View the asset details of metadata collected from data sources, including basic information, fields, data lineage, quality overview, and data preview.
Limits
-
You must enable the metadata acquisition and management feature to view metadata asset details.
-
You must configure the data source encoding to use the data preview feature for data source tables. For more information, see Data Source Management.
-
Support for operations, such as data preview and viewing DDL, varies by data source. For more information, see Supported operations for different types of collection sources.
Access the details page of a data source table
-
In the top navigation bar of the Dataphin homepage, choose Administration > Asset Checklist.
-
Select Other System Assets, and then click the name of the target metadata or the
 icon in the Actions column to open the object details page.
icon in the Actions column to open the object details page.
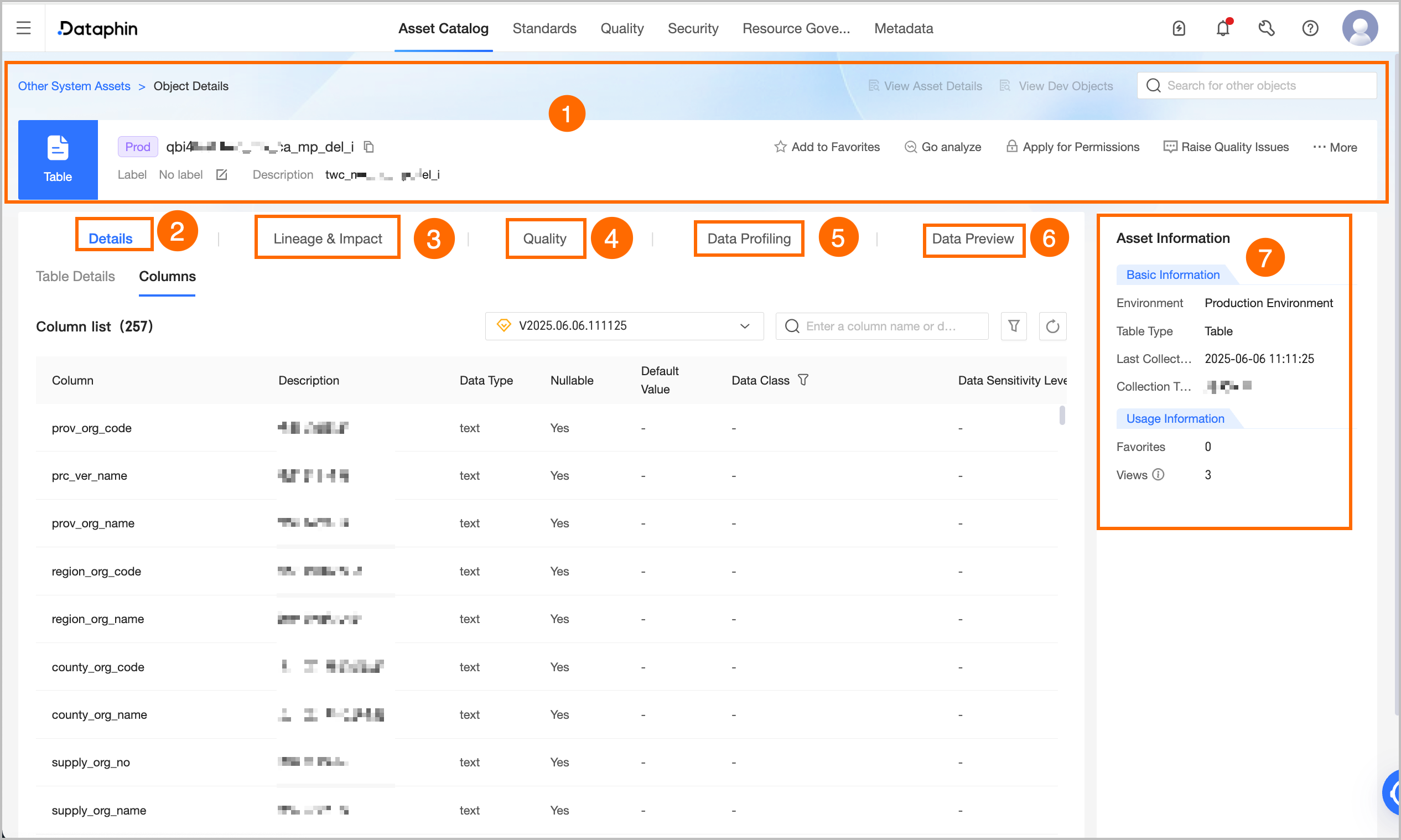
Data source table details
|
Area |
Description |
|
① Basic information |
Shows the metadata name, environment, tags, and description. You can also perform the following operations: For Elasticsearch data source tables, you can search metadata, view asset details, switch between production and development objects, modify tags, add favorites, report quality issues, request data source permissions, and export fields. Field export is supported only for table objects.
|
|
② Detail information |
Displays the attribute and field information of tables and views.
|
|
③ Lineage & impact |
|
|
④ Quality overview |
Enable the Data Quality feature to view the rule verification overview and quality monitoring rules for the current table. Click View Report Details or View Rule Details to go to the Data Quality module for more details. The quality overview is available only for data tables that support quality monitoring. For supported data sources, see Data Sources Supported by Dataphin. You can create quality rules and view the quality overview only for data source tables in the production environment. |
|
⑤ Data exploration |
With the Data Quality feature enabled, you can run data explorations on supported data source tables to understand the data overview and assess availability and potential threats. To enable automatic exploration, configure the settings in Administration > Metadata Center > Exploration and Analysis. For details about exploration tasks, see Create a data exploration task. For supported data sources, see Exploration partitions and ranges supported by different data sources. |
|
⑥ Data preview |
With query permission on the current table, data preview returns results for fields where you have SELECT permission. Up to 50 entries are shown. To request query permission, see Request, renew, and return table permission. You can search or filter by field, view single-row details, auto-adjust column widths, and transpose rows and columns. Click the sort icon next to a field to sort by No Sort, Ascending, or Descending. Double-click a field value to copy it. Note
If the data source is Hive and the table is an internal table with the Iceberg (Hive version EMR 5.x 3.1.x) or Hudi (Hive version CDP 7.x 3.1.3) lakehouse format, you must enable the Spark configuration for the table's data source before you can query data. |
|
⑦ Asset information |
Displays the basic and usage information of the data source table.
|
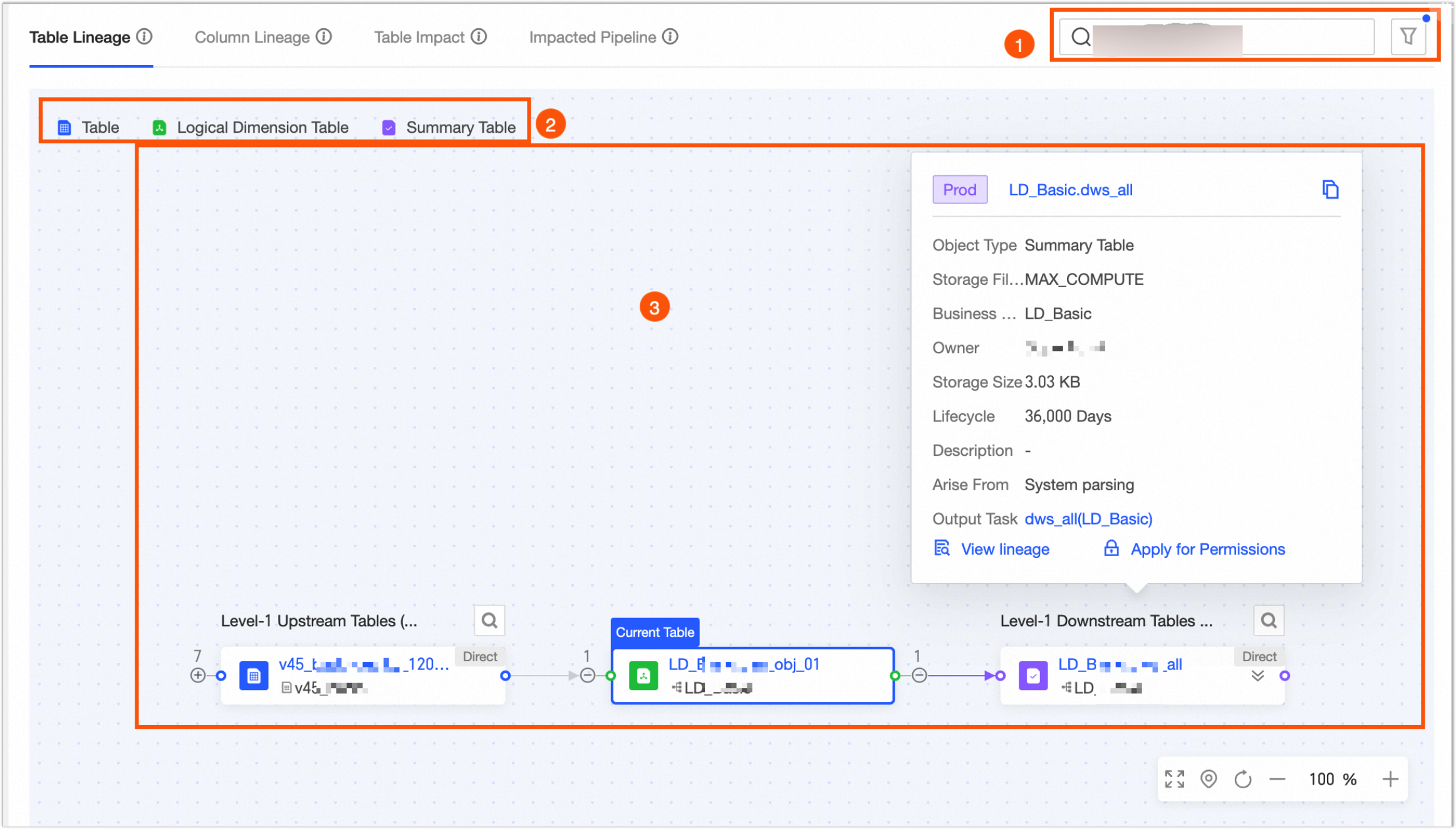
Table-level lineage
The table-level lineage page displays a lineage graph automatically parsed from sync tasks, custom lineage compute tasks, SQL compute tasks, and logical table tasks.
|
Ordinal number |
Description |
|
① Quick actions |
|
|
② Legend |
Table-level lineage supports the following data tables: Physical Table, Logical Dimension Table, Logical Fact Table, Logical Summary Table, Logical Tag Table, View, Materialized View, Logical View, Meta Table, Mirror Table, and Datasource Table. |
|
③ Lineage graph display |
Displays the full lineage graph. Expand multiple levels of upstream or downstream nodes and search by table name. If a circular dependency exists, you cannot expand further and must view downstream lineage from the start node.
|
|
④ Object details |
Hover over a table to view its details. For a data source table, the details include its Name, Object Type, Data Source Type, Data Source, and Lineage Source. You can also perform the following operations: View Lineage, View DDL, and Request Permission.
|
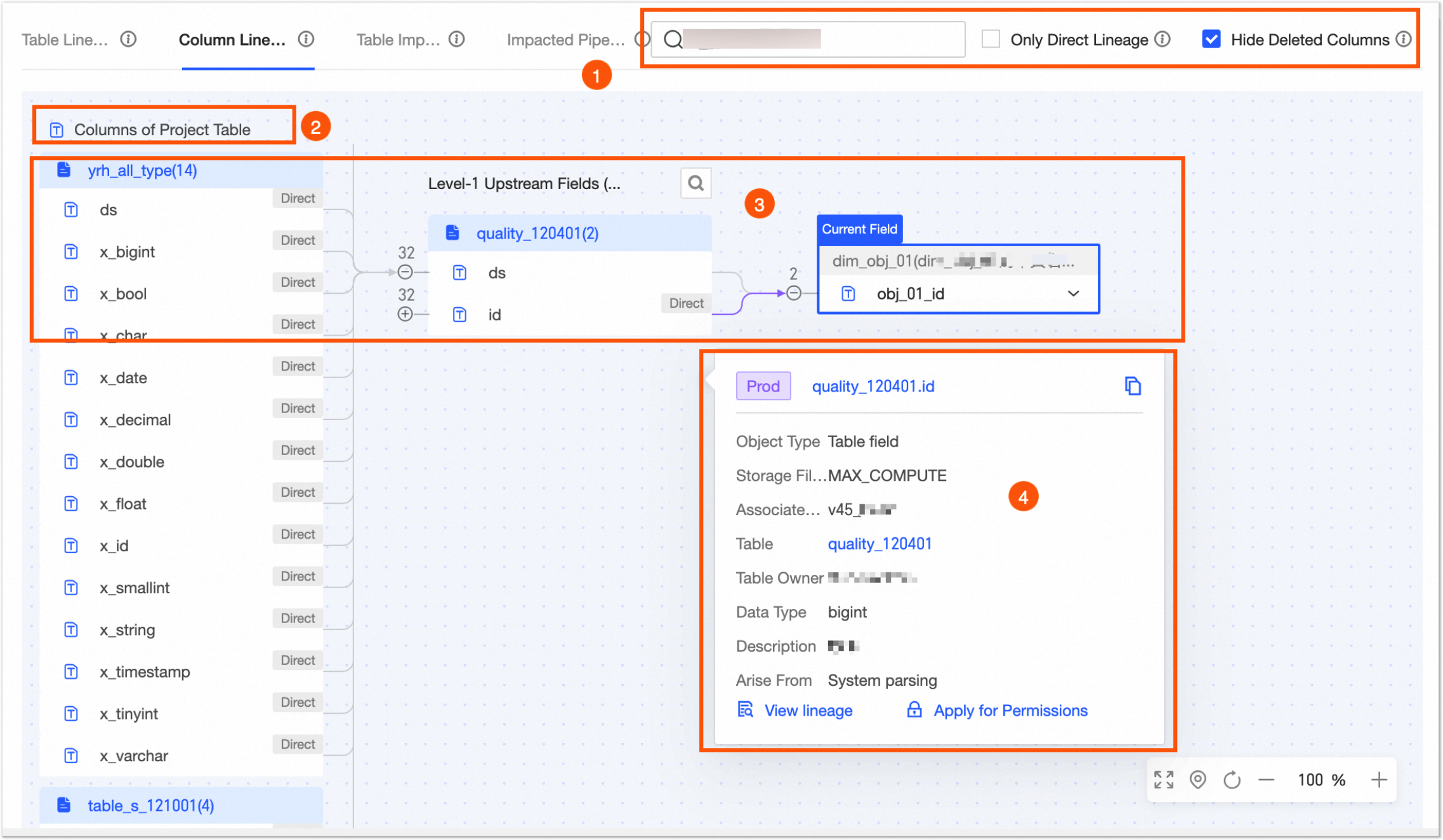
Field lineage
The field lineage page displays a lineage graph automatically parsed from custom lineage compute tasks, SQL compute tasks, and logical table tasks.
|
Ordinal number |
Description |
|
① Quick actions |
|
|
② Legend |
Field lineage supports the following fields: Compute Source Table Field and Data Source Table Field. |
|
③ Lineage graph display |
Displays the full lineage graph. Expand multiple levels of upstream or downstream nodes and search by field name. If a circular dependency exists, you cannot expand further and must view downstream lineage from the start node. Central node: Displays the current field and its table name. The node is marked with Current Field in the upper-left corner. You can perform a fuzzy search by field keyword to switch the view to the lineage graph of a different field. |
|
④ Object details |
Hover over a field to view its details. The details include the Name, Object Type, Data Source Type, Table, Owner, Data Type, Description, and Lineage Source. You can also perform the View Lineage operation.
Note
If a metadata acquisition task is not configured for a data source table, you cannot click to view its asset details. You can only view basic information, such as the field's name, object type, table, data source type, and lineage source. |