A distribution key controls how Hologres distributes table data across shards. Records with the same distribution key value are always placed in the same shard, which lets the engine compute locally within each shard instead of shuffling data across the network. Set a distribution key when your tables frequently use GROUP BY or JOIN operations, or when you need to prevent data skew.
How it works
Hologres uses the formula hash(distribution_key) % shard_count = shard_id to assign each record to a shard. For a composite key, the formula becomes hash(col1, col2, ...) % shard_count = shard_id. All records with the same hash result land in the same shard.
The core principle is that local operations are faster than distributed operations. When related data is co-located in the same shard, the engine avoids network shuffles and performs all computation locally. This drives three performance gains:
Parallel computing: Each shard computes independently, so all shards work in parallel.
Shard pruning: When you filter on the distribution key, Hologres scans only the relevant shards instead of all shards, which directly improves queries per second (QPS).
Local Join: When two tables in the same table group share the same distribution key column in their
JOINcondition, matching records from both tables are in the same shard. The join runs entirely within each shard — no data movement required.
Set a distribution key
Set the distribution key in the CREATE TABLE statement. You cannot change it after the table is created without recreating the table.
Hologres V2.1 and later — use the WITH clause:
CREATE TABLE <table_name> (...)
WITH (distribution_key = '<column_name>[,<column_name>]');All versions — use set_table_property:
BEGIN;
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'distribution_key', '<column_name>[,<column_name>]');
COMMIT;| Parameter | Description |
|---|---|
table_name | Name of the table. |
column_name | Column to use as the distribution key. Separate multiple columns with commas (,). |
The following figure shows how data is distributed across shards when a distribution key is set.
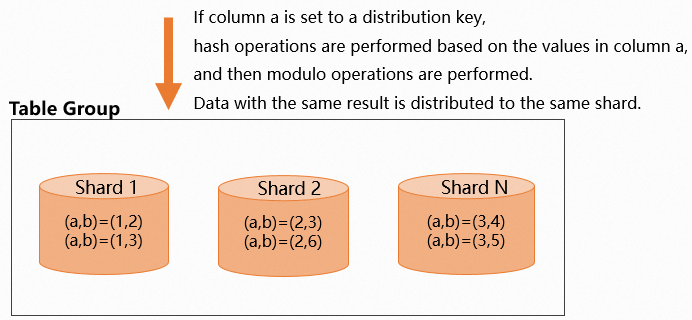
The number of shards is determined by the number of worker nodes. For more information, see Terms.
Choose a distribution key
Pick the distribution key using the following priority order:
If tables are joined: Set the
JOINcolumn as the distribution key on both tables. For multi-table joins, prioritize the largest table first. Both tables must be in the same table group. This enables Local Join and eliminates data redistribution.If a column is frequently used in `GROUP BY`: Set that column as the distribution key. Data is pre-aggregated within shards, so
GROUP BYqueries avoid cross-shard redistribution.Choose a high-cardinality column: The column must have a wide range of distinct values so data distributes evenly across shards. A low-cardinality column — such as a status flag with only a handful of states — concentrates data in a few shards and causes data skew and load imbalance.
Limit the number of distribution key columns: Use no more than two columns. With a composite key, a query that does not include all key columns may still trigger data shuffle. Avoid composite keys where the combined values are identical across many rows — this causes all those rows to land in the same shard.
Primary key constraint: If a table has a primary key (PK), the distribution key must be the PK or a subset of PK columns. If you don't specify a distribution key, the PK is used by default.
Note: To check for existing data skew on a table, see View worker skew relationships.
Limitations
Set the distribution key at table creation. To change it, recreate the table and reimport the data.
Values in distribution key columns cannot be updated. To change a value, recreate the table.
Columns of the following data types cannot be used as a distribution key: Float, Double, Numeric, Array, JSON, or other complex types.
If a table has no primary key, the distribution key can be empty (no columns specified), which distributes data randomly across shards. Starting from Hologres V1.3.28, an empty distribution key is no longer allowed:
-- This syntax is prohibited from V1.3.28 onward. CALL SET_TABLE_PROPERTY('<table_name>', 'distribution_key', '');A
nullvalue in a distribution key column is treated as an empty string ("") for hashing purposes.
GROUP BY aggregation
Set the distribution key to the GROUP BY column so that data is pre-aggregated within each shard. When you query, the engine avoids redistributing data across shards.
Hologres V2.1 and later:
CREATE TABLE agg_tbl (
a int NOT NULL,
b int NOT NULL
)
WITH (
distribution_key = 'a'
);
-- Aggregate query: groups by the distribution key column
SELECT a, SUM(b) FROM agg_tbl GROUP BY a;All versions:
BEGIN;
CREATE TABLE agg_tbl (
a int NOT NULL,
b int NOT NULL
);
CALL set_table_property('agg_tbl', 'distribution_key', 'a');
COMMIT;
-- Aggregate query: groups by the distribution key column
SELECT a, SUM(b) FROM agg_tbl GROUP BY a;Run EXPLAIN <query> to verify the configuration. If the execution plan does not contain a redistribution operator, data stays within shards and no cross-shard movement occurs.

Two-table JOIN
JOIN fields set as distribution keys (recommended)
When both tables use their JOIN column as the distribution key, matching records land in the same shard. The engine performs a Local Join without moving data.
Hologres V2.1 and later:
BEGIN;
-- tbl1 distributed by column a, tbl2 distributed by column c.
-- Joining on tbl1.a = tbl2.c: matching records are co-located in the same shard.
CREATE TABLE tbl1 (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
CREATE TABLE tbl2 (
c int NOT NULL,
d text NOT NULL
)
WITH (
distribution_key = 'c'
);
COMMIT;
SELECT * FROM tbl1 JOIN tbl2 ON tbl1.a = tbl2.c;All versions:
BEGIN;
CREATE TABLE tbl1 (
a int NOT NULL,
b text NOT NULL
);
CALL set_table_property('tbl1', 'distribution_key', 'a');
CREATE TABLE tbl2 (
c int NOT NULL,
d text NOT NULL
);
CALL set_table_property('tbl2', 'distribution_key', 'c');
COMMIT;
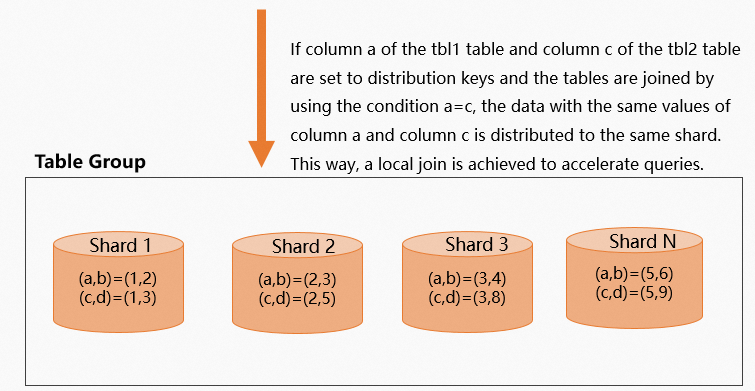
SELECT * FROM tbl1 JOIN tbl2 ON tbl1.a = tbl2.c;The following figure shows how data is distributed when the distribution keys are aligned.
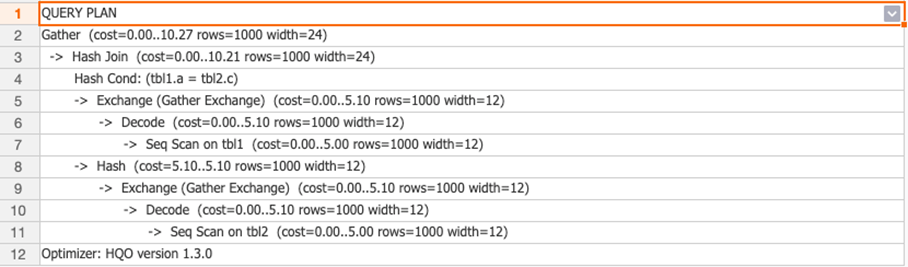
The execution plan contains no redistribution operator, confirming that data is not redistributed.
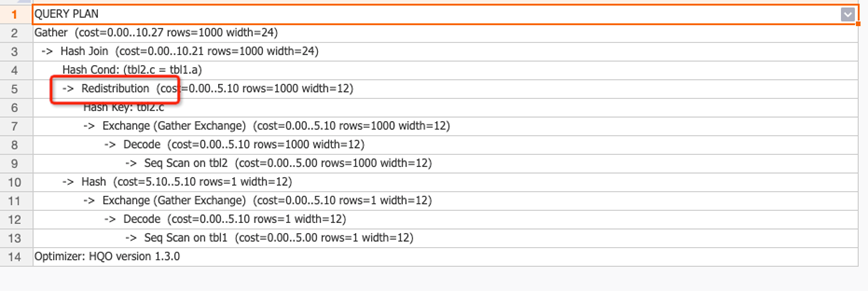
JOIN fields not set as distribution keys
When the JOIN column does not match the distribution key, the engine must shuffle data across shards before joining. In the following example, tbl1 is distributed by a and tbl2 is distributed by d, but the join condition is tbl1.a = tbl2.c. Column c in tbl2 must be redistributed.
Hologres V2.1 and later:
BEGIN;
CREATE TABLE tbl1 (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
CREATE TABLE tbl2 (
c int NOT NULL,
d text NOT NULL
)
WITH (
distribution_key = 'd' -- Mismatched: join is on column c, not d
);
COMMIT;
SELECT * FROM tbl1 JOIN tbl2 ON tbl1.a = tbl2.c;All versions:
BEGIN;
CREATE TABLE tbl1 (
a int NOT NULL,
b text NOT NULL
);
CALL set_table_property('tbl1', 'distribution_key', 'a');
CREATE TABLE tbl2 (
c int NOT NULL,
d text NOT NULL
);
CALL set_table_property('tbl2', 'distribution_key', 'd');
COMMIT;
SELECT * FROM tbl1 JOIN tbl2 ON tbl1.a = tbl2.c;The following figure shows data distribution when keys are misaligned.
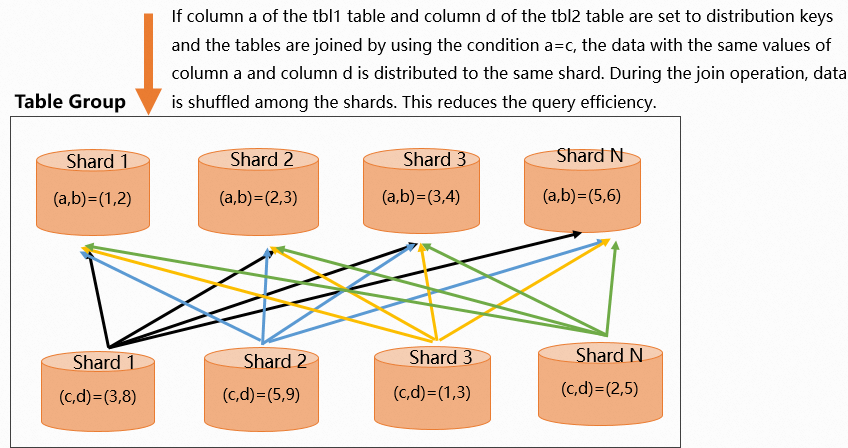
The execution plan contains a redistribution operator, indicating data is being shuffled. Reset the distribution key to eliminate the redistribution.
Multi-table JOIN
Multi-table joins involve tradeoffs. Follow these principles:
Same JOIN field across all tables: Set the shared
JOINcolumn as the distribution key for every table.Different JOIN fields: Prioritize the join between the largest tables. Set the
JOINcolumns of the large tables as their distribution keys. Small tables contain less data, so redistributing them is less costly.
Case 1: Same JOIN field
All three tables join on column a. Set distribution_key = 'a' on each table to enable Local Join across all three.
Hologres V2.1 and later:
BEGIN;
CREATE TABLE join_tbl1 (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
CREATE TABLE join_tbl2 (
a int NOT NULL,
d text NOT NULL,
e text NOT NULL
)
WITH (
distribution_key = 'a'
);
CREATE TABLE join_tbl3 (
a int NOT NULL,
e text NOT NULL,
f text NOT NULL,
g text NOT NULL
)
WITH (
distribution_key = 'a'
);
COMMIT;
-- 3-table join query
SELECT * FROM join_tbl1
INNER JOIN join_tbl2 ON join_tbl2.a = join_tbl1.a
INNER JOIN join_tbl3 ON join_tbl2.a = join_tbl3.a;All versions:
BEGIN;
CREATE TABLE join_tbl1 (
a int NOT NULL,
b text NOT NULL
);
CALL set_table_property('join_tbl1', 'distribution_key', 'a');
CREATE TABLE join_tbl2 (
a int NOT NULL,
d text NOT NULL,
e text NOT NULL
);
CALL set_table_property('join_tbl2', 'distribution_key', 'a');
CREATE TABLE join_tbl3 (
a int NOT NULL,
e text NOT NULL,
f text NOT NULL,
g text NOT NULL
);
CALL set_table_property('join_tbl3', 'distribution_key', 'a');
COMMIT;
-- 3-table join query
SELECT * FROM join_tbl1
INNER JOIN join_tbl2 ON join_tbl2.a = join_tbl1.a
INNER JOIN join_tbl3 ON join_tbl2.a = join_tbl3.a;The execution plan shows no redistribution operator between any of the three tables. The Exchange operator aggregates data from the file level to the shard level, which only requires data from the relevant shards.
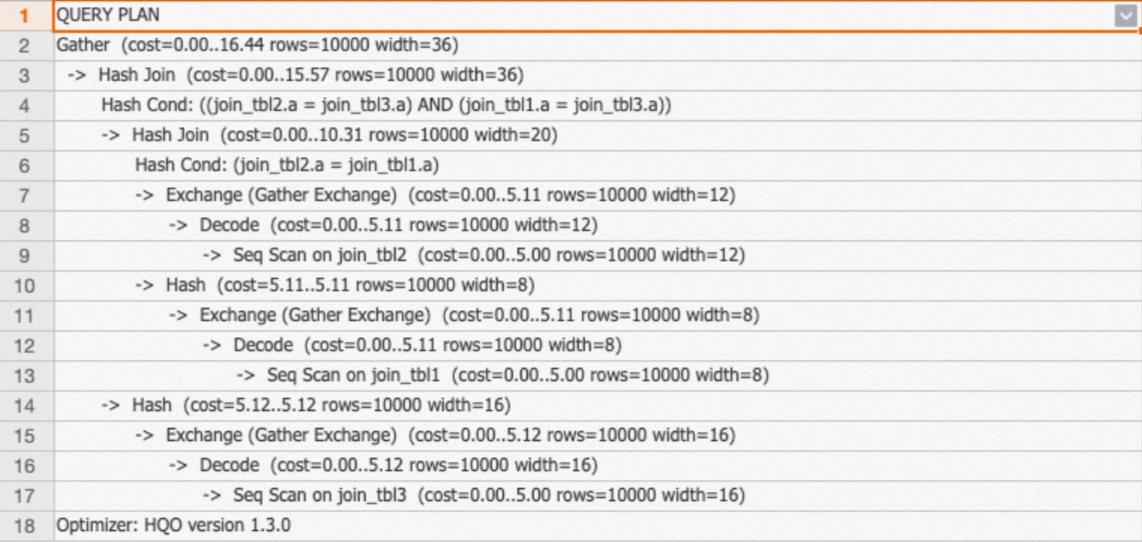
Case 2: Different JOIN fields
When JOIN fields differ across tables, optimize for the largest table. In this example, join_tbl_1 has 10 million records while join_tbl_2 and join_tbl_3 each have 1 million. The join between join_tbl_1 and join_tbl_2 uses column a, so both are distributed by a. The join between join_tbl_2 and join_tbl_3 uses column d/f — since those are smaller tables, redistributing them carries lower cost.
Hologres V2.1 and later:
BEGIN;
-- join_tbl_1: 10 million records, distributed by column a (the large-table JOIN key)
CREATE TABLE join_tbl_1 (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
-- join_tbl_2: 1 million records, distributed by column a (matches join_tbl_1)
CREATE TABLE join_tbl_2 (
a int NOT NULL,
d text NOT NULL,
e text NOT NULL
)
WITH (
distribution_key = 'a'
);
-- join_tbl_3: 1 million records, no distribution key set (small table, redistribution cost is low)
CREATE TABLE join_tbl_3 (
a int NOT NULL,
e text NOT NULL,
f text NOT NULL,
g text NOT NULL
);
COMMIT;
-- join_tbl_1 and join_tbl_2 use Local Join (keys aligned); join_tbl_3 requires redistribution (small table)
SELECT * FROM join_tbl_1
INNER JOIN join_tbl_2 ON join_tbl_2.a = join_tbl_1.a
INNER JOIN join_tbl_3 ON join_tbl_2.d = join_tbl_3.f;All versions:
BEGIN;
-- join_tbl_1: 10 million records
CREATE TABLE join_tbl_1 (
a int NOT NULL,
b text NOT NULL
);
CALL set_table_property('join_tbl_1', 'distribution_key', 'a');
-- join_tbl_2: 1 million records
CREATE TABLE join_tbl_2 (
a int NOT NULL,
d text NOT NULL,
e text NOT NULL
);
CALL set_table_property('join_tbl_2', 'distribution_key', 'a');
-- join_tbl_3: 1 million records, no distribution key set
CREATE TABLE join_tbl_3 (
a int NOT NULL,
e text NOT NULL,
f text NOT NULL,
g text NOT NULL
);
COMMIT;
SELECT * FROM join_tbl_1
INNER JOIN join_tbl_2 ON join_tbl_2.a = join_tbl_1.a
INNER JOIN join_tbl_3 ON join_tbl_2.d = join_tbl_3.f;The execution plan shows:
No
redistributionoperator betweenjoin_tbl_1andjoin_tbl_2— Local Join (keys aligned).A
redistributionoperator betweenjoin_tbl_2andjoin_tbl_3— expected, becausejoin_tbl_3is a small table with a different JOIN field.

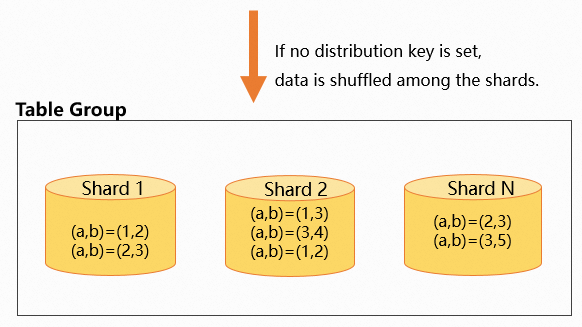
No distribution key
If you don't set a distribution key (tables without a primary key only), data is randomly distributed across shards. Records with the same field values may end up in different shards.
BEGIN;
CREATE TABLE tbl (
a int NOT NULL,
b text NOT NULL
);
COMMIT;The following figure shows how data distributes randomly when no distribution key is set.
Note: Starting from Hologres V1.3.28, leaving the distribution key empty is not allowed for tables without a primary key.
What's next
Scenario-based guide for table creation and tuning — choose the right table properties based on your query patterns.
Optimize query performance — best practices for tuning Hologres internal tables.
DDL reference for internal tables: