DataWorks allows you to create manually triggered tasks in DataStudio and manage the manually triggered tasks in Operation Center in the production environment. This topic describes how to create a manually triggered task and deploy the manually triggered task to the production environment.
Usage notes
If tasks do not need to be deployed to the production environment or used to access compute engine data in the production environment, you can create ad hoc queries. For more information, see Create an ad hoc query.
Manually triggered tasks cannot be automatically scheduled.
You can draw lines between manually triggered nodes to specify the sequence in which tasks on the nodes are run. However, this operation is not performed to configure scheduling dependencies for the manually triggered nodes.
The page on which you configure a manually triggered workflow is partially different from the page on which you configure an auto triggered workflow. For more information, see Features on the DataStudio page.
Go to the Manually Triggered Workflows pane
If you want to create a manually triggered task, you must go to the Manually Triggered Workflows pane in DataStudio to create a manually triggered workflow first.
Go to the DataStudio page.
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Development.
In the left-side navigation pane of the DataStudio page, click Manually Triggered Workflows. If the Manually Triggered Workflows module is not displayed in the left-side navigation pane, add this module first. For more information, see Adjust the displayed DataStudio modules.
Create a manually triggered workflow
DataWorks organizes data development processes by using workflows. DataWorks provides dashboards for different types of nodes in each workflow and allows you to use tools and optimize and manage nodes on the dashboards. This facilitates data development and management. You can place nodes of the same type in one workflow based on your business requirements. To create a workflow, perform the following steps:
Create a workflow. You can use one of the following methods to create a workflow:
Method 1: Move the pointer over the
 icon and click Create Workflow.
icon and click Create Workflow. Method 2: Right-click Manually Triggered Workflows in the Manually Triggered Workflows pane and select Create Workflow.
In the Create Workflow dialog box, configure the Workflow Name and Description parameters for the workflow, and click Create.
For more information about how to use a workflow, see Create and manage business processes.
Create a manually triggered task
DataWorks allows you to create a manually triggered task in the Manually Triggered Workflows pane or on the configuration tab of a manually triggered workflow.
Create a manually triggered task.
Method 1: Create a task in the Manually Triggered Workflows pane.
In the Manually Triggered Workflows pane of the DataStudio page, click Manually Triggered Workflows, find the workflow that you created, and then click the name of the workflow.
Right-click the type of the compute engine that you want to use, move the pointer over Create Node, and then select the required node type.
Method 2: Create a task on the configuration tab of a manually triggered workflow.
In the Manually Triggered Workflows pane of the DataStudio page, click Manually Triggered Workflows and find the workflow that you created.
Double-click the name of the workflow to go to the configuration tab of the workflow.
In the left-side section of the configuration tab, click Create Node. Click the required node type or drag the required node type to the canvas on the right side.
In the dialog box that appears, configure parameters such as Engine Instance and Name for the node and click Confirm.
Define the code of the task.
You can edit the task code based on the type of the compute engine and the syntax for the compute engine. To enable parameters to be dynamically passed in the task code, you can define variables in the task code in the ${Variable name} format, and assign built-in parameters to the variables as values when you configure properties for the task. The way you define variables in the code of a manually triggered task is consistent with that you define variables in the code of an auto triggered task.
NoteThe format of a scheduling parameter varies based on the type of a node. For example, you can configure scheduling parameters for a Shell node only in the $N format. N indicates an integer that starts from 1. For more information, see Configure scheduling parameters for different types of nodes.
(Optional) Specify the sequence in which manually triggered tasks are run
If you want to run manually triggered tasks in a manually triggered workflow in sequence, you can draw lines between the tasks on nodes on the configuration tab of the workflow to specify a sequence. If you do not specify the sequence, the tasks are run at the same time. If you specify the sequence in which tasks in a workflow are run, the tasks are run in sequence.
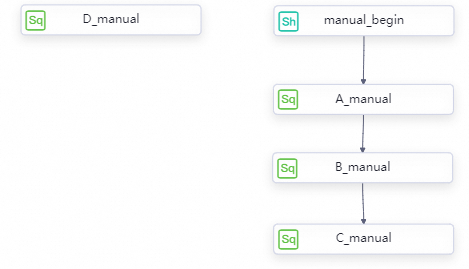
Configure properties for a manually triggered task
If a manually triggered task needs to be deployed to the production environment and used to access compute engine data in the production environment, you can configure properties that determine how the task is run in the production environment on the tab that appears after you click General in the right-side navigation pane on the configuration tab of the node that corresponds to the manually triggered task. The functionalities of the properties that you configure for a manually triggered task are consistent with the properties that you configure for an auto triggered task. The following table describes the properties that you need to configure.
Property | Description |
In this section, the node name, node ID, node type, and owner of the node are automatically displayed. You do not need to configure additional settings. Note
| |
The parameters that you define to run the task. Note DataWorks provides scheduling parameters that can be classified into custom parameters and built-in variables based on their value assignment methods. Scheduling parameters support dynamic parameter settings for task scheduling. If a variable is defined during the development of the task code, you can assign a value to the variable in the Parameters section. | |
The resource group that is used to issue the task after the task is deployed to the production environment. The resource groups for scheduling that are available in the current workspace are displayed in the Resource Group drop-down list. We recommend that you purchase a DataWorks serverless resource group. For more information, see Create and use a serverless resource group. |
Debug a manually triggered task
You can debug a manually triggered task by clicking ![]() and
and ![]() in the top toolbar on the configuration tab of the node that corresponds to the task. You can also debug the manually triggered workflow to which the manually triggered task belongs by clicking
in the top toolbar on the configuration tab of the node that corresponds to the task. You can also debug the manually triggered workflow to which the manually triggered task belongs by clicking ![]() in the top toolbar on the configuration tab of the workflow.
in the top toolbar on the configuration tab of the workflow.
In most cases, the debugging operations are performed by using your personal account that you configure to access the data source associated with the workspace in the development environment. To view information about the data source in the development environment, perform the following operations: Go to the SettingCenter page. In the left-side navigation pane, choose . For more information, see Add and manage data sources.
(Optional) Configure parameters for a manually triggered workflow
If you define variables with the same name in a manually triggered workflow and values of the variables can be assigned in a unified manner, you can configure parameters for the workflow on the configuration tab of the workflow. For more information, see Use workflow parameters. After you configure the parameters for the workflow, run the workflow. Values are assigned to the parameters. You can view the status of the workflow based on the value assignment result.
You can use the default values of the parameters. You can also specify only names for the parameters. Each time you run the workflow in the production environment, you can separately assign a value for each parameter.
Commit and deploy a manually triggered task
To run a manually triggered task in the production environment, you must save the task configurations, and commit and deploy the task to Operation Center in the production environment. For more information about how to commit and deploy a task, see Deploy nodes. The deployment operation is not necessarily successful. You must confirm the final status of the task.
To view the status of the task that is deployed to the production environment, go to the Manually Triggered Nodes page in Operation Center.
Run a manually triggered task in the production environment
Manually triggered tasks cannot be automatically scheduled. To run a manually triggered task, go to the Manually Triggered Nodes page in Operation Center, find the desired task, and then run the task. You can run the entire workflow to which the task belongs or run some tasks in the workflow. You can also specify the time at which tasks are run.
A manually triggered task cannot run for more than 3 days. If a manually triggered task runs for more than 3 days, the task fails to be run and exits.
Value assignment for workflow parameters: If you configure parameters for the workflow, you can assign values to the variables that have the same name in the code of the workflow in a unified manner by assigning values to each workflow parameter each time you run the workflow. You need to assign values to workflow parameters only if you configure parameters for the workflow.
Sequence: The tasks are run based on the sequence that you specify. For more information, see the "(Optional) Specify the sequence in which manually triggered tasks are run" section.
If you do not specify the sequence, the tasks are run at the same time.
If you specify the sequence in which tasks in a workflow are run, the tasks are run in sequence.

An instance is generated for a task in the production environment each time you run the task. Therefore, a manually triggered instance is generated for a manually triggered task each time the task is run. To view the execution results of a manually triggered task, go to the Manually Triggered Instances page under Manually Triggered Node O&M in Operation Center.