Delta tables support incremental data writes and storage. MaxCompute provides a dedicated SQL incremental query syntax for near-real-time incremental processing pipelines. An incremental query reads only the delta files within a specified version range, merges them, and returns the result — without reading base files produced by compaction or clustering.
How it works
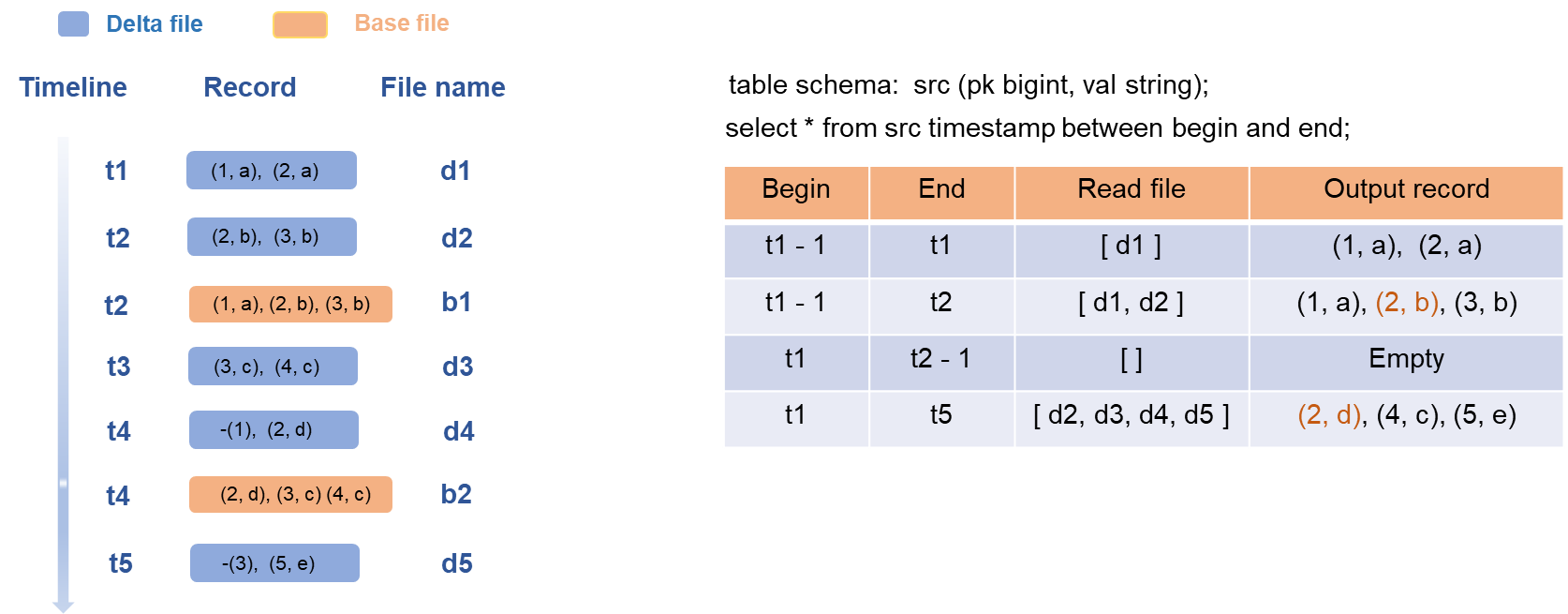
The diagram shows an incremental query against a transactional table named src with two columns: pk and val.
Data change timeline:
Five write transactions occur at time points t1 through t5, producing five delta files.
Compaction runs at t2 and t4, producing two base files: b1 and b2.
When you submit an incremental query SQL statement, MaxCompute:
Parses the specified version range (
BeginandEndvalues).Locates all delta files whose timestamps fall within that range.
Merges data across those delta files according to the specified merge policy.
Returns the merged result as the query output.
Why base files are excluded: Compaction and clustering reorganize existing records for storage efficiency without adding new logical records. Including base files would duplicate data already captured in earlier delta files. MaxCompute excludes base files by design to ensure incremental results reflect only net-new writes.
Version range semantics
The version range is defined by Begin and End values. Each value identifies a specific time version in the table's transaction history.
Begin | End | Delta files read | Result |
|---|---|---|---|
| t1-1 | t1 | d1 | Records from delta file d1 |
| t2 | unspecified | d1, d2 | Records from delta files d1 and d2 |
| t1 | t2-1 | none | Empty — no write transactions occurred in the range (t1, t2) |
Limitations
Base files are excluded: Records reorganized by compaction or clustering do not appear in incremental query results. These operations do not add new logical records, so excluding their output files does not omit any net-new data.
Empty results for gap ranges: If the specified range falls entirely between two compaction points with no write transactions, the query returns empty rows.