Search indexes are used for multi-dimensional data queries and statistical analysis in big data scenarios based on inverted indexes and column stores. If your business requires complex queries and data analysis, you can create a search index and specify the required attributes as the fields of the search index. Then, you can query and analyze data by using the search index. For example, you can use a search index to perform queries based on non-primary key columns, Boolean queries, fuzzy queries, full-text search, and k-nearest neighbor (KNN) vector queries. You can also use a search index to obtain maximum and minimum values, collect statistics about the number of rows, and group query results.
Background information
Search indexes are applicable only to the Wide Column model.
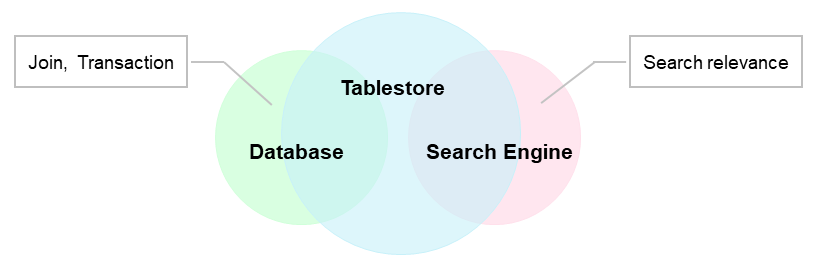
Search indexes can solve complex query problems in big data scenarios. Other systems such as databases and search engines can also solve complex data query problems. The following figure shows the differences between Tablestore and databases and search engines.
Tablestore can provide all features of databases and search engines except JOIN operations, transactions, and relevance of search results. Tablestore also has high data reliability of databases and supports advanced queries of search engines. Therefore, Tablestore can be used to replace the common architecture that consists of databases and search engines.
If you do not need JOIN operations, transaction processing, or complex relevance analysis of search results, we recommend that you use the search index feature of Tablestore.
Overview
Search indexes are used for multi-dimensional data queries and statistical analysis in big data scenarios based on inverted indexes and column stores. Search indexes support various query methods, including query based on non-primary key columns, prefix query, fuzzy query, Boolean query, nested query, geo query, full-text search, and KNN vector query. Search indexes also support multiple aggregation operations. You can perform aggregation operations to obtain the maximum and minimum values, count and distinct count of rows, sums, averages, and percentile statistics, group results by specific conditions, and display data as histograms.
The following figure shows how inverted indexes and column stores are used for search indexes, as well as the structure of a multi-dimensional spatial index.
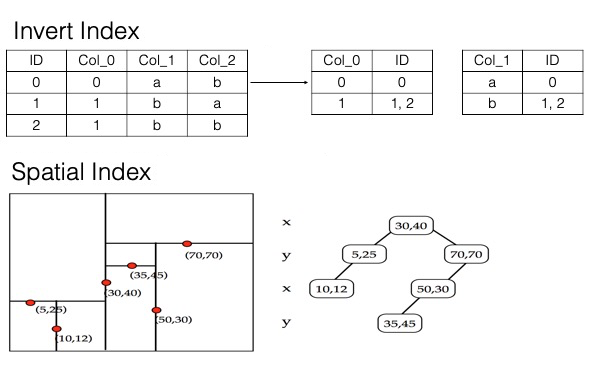
Compared with indexes of traditional database services such as MySQL, the search index feature of Tablestore is not subject to the leftmost matching principle. Therefore, the search index feature can be used in more scenarios. In most cases, only one search index is required for a data table. For example, a data table about student information contains the following columns: student name, ID, gender, grade, class, and home address. If you want to query the data in the data table by specifying a combination of conditions, such as students named Zhang San in Grade Three, male students who live within one kilometer of the school, and students in Class Two, Grade Three from the specified residential community, you can create a search index and add these columns to the search index.
Comparison
Aside from queries based on primary key columns in data tables, Tablestore provides the following two index schemas for accelerated data queries: secondary index and search index. The following table describes the differences among the three types of indexes.
Index type | Description | Scenario |
Primary key of a data table | A data table is similar to a large map. Data tables support queries based only on primary key columns. | Primary key-based queries are suitable for scenarios in which the values of all primary key columns or the primary key prefix can be determined. |
Secondary index | You can create one or more index tables for a data table and perform queries by using the primary key columns of the index tables. The primary key columns of an index table consist of all primary key columns and a specific number of predefined columns of the data table for which the index table is created. | Secondary indexes are suitable for scenarios in which the columns to be queried can be determined, the number of columns to be queried is small, and the values of all primary key columns or the primary key prefix can be determined. |
Search index | Search indexes use inverted indexes, Bkd-trees, and column stores for various query scenarios. | Search indexes are suitable for all query and analysis scenarios in which queries based on the primary key columns and secondary indexes of data tables cannot meet your business requirements. For example, you can use search indexes to perform queries based on non-primary key columns, Boolean queries, relational queries, full-text search, geo queries, fuzzy queries, nested queries, exists queries, and aggregation operations. |
Scenarios
Search indexes can be widely used in various application systems for data query and analysis. The following table describes some scenarios in which search indexes can be used.
Application system | Scenario |
E-commerce platform | You can use search indexes on e-commerce platforms to classify products and filter attributes. This facilitates product search and filtering for customers. |
Social media application | You can use search indexes in social media applications to query the follower and friend connections between users and provide the recommendation and matching features based on the interests of users. |
Log analysis | You can use search indexes to query logs based on conditions such as keywords and time ranges. This allows you to identify issues in an efficient manner and analyze log data. |
Data analysis for IoT | You can use search indexes to query and analyze device data in Internet of things (IoT) scenarios. For example, you can filter device data and collect statistics based on device types and geographic locations. |
Application performance monitoring | You can use search indexes to aggregate and query metric data, which is essential for monitoring application performance. For example, you can filter and aggregate data by time range and application name. |
Location-based service | You can use search indexes to query geographic locations and search for nearby points of interest such as stores, attractions, and services. |
Text search engine | You can use search indexes for full-text search and relevance-based sorting in a text search engine. This way, you can search for information such as documents and articles in an efficient manner. |
Feature description
Features
The following table describes the features of search indexes.
Feature | Description | References |
Query based on primary key columns and non-primary key columns | You can use a search index to query data based on a random column. This feature meets query requirements in most scenarios. If queries based on primary key columns or primary key prefix do not meet your business requirements, you can create a search index and add columns based on which you want to query data to the search index. This way, you can use the search index to query data based on the columns. | Documentation for query methods provided by search indexes, such as Basic query |
Boolean query | You can combine multiple fields to query data in an efficient manner. This feature is suitable for scenarios, such as order systems, log analysis, and user profiles in which you want to filter data based on multiple conditions. For example, a data table in the order scenario may contain dozens of fields. To query data based on various combinations of fields in a relational database, you may need to create hundreds of indexes. In addition, if a combination is not considered in advance and the corresponding index is not created, you cannot query data in an efficient manner. However, if you use Tablestore, you only need to create a search index and add the fields based on which you may want to query data to the search index. When you use the search index to query data, you can specify conditions based on a combination of the fields in the search index based on your business requirements. Search indexes also support logical operators such as AND, OR, and NOT. | |
Geo query | As mobile devices gain popularity, geographical location data becomes increasingly important. Geographical location data is used in various apps such as social media apps, food delivery apps, sports apps, and Internet of Vehicles (IoV) apps. Queries based on geographical location data are required. Search indexes support the following query features based on geographical location data:
Search indexes of Tablestore allow you to use these features to query geographical location data without the need to use other database services or search engines. | |
Full-text search | You can query data that contains a specific string. This feature is suitable for scenarios, such as big data analytics, content search, knowledge management, social media analysis, log analysis, intelligent Q&A systems, compliance review, and intelligent recommendation. Search indexes can tokenize data to support full-text search. You can use search indexes to sort query results based on only the BM25-based keyword relevance score. If you want to sort query results based on complex relevance scores, we recommend that you use search systems. Search indexes support the following tokenization methods: single-word tokenization, delimiter tokenization, minimum semantic unit-based tokenization, maximum semantic unit-based tokenization, and fuzzy tokenization. You can select tokenization methods based on your requirements. If you want to highlight the query string in the query results, you can use the highlight feature. | |
KNN vector query | Search indexes provide the KNN vector query feature. You can find the most similar data items in large-scale datasets by using vectors to perform approximate nearest neighbor searches. This feature is suitable for scenarios such as retrieval augmented generation (RAG), recommend systems, similarity detection for images, videos, and voices, and Natural Language Processing (NLP). | |
Fuzzy query | Search indexes of Tablestore support the wildcard query, prefix query, and suffix query features to meet your fuzzy query requirements in different scenarios.
| |
Exists query | You can query whether a column of a row exists. An exists query is also called a NULL query or a NULL-value query. This feature is suitable for scenarios such as data integrity check and data cleansing. | |
Nested query | In addition to a flat structure, the data produced by online applications often has a complex and multilayered structure, such as tagged images. For example, a database stores a large number of images, and each image has multiple elements such as houses, cars, and people. Each element in an image has a unique weight score. The score is evaluated based on the size and position of an element in an image. Therefore, each image has multiple tags. Each tag has a name and a weight score. If you want to filter images based on tag conditions, you can use the nested query feature. Image tags are stored in the JSON format. Example: You can use the nested query feature to handle storage and query requirements of data that has multilayered logical relationships in an efficient manner, facilitating the modeling of complex data. For Nested fields in complex data structures such as JSON, you can also enable the highlight feature to precisely locate the required information. | |
Collapse (distinct) | Search indexes support the collapse (distinct) feature to improve the diversity of query results. This feature limits the maximum number of occurrences of an attribute in the query results of a query request. This avoids excessive query results that have the same attribute. For example, in e-commerce scenarios, if you search for | |
Sorting | In Tablestore, table data is automatically sorted in alphabetical order of the primary key. To sort data based on other fields, you must use the sorting feature of search indexes. Search indexes support sorting in ascending order or descending order based on one or more conditions. The sorting is globally performed on all data in a search index. By default, the returned results of a search index are sorted based on the primary key in the data table. |
|
Match all query | When you use a search index to query data, you can specify that Tablestore returns the total number of rows that meet the query conditions. This feature is suitable for scenarios such as data verification and data-driven operations.
|
|
Aggregation | Search indexes allow you to perform aggregation operations to obtain the maximum value, minimum value, average value, sum, count and distinct count of rows, percentiles, and histogram statistics. You can also use search indexes to group results. This allows you to perform lightweight statistical analysis. |
Supported regions
The search index feature is available in the following regions: China (Hangzhou), China (Shanghai), China (Qingdao), China (Beijing), China (Zhangjiakou), China (Ulanqab), China (Shenzhen), China (Guangzhou), China (Chengdu), China (Hong Kong), Japan (Tokyo), Singapore, Malaysia (Kuala Lumpur), Indonesia (Jakarta), Philippines (Manila), Thailand (Bangkok), Germany (Frankfurt), UK (London), US (Silicon Valley), US (Virginia), and SAU (Riyadh - Partner Region). The KNN vector query feature is not supported in the US (Silicon Valley) region.
Disaster recovery capability
By default, search indexes provide the zone-redundant disaster recovery capability in regions that support the zone-redundant storage (ZRS) feature. In the regions, data is stored in multiple zones. If a fault such as power outage, network outage, or fire occurs in a zone, the read and write of data is not affected.
Search indexes support the ZRS feature in the following regions: China (Beijing), China (Shanghai), China (Hangzhou), China (Shenzhen), China (Zhangjiakou), China (Ulanqab), China (Hong Kong), Japan (Tokyo), Indonesia (Jakarta), Singapore, and Germany (Frankfurt).
Time to live
If the UpdateRow operation is disabled for a data table, you can use the time to live (TTL) feature of the search index that is created for the data table. For more information, see Specify the TTL of a search index.
If you want to retain data only for a period of time and the time field does not need to be updated, you can implement the TTL feature by partitioning a data table into several data tables based on the time field. The following table describes the principle, rule, and benefits of table partitioning by time.
Item | Table partitioning by time |
Principle | Partition a data table based on fixed periods of time, such as daily, weekly, monthly, or annually. Then, create a search index for each partitioned table. This way, you can retain tables for the specified periods of time based on your business requirements. For example, to retain data for a six-month period, you can store the data for each month in a data table. Label the data tables in sequence from table_1 to table_6 and create a search index for each data table. Make sure that each data table and its search index exclusively store data for their respective month. To implement the TTL feature, you need to only delete data tables and their associated search indexes that are retained for longer than six months. When you query data by using a search index, you need to only query a specific data table if the data table contains all the data that falls within your desired time range. If the data that falls within your desired time range spans multiple data tables, you need to query all these data tables and merge the query results. |
Rule | The size of a single search index can be up to 50 billion rows. To ensure the optimal query performance, we recommend that you limit the size of a single search index to 20 billion rows or fewer. |
Benefits |
|
Max versions
You cannot create a search index for a data table for which you specified the max versions parameter.
You can specify the timestamp when you write data to a column that allows only a single version. If you write data with a greater version number first and then write data with a smaller version number, the data with the greater version number may be overwritten by data with the smaller version number.
The results of the Search and ParallelScan requests may not include the timestamp attribute.
Limits
Search indexes synchronize data from data tables in an asynchronous manner. Data latency occurs and data cannot be queried in real time. The latency is usually less than 3 seconds. For information about more limits on search indexes, see Search index limits.
Billing
When you create a search index, data in the search index occupies storage space. When you use a search index to query and analyze data, computing resources are consumed. You are charged for the storage usage and consumed computing resources. For more information, see Billing overview.
Development integration
API operations
Tablestore provides API operations to manage search indexes and query data by using search indexes. You can call the Search or ParallelScan operation to query data. Most features that are provided by the two API operations are the same. However, to improve the performance and throughput, the ParallelScan operation does not provide some features of the Search operation.
Category | Operation | Description |
Index management | Creates a search index. | |
Updates the configurations of a search index, including the TTL and schema configurations. | ||
Queries the details about a search index. | ||
Queries the list of search indexes. | ||
Deletes a search index. | ||
Data query | Supports all features of search indexes. You can call the Search operation to query data by using all supported query methods and analyze data by performing sorting and aggregation operations. The query results are returned based on the specified order.
| |
Exports data in parallel. You can call the ParallelScan operation to query data by using all supported query methods. However, to ensure faster retrieval of query results, the ParallelScan operation does not support analysis features such as sorting and aggregation. The ParallelScan operation offers superior query performance compared to the Search operation. When the ParallelScan operation processes a single query request that includes a parallel scan task, its throughput is five times that of the Search operation.
When you call this operation, you must call the ComputeSplits operation to query the maximum number of parallel scan tasks for a single ParallelScan request. |
Integration methods
You can use Tablestore SDKs or the Tablestore CLI to perform operations on search indexes.
Use Tablestore SDKs
Tablestore SDK for Java: Search index
Tablestore SDK for Go: Search index
Tablestore SDK for Python: Search index
Tablestore SDK for Node.js: Search index
Tablestore SDK for .NET: Search index
Tablestore SDK for PHP: Search index
FAQ
How do I select between a secondary index and a search index?
What do I do if no data is found when I call the Search operation for search indexes?
Does Tablestore support the storage of data in the JSON format?
Why are reserved read CUs generated when I use a search index?
Can I modify the reserved read CU settings for a search index?
References
Tablestore allows you to query and analyze data by using the SQL query feature. For more information, see SQL query.
NoteYou can also use compute engines such as MaxCompute, Spark, Hive, HadoopMR, Function Compute, and Realtime Compute for Apache Flink to analyze data in Tablestore. For more information, see Overview.
Appendix: Mappings between SQL statements and the features of search indexes
Some features of search indexes are equivalent to specific SQL statements. The following table describes the mappings between SQL statements and the features of search indexes.
SQL | Search index feature | References |
Show | DescribeSearchIndex | |
Select | ColumnsToGet parameter in a query | Documentation for query methods provided by search indexes, such as Basic query |
From | IndexName parameter in a query Important Single-column indexes are supported. Multi-column indexes are not supported. | Documentation for query methods provided by search indexes, such as Basic query |
Where | Conditions in a query | Documentation for query methods provided by search indexes, such as Basic query |
Order by | sort parameter in a query | |
Limit | limit parameter in a query | |
Delete |
|
|
Like | WildcardQuery | |
And | operator = and in BoolQuery | |
Or | operator = or in BoolQuery | |
Not | BoolQuery(mustNotQueries) | |
Between | RangeQuery | |
Null | ExistsQuery | |
In | TermsQuery | |
Min | Aggregation: min | |
Max | Aggregation: max | |
Avg | Aggregation: avg | |
Count | Aggregation: count | |
Count(distinct) | Aggregation: distinctCount | |
Sum | Aggregation: sum | |
Group By | GroupBy |