Get independent, dedicated inference services for high concurrency, low latency, and other performance requirements.
This document applies only to the Chinese mainland (Beijing) region.
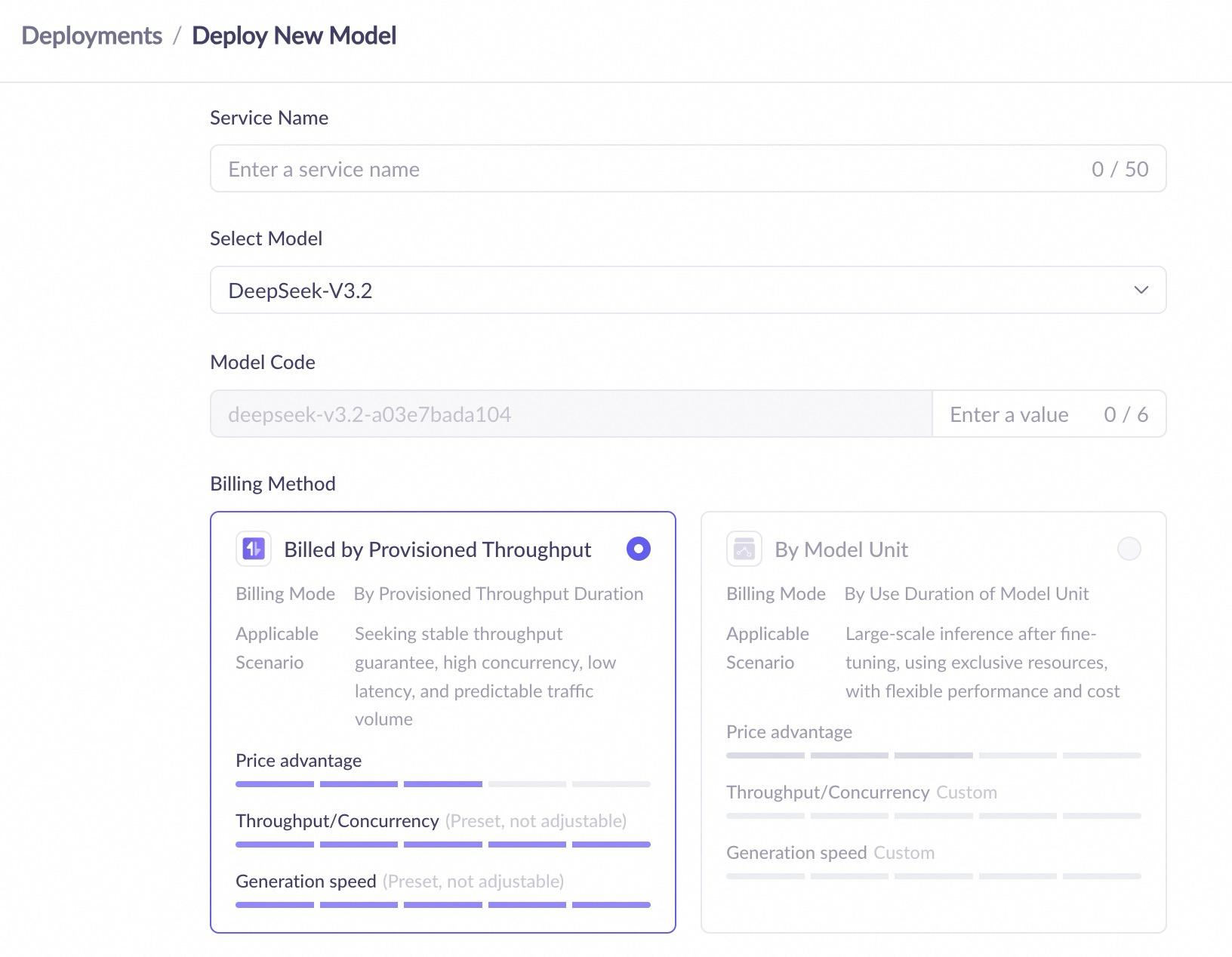
Billing methods
Before deployment, view the estimated hourly cost for different models on the Model Deployment console (Beijing).
You cannot change the billing method after service creation. To switch, unpublish the deployed model and then redeploy it.
Provisioned Throughput (PTU) (High throughput; high performance) | Model Unit (Whitelist open. Contact your account manager; customizable performance metrics; resource isolation; for fine-tuned models) | |||
Definition | A model deployment method that reserves platform resources to ensure a specific TPM throughput capacity. No speed limits within the guaranteed quota. | A model deployment method that configures computing power based on usage duration and the number of model units, with dedicated resources. | ||
Advantages |
|
| ||
Supported models | Some pre-built models | Fine-tuned models | ||
Scenarios |
|
| ||
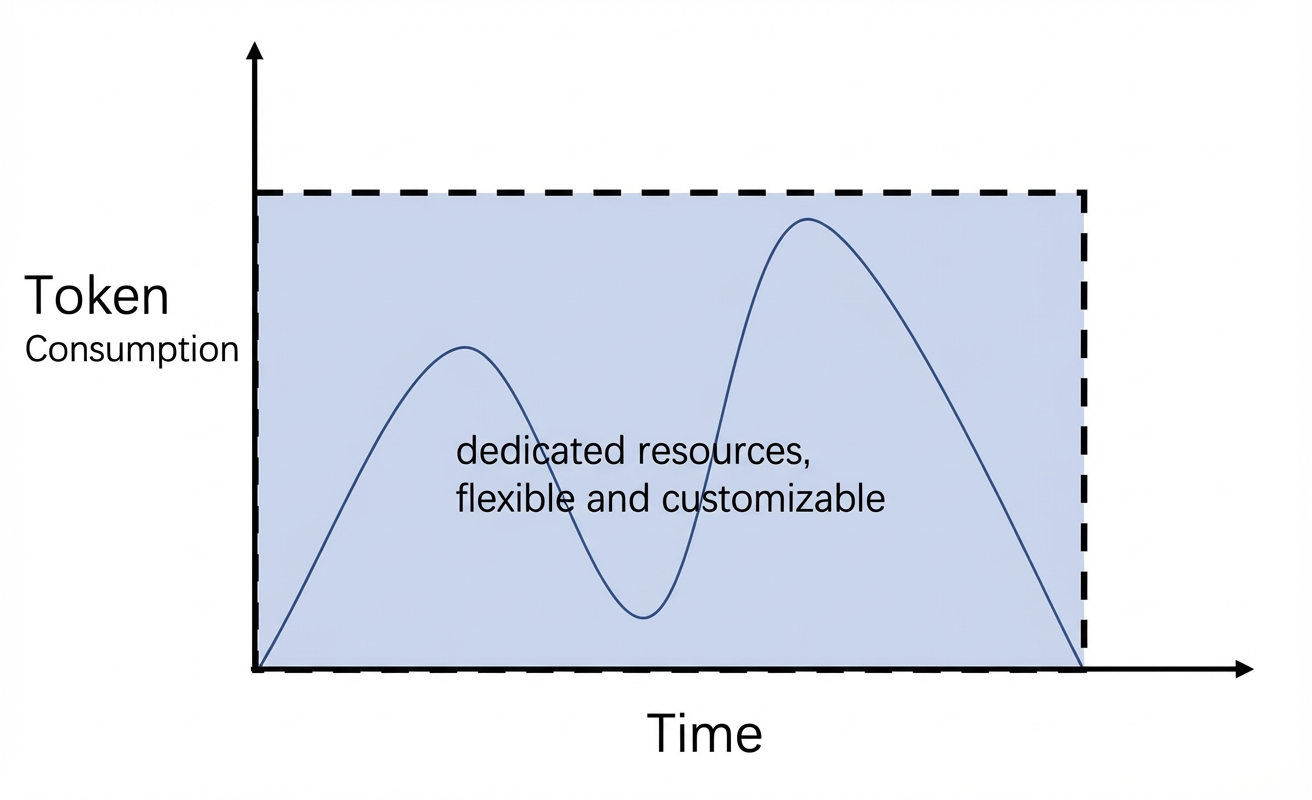
Billing diagram |
|
| ||
Billing method | Based on usage duration and provisioned throughput Pay-as-you-go, daily package | Based on usage duration and number of model units Pay-as-you-go, monthly package | ||
Scaling method | Self-service adjustment of throughput | Self-service adjustment of model unit quantity | ||
Product constraints |
| If you cancel an upfront purchase within the first month, the daily unit price is billed at 1.2 times the original rate. | ||
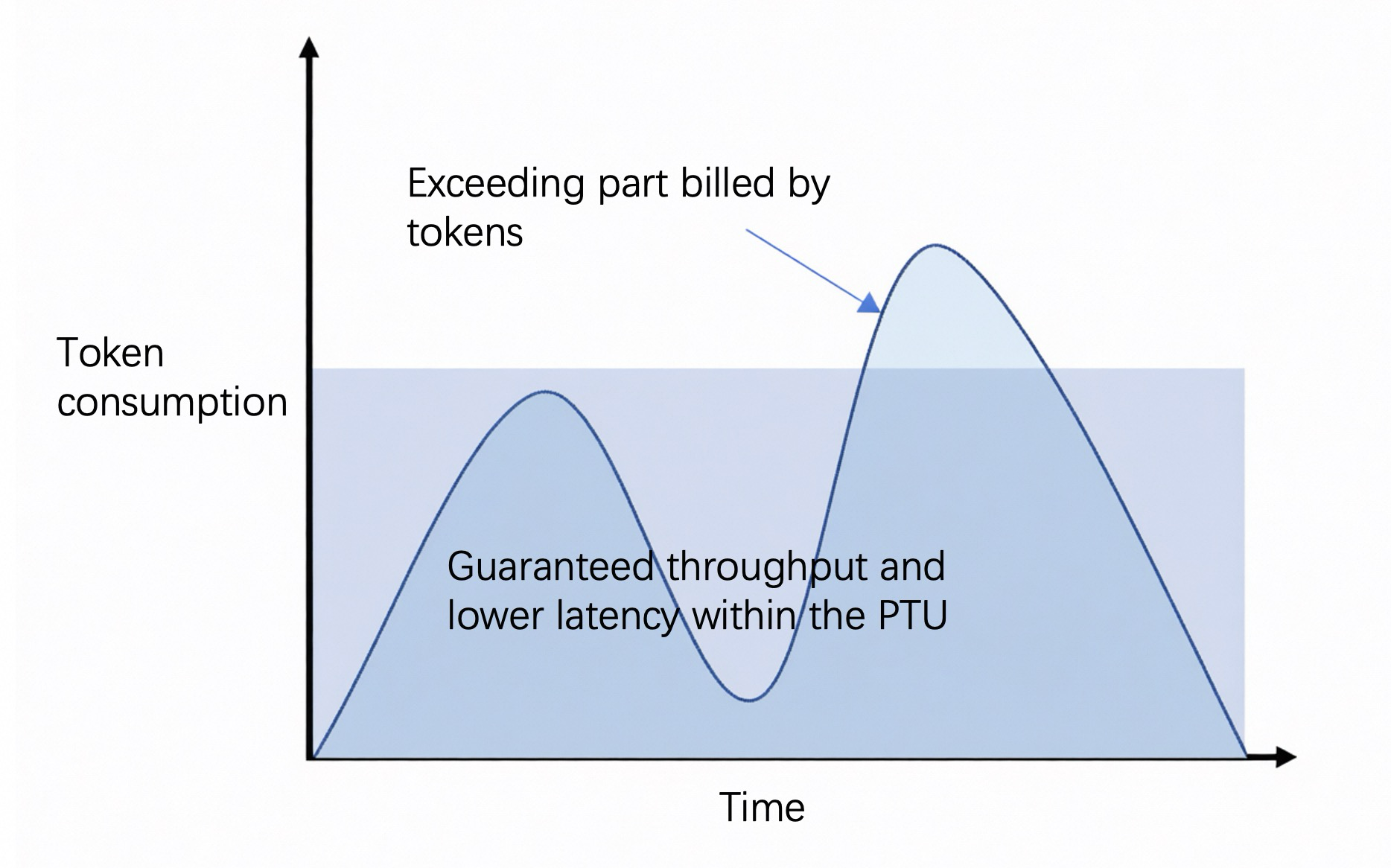
To view token usage and historical call statistics for a single call, go to Monitoring (Beijing).
Billing details
Billing by usage duration (Provisioned Throughput)
Cost = Usage Duration × (Input TPM Unit Price × Input TPM + Output TPM Unit Price × Output TPM)
Upfront payment orders take effect immediately upon payment. The validity period ends at 23:59 on day N. If you place an order after 22:00, the expiration date automatically extends by one day.
After an upfront payment order expires, the service stops after a 2 hour delay. Resources are retained for 14 hours after stopping, then they are released.
Upfront payment orders cannot be terminated early.
For pay-as-you-go billing, if your account has overdue payments, deployed resources are retained and continue to be billed for 24 hours, then they are automatically released.
If the model input exceeds the maximum input tokens or the purchased TPM (Tokens per Minute), calls automatically switch to pay-as-you-go model calls. Inference performance may decrease. Rate limiting occupies public traffic in the workspace. Costs are charged according to the pay-as-you-go model call standard.
In this case, the API call return header includes the following:
x-dashscope-ptu-overflow:true.For TPM statistics, go to Model Monitoring (Beijing).
Model name | Model type | Max context window (Input Tokens + Output Tokens) | Max input tokens | Pay-as-you-go - hourly | Upfront—per day | ||
Input (per 10k TPM) | Output (per 1k TPM) | Input (per 10k TPM) | Output (per 1k TPM) | ||||
Qwen3-max-2025-09-23 | Instruct | 128,000 | 128,000 | $1.11 | $0.45 | $13.32 | $5.40 |
Qwen-plus-2025-12-01 | Instruct | $0.28 | $0.07 | $3.36 | $0.84 | ||
Thinking | $0.28 | $3.36 | |||||
Qwen-flash-2025-07-28 | Instruct/Thinking | $0.06 | $0.06 | $0.72 | $0.72 | ||
Qwen3-vl-plus-2025-09-23 | Instruct/Thinking | $0.35 | $0.35 | $4.20 | $4.20 | ||
DeepSeek-v3.2 | Instruct/Thinking | 64,000 | $1.04 | $0.16 | $12.48 | $1.92 | |
Model types:
Instruct - The model performs inference in non-thinking mode after deployment.
Thinking - The model performs inference in thinking mode after deployment.
Billing by usage duration (Model Unit)
Cost = Usage Duration (hours) × Number of Model Units × Model Unit Price
If you cancel an upfront purchase within the first month, the daily unit price is billed at 1.2 times the original rate.
Model unit computing power resources for pay-as-you-go are allocated on a first-come, first-served basis. If a purchase fails, you receive a full refund.
Qwen
Model name | Model type | Rate limiting | Model unit specification | Max context window | Unit price (billed per minute for less than 1 minute) | Monthly unit price (billed per day for less than 1 day) (If you cancel an upfront purchase within the first month, the daily unit price is billed at 1.2 times the original rate.) |
Qwen3-14B | Instruct | Type I Model Unit (MU1) | Fixed at: See qwen-3 | $40/hour | $18,800/month | |
Qwen3-32B | Instruct | Type I Model Unit (MU1) | Fixed at: See qwen-3 | $40/hour | $18,800/month |
Model types:
Instruct - The model performs inference in non-thinking mode after deployment.
Qwen-VL
Model name | Model type | Rate limiting | Model unit specification | Max context window | Unit price (billed per minute for less than 1 minute) | Monthly unit price (billed per day for less than 1 day) (If you cancel an upfront purchase within the first month, the daily unit price is billed at 1.2 times the original rate.) |
Qwen3-VL-8B-Instruct | Instruct | Type I Model Unit (MU1) | Fixed at: | $20/hour | $9,400/month | |
Qwen3-VL-8B-Thinking | Thinking |
Model types:
Instruct - The model performs inference in non-thinking mode after deployment.
Thinking - The model performs inference in thinking mode after deployment.
To deploy more models, refer to this solution and select the most suitable deployment solution based on your specific business requirements.
Deployment methods
Deploy models in the console. Follow these steps:
If you encounter a permission error, see the following: What do I do if I get a permission error during deployment?
|
|
| |
Important You incur charges after successful model deployment. |
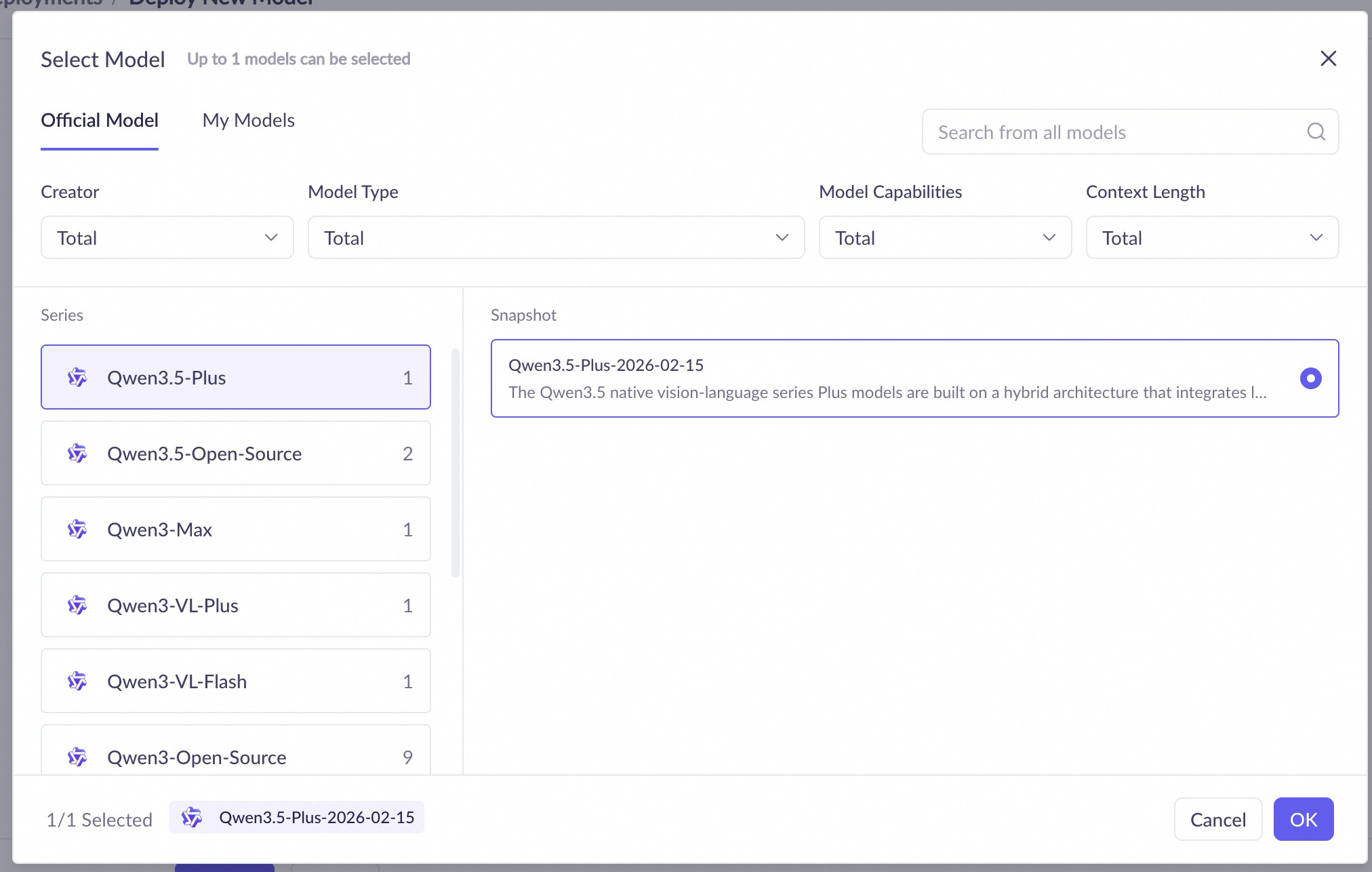
Deployment configuration
Model unit
Configuration | Details |
Configure model inference pattern | Some models let you configure the inference pattern and maximum context window when deployed as a Model Unit.
|
Maximum context window | Some models support this setting in Model Unit deployment mode. The maximum context window depends on the model type. |
Service throttling | Some models support this setting in Model Unit deployment mode. You can limit RPM and TPM for model calls. |
Call a deployed model
After you deploy a model, you can call it using the OpenAI-compatible interface, DashScope, or the Assistant SDK.
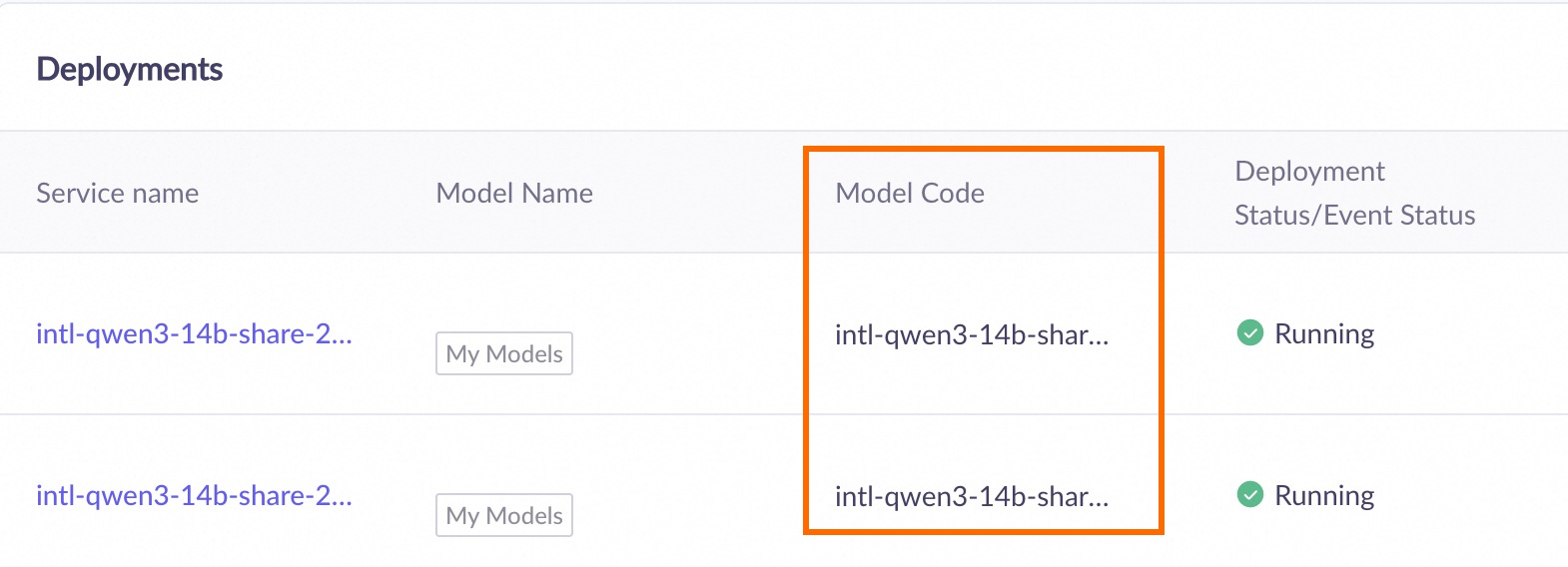
When you call a successfully deployed model, set the model parameter to the model code that appears after deployment. Go to the Deployment console (Beijing) to get the Model Code.
DashScope
import os
import dashscope
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"},
]
dashscope.base_http_api_url = 'https://dashscope-intl.aliyuncs.com/api/v1'
response = dashscope.Generation.call(
# If you have not set the environment variable, replace the next line with: api_key="sk-xxx"
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen3-max-xxx-xxx", # Replace with the model code from your successful deployment
messages=messages,
result_format="message",
enable_thinking=False,
)
print(response)
OpenAI-compatible interface
import os
from openai import OpenAI
client = OpenAI(
# If you have not set the environment variable, replace the next line with: api_key="sk-xxx"
api_key=os.getenv('DASHSCOPE_API_KEY'),
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-max-xxx-xxx", # Replace with the model code from your successful deployment
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"},
],
extra_body={"enable_thinking": False},
)
print(completion)
Scale your service
Provisioned throughput (by time): Click Scaling to adjust the number of instances manually.
Model unit (by time): Click Scaling to adjust the number of instances manually.
Unpublish a deployed service
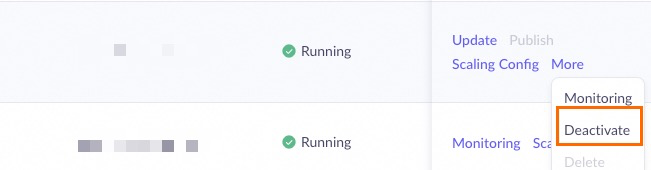
Go to the Deployment console (Beijing), find the deployed servic, click Deactivate, and confirm. Billing stops after unpublishing.
FAQ
Can I upload and deploy my own models?
Currently, you cannot upload and deploy your own models. We recommend that you follow the latest updates from Alibaba Cloud Model Studio.
Platform for AI (PAI) also lets you deploy your own models. For deployment methods, see Deploy large language models.
What if a permission error occurs during deployment?
If the message 'Missing permissions for this module' appears, ensure that your account is granted the 'ModelDeploy-FullAccess' permission on the permission management page for the workspace.
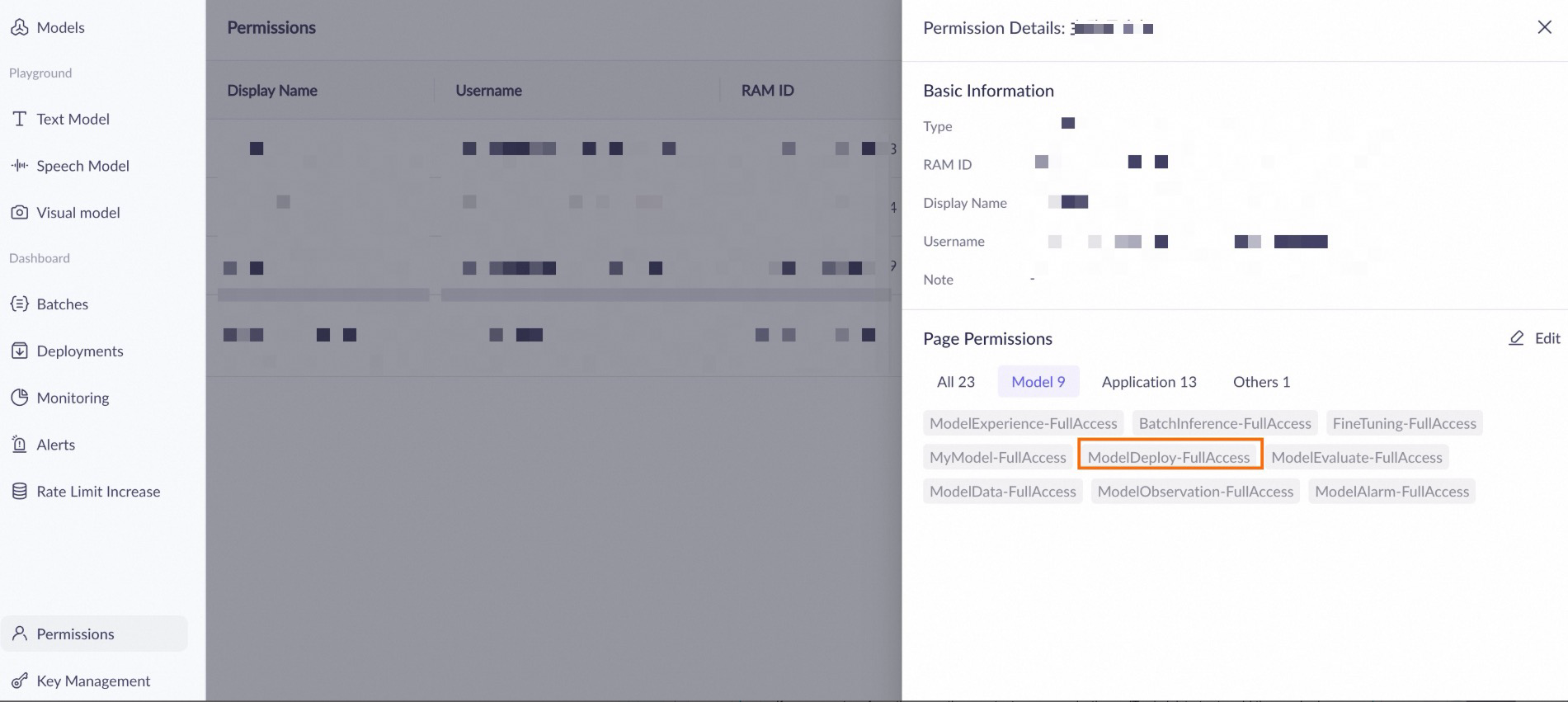
If you cannot perform the operation, contact your organization or IT administrator to add the required permissions or resolve the issue.
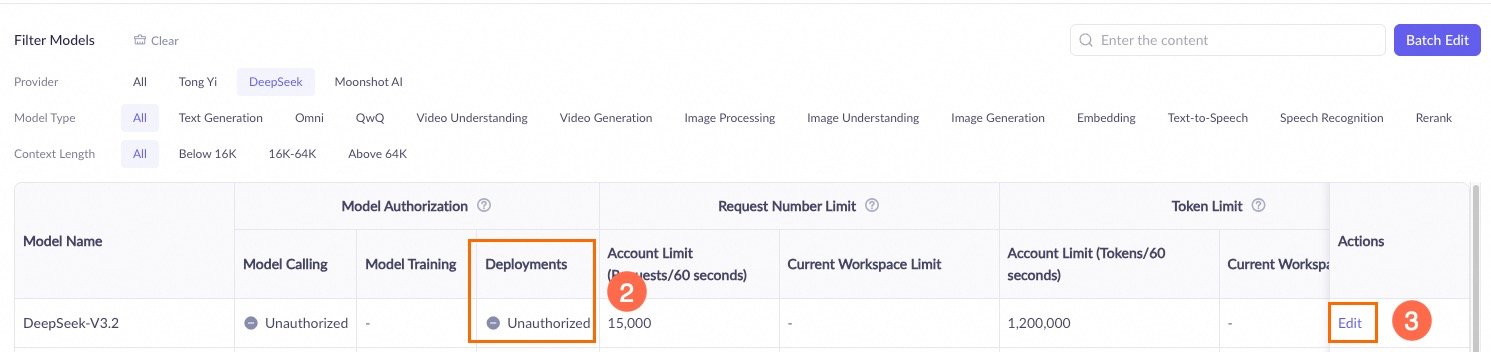
If the 'Workspace xx does not have permission to deploy model xx' error occurs during deployment, go to the Workspaces page in Model Studio and add the deployment permission for the model to the workspace.
API call error:
Workspace xxx does not have deployment privilege for model xxxx.
If a permission error occurs, contact your organization or IT administrator to add the required permissions or perform the operation for you.