A search index uses inverted indexes and column stores to support multi-dimensional queries and statistical analysis on big data. Use search indexes for non-primary key column queries, boolean queries, fuzzy queries, full-text search, vector search, and aggregations such as max, min, count, and group by.
Background information
Search indexes apply only to wide table models.
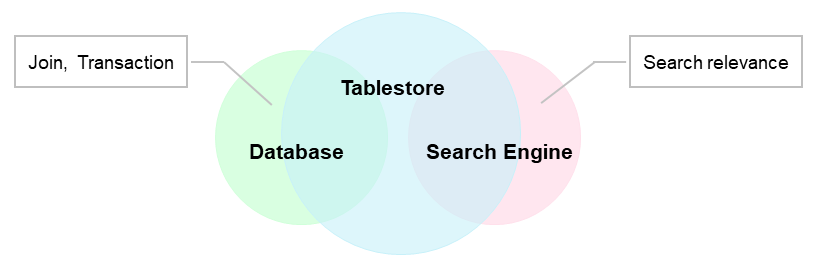
Search indexes, databases, and search engines all address complex query problems in big data, but differ in the following ways:
Except for joins, transactions, and relevance analysis, Tablestore provides the features of both databases and search systems. It combines the high data reliability of a database with the advanced query capabilities of a search system, replacing the common database + search engine architecture.
If your scenario does not involve joins, transactions, or complex relevance analysis, use a Tablestore search index.
Index overview
A search index uses inverted indexes and column stores to solve multi-dimensional query and statistical analysis problems for big data. It supports non-primary key column queries, prefix queries, fuzzy queries, boolean queries, nested queries, geo queries, full-text search, vector search, and statistical aggregation (max, min, count, sum, avg, distinct_count, group_by, percentiles, and histogram).
The following figure shows the inverted index, column store, and multi-dimensional spatial index structures used by a search index.
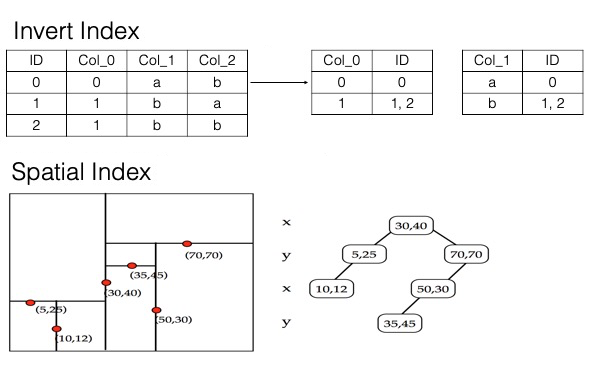
Unlike traditional database indexes (such as MySQL), a search index is not limited by the leftmost prefix matching rule. In most cases, you only need one search index per table. For example, a student table with columns such as name, student ID, gender, grade, class, and home address requires only a single search index to support combined queries like students named John Doe in the third grade, male students whose home address is within 1 km, or students in Class 2 of Grade 3 who live in a specific residential area.
Index comparison
Tablestore supports primary key queries on data tables, plus two index types for accelerated queries: secondary index and search index. The following table compares these three query methods.
|
Query method |
Principle |
Scenario |
|
Primary key |
A data table functions like a large map. You can only query data by primary key. |
Suitable for scenarios where you know the full primary key or a key prefix. |
|
Secondary index |
Creates index tables whose primary key columns extend the query capability of the data table to different columns. |
Suitable for scenarios where the query columns are predetermined, the column count is small, and you know the full primary key or a key prefix. |
|
Search index |
Uses structures such as inverted indexes, BKD trees, and column stores to provide rich query capabilities. |
Suitable for all query and analysis scenarios beyond primary key and secondary index coverage: non-primary key column queries, boolean queries on any columns, relationship queries, full-text search, geo queries, fuzzy queries, nested queries, NULL value queries, and statistical aggregation. |
Scenarios
Search indexes are widely used for data query and analysis across application systems. The following table lists common scenarios.
|
Application system |
Example scenario |
|
E-commerce platform |
Implement product categorization and attribute filtering to help users quickly search and filter products. |
|
Social application |
Query user follow and friend relationships, or recommend and match users based on interest tags. |
|
Log analysis |
Perform keyword searches and time-range queries to quickly locate problems and analyze log data. |
|
Internet of Things data analytics |
Query and analyze device data. For example, filter and count data by device type or geographic location. |
|
Application performance monitoring |
Aggregate and query metric data. For example, filter and summarize data by time range or application name. |
|
Location-based service |
Perform geo queries and nearby searches to provide information about nearby shops, attractions, and services. |
|
Text search engine |
Perform full-text search and relevance sorting to quickly find documents, articles, and other content. |
Features
Feature list
The following table lists search index features.
|
Feature |
Description |
Document |
|
Query on any column (including primary key and non-primary key columns) |
Query data by any column. Suitable for most query scenarios. If primary key or prefix queries cannot meet your needs, create a search index with the target fields and query by column values. |
Any search index query, such as a basic query |
|
Boolean query |
Combine multiple fields for efficient filtering. Suitable for order systems, log analysis, and user personas. In a relational database, a table with dozens of fields may require hundreds of indexes to cover all field combinations. Missing combinations result in inefficient queries. With Tablestore, one search index covers all field combinations. Add the fields you might query to the index, then freely combine them using And, Or, and Not logic. |
|
|
Geo query |
Mobile devices have made geographic location data increasingly valuable. Applications for social networking, food delivery, sports, and the Internet of Vehicles (IoV) all require location-aware queries. Search indexes support the following geo query features:
If your application requires location-based queries, a Tablestore search index provides a one-stop solution without additional databases or search systems. |
|
|
Full-text index |
Find data containing a specified phrase. Suitable for big data analytics, content search, knowledge management, social media analysis, log analysis, AI chat systems, compliance reviews, and personalized recommendations. Search indexes use tokenization for full-text search. They provide basic BM25 relevance but not custom relevance. For complex relevance search needs, use a dedicated search system; otherwise, a search index is sufficient. Five tokenization types are available: single-word, delimiter, minimum semantic, maximum semantic, and fuzzy. To highlight keywords in results, use the summary and highlighting feature. |
|
|
Vector search |
Search indexes support vector search for efficient approximate nearest neighbor queries on large-scale datasets. Suitable for retrieval-augmented generation (RAG), recommendation systems, similarity detection (images, videos, and speech), and natural language processing. |
|
|
Fuzzy query |
Search indexes provide wildcard, prefix, and suffix queries for fuzzy matching in different scenarios.
|
|
|
Column existence query (NULL query) |
Check whether a column has a null value. Suitable for data integrity checks and data cleaning. |
|
|
Nested query |
Beyond flat structures, application data often has multi-level nested structures. For example, an image tagging system stores images with multiple entities (houses, cars, people), each with a different position, size, and weight (score). Each image maps to multiple tags, and each tag has a name and a weight score. To filter images by tag conditions, use the nested type query. Image tags are stored in JSON format: Nested type queries handle data with multi-level logical relationships, providing flexibility for complex data modeling. For complex nested data structures (such as JSON), use the summary and highlighting feature to precisely locate required information. |
|
|
Deduplication |
Search indexes deduplicate query results to improve diversity. Deduplication limits how many times a specific attribute value appears in a single result set. For example, when searching for |
|
|
Sorting |
Tablestore sorts data by primary key in alphabetical order by default. To sort by other fields, use the sorting feature of a search index. Search indexes support ascending or descending order, single-condition sorting, and multi-condition sorting. All sorting is global. By default, search index results are sorted by the primary key in alphabetical order. |
|
|
Total number of rows |
When querying data with a search index, you can return the number of matching rows. This is useful for data validation and operations.
|
|
|
Statistical aggregation |
Search indexes provide common aggregation functions: Max, Min, Avg, Sum, Count, DistinctCount, GroupBy, Percentile, and Histogram. These meet basic statistical needs for lightweight analysis. |
Supported regions
Currently, the search index feature is available in the following regions: China (Hangzhou), China (Shanghai), China (Qingdao), China (Beijing), China (Zhangjiakou), China (Ulanqab), China (Shenzhen), China (Guangzhou), China (Chengdu), China (Hong Kong), Japan (Tokyo), Singapore, Malaysia (Kuala Lumpur), Indonesia (Jakarta), Philippines (Manila), Thailand (Bangkok), Germany (Frankfurt), UK (London), US (Silicon Valley), US (Virginia), SAU (Riyadh - Partner Region), and . The vector search feature is not yet supported in the US (Silicon Valley) region.
Disaster recovery
In regions with zone-disaster recovery capabilities, search indexes provide zone-redundant storage by default. Data is stored across multiple zones within the region. If a single zone fails, read and write services continue without disruption.
Currently, search index supports zone-redundant storage in the following regions: China (Hangzhou), China (Shanghai), China (Beijing), China (Zhangjiakou), China (Ulanqab), China (Shenzhen), China (Hong Kong), Japan (Tokyo), Singapore, Indonesia (Jakarta), Germany (Frankfurt), and .
Data Lifecycle
If your data table has no UpdateRow operations, you can use search index TTL. Lifecycle management.
If you only need to retain data for a specific period and the time field does not need updates, implement TTL by sharding tables by time.
|
Dimension |
Table sharding by time |
|
Principle |
Shard tables by a fixed interval (day, week, month, or year). Create a search index for each table and retain data tables for the required duration. For example, to retain data for six months, store each month's data in a separate table (table_1 through table_6) with its own search index. Each month, delete the table from six months ago. When querying, if the time range falls within a single table, query that table only. If it spans multiple tables, query each and merge the results. |
|
Rule |
A single table (single index) must not exceed 50 billion rows. Query performance is optimal when the row count stays below 20 billion. |
|
Advantages |
|
Data versions
Search indexes do not support multiple data versions. You cannot create a search index for a data table with multiple versions enabled.
In a single-version table, if you customize the timestamp for each write, writing data with a smaller version number after a larger one may overwrite the larger version.
The data returned by Search and ParallelScan requests does not necessarily include the timestamp property.
Limits
Search indexes synchronize data from the data table asynchronously, so real-time queries are not possible. The typical latency is within 3 seconds. Search index limits.
Billing
Search indexes are billed for the storage space occupied by index data and the computing resources consumed for queries and analysis. Billing overview.
Development and integration
API reference
Search indexes provide API operations for index management and data query. Data query includes the general-purpose Search API and the data-exporting ParallelScan API. ParallelScan sacrifices some features (sorting, aggregation) for higher performance and throughput.
|
Category |
API |
Description |
|
Index management |
Creates a search index. |
|
|
Updates the configuration of a search index, including its time to live (TTL) and index schema. |
||
|
Gets the detailed description of a search index. |
||
|
Lists the search indexes. |
||
|
Deletes a search index. |
||
|
Data query |
Full-featured query API. Supports all search index features including query functions, sorting, and statistical aggregation. Results are returned in the specified order.
|
|
|
Data-exporting API with parallel scan support. Includes all query functions but omits sorting and statistical aggregation. Returns all matched data at higher speed. With a single concurrency, ParallelScan throughput is 5x that of the Search API.
When exporting data with multiple concurrent requests, use the ComputeSplits API to get the maximum concurrency for a single ParallelScan request. |
Integration methods
You can use the following SDKs or CLI tools to work with search indexes.
FAQ
-
How do I choose between a secondary index and a search index?
-
Why can't I retrieve data using the Search API of a search index?
-
What are the differences between using the GetRange API and the Search API for range queries?
-
Does Tablestore support queries similar to 'in' and 'between...and' in relational databases?
-
How do I increase the 'limit' for the Search API of a search index to 1,000?
-
Why are reserved read CUs generated when I use a search index?
-
Can the reserved read CU configuration for a search index be adjusted?
-
Can the reserved read throughput of a search index be covered by a reserved CU plan?
References
-
To query and analyze data with SQL, use the Tablestore SQL query feature.
NoteYou can also analyze data in Tablestore using compute engines such as MaxCompute, Spark, Hive, HadoopMR, Function Compute, or Flink. Compute and analysis overview.
Appendix: SQL mapping
Some search index features map to SQL functions. The following table lists the mappings.
|
SQL |
Search index |
Search index documentation |
|
Show |
DescribeSearchIndex |
|
|
Select |
ColumnsToGet parameter in any query |
Any search index query, such as a basic query |
|
From |
IndexName parameter in any query Important
Single index is supported. Multiple indexes are not yet supported. |
Any search index query, such as a basic query |
|
Where |
Conditions in any query |
Any search index query, such as a basic query |
|
Order by |
sort parameter in any query |
|
|
Limit |
limit parameter in any query |
|
|
Delete |
|
|
|
Like |
WildcardQuery |
|
|
And |
operator = and in BoolQuery |
|
|
Or |
operator = or in BoolQuery |
|
|
Not |
BoolQuery(mustNotQueries) |
|
|
Between |
RangeQuery |
|
|
Null |
ExistsQuery |
|
|
In |
TermsQuery |
|
|
Min |
Aggregation: min |
|
|
Max |
Aggregation: max |
|
|
Avg |
Aggregation: avg |
|
|
Count |
Aggregation: count |
|
|
Count(distinct) |
Aggregation: distinctCount |
|
|
Sum |
Aggregation: sum |
|
|
Group By |
GroupBy |