When your data pipeline connects databases, log systems, or message queues to MaxCompute, batch loads introduce latency that makes recent data unavailable for queries. Near-real-time incremental write solves this by continuously writing incoming rows to a delta table at minute-level intervals, so committed data is immediately queryable without waiting for a full-load cycle.
Choose a write mode
| Write mode | Latency | Use when |
|---|---|---|
| Near-real-time incremental write | Minute-level | Continuous data streams; requires low latency and fault tolerance |
| Full data write | Higher | Periodic batch loads; entire dataset is replaced at once |
How it works
MaxCompute provides an open-source Flink connector plug-in that integrates with Data Integration of DataWorks and other data import tools to support near-real-time incremental writes.
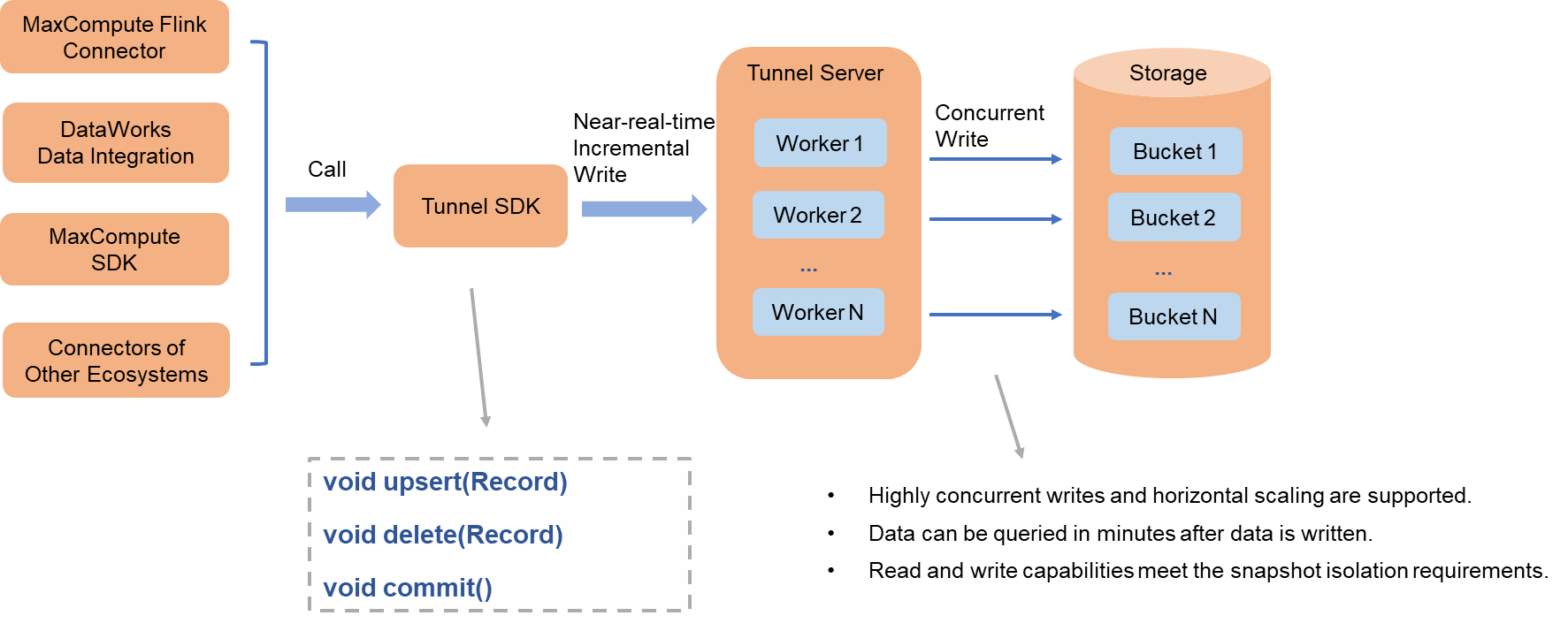
The preceding figure shows business data processing.
The data flow works as follows:
A data import tool uses the SDK client from the MaxCompute Tunnel service to write data concurrently at minute-level intervals to the Tunnel server.
The Tunnel server distributes the writes across multiple worker nodes, which write data in parallel to the data files of each bucket.
When the import tool calls the commit interface, all data written up to that point is atomically committed to the delta table and becomes immediately queryable.
Concurrency control
Set the write.bucket.num parameter to control write concurrency. A higher bucket count increases write throughput. For details on how buckets affect performance, see Table data format.
Supported operations
The Tunnel SDK write interface supports the following operations:
| Operation | Description |
|---|---|
| UPSERT | Insert a new row or update an existing row |
| DELETE | Remove a row from the delta table |
Commit semantics and fault tolerance
Each call to the commit interface represents an atomic commit of all data written before the call. Committed data satisfies read/write snapshot isolation.
On success: The committed data is immediately queryable and satisfies read/write snapshot isolation.
On failure: If the call fails, you can retry to write the data. If the failure is not caused by an unrecoverable error, such as data corruption, the retry may be successful and you do not need to rewrite the data. Otherwise, you must rewrite and recommit the data.
| Failure type | Recovery action |
|---|---|
| Non-unrecoverable (for example, not caused by data corruption) | Retry the commit directly — no need to rewrite data |
| Unrecoverable (for example, data corruption or permanent error) | Rewrite the data and recommit |
What's next
Table data format — learn how buckets affect write performance
Flink connector plug-in — set up the open-source connector for incremental writes