This document explains how to tune the Qwen model in Alibaba Cloud Model Studio using the API (HTTP) and the command line (shell). Model tuning includes three methods: supervised fine-tuning (SFT), continual pre-training (CPT), and Direct Preference Optimization (DPO).
Prerequisites
You have read Introduction to model fine-tuning and understand its concepts, process, and data format requirements.
You have activated the service and obtained an API key as described in Get an API key.
You must grant the RAM user (RAM user) the necessary invocation, training, and deployment permissions.
Training jobs created using the API support only token-based billing. To use model training units (prepaid or postpaid), create the job in the console.
Upload a tuning file
Prepare a fine-tuning file
SFT training set
The SFT training set uses the ChatML (Chat Markup Language) format, which supports multi-turn conversation and various role settings.
OpenAI'snameandweightparameters are not supported. All assistant outputs are trained.
# A single line of training data (JSON format) has the following structure:
{"messages": [
{"role": "system", "content": "System input 1"},
{"role": "user", "content": "User input 1"},
{"role": "assistant", "content": "Expected model output 1"},
{"role": "user", "content": "User input 2"},
{"role": "assistant", "content": "Expected model output 2"}
...
]}For an explanation of the system, user, and assistant roles, see Overview. For dataset examples, see SFT-ChatML-format-example.jsonl and SFT-ChatML-format-example.xlsx (XLS and XLSX formats support only single-turn conversations).
All assistant rows in a single training data entry support the "loss_weight" parameter, which is used to set the relative importance of that row during training. (The valid range is 0.0 to 1.0, and a larger value indicates higher importance.)
This is an invitation-only parameter. To use it, please contact your account manager.
{"role": "assistant", "content": "Expected model output 1", "loss_weight": 1.0},
{"role": "assistant", "content": "Expected model output 2", "loss_weight": 0.5}You can also download a data template from the Model Studio console. |
|
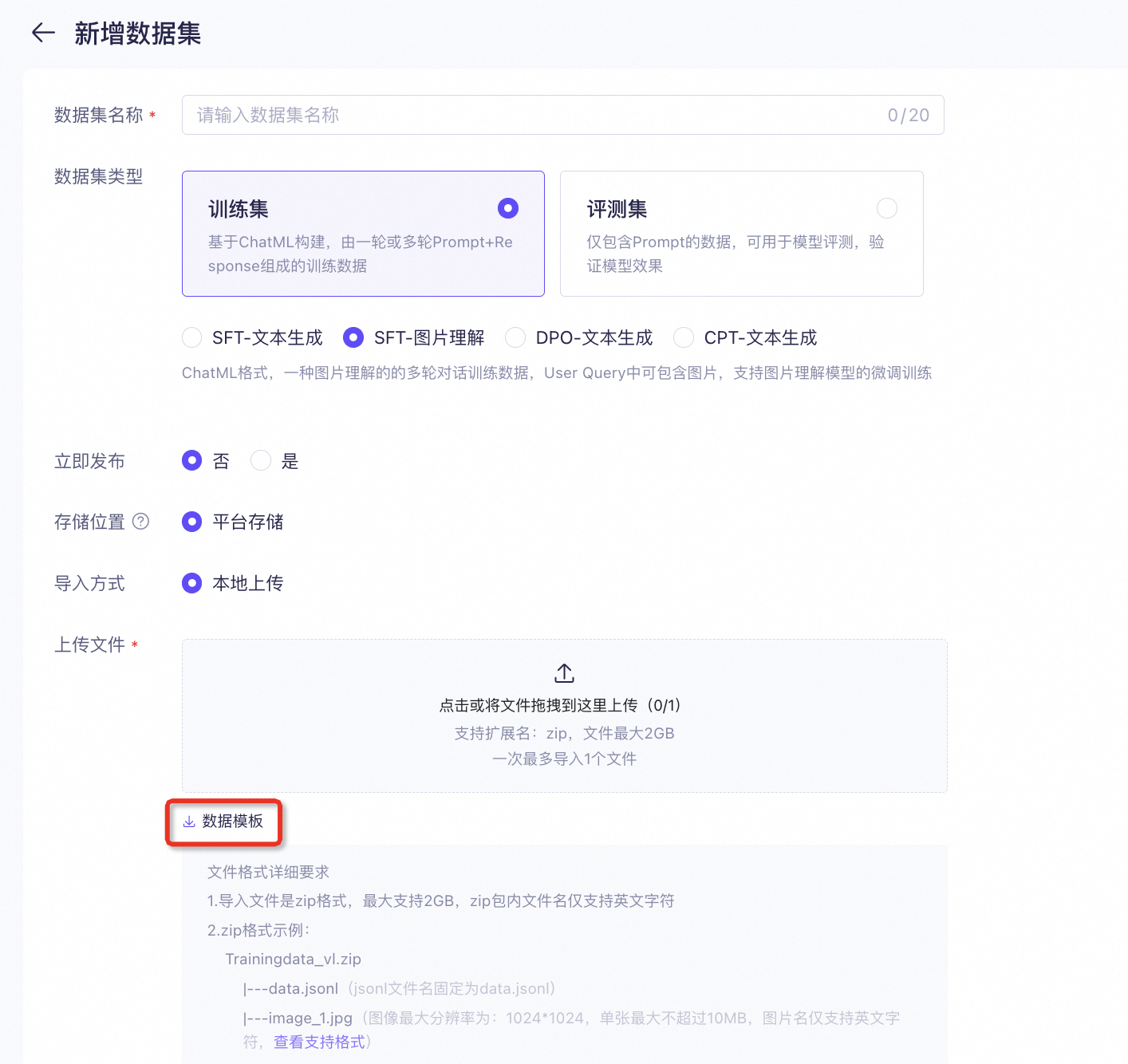
Upload a fine-tuning file to Model Studio
OpenAI-compatible file API
import os
from pathlib import Path
from openai import OpenAI
client = OpenAI(
# If you have not configured an environment variable, replace the following line with api_key="sk-xxx" and use your Model Studio API key.
# API keys for the Singapore and China (Beijing) regions are different. Get an API key: https://www.alibabacloud.com/help/en/model-studio/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
# The following is the URL for the Singapore region. If you use a service in the China (Beijing) region, replace the URL with: https://dashscope.aliyuncs.com/compatible-mode/v1
base_url="https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/compatible-mode/v1",
)
# test.jsonl is a local sample file.
file_object = client.files.create(file=Path("test.jsonl"), purpose="fine-tune")
print(file_object.model_dump_json())import com.openai.client.OpenAIClient;
import com.openai.client.okhttp.OpenAIOkHttpClient;
import com.openai.models.files.*;
import java.nio.file.Path;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) {
// Create a client and use the API key from the environment variable.
OpenAIClient client = OpenAIOkHttpClient.builder()
// API keys for the Singapore and China (Beijing) regions are different. Get an API key: https://www.alibabacloud.com/help/en/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
// The following is the URL for the Singapore region. If you use a service in the China (Beijing) region, replace the URL with: https://dashscope.aliyuncs.com/compatible-mode/v1
.baseUrl("https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/compatible-mode/v1")
.build();
// Set the file path. Modify the path and filename as needed.
Path filePath = Paths.get("src/main/java/org/example/test.txt");
// Create file upload parameters.
FileCreateParams params = FileCreateParams.builder()
.file(filePath)
.purpose(FilePurpose.of("fine-tune"))
.build();
// Upload the file.
FileObject fileObject = client.files().create(params);
System.out.println(fileObject);
}
}# ======= Important =======
# API keys for the Singapore and China (Beijing) regions are different. Get an API key: https://www.alibabacloud.com/help/en/model-studio/get-api-key
# The following is the URL for the Singapore region. If you use a service in the China (Beijing) region, replace the URL with: https://dashscope.aliyuncs.com/compatible-mode/v1/files
# === Delete this comment before running ===
curl -X POST https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/compatible-mode/v1/files \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
--form 'file=@"test.jsonl"' \
--form 'purpose="fine-tune"'Usage limits:
The maximum size of a single file is 300 MB.
The total storage for all non-deleted files is limited to 5 GB.
The total number of non-deleted files is limited to 100.
There is no time limit on file storage.
Model fine-tuning
Create a fine-tuning job
HTTP
For Windows CMD, replace${DASHSCOPE_API_KEY}with%DASHSCOPE_API_KEY%. For PowerShell, replace it with$env:DASHSCOPE_API_KEY.
curl --location "https://dashscope.aliyuncs.com/api/v1/fine-tunes" \
--header "Authorization: Bearer ${DASHSCOPE_API_KEY}" \
--header 'Content-Type: application/json' \
--data '{
"model":"qwen3-8b",
"training_file_ids":[
"<your_training_file_id_1>",
"<your_training_file_id_2>"
],
"hyper_parameters":
{
"n_epochs": 3,
"batch_size": 16,
"max_length": 8192,
"learning_rate": "1.6e-5",
"lr_scheduler_type": "linear",
"split": 0.9,
"warmup_ratio": 0.05,
"eval_steps": 50,
"data_augmentation": true,
"augmentation_ratio": "0.1,0.05,0.15",
"augmentation_types": "dialogue_CN,general_purpose_CN,NLP",
"save_strategy": "epoch",
"save_total_limit": 10
},
"training_type":"sft"
}'Input parameters
Parameter | Required | Type | Location | Description |
training_file_ids | Yes | Array | Body | A list of file IDs for the training set. |
validation_file_ids | No | Array | Body | A list of file IDs for the validation set. |
model | Yes | String | Body | The ID of the base model to fine-tune, or the ID of a model from a previous fine-tuning job. |
hyper_parameters | No | Map | Body | Hyperparameters for the fine-tuning job. Supported parameters and their default values vary by model. Go to the console and select the same model and training method to view the default values. The following parameters affect the training cost and are required: |
training_type | No | String | Body | The fine-tuning method. Valid values are:
|
job_name | No | String | Body | The name of the fine-tuning job. |
model_name | No | String | Body | The name of the fine-tuned model. This is not the model ID, which is generated by the system. |
Sample response
{
"request_id": "635f7047-003e-4be3-b1db-6f98e239f57b",
"output":
{
"job_id": "ft-202511272033-8ae7",
"job_name": "ft-202511272033-8ae7",
"status": "PENDING",
"finetuned_output": "qwen3-8b-ft-202511272033-8ae7",
"model": "qwen3-8b",
"base_model": "qwen3-8b",
"training_file_ids":
[
"9e9ffdfa-c3bf-436e-9613-6f053c66aa6e"
],
"validation_file_ids":
[],
"hyper_parameters":
{
"n_epochs": 3,
"batch_size": 16,
"max_length": 8192,
"learning_rate": "1.6e-5",
"lr_scheduler_type": "linear",
"split": 0.9,
"warmup_ratio": 0.05,
"eval_steps": 50,
"data_augmentation": true,
"augmentation_ratio": "0.1,0.05,0.15",
"augmentation_types": "dialogue_CN,general_purpose_CN,NLP",
"save_strategy": "epoch",
"save_total_limit": 10
},
"training_type": "sft",
"create_time": "2025-11-27 20:33:15",
"workspace_id": "llm-8v53etv3hwb8orx1",
"user_identity": "1654290265984853",
"modifier": "1654290265984853",
"creator": "1654290265984853",
"group": "llm",
"max_output_cnt": 10
}
}Supported base model IDs (model) and training types (training_type)
hyper_parameters: Supported settings
Query job details
To query the job status, use the job_id returned when you create the job.
HTTP
curl 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<job_id>' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json'Request parameters
Parameter | Type | Location | Required | Description |
job_id | String | Path | Yes | The ID of the fine-tuning job to query. |
Successful response
{
"request_id": "d100cddb-ac85-4c82-bd5c-9b5421c5e94d",
"output":
{
"job_id": "ft-202511272033-8ae7",
"job_name": "ft-202511272033-8ae7",
"status": "RUNNING",
"finetuned_output": "qwen3-8b-ft-202511272033-8ae7",
"model": "qwen3-8b",
"base_model": "qwen3-8b",
"training_file_ids":
[
"9e9ffdfa-c3bf-436e-9613-6f053c66aa6e"
],
"validation_file_ids":
[],
"hyper_parameters":
{
"n_epochs": 3,
"batch_size": 16,
"max_length": 8192,
"learning_rate": "1.6e-5",
"lr_scheduler_type": "linear",
"split": 0.9,
"warmup_ratio": 0.05,
"eval_steps": 50,
"data_augmentation": true,
"augmentation_ratio": "0.1,0.05,0.15",
"augmentation_types": "dialogue_CN,general_purpose_CN,NLP",
"save_strategy": "epoch",
"save_total_limit": 10
},
"training_type": "sft",
"create_time": "2025-11-27 20:33:15",
"workspace_id": "llm-8v53etv3hwb8orx1",
"user_identity": "1654290265984853",
"modifier": "1654290265984853",
"creator": "1654290265984853",
"group": "llm",
"max_output_cnt": 10
}
}Job status | Description |
PENDING | The job is waiting to start. |
QUEUING | The fine-tuning job is in the queue. Only one fine-tuning job can run at a time. |
RUNNING | The job is running. |
CANCELING | The job is being canceled. |
SUCCEEDED | The job succeeded. |
FAILED | The job failed. |
CANCELED | The job has been canceled. |
After a fine-tuning job succeeds, the finetuned_output field contains the resulting model ID. You can use this ID for model deployment.
Fine-tuning job logs
HTTP
curl 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<job_id>/logs?offset=0&line=1000' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json' Use theoffsetandlineparameters to retrieve a specific range of log lines. Theoffsetparameter sets the starting position for the log output, and thelineparameter sets the maximum number of lines to return.
Sample response:
{
"request_id":"1100d073-4673-47df-aed8-c35b3108e968",
"output":{
"total":57,
"logs":[
"{Log entry 1}",
"{Log entry 2}",
...
...
...
]
}
}Query and publish model checkpoints
Only SFT fine-tuning (efficient_sftandsft) supports saving and publishing model checkpoints from intermediate states.
List checkpoints for a fine-tuning job
curl 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<job_id>/checkpoints' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json'Request parameters
Parameter | Type | Parameter location | Required | Description |
job_id | String | Path | Yes | The ID of the fine-tuning job. |
Successful response example
checkpoint refers to the Checkpoint ID, which is used to specify the snapshot to publish in the Model Publishing (Optional) API. model_name refers to the model ID and can be used for model deployment. (finetuned_output outputs the model_name of the last checkpoint.)
{
"request_id": "c11939b5-efa6-4639-97ae-ed4597984647",
"output":
[
{
"create_time": "2025-11-11T16:25:42",
"full_name": "ft-202511272033-8ae7-checkpoint-20",
"job_id": "ft-202511272033-8ae7",
"checkpoint": "checkpoint-20",
"model_name": "qwen3-8b-instruct-ft-202511272033-8ae7",
"status": "SUCCEEDED"
}
]
}Status | Description |
PENDING | A checkpoint is pending publication and must be published using the Model Publishing API before you can perform Model Deployment & Invocation. |
PROCESSING | Checkpoint publishing is in progress. |
SUCCEEDED | The checkpoint has been published successfully. You can now use it for model deployment and invocation. |
FAILED | Checkpoint publishing failed. |
Model publishing (optional)
In Model Studio, you can export a checkpoint after a fine-tuning job completes. Only exported checkpoints can be deployed.
Exported checkpoints are stored in cloud storage. You cannot access or download them at this time.
curl --request GET 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<job_id>/export/<checkpoint_id>?model_name=<model_name>' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json'Request parameters
Parameter | Type | Parameter location | Required | Description |
job_id | String | Path | Yes | The ID of the fine-tuning job. |
checkpoint_id | String | Path | Yes | The ID of the checkpoint to publish. |
model_name | String | Path | Yes | The custom model ID to assign to the published model. |
Successful response example
{
"request_id": "ed3faa41-6be3-4271-9b83-941b23680537",
"output": true
}Publishing tasks are performed asynchronously. Use the Query Snapshot List API to monitor the snapshot publishing status.
More fine-tuning operations
List fine-tuning jobs
curl 'https://dashscope.aliyuncs.com/api/v1/fine-tunes' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json' Cancel fine-tuning job
Cancels a fine-tuning job that is in progress.
curl --request POST 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<job_id>/cancel' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json' Delete fine-tuning job
You cannot delete a fine-tuning job that is in progress.
curl --request DELETE 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<job_id>' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json' Model deployment and invocation
Model deployment
Go to the model deployment console to deploy the model.
Model invocation
When the deployment status is RUNNING, you can invoke the fine-tuned model just like any other model.
You can also go to the model deployment console to get the Model Code.
For more information about usage and parameter settings, see the DashScope API Reference.
curl 'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json' \
--data '{
"model": "<Replace with the model instance ID returned after the deployment job succeeds>",
"input":{
"messages":[
{
"role": "user",
"content": "Who are you?"
}
]
},
"parameters": {
"result_format": "message"
}
}'