This topic describes the business pain points that the near real-time data warehouse solution can address and its main architectural features.
Background information
As data processing scenarios become more complex, the display of updated data within seconds or row-level updates are not required in many business scenarios. Instead, minute-level or hour-level near-real-time data processing and batch processing of large amounts of data are required. MaxCompute provides Delta tables to meet your business requirements for the storage and processing of full and incremental data in near real time.
Current situation analysis
In low-timeliness business scenarios in which a large amount of data needs to be processed in batches, you can use MaxCompute to meet business requirements. In high-timeliness business scenarios in which second-level real-time data processing or streaming processing is required, you need to use a real-time data processing system or a streaming system to meet business requirements. In comprehensive business scenarios, such as the combination of minute-level or hour-level near-real-time data processing and batch processing of large amounts of data, specific issues may occur regardless of whether you use a single engine or multiple federated engines.
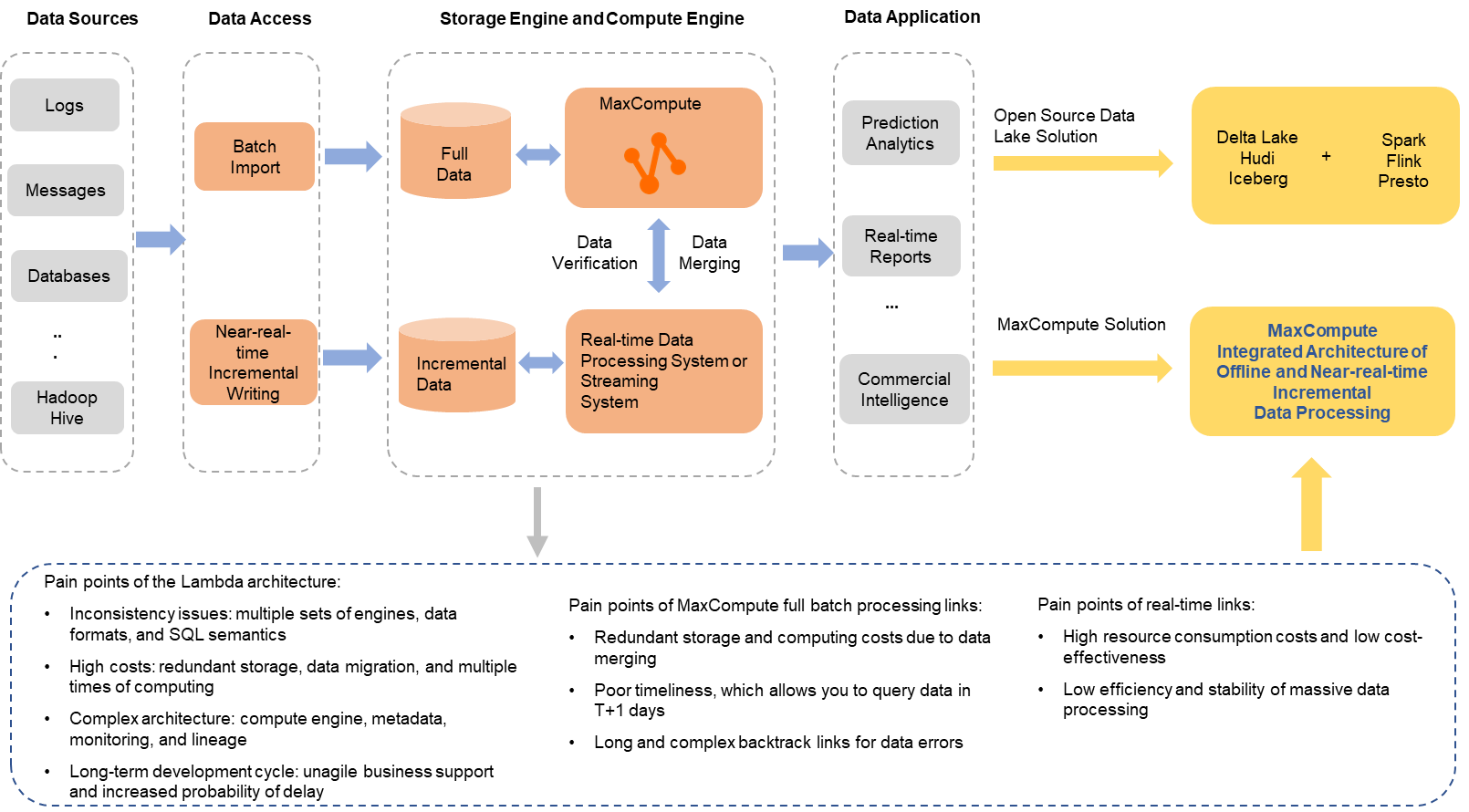
Specific issues may occur if you use only MaxCompute for batch processing in specific scenarios, as shown in the preceding figure. For example, if you use MaxCompute in scenarios in which minute-level incremental data and full data of users need to be continuously merged and stored, additional computing and storage costs are generated. If you use MaxCompute in scenarios in which complex data processing links and processing logic need to be converted into batch processing of data within T+1 days, the complexity of data processing links increases and the timeliness cannot meet business requirements. If you use only a real-time data processing system in the preceding scenarios, the resource costs are high, the cost efficiency is low, and the batch processing of large-scale data is unstable. In most cases, the Lambda architecture is used as a solution. In the Lambda architecture, MaxCompute is used for batch processing of full data, and a real-time data processing system is used for incremental data processing to meet high timeliness requirements. However, the Lambda architecture can cause known issues, such as data inconsistency between multiple sets of processing and storage engines, additional costs due to redundant storage and computing of multiple copies of data, a complex architecture, and a long-term development cycle.
To address the preceding issues, the big data open source ecosystem launched various solutions in recent years. The most popular solution is that the open source data processing engine Spark, Flink, or Presto is deeply integrated with the open source data lakes Hudi, Delta Lake, and Iceberg to implement a unified compute engine and data storage. This solution can help resolve a series of issues caused by the Lambda architecture. An incremental data storage and processing architecture is developed based on the architecture of MaxCompute. The architecture provides an integrated solution for batch data processing and near-real-time incremental data processing. The architecture maintains the cost-effectiveness of batch processing and meets the business requirements for minute-level incremental data reading, writing, and processing. The architecture can also provide practical features, such as the UPSERT operation and the time travel feature, to expand business scenarios. This helps reduce data computing, storage, and migration costs and improve user experience.
MaxCompute near real-time architecture
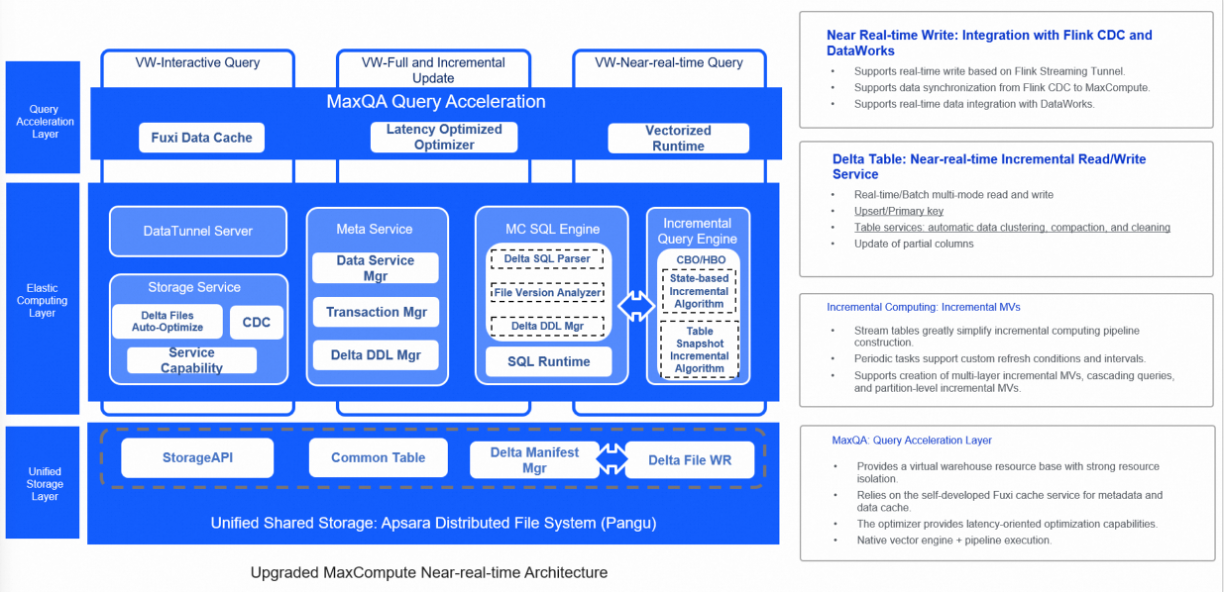
The preceding figure shows the new architecture in which MaxCompute efficiently supports the preceding comprehensive business scenarios. In the new architecture, MaxCompute supports various data sources to allow you to easily import incremental and full data to a unified storage system by using customized access tools. The background data management service automatically optimizes the data storage structure. A unified computing engine is used to support near-real-time incremental data processing and batch processing of large-scale data. A unified metadata service is used to support transaction management and file metadata management. The new architecture provides multiple benefits, including resolving issues that occur when only a batch processing system is used, such as redundant computing and storage and low timeliness, preventing the high resource consumption of real-time data processing systems or streaming systems, eliminating data inconsistency between multiple sets of systems in the Lambda architecture, and reducing the redundant storage cost of multiple copies of data and the cost of data migration between systems.
The end-to-end integrated architecture can meet the business requirements for computing and storage optimization of incremental data processing and minute-level timeliness, ensure the overall efficiency of batch processing, and effectively reduce resource costs.
Core features
MaxCompute near real-time data warehouse primarily provides three key functionalities: MC Delta Table that supports minute-level data import, incremental computation capabilities that better balance latency and throughput, and the newly upgraded MCQA2.0 that enables second-level query response.
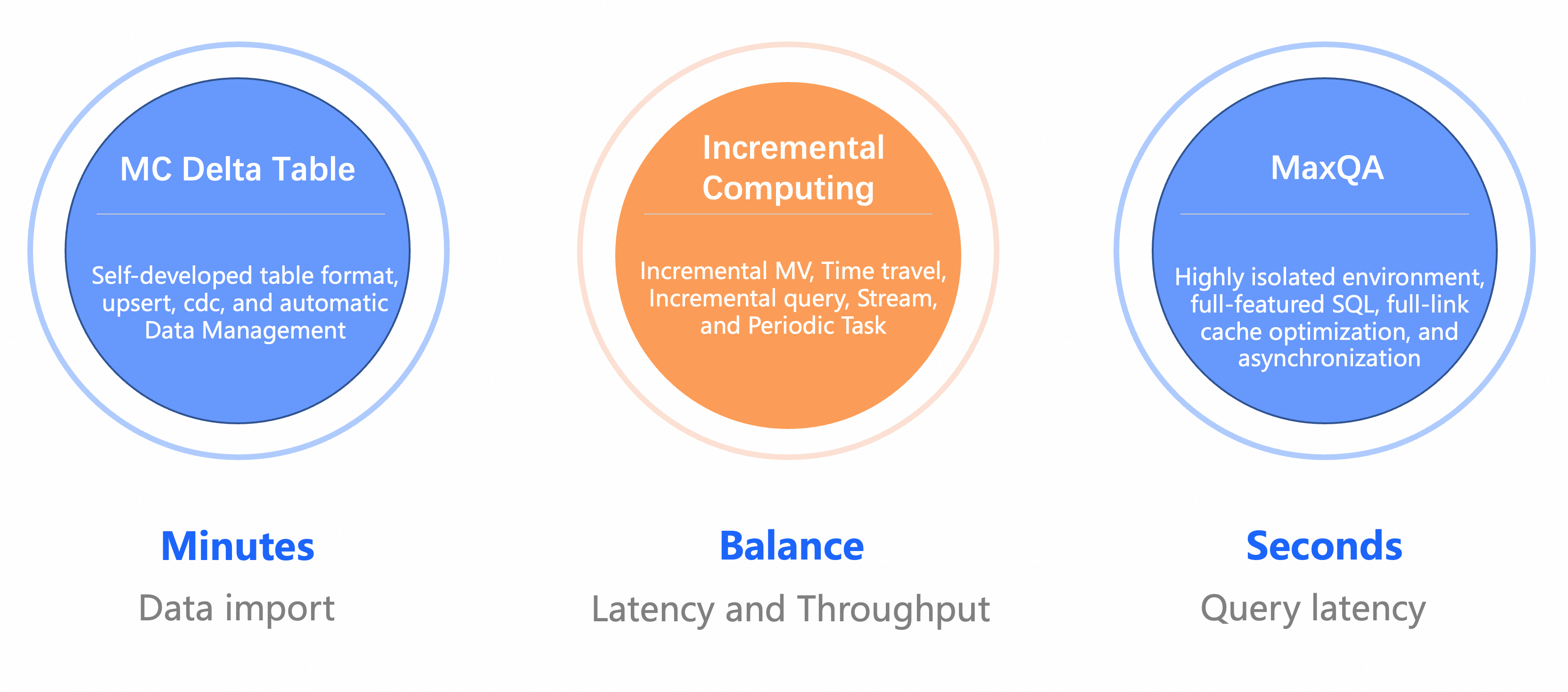
The three core features are as follows:
Delta Table format: Supports minute-level data import. This table format uses AliORC as the underlying file format, supports UPSERT semantics, and provides standard CDC (Change Data Capture) methods for reading and writing incremental data. It relies on MaxCompute storage service and global meta service for automatic data management.
Incremental computation: Based on the Delta Table format, MaxCompute has added a series of incremental computation capabilities such as incremental materialized views, Time Travel, and Stream Table. Additionally, incremental materialized views and periodically scheduled tasks provide different trigger frequencies, giving users more options to balance latency and throughput.
MCQA2.0 query acceleration: This is a complete upgrade to MaxCompute query acceleration. It improves performance stability through a strongly fenced environment and extends MCQA 1.0's support from DQL SELECT queries only to full SQL functionality, including DDL and DML. Performance is further enhanced through end-to-end cache and optimization methods such as asynchronous processing of multiple steps in the job submission pipeline.
Most importantly, these new capabilities are built and implemented based on MaxCompute's original SQL engine. MaxCompute users can analyze massive amounts of data with higher cost-effectiveness without changing their development habits.
Benefits
To support the business scenarios and business migration of the open source data lakes Hudi and Iceberg, the new architecture provides specific common features. The self-developed new architecture also provides the following benefits in terms of features, performance, stability, and integration:
Provides a unified design for storage, metadata, and compute engines to achieve in-depth and efficient integration of the engines. The new architecture provides the following benefits: low storage costs, efficient data file management, and high query efficiency. In addition, a large number of optimization rules for MaxCompute batch queries can be reused by time travel and incremental queries.
Provides a full set of unified SQL syntax to support all features of the new architecture. This facilitates user operations.
Provides in-depth customized and optimized data import tools to support various complex business scenarios.
Seamlessly integrates with existing business scenarios of MaxCompute to reduce migration, storage, and computing costs.
Supports automatic management of data files to ensure better read and write stability and supports automatic optimization of storage efficiency and costs.
Is fully managed on MaxCompute. You can use the new architecture out-of-the-box without additional access costs. You need to only create a Delta table to use the features of the new architecture.
Is a self-developed architecture. You can manage data development for your business requirements based on the new architecture.