Common questions about data import methods, performance tuning, and error resolution for StarRocks on EMR.
Common issues
How do I select an import method?
See Overview for a comparison of all available import methods.
What are the factors that affect import performance?
The main factors are:
Server memory: More tablets consume more memory. Follow How do I determine the number of tablets? to estimate tablet size.
Disk I/O and network bandwidth: 50–100 Mbit/s is a suitable network bandwidth range.
Batch size and frequency:
For Stream Load, set batch size to 10–100 MB.
For Broker Load, no batch size limit applies — use it for large batches.
Keep import frequency low. For a serial SATA (Serial Advanced Technology Attachment) HDD, do not exceed one import job per second.
"close index channel failed" or "too many tablet versions"
Cause: High import frequency prevents compaction from keeping up, causing the number of unmerged data versions to exceed the default limit of 1,000.
Fix: Use one or both of the following approaches:
Reduce import frequency: Increase batch size so fewer import jobs run per unit of time.
Speed up compaction: Set the following parameters in the be.conf file of each backend (BE) node:
cumulative_compaction_num_threads_per_disk = 4
base_compaction_num_threads_per_disk = 2
cumulative_compaction_check_interval_seconds = 2"Label Already Exists"
Description: An import job with the same label is already running or has finished in the same database.
Cause: The most common cause is HTTP client retry behavior. Stream Load imports data over HTTP. When StarRocks doesn't return a result fast enough, some HTTP clients automatically retry the same request. StarRocks then rejects the second request because the first is still in progress.
Fix: Investigate the source of the duplicate label:
Search the primary frontend (FE) node log by label. If the label appears twice, the client sent two requests.
Run
SHOW LOAD WHERE LABEL = "xxx"to check whether a FINISHED job already holds this label.
Labels are not scoped to a specific import method. Two jobs using different methods (for example, Stream Load and Broker Load) can conflict on the same label.
To prevent retries, estimate your import duration based on data size and set the HTTP client timeout to exceed that duration.
"ETL_QUALITY_UNSATISFIED; msg:quality not good enough to cancel"
Run SHOW LOAD, find the URL in the output, and open it to see the specific error. Common errors include:
| Error | Meaning |
|---|---|
convert csv string to INT failed | A column value can't be converted to the target data type (for example, abc into a numeric column). |
the length of input is too long than schema | A string exceeds the column's defined length, or an INT value exceeds 4 bytes. |
actual column number is less than schema column number | After splitting by delimiter, fewer columns were produced than expected — usually a delimiter mismatch. |
actual column number is more than schema column number | After splitting, more columns were produced than the schema defines. |
the frac part length longer than schema scale | The decimal part of a DECIMAL column value exceeds the defined scale. |
the int part length longer than schema precision | The integer part of a DECIMAL column value exceeds the defined precision. |
there is no corresponding partition for this key | A partition key value falls outside all defined partition ranges. |
RPC timeout during data import
Check the write_buffer_size parameter in be.conf. This parameter sets the maximum memory block size for the BE node (default: 100 MB). If the value is too large, remote procedure call (RPC) timeouts can occur. Adjust write_buffer_size relative to the tablet_writer_rpc_timeout_sec parameter. See Parameter configuration for details.
"Value count does not match column count"
Cause: The delimiter in your import command doesn't match the delimiter in the source data. For example:
Error: Value count does not match column count. Expect 3, but got 1. Row: 2023-01-01T18:29:00Z,cpu0,80.99In this case, the source data uses commas (,) as the delimiter, but the import command specifies a tab (\t). StarRocks reads all three comma-separated fields as a single column.
Fix: Change the delimiter in your import command to match the source data and retry.
"ERROR 1064 (HY000): Failed to find enough host in all backends. need: 3"
Add "replication_num" = "1" to the table properties when you create the table.
"Too many open files" in BE logs
Increase the system's file handle limit.
Reduce
base_compaction_num_threads_per_diskandcumulative_compaction_num_threads_per_disk(default: 1 each). See Modify configuration items.If the issue persists, scale out the cluster or reduce import frequency.
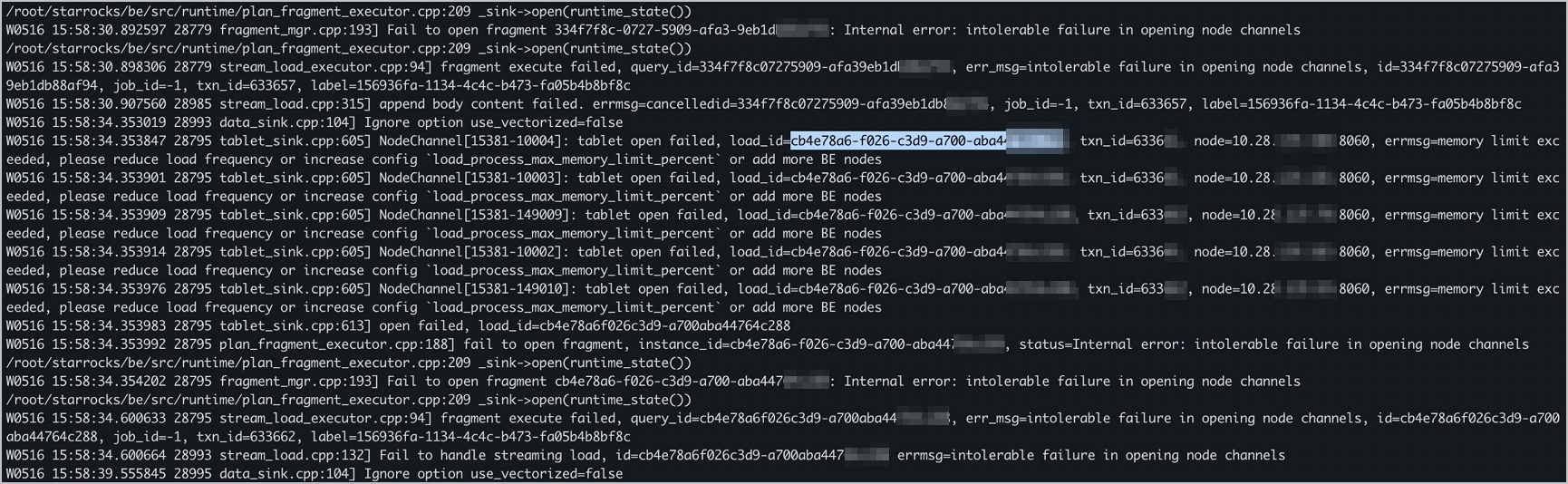
"increase config load_process_max_memory_limit_percent"
Check and increase load_process_max_memory_limit_bytes and load_process_max_memory_limit_percent. See Modify configuration items.
Stream Load
Can Stream Load identify column names in the first row?
No. Stream Load treats the first row as regular data — it cannot identify or skip column headers.
If your source file has column names in the first row, use one of these approaches:
Modify the export tool to export without column headers.
Delete the first row before importing:
sed -i '1d' filenameFilter the header row by adding
-H "where: column_name != 'Column Name'"to the Stream Load statement. StarRocks converts the header strings to the target data type and filters them out. If conversion fails,nullis returned — make sure the affected columns don't have theNOT NULLconstraint.Allow one error row by adding
-H "max_filter_ratio:0.01". This lets the first row fail without aborting the job. TheErrorURLin the response will still flag the error, but the import succeeds. Keep this value low to avoid hiding real data errors.
Do I need to convert the data type of a partition key column during Stream Load?
Yes, but StarRocks handles the conversion. Define the target column type in the table schema and use a column expression in the Stream Load statement.
For example, if your CSV file has a DATE column with values in 202106.00 format and the table expects a DATE type, map it like this:
-H "columns: NO,DATE_1, VERSION, PRICE, DATE=LEFT(DATE_1,6)"DATE_1 is a temporary placeholder for the raw value. LEFT(DATE_1,6) extracts the first six characters and assigns the result to DATE. List all source columns by their temporary names before calling any conversion function. Conversion functions must be scalar functions (non-aggregate and non-window).
"body exceed max size: 10737418240, limit: 10737418240"
Cause: The source file exceeds Stream Load's 10 GB limit.
Fix:
Split the file into smaller parts:
seq -w 0 nOr increase the limit by updating
streaming_load_max_mb:curl -XPOST http://<be_host>:<http_port>/api/update_config?streaming_load_max_mb=<file_size>See Parameter configuration for other BE parameters.
Routine Load
How can I improve Routine Load import performance?
Method 1: Increase task parallelism
This increases CPU usage and may produce more data versions.
Task parallelism is capped at:
min(alive_be_number, partition_number, desired_concurrent_number, max_routine_load_task_concurrent_num)| Parameter | Description | Default |
|---|---|---|
alive_be_number | Number of alive BE nodes | — |
partition_number | Number of Kafka partitions to consume | — |
desired_concurrent_number | Expected parallelism per Routine Load job | 3 |
max_routine_load_task_concurrent_num | Maximum parallelism per Routine Load job (FE dynamic parameter) | 5 |
If alive_be_number and partition_number both exceed desired_concurrent_number and max_routine_load_task_concurrent_num, increase both of the latter to raise parallelism.
Example: 7 partitions, 5 alive BE nodes, max_routine_load_task_concurrent_num = 5. Change desired_concurrent_number from 3 to 5. Effective parallelism: min(5, 7, 5, 5) = 5.
For a new job: set
desired_concurrent_numberinCREATE ROUTINE LOAD.For an existing job: update it with
ALTER ROUTINE LOAD.
For max_routine_load_task_concurrent_num, see Parameter configuration.
Method 2: Increase data consumed per task
This increases import latency.
Each Routine Load task consumes data until it hits the limit set by max_routine_load_batch_size (bytes) or routine_load_task_consume_second (seconds). To diagnose which limit is binding, check be/log/be.INFO:
I0325 20:27:50.410579 15259 data_consumer_group.cpp:131] consumer group done: 41448fb1a0ca59ad-30e34dabfa7e47a0. consume time(ms)=3261, received rows=179190, received bytes=9855450, eos: 1, left_time: -261, left_bytes: 514432550, blocking get time(us): 3065086, blocking put time(us): 24855If
left_bytes >= 0: the time limit (routine_load_task_consume_second) is binding. Increaseroutine_load_task_consume_second.If
left_bytes < 0: the byte limit (max_routine_load_batch_size) is binding. Increasemax_routine_load_batch_size.
See Parameter configuration for details.
After running SHOW ROUTINE LOAD, the job status is PAUSED or CANCELLED. What do I do?
Status: PAUSED — "Broker: Offset out of range"
Cause: The consumer offset no longer exists in the Kafka partition.
Fix: Run SHOW ROUTINE LOAD and check the Progress field for the latest offset. If messages at that offset are gone, either:
The offset was set to a future point when the job was created.
Kafka cleaned up the messages before they were consumed. Tune
log.retention.hoursandlog.retention.bytesbased on your import speed.
Status: PAUSED — error rows exceeded limit
Cause: The number of error rows exceeded max_error_number.
Fix: Check ReasonOfStateChanged and ErrorLogUrls:
If the data format is fixable, fix it and run
RESUME ROUTINE LOAD.If the data format can't be parsed by StarRocks, increase
max_error_number:Run
SHOW ROUTINE LOADto check the current value.Run
ALTER ROUTINE LOADto increase it.Run
RESUME ROUTINE LOAD.
Status: CANCELLED
Cause: An unrecoverable exception occurred (for example, the target table was dropped).
Fix: Check ReasonOfStateChanged and ErrorLogUrls. A CANCELLED job cannot be resumed — create a new one.
Can Routine Load guarantee exactly-once semantics when importing from Kafka?
Yes. Each import task runs as a separate transaction. If the transaction fails, the FE node does not update the partition's consumer offset. When the FE node reschedules the task, it starts from the last saved offset, ensuring exactly-once delivery.
"Broker: Offset out of range"
Run SHOW ROUTINE LOAD to get the latest offset and verify that messages at that offset exist in Kafka. Common causes:
A future offset was specified when the job was created.
Kafka deleted the messages before the import job consumed them. Adjust
log.retention.hoursandlog.retention.bytesto match your import speed.
Broker Load
Can I rerun a FINISHED Broker Load job?
No. A completed job's label cannot be reused, which prevents duplicate imports. To re-import the same data, run SHOW LOAD to view the original job's configuration and create a new job with a new label.
The date field is 8 hours later than expected after importing HDFS data
Cause: The table or import job was created with UTC+8 as the time zone, but the server runs in UTC+0. StarRocks adds 8 hours to the stored values.
Fix: Remove the timezone parameter when creating the StarRocks table.
"ErrorMsg: type:ETL_RUN_FAIL; msg:Cannot cast '\<slot 6\>' from VARCHAR to ARRAY\<VARCHAR(30)\>"
Cause: Column names in the ORC file don't match column names in the StarRocks table. When names differ, StarRocks invokes a SET statement and calls cast() for type inference, which can fail.
Fix: Make sure the ORC file's column names match the target table's column names exactly. This lets StarRocks skip the SET statement and cast function.
No error when creating a Broker Load job, but no data appears
Broker Load is asynchronous. A successful CREATE LOAD statement means only that the job was submitted, not that it completed. Run SHOW LOAD to check the job status and error message, then adjust parameters and resubmit if needed.
"failed to send batch" or "TabletWriter add batch with unknown id"
Cause: A data write timeout occurred.
Fix: Increase the query_timeout system variable and the streaming_load_rpc_max_alive_time_sec BE parameter. See Parameter configuration.
"LOAD-RUN-FAIL; msg:OrcScannerAdapter::init_include_columns. col name = xxx not found"
When importing Parquet or ORC files, the column names in the file header must match those in the StarRocks table. If they differ, use a column mapping in the SET clause:
(tmp_c1,tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
)If the ORC file was generated by an older version of Hive with a (_col0, _col1, _col2, ...) header, configure column mappings explicitly via SET.
An import job is stuck and doesn't finish
In the FE node's fe.log, search for the import job ID using the job label. Then search for that job ID in the BE node's be.INFO log to identify what's blocking it.
How do I access a high-availability HDFS cluster?
Configure the following parameters to enable automatic NameNode failover:
| Parameter | Description |
|---|---|
dfs.nameservices | The HDFS service name. Set a custom name, for example my_ha. |
dfs.ha.namenodes.xxx | Comma-separated NameNode names. Replace xxx with the value of dfs.nameservices. Example: my_nn. |
dfs.namenode.rpc-address.xxx.nn | The RPC address of each NameNode. Replace nn with the NameNode name. Format: Hostname:Port. |
dfs.client.failover.proxy.provider | The failover proxy provider. Default: org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider. |
Example configuration using simple authentication:
(
"username"="user",
"password"="passwd",
"dfs.nameservices" = "my-ha",
"dfs.ha.namenodes.my-ha" = "my_namenode1,my_namenode2",
"dfs.namenode.rpc-address.my-ha.my-namenode1" = "nn1-host:rpc_port",
"dfs.namenode.rpc-address.my-ha.my-namenode2" = "nn2-host:rpc_port",
"dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)You can also write these settings to hdfs-site.xml. If using a broker process to access HDFS, specify only the file path and authentication info.
How do I configure ViewFs in HDFS Federation?
Copy core-site.xml and hdfs-site.xml from the ViewFs configuration to the broker/conf directory.
If the setup includes a custom file system, copy the related .jar files to the broker/lib directory.
"Can't get Kerberos realm" when accessing a Kerberos-enabled EMR cluster
Verify that
/etc/krb5.confis present on every broker machine.If the error persists, append
-Djava.security.krb5.conf:/etc/krb5.confto theJAVA_OPTSvariable in the broker startup script.
INSERT INTO
Why does inserting one row with INSERT INTO take 50–100 ms?
INSERT INTO is designed for batch imports. The time to insert one row is the same as for a batch because the operation always opens a full transaction. Avoid using INSERT INTO to load individual rows in an online analytical processing (OLAP) workload.
"index channel has intolerable failure" when running INSERT INTO SELECT
Cause: Stream Load RPC timeout.
Fix: Update the following parameters in be.conf and restart the cluster:
| Parameter | Description | Default |
|---|---|---|
streaming_load_rpc_max_alive_time_sec | RPC timeout for Stream Load | 1200 seconds |
tablet_writer_rpc_timeout_sec | Timeout for TabletWriter | 600 seconds |
"execute timeout" when running INSERT INTO SELECT on a large dataset
Cause: The query exceeded the session timeout.
Fix: Increase query_timeout for the session (default: 600 seconds):
SET query_timeout = <value>;Real-time synchronization from MySQL to StarRocks
"Could not execute SQL statement. Reason: ValidationException: One or more required options are missing" when running a Flink job
Cause: Multiple rules (for example, [table-rule.1] and [table-rule.2]) are defined in the StarRocks-migrate-tools (SMT) config_prod.conf file, but required fields are missing for one or more rules.
Fix: Check that each rule has databases, tables, and a Flink connector configured.
How does Flink restart failed tasks?
Flink uses its checkpointing mechanism combined with a restart policy. To enable checkpointing with the fixed-delay restart policy, add the following to flink-conf.yaml:
# Checkpoint interval in milliseconds
execution.checkpointing.interval: 300000
state.backend: filesystem
state.checkpoints.dir: file:///tmp/flink-checkpoints-directory| Parameter | Description |
|---|---|
execution.checkpointing.interval | Interval between checkpoints in milliseconds. Must be greater than 0 to enable checkpointing. |
state.backend | Where state is persisted. See State backends. |
state.checkpoints.dir | Directory where checkpoints are stored. |
How do I stop a Flink job and restore it to a previous state?
Use a savepoint. A savepoint is a consistent snapshot of a streaming job's execution state, triggered manually. See Savepoints.
Stop the job and write a savepoint:
bin/flink stop --type [native/canonical] --savepointPath [:targetDirectory] :jobId| Parameter | Description |
|---|---|
jobId | The Flink job ID. Get it from flink list -running or the Flink web UI. |
targetDirectory | Directory for the savepoint. Set state.savepoints.dir in flink-conf.yml to configure a default: state.savepoints.dir: [file:// or hdfs://]/home/user/savepoints_dir |
To restore the job, specify the savepoint when resubmitting:
./flink run -c com.starrocks.connector.flink.tools.ExecuteSQL -s savepoints_dir/savepoints-xxxxxxxx flink-connector-starrocks-xxxx.jar -f flink-create.all.sqlFlink connector
Import fails when using exactly-once semantics
If you see an error like:
{
"Status": "Fail",
"Message": "timeout by txn manager",
"WriteDataTimeMs": 120278,
...
}Cause: The sink.properties.timeout value is less than the Flink checkpoint interval.
Fix: Increase sink.properties.timeout so it exceeds the checkpoint interval.
After using flink-connector-jdbc_2.11, timestamps in StarRocks are 8 hours earlier than in Flink
Set server-time-zone to Asia/Shanghai on the Flink sink table and add &serverTimezone=Asia/Shanghai to the url parameter:
CREATE TABLE sk (
sid int,
local_dtm TIMESTAMP,
curr_dtm TIMESTAMP
)
WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.**.**:9030/sys_device?characterEncoding=utf-8&serverTimezone=Asia/Shanghai',
'table-name' = 'sink',
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'sr',
'password' = 'sr123',
'server-time-zone' = 'Asia/Shanghai'
);Kafka on the StarRocks cluster imports successfully, but Kafka on other machines fails
If you see:
failed to query wartermark offset, err: Local: Bad message formatCause: StarRocks can't resolve the Kafka hostname.
Fix: Add the Kafka hostnames to /etc/hosts on every StarRocks cluster node.
BE node memory is fully occupied and CPU is at 100% with no queries running
The BE node collects statistics periodically and manages memory based on its configuration. By default, StarRocks returns memory to the operating system (OS) only after used memory exceeds tc_use_memory_min (default: 10737418240 bytes, approximately 10 GiB).
To change this threshold, update tc_use_memory_min in the BE configuration. In the EMR console, go to the Configure tab of the StarRocks service page and select the be.conf tab. See Parameter configuration.
Why does the BE node delay returning memory to the OS?
Memory allocation is expensive. When StarRocks requests a large amount of memory from the OS, it reserves extra capacity for future use. Idle memory is returned to the OS gradually, not immediately. To validate this behavior, monitor memory usage over an extended period in your test environment to confirm the memory is eventually released.
The system can't parse Flink connector dependencies
Cause: The /etc/maven/settings.xml file is not configured to use the Alibaba Cloud image repository, so some dependencies can't be resolved.
Fix: Set the Alibaba Cloud public repository address to https://maven.aliyun.com/repository/public in /etc/maven/settings.xml.
Does sink.buffer-flush.interval-ms still take effect when checkpoint interval is set?
Yes. Flush operations are not gated by the checkpoint interval. A flush is triggered when any of the following thresholds is reached:
sink.buffer-flush.max-rows
sink.buffer-flush.max-bytes
sink.buffer-flush.interval-msThe checkpoint interval controls exactly-once semantics. The sink.buffer-flush.interval-ms parameter controls at-least-once flush behavior. Both operate independently.
DataX
Can I update data imported by DataX?
Yes. StarRocks of the latest version supports updating data in tables created with a primary key model using DataX. Add the _op field in the reader section of the JSON configuration file.
How do I handle DataX keywords to avoid import errors?
Enclose keywords in backticks (` ``).
Spark Load
"When running with master 'yarn' either HADOOP-CONF-DIR or YARN-CONF-DIR must be set in the environment"
Configure the HADOOP-CONF-DIR environment variable in the spark-env.sh script of the Spark client.
"Cannot run program 'xxx/bin/spark-submit': error=2, No such file or directory"
Cause: The spark_home_default_dir parameter is missing or points to the wrong directory.
Fix: Set it to the correct root directory of the Spark client.
"File xxx/jars/spark-2x.zip does not exist"
Cause: The spark-resource-path parameter doesn't point to the packaged ZIP file.
Fix: Verify that the path matches the actual file name.
"yarn client does not exist in path: xxx/yarn-client/hadoop/bin/yarn"
Cause: No executable file is configured for yarn-client-path.
Fix: Set it to the correct YARN client binary path.