背景情報
データサイエンティストはモデルの精度に重点を置いていますが、R&D エンジニアはモデルのパフォーマンスをより重視しています。両者がお互いのドメインを理解していない場合、誤解が生じやすくなります。その結果、オンラインサービスとしてモデルをリリースした後、モデルがパフォーマンス要件を満たさない可能性があります。この問題を防ぐために、モデルをリリースする前にベンチマークを行う必要がある場合があります。モデルがパフォーマンス要件を満たしていない場合は、パフォーマンスボトルネックを特定し、モデルを最適化できます。
モデル分析および最適化コマンドの概要
クラウドネイティブ AI スイートは、複数のモデル分析および最適化コマンドをサポートしています。コマンドを実行して、モデルのベンチマーク、ネットワーク構造の分析、各オペレーターの期間の確認、GPU 使用率の表示を行うことができます。次に、モデルのパフォーマンスボトルネックを特定し、TensorRT を使用してモデルを最適化できます。これにより、本番環境のパフォーマンス要件を満たすモデルをリリースできます。次の図は、モデル分析および最適化コマンドによって支援されるモデルライフサイクルを示しています。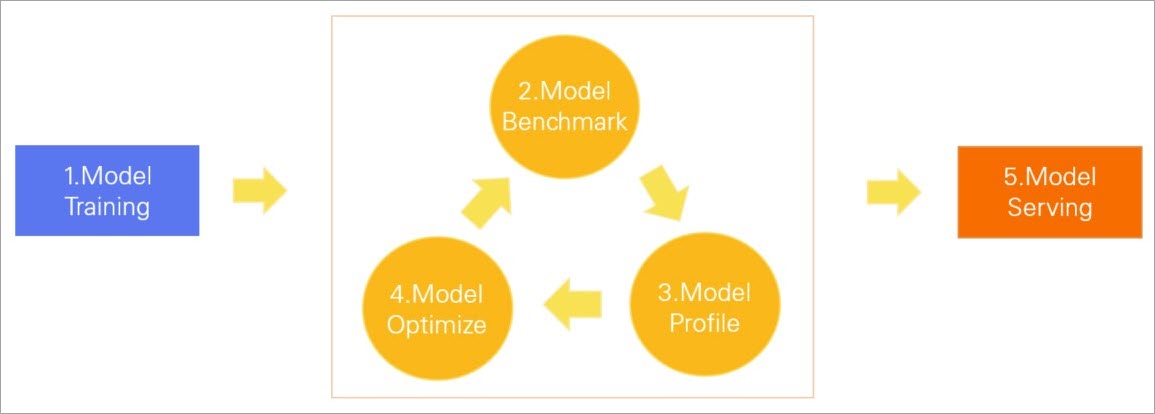
モデルのトレーニング: 指定されたデータセットに基づいてモデルがトレーニングされます。
モデルベンチマーク: モデルのレイテンシ、スループット、GPU 使用率が要件を満たしているかどうかを確認するために、モデルでベンチマークが実行されます。
モデルプロファイル: パフォーマンスボトルネックを特定するためにモデルが分析されます。
モデルの最適化: TensorRT などのツールを使用して、モデルの GPU 推論機能が最適化されます。
モデルサービング: モデルはオンラインサービスとしてデプロイされます。
モデルを最適化した後もモデルがパフォーマンス要件を満たしていない場合は、前のフェーズを繰り返すことができます。
コマンドの実行方法
Arena を使用して、モデル分析、最適化、ベンチマーク、および評価ジョブを ACK Pro マネージドクラスターに送信できます。arena model analyze --help コマンドを実行して、ヘルプ情報を表示できます。
$ arena model analyze --help
submit a model analyze job. // モデル分析ジョブを送信します。
Available Commands:
profile Submit a model profile job. // モデルプロファイルジョブを送信します。
evaluate Submit a model evaluate job. // モデル評価ジョブを送信します。
optimize Submit a model optimize job. // モデル最適化ジョブを送信します。
benchmark Submit a model benchmark job // モデルベンチマークジョブを送信します。
Usage:
arena model analyze [flags]
arena model analyze [command]
Available Commands:
benchmark Submit a model benchmark job // モデルベンチマークジョブを送信します。
delete Delete a model job // モデルジョブを削除します。
evaluate Submit a model evaluate job // モデル評価ジョブを送信します。
get Get a model job // モデルジョブを取得します。
list List all the model jobs // すべてのモデルジョブを一覧表示します。
optimize Submit a model optimize job, this is a experimental feature // モデル最適化ジョブを送信します。これは実験的な機能です。
profile Submit a model profile job // モデルプロファイルジョブを送信します。ステップ 1: モデルを準備する
PyTorch モデルをデプロイするには、TorchScript を使用することをお勧めします。このトピックでは、PyTorch によって提供される ResNet18 モデルを例として使用します。
モデルを変換します。ResNet18 モデルを TorchScript モデルに変換して保存します。
import torch import torchvision model = torchvision.models.resnet18(pretrained=True) # Switch the model to eval model // モデルを評価モデルに切り替えます。 model.eval() # An example input you would normally provide to your model's forward() method. // 通常、モデルの forward() メソッドに提供する入力例。 dummy_input = torch.rand(1, 3, 224, 224) # Use torch.jit.trace to generate a torch.jit.ScriptModule via tracing. // torch.jit.trace を使用して、トレースを介して torch.jit.ScriptModule を生成します。 traced_script_module = torch.jit.trace(model, dummy_input) # Save the TorchScript model // TorchScript モデルを保存します。 traced_script_module.save("resnet18.pt")パラメーター
説明
model_nameモデルの名前。
model_platformモデルで使用されるプラットフォームまたはフレームワーク。例:
TorchScript、ONNX。model_pathモデルが保存されているパス。
inputs入力パラメーター。
outputs出力パラメーター。
モデルの変換後、モデル構成ファイル
resnet18.ptを OSS にアップロードします。構成ファイルの OSS パスはoss://bucketname/models/resnet18/resnet18.ptです。詳細については、「オブジェクトをアップロードする」をご参照ください。
ステップ 2: ベンチマークを実行する
本番環境にモデルをデプロイする前に、ベンチマークを実行してモデルのパフォーマンスを評価できます。このステップでは、Arena でベンチマークジョブが送信され、クラスターの default 名前空間にある oss-pvc という名前の PVC を例として使用します。詳細については、「静的にプロビジョニングされた OSS ボリュームをマウントする」をご参照ください。
モデルの構成ファイルを準備してアップロードします。
モデルの構成ファイルを作成します。この例では、構成ファイルの名前は
config.jsonです。{ "model_name": "resnet18", "model_platform": "torchscript", "model_path": "/data/models/resnet18/resnet18.pt", "inputs": [ { "name": "input", // 入力 "data_type": "float32", "shape": [1, 3, 224, 224] } ], "outputs": [ // 出力 { "name": "output", // 出力 "data_type": "float32", "shape": [ 1000 ] } ] }構成ファイルを OSS にアップロードします。構成ファイルの OSS パスは
oss://bucketname/models/resnet18/config.jsonです。
次のコマンドを実行して、ベンチマークジョブを ACK Pro マネージドクラスターに送信します。
arena model analyze benchmark \ --name=resnet18-benchmark \ --namespace=default \ --image=registry.cn-beijing.aliyuncs.com/kube-ai/easy-inference:1.0.2 \ --gpus=1 \ --data=oss-pvc:/data \ --model-config-file=/data/models/resnet18/config.json \ --report-path=/data/models/resnet18 \ --concurrency=5 \ --duration=60パラメーター
説明
--gpus使用される GPU の数。
--dataクラスターの PVC と、PVC がマウントされるパス。
--model-config-file構成ファイルのパス。
--report-pathベンチマークレポートが保存されるパス。
--concurrency同時リクエストの数。
--durationベンチマークジョブの期間。単位: 秒。
重要--requestsパラメーターと--durationパラメーターを同時に指定することはできません。ベンチマークジョブを送信するときは、どちらか一方のみを指定してください。両方を指定した場合、システムはデフォルトで--durationパラメーターを使用します。ベンチマークジョブによって送信されるリクエストの総数を指定するには、
--requestsパラメーターを指定します。
次のコマンドを実行して、ジョブのステータスをクエリします。
arena model analyze list -A予期される出力:
NAMESPACE NAME STATUS TYPE DURATION AGE GPU(Requested) // 名前空間、名前、ステータス、タイプ、期間、経過時間、GPU (リクエスト済み) default resnet18-benchmark COMPLETE Benchmark 0s 2d 1 // デフォルト、resnet18-benchmark、完了、ベンチマーク、0 秒、2 日、1STATUSパラメーターにCOMPLETEと表示されている場合は、ベンチマークジョブは完了です。その後、--report-pathパラメーターで指定されたパスにbenchmark_result.txtという名前のベンチマークレポートがあります。ベンチマークレポートを表示します。予期される出力:
{ "p90_latency":7.511, // 90 パーセンタイルレイテンシ "p95_latency":7.86, // 95 パーセンタイルレイテンシ "p99_latency":9.34, // 99 パーセンタイルレイテンシ "min_latency":7.019, // 最小レイテンシ "max_latency":12.269, // 最大レイテンシ "mean_latency":7.312, // 平均レイテンシ "median_latency":7.206, // 中央値レイテンシ "throughput":136, // スループット "gpu_mem_used":1.47, // GPU メモリ使用量 "gpu_utilization":21.280 // GPU 使用率 }次の表は、ベンチマークレポートに含まれるメトリックを示しています。
メトリック
説明
単位
p90_latency
90 パーセンタイル応答時間
ミリ秒
p95_latency
95 パーセンタイル応答時間
ミリ秒
p99_latency
99 パーセンタイル応答時間
ミリ秒
min_latency
最速応答時間
ミリ秒
max_latency
最も遅い応答時間
ミリ秒
mean_latency
平均応答時間
ミリ秒
median_latency
中央応答時間
ミリ秒
throughput
スループット
回数
gpu_mem_used
GPU メモリ使用量
GB
gpu_utilization
GPU 使用率
パーセンテージ
ステップ 3: モデルを分析する
ベンチマークを実行した後、arena model analyze profile コマンドを実行してモデルを分析し、パフォーマンスボトルネックを特定できます。
次のコマンドを実行して、モデル分析ジョブを ACK Pro マネージドクラスターに送信します。
arena model analyze profile \ --name=resnet18-profile \ --namespace=default \ --image=registry.cn-beijing.aliyuncs.com/kube-ai/easy-inference:1.0.2 \ --gpus=1 \ --data=oss-pvc:/data \ --model-config-file=/data/models/resnet18/config.json \ --report-path=/data/models/resnet18/log/ \ --tensorboard \ --tensorboard-image=registry.cn-beijing.aliyuncs.com/kube-ai/easy-inference:1.0.2パラメーター
説明
--gpus使用される GPU の数。
--dataクラスターの PVC と、PVC がマウントされるパス。
--model-config-file構成ファイルのパス。
--report-path分析レポートが保存されるパス。
--tensorboardTensorBoard で分析レポートを表示するかどうかを指定します。
--tensorboard-imageTensorboard のデプロイに使用されるイメージの URL。
次のコマンドを実行して、ジョブのステータスをクエリします。
arena model analyze list -A予期される出力:
NAMESPACE NAME STATUS TYPE DURATION AGE GPU(Requested) // 名前空間、名前、ステータス、タイプ、期間、経過時間、GPU (リクエスト済み) default resnet18-profile COMPLETE Profile 13s 2d 1 // デフォルト、resnet18-profile、完了、プロファイル、13 秒、2 日、1次のコマンドを実行して、TensorBoard のステータスをクエリします。
kubectl get service -n default予期される出力:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE // 名前、タイプ、クラスター IP、外部 IP、ポート、経過時間 resnet18-profile-tensorboard NodePort 172.16.158.170 <none> 6006:30582/TCP 2d20h // resnet18-profile-tensorboard、NodePort、172.16.158.170、<なし>、6006:30582/TCP、2 日 20 時間次のコマンドを実行して、ポートフォワーディングを有効にし、TensorBoard にアクセスします。
kubectl port-forward svc/resnet18-profile-tensorboard -n default 6006:6006予期される出力:
Forwarding from 127.0.X.X:6006 -> 6006 // 127.0.X.X:6006 から 6006 へ転送 Forwarding from [::1]:6006 -> 6006 // [::1]:6006 から 6006 へ転送ブラウザのアドレスバーに
http://localhost:6006と入力して、分析結果を表示します。左側のナビゲーションウィンドウで、[表示] をクリックして、複数のディメンションに基づいて分析結果を表示し、パフォーマンスボトルネックを特定します。分析結果に基づいてモデルを最適化できます。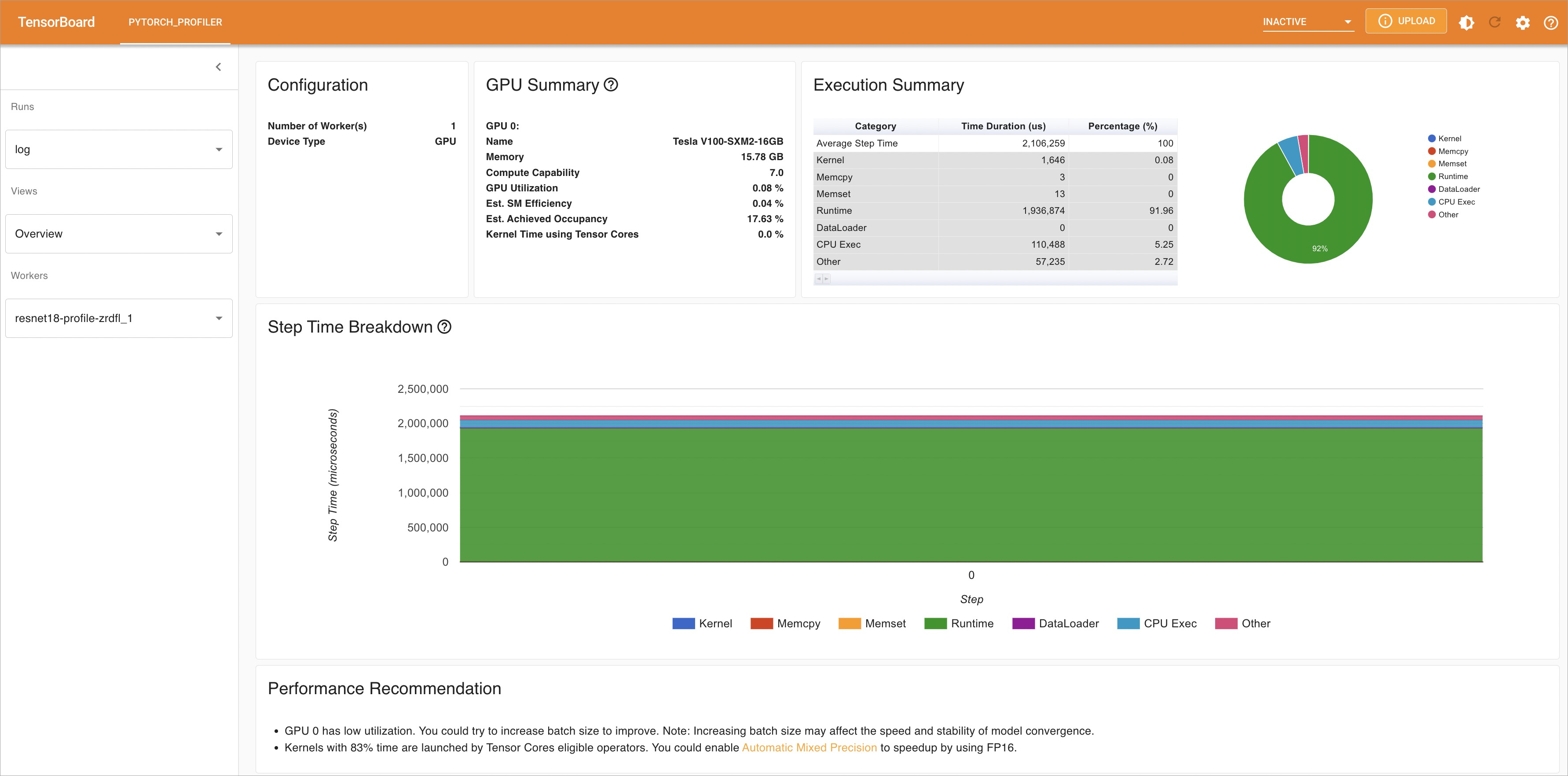
ステップ 4: モデルを最適化する
Arena を使用してモデルを最適化できます。
次のコマンドを実行して、モデル最適化ジョブを ACK Pro マネージドクラスターに送信します。
arena model analyze optimize \ --name=resnet18-optimize \ --namespace=default \ --image=registry.cn-beijing.aliyuncs.com/kube-ai/easy-inference:1.0.2 \ --gpus=1 \ --data=oss-pvc:/data \ --optimizer=tensorrt \ --model-config-file=/data/models/resnet18/config.json \ --export-path=/data/models/resnet18パラメーター
説明
--g` data-tag="code">--gpusご質問がある場合は、support@example.com にお問い合わせください。
--dataクラスターの PVC と、PVC がマウントされるパス。
--optimizer最適化手法。有効な値:
tensorrt(デフォルト)aiacc-torch。
--model-config-file構成ファイルのパスです。
--export-path最適化されたモデルが保存されているパスです。
次のコマンドを実行して、ジョブのステータスをクエリします。
arena model analyze list -A予想される出力:
NAMESPACE NAME STATUS TYPE DURATION AGE GPU(Requested) default resnet18-optimize COMPLETE Optimize 16s 2d 1最適化済みモデルの構成ファイルを表示します。
STATUSパラメーターにCOMPLETEと表示されている場合、最適化ジョブは完了しています。その後、--export-pathパラメーターで指定されたパスにopt_resnet18.ptという名前の構成ファイルがあります。ベンチマーク ジョブの
--model_pathパラメーターの値を、前のステップで取得した構成ファイルのパスに変更し、ベンチマークを再度実行します。ベンチマークの実行方法の詳細については、「ステップ 2:ベンチマークを実行する」をご参照ください。次の表は、モデルの最適化前後のメトリック値を示しています。
メトリック
最適化前
最適化後
p90_latency
7.511 ミリ秒
5.162 ミリ秒
p95_latency
7.86 ミリ秒
5.428 ミリ秒
p99_latency
9.34 ミリ秒
6.64 ミリ秒
min_latency
7.019 ミリ秒
4.827 ミリ秒
max_latency
12.269 ミリ秒
8.426 ミリ秒
mean_latency
7.312 ミリ秒
5.046 ミリ秒
median_latency
7.206 ミリ秒
4.972 ミリ秒
スループット
136 回
198 回
gpu_mem_used
1.47 GB
1.6 GB
gpu_utilization
21.280%
10.912%
統計によると、最適化後、モデルのパフォーマンスと GPU 使用率が大幅に向上しています。モデルがまだパフォーマンス要件を満たしていない場合は、前の手順を繰り返してモデルを分析および最適化できます。
ステップ 5: モデルをデプロイする
モデルがパフォーマンス要件を満たしている場合は、モデルをオンライン サービスとしてデプロイできます。Arena では、NVIDIA Triton Inference Server を使用して TorchScript モデルをデプロイできます。詳細については、「Nvidia Triton Server」をご参照ください。
config.pbtxtという名前の構成ファイルを作成します。重要ファイル名は変更しないでください。
name: "resnet18" platform: "pytorch_libtorch" max_batch_size: 1 default_model_filename: "opt_resnet18.pt" input [ { name: "input__0" format: FORMAT_NCHW data_type: TYPE_FP32 dims: [ 3, 224, 224 ] } ] output [ { name: "output__0", data_type: TYPE_FP32, dims: [ 1000 ] } ]説明構成ファイルのパラメーターの詳細については、「モデルリポジトリ」をご参照ください。
OSS で次のディレクトリ構造を作成します。
oss://bucketname/triton/model-repository/ resnet18/ config.pbtxt 1/ opt_resnet18.pt説明1/は、NVIDIA Triton Inference Server の規則です。この値は、モデルのバージョン番号を示します。モデルリポジトリには、さまざまなバージョンのモデルを格納できます。詳細については、「モデルリポジトリ」をご参照ください。Arena を使用してモデルをデプロイします。モデルは、GPU 共有モードまたは GPU 排他モードでデプロイできます。
GPU 排他モード: このモードは、高い安定性を必要とする推論サービスをデプロイするために使用できます。このモードでは、各 GPU は 1 つのモデルのみを高速化します。モデルは GPU リソースを競合しません。次のコマンドを実行して、GPU 排他モードでモデルをデプロイできます。
arena serve triton \ --name=resnet18-serving \ --gpus=1 \ --replicas=1 \ --image=nvcr.io/nvidia/tritonserver:21.05-py3 \ --data=oss-pvc:/data \ --model-repository=/data/triton/model-repository \ --allow-metrics=trueGPU 共有モード: このモードは、ロングテール推論サービスや費用対効果の高い推論サービスをデプロイするために使用できます。このモードでは、GPU は複数のモデルで共有されます。各モデルは、指定された量の GPU メモリのみを使用できます。次のコマンドを実行して、GPU 共有モードでモデルをデプロイできます。
GPU 共有モードでモデルをデプロイする場合は、
--gpumemoryパラメーターを設定する必要があります。このパラメーターは、各ポッドに割り当てられるメモリの量を指定します。ベンチマーク結果のgpu_mem_usedメトリックに基づいて適切な値を指定できます。たとえば、gpu_mem_usedメトリックの値が 1.6 GB の場合は、--gpumemoryパラメーターを 2 GB に設定できます。このパラメーターの値は正の整数である必要があります。arena serve triton \ --name=resnet18 \ --gpumemory=2 \ --replicas=1 \ --image=nvcr.io/nvidia/tritonserver:21.12-py3 \ --data=oss-pvc:/data \ --model-repository=/data/triton/model-repository \ --allow-metrics=true
次のコマンドを実行して、デプロイメントのステータスをクエリします。
arena serve list -A予想される出力:
NAMESPACE NAME TYPE VERSION DESIRED AVAILABLE ADDRESS PORTS GPU default resnet18-serving Triton 202202141817 1 1 172.16.147.248 RESTFUL:8000,GRPC:8001 1AVAILABLEパラメーターの値がDESIREDパラメーターの値と等しい場合、モデルはデプロイされています。