Tablestore vector search (KnnVectorQuery) performs approximate nearest neighbor queries using numerical vectors to find the most similar data items in large-scale datasets. Common use cases include retrieval-augmented generation (RAG), recommendation systems, similarity detection, natural language processing, and semantic search.
Scenarios
Vector search applies to recommendation systems, image and video retrieval, natural language processing, and semantic search.
-
Retrieval-augmented generation (RAG)
RAG is an AI framework that combines retrieval with Large Language Models (LLMs) to improve the accuracy of LLM outputs, especially for private or professional data. RAG is widely used in knowledge base scenarios.
-
Recommendation system
On e-commerce, social media, and streaming platforms, user behaviors, preferences, and content features are encoded into vectors. Vector search then finds matching products, articles, or videos, enabling personalized recommendations that improve user satisfaction and retention.
-
Similarity detection (images, videos, and voice)
In image, video, voice, voiceprint, and facial recognition, unstructured data is converted into vector representations. Vector search then finds the most similar targets. For example, when a user uploads an image on an e-commerce platform, the system finds product images with similar styles, colors, or patterns.
-
Natural language processing and semantic search
In natural language processing (NLP), text is converted into vector representations such as Word2Vec or BERT embeddings. Vector search then matches query semantics to find the most relevant documents, news, or Q&A pairs, improving search result relevance and user experience.
-
Knowledge graph and AI chat
Knowledge graph nodes and relationships can be represented as vectors. Vector search accelerates entity linking, relationship inference, and AI chat response times, enabling more accurate answers to complex questions.
Core advantages
Low cost
The core engine uses optimized DiskAnn technology. Unlike the Hierarchical Navigable Small World (HNSW) algorithm, DiskAnn does not load all index data into memory. It achieves a recall rate and performance comparable to HNSW while using less than 10% of the memory, significantly reducing costs compared to similar systems.
Easy to use
-
Vector search is a serverless sub-feature of search index. No system build or deployment is required. To get started, create an instance in the Tablestore console.
-
The feature supports the pay-as-you-go billing method, with no usage level management or manual scale-out required. The system scales horizontally for both storage and compute. Vector search supports up to hundreds of billions of data entries, while non-vector search supports up to ten trillion data entries.
-
During a vector search, the internal engine uses a query optimizer to automatically select the best algorithm and execution path. High recall and performance are achievable without extensive parameter tuning, lowering the entry barrier and shortening the development cycle.
-
Vector search is accessible through SQL, SDKs for multiple languages such as Java, Go, Python, and Node.js, and open source frameworks such as LangChain, LangChain4J, and LlamaIndex.
Function overview
A KnnVectorQuery finds the most similar data items in a large-scale dataset by performing an approximate nearest neighbor query on numerical vectors.
Vector search inherits all the features of a search index. As a ready-to-use, pay-as-you-go service, it requires no system deployment. Stream-based index building allows data to be queried in near-real-time after it is written. It also supports high-throughput additions, updates, and deletions, with query performance comparable to HNSW-based systems.
To use KnnVectorQuery, specify the query vector, the vector field to search, and the number of nearest neighbors (TopK) to retrieve. The query returns the TopK vectors most similar to the query vector. You can combine it with other non-vector search features to filter results as needed.
Vector field description
Before using KnnVectorQuery, configure a vector field when creating a search index. Specify the vector dimensions, data type, and distance measure algorithm.
The corresponding field in the data table must use the String data type, and the search index must use a Float32 array string. For details on vector field configuration, see the following table.
|
Configuration item |
Description |
|
dimension |
The vector dimensions. The maximum supported dimension is 4096. The value must match the dimension of vectors produced by the upstream embedding system. The array length of the vector field must equal the configured dimension parameter. For example, if the vector field value is the string Note
Only dense vectors are supported. The vector field dimension must match the dimension set in the schema when the index was created. A mismatch causes index building for that row to fail. |
|
dataType |
The data type of the vector. Only Float32 is supported. Float32 does not support extreme values such as NaN and Infinite. The data type must match the vector data type produced by the upstream embedding system. Note
To use vectors of other data types, submit a ticket to contact us. |
|
metricType |
The algorithm used to measure the distance between vectors. Valid values: euclidean, cosine, and dot_product. The distance measure algorithm must match the recommended algorithm of the upstream embedding system. For more information, see Distance measure algorithms. |
Different models or versions of an embedding system produce vectors with different properties, including dimension, data type, and distance measure algorithm. The properties of the vector field in the vector search system (dimension, data type, and distance measure algorithm) must match the properties of the vectors produced by the embedding system. For more information about how to generate vectors, see Two ways to generate vectors.
Distance measure algorithms
Vector search supports three distance measure algorithms: euclidean, cosine, and dot_product. A higher score indicates greater similarity between two vectors.
|
MetricType |
Scoring formula |
Performance |
Description |
|
Euclidean distance (euclidean) |
|
High |
Euclidean distance measures the straight-line distance between two vectors in a multi-dimensional space. For performance, the Tablestore implementation omits the final square root calculation. A higher score indicates greater similarity. |
|
Dot product (dot_product) |
|
Highest |
The dot product multiplies the corresponding coordinates of two same-dimension vectors and sums the results. A higher score indicates greater similarity. Important
Normalize Float32 vectors before writing them to a table, for example, using the L2 norm. Without normalization, issues such as poor query results, slow vector index building, and poor query performance may occur. For a vector normalization example, see Appendix 2: Vector normalization example. |
|
Cosine similarity (cosine) |
|
Low |
Measures the cosine of the angle between two vectors. A higher score indicates greater similarity. Cosine similarity is commonly used for text data. Because division by zero is undefined, cosine similarity cannot be calculated if the sum of squares of a Float32 vector is 0. Important
Cosine similarity calculation is complex. We recommend normalizing vectors before writing data to the table and then using dot_product as the distance measure algorithm. For a vector normalization example, see Appendix 2: Vector normalization example. |
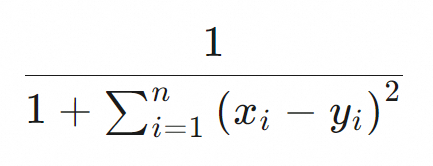
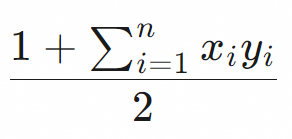
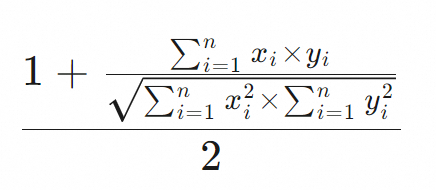
Notes
Note the following when using vector search:
-
Limits apply to the number of vector field types, dimensions, and other properties. For more information, see Search index limits.
-
The search index is partitioned on the server side. Each partition returns its own TopK nearest neighbors, and the results are then aggregated at the client node. Therefore, if a token is used to paginate through all data, the total number of rows returned depends on the number of server-side partitions.
-
Currently, the vector search feature is available in the following regions: China (Hangzhou), China (Shanghai), China (Qingdao), China (Beijing), China (Zhangjiakou), China (Ulanqab), China (Shenzhen), China (Guangzhou), China (Chengdu), China (Hong Kong), Japan (Tokyo), Singapore, Malaysia (Kuala Lumpur), Indonesia (Jakarta), Philippines (Manila), Thailand (Bangkok), Germany (Frankfurt), UK (London), US (Virginia), US (Silicon Valley), SAU (Riyadh - Partner Region).
Procedure
-
Use open source models to convert data in Tablestore into vectors and store them.
-
Write vector data to Tablestore.
-
When you create a search index, configure the vector field.
Configure the vector field's type, dimensions, and distance measure algorithm.
-
Use vector search to query data.
Billing
During the public preview, you are not charged for billable items specific to the KNN vector query feature. You are charged for other billable items based on existing billing rules.
When you use a search index to query data, you are charged for the read throughput consumed. For more information, see Billable items of search indexes.
Appendix 1: Use with BoolQuery
KnnVectorQuery and BoolQuery can be combined in different ways. The following two examples assume a scenario where a filter matches a small amount of data.
Assume a table contains 100 million images. A user has 50,000 images in total, but only 50 were added in the last 7 days. The user wants to find the 10 most similar images from those added in the last 7 days using search by image. The following table shows how these two combination methods differ.
|
Combined usage |
Query condition diagram |
Description |
|
Use BoolQuery inside the filter of KnnVectorQuery |
|
KnnVectorQuery hits the rows that satisfy the BoolQuery condition and returns the TopK most similar rows. The SearchRequest response returns the first `Size` rows from the TopK results. In this example, KnnVectorQuery first uses the filter to select all 50 images belonging to user "a" from the last 7 days, then finds the 10 most similar images from these 50 and returns them. |
|
Use KnnVectorQuery inside BoolQuery |
|
Each subquery in BoolQuery is executed first, and then the intersection of all subquery results is calculated. In this example, KnnVectorQuery returns the top 500 most similar images from the 100 million images in the table, then sequentially finds the 10 images for user "a" from the last 7 days. However, the top 500 images might not include all 50 of user "a"'s images from the last 7 days. Therefore, this query method may not find the 10 most similar images from the last 7 days, and might even return no data. |


Appendix 2: Vector normalization example
The following code normalizes a vector:
public static float[] l2normalize(float[] v, boolean throwOnZero) {
double squareSum = 0.0f;
int dim = v.length;
for (float x : v) {
squareSum += x * x;
}
if (squareSum == 0) {
if (throwOnZero) {
throw new IllegalArgumentException("can't normalize a zero-length vector");
} else {
return v;
}
}
double length = Math.sqrt(squareSum);
for (int i = 0; i < dim; i++) {
v[i] /= length;
}
return v;
}