Overview
If you want to periodically run a MaxCompute job, you can use DataStudio in the DataWorks console to develop the job that runs on an auto triggered node and configure related parameters for the node. The related parameters include time properties and scheduling dependencies. Then, you can submit the MaxCompute job to DataWorks Operation Center for periodic scheduling. This topic describes how to develop a periodically scheduled job in the DataWorks console.
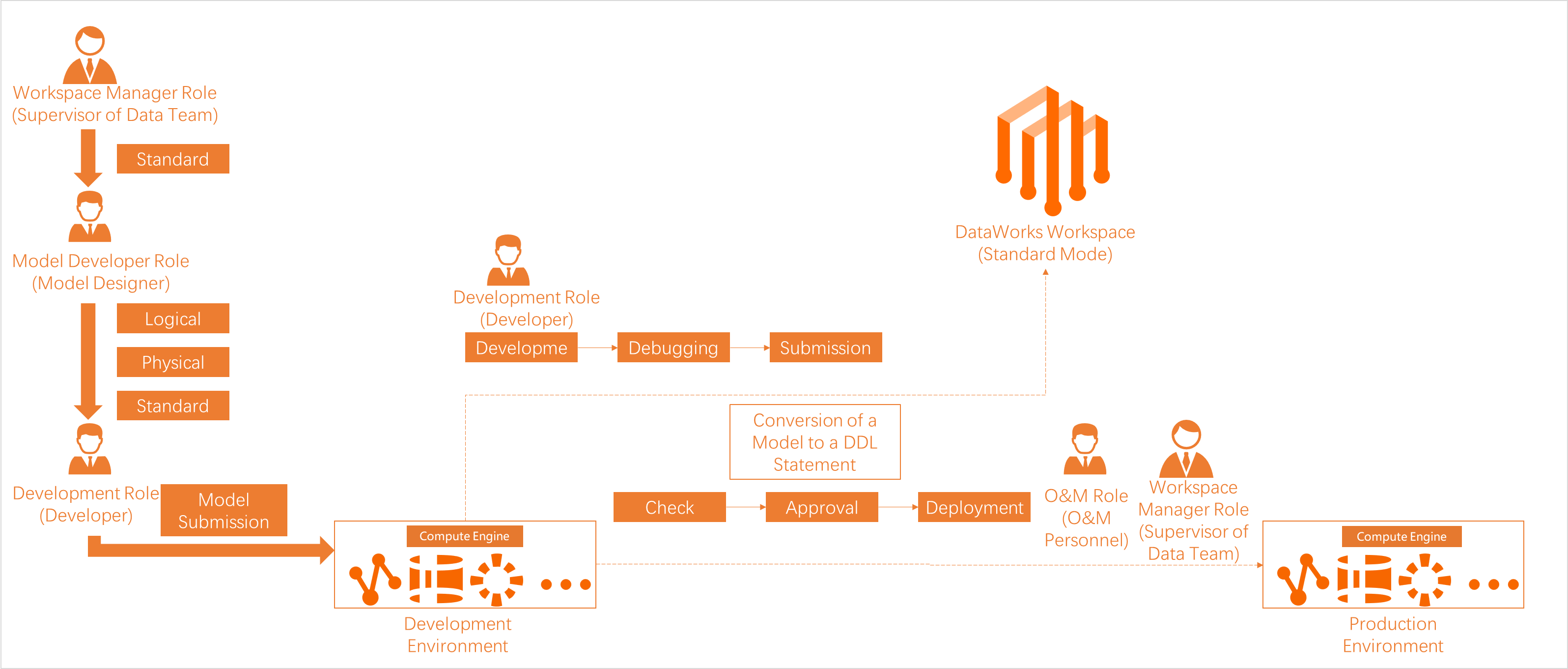
Development workflow
The following figure shows the basic development workflow of a MaxCompute job in the DataWorks console. 
A DataWorks workspace can work in basic mode or standard mode. In standard mode, one DataWorks workspace is associated with a MaxCompute project in the production environment and a MaxCompute project in the development environment. The figure above uses a DataWorks workspace in standard mode.
Keep the following in mind:
Different job types run on different node types. The following table describes the available node types.
| Node type | Description |
|---|---|
| ODPS SQL node | Runs SQL-based jobs on MaxCompute |
| ODPS Spark node | Runs Spark-based jobs on MaxCompute |
| PyODPS node | Runs Python-based jobs on MaxCompute |
| General node | Implements complex job logic such as loops and traversals |
In DataStudio, you can create MaxCompute tables, register MaxCompute functions, and create MaxCompute resources to improve development efficiency.
Billing
When you create MaxCompute-related synchronization nodes and data processing nodes in DataStudio and enable periodic scheduling in Operation Center, you are charged for both DataWorks resources and resources from other Alibaba Cloud services.
DataWorks resource fees
Your DataWorks bill includes the following charges. For the full list of billable items, see Billing overview.
| Fee type | Description |
|---|---|
| DataWorks edition fees | Activate DataWorks before developing nodes. If you use an advanced edition such as DataWorks Enterprise Edition, you are charged when you purchase the edition. |
| Scheduling resource fees | After nodes are developed, scheduling resources are required to run them. Purchase resource groups for scheduling based on your needs: subscription exclusive resource groups or the pay-as-you-go shared resource group for scheduling. |
| Data synchronization resource fees | A data synchronization node consumes both scheduling resources and synchronization resources. Purchase resource groups for Data Integration based on your needs: subscription exclusive resource groups or the pay-as-you-go shared resource group for Data Integration (debugging). |
No scheduling fees apply when you run nodes by clicking Run or Run with Parameters in the top toolbar on the DataStudio page.
No scheduling fees apply to failed nodes or dry-run nodes.
For more details on how scheduling fees are calculated, see Issuing logic of scheduling nodes in DataWorks.
Fees for other Alibaba Cloud services
The following fees are not included in your DataWorks bill.
These charges follow the billing logic of the respective Alibaba Cloud services. For example, for MaxCompute compute engine billing details, see Billable items of MaxCompute.
Running nodes in DataWorks may generate fees from other Alibaba Cloud services, including but not limited to:
| Fee type | Description |
|---|---|
| Database fees | Running data synchronization nodes to read from or write to databases may generate database fees. |
| Computing and storage fees | Running nodes on a specific compute engine may generate computing and storage fees. For example, running an ODPS SQL node to create a MaxCompute table and write data to it may incur MaxCompute computing and storage fees. |
| Network service fees | Establishing network connections between DataWorks and other services may generate network fees. For example, using Express Connect, Elastic IP Address (EIP), or EIP Bandwidth Plan to connect DataWorks to other services may incur network fees. |
Permission management
DataWorks provides a comprehensive permission management system covering both product-level and module-level permissions. In the DataWorks console, you can request and process permissions on MaxCompute compute engine resources.
Understanding the execution identity model
Jobs in DataWorks run on behalf of an execution identity, and the identity used depends on the environment:
Development environment: The personal identity of the node executor is used by default. RAM users automatically receive permissions for the development environment MaxCompute project when assigned a workspace-level role.
Production environment: An Alibaba Cloud account is used as the scheduling access identity. RAM users do not have production environment permissions by default and must request access through Security Center.
This separation means that a RAM user's personal account has access to the development environment automatically, but must explicitly request access to the production environment.
Data access permissions
Use an ODPS SQL or ad hoc query node to query data in MaxCompute tables. This topic uses a DataWorks workspace in standard mode. In basic mode, fine-grained permission management and isolation between development and production environments are not supported.
The following table describes the permissions of RAM users on MaxCompute after they are added to a workspace and assigned workspace-level roles.
| Permission type | Description |
|---|---|
| Permissions on a MaxCompute project in the development environment | After you assign a RAM user a built-in workspace-level role and associate a MaxCompute project with the workspace in the development environment, the RAM user is automatically granted the permissions of the mapped role. By default, the RAM user has permissions in the development environment but not in the production environment. |
| Permissions on a MaxCompute project in the production environment | The scheduling access identity has broad permissions on the production MaxCompute project. Other RAM users do not have permissions by default. To access MaxCompute tables in the production environment, go to Security Center to request the required permissions. DataWorks provides a default request processing procedure and allows users with management permissions to customize it. |
For more information, see Manage permissions on data in a MaxCompute compute engine instance.
Cross-project table access
MaxCompute allows you to query tables across projects by specifying the project name in DataStudio. The following table describes the access methods and execution accounts used in each environment.
In the Compute Engine Information section of the Workspace Management page, you can view the MaxCompute projects associated with the workspace and the accounts used to configure each environment. For more information, see Associate a MaxCompute compute engine with a workspace.
In the development environment, the personal identity of the node executor runs nodes by default. In the production environment, the scheduling access identity (an Alibaba Cloud account) runs nodes. For more information, see Associate a MaxCompute compute engine with a workspace.
| Sample code | Execution account in the development environment (DataStudio and Operation Center in the development environment) | Execution account in the production environment (Operation Center in the production environment) |
|---|---|---|
Access tables in the development environment MaxCompute project: | The personal Alibaba Cloud account of the node executor. If a RAM user runs the node, the RAM user's account is used. If an Alibaba Cloud account runs the node, that account is used. | The scheduling access identity. |
Access tables in the production environment MaxCompute project: | The personal Alibaba Cloud account of the node executor. Important Due to security controls on production data, personal accounts cannot access production tables by default. Go to Security Center to request the required permissions. | The scheduling access identity. |
Access tables using the project of the current environment: | If the statement runs in the development environment, the personal Alibaba Cloud account of the node executor is used to access the development environment tables. | If the statement runs in the production environment, the scheduling access identity is used to access the production environment tables. |
Service and feature permissions
Before a RAM user develops data in DataWorks, assign the RAM user a workspace-level role to grant the required permissions. For more information, see Best practices for managing permissions of RAM users.
Use RAM policy-based authorization to manage permissions on DataWorks service modules—for example, preventing users from accessing DataMap or allowing users to delete a workspace.
Use role-based access control (RBAC) to manage permissions on workspace-level modules (such as DataStudio development operations) and global-level modules (such as preventing access to Data Security Guard).