Manually triggered tasks run on demand — they are not automatically scheduled. Use them when you need to execute a data workflow at an arbitrary time, test a pipeline in the production environment, or run a one-off data job without setting up a recurring schedule.
To run a manually triggered task in the production environment, create the task in DataStudio, deploy it to Operation Center, then trigger it manually.
Manually triggered tasks cannot run for more than 3 days. If a task exceeds this limit, it fails and exits automatically.
Prerequisites
Before you begin, ensure that you have:
A DataWorks workspace
Access to DataStudio with permission to create and deploy nodes
A compute engine instance available in your workspace
Step 1: Go to the Manually Triggered Workflows pane
Log on to the DataWorks console. In the top navigation bar, select the target region.
In the left-side navigation pane, choose Data Development and O&M > Data Development. Select your workspace from the drop-down list, then click Go to Data Development.
In DataStudio, click Manually Triggered Workflows in the left-side navigation pane. If the Manually Triggered Workflows module is not visible, add it first. For more information, see Adjust the displayed DataStudio modules.
Step 2: Create a manually triggered workflow
DataWorks organizes development tasks using workflows. Create a workflow before adding tasks to it.
Use one of the following methods:
Method 1: Hover over the
 icon and click Create Workflow.
icon and click Create Workflow.Method 2: Right-click Manually Triggered Workflows in the pane and select Create Workflow.
In the Create Workflow dialog box, enter a workflow name and description, then click Create.
For more information, see Create and manage business processes.
Step 3: Create a manually triggered task
Use one of the following methods to create a task inside your workflow:
Method 1: From the Manually Triggered Workflows pane
In the Manually Triggered Workflows pane, find the workflow you created and click the name of the workflow.
Right-click the compute engine type, hover over Create Node, and select the node type.
Method 2: From the workflow configuration tab
In the Manually Triggered Workflows pane, double-click the workflow name to open its configuration tab.
In the left-side section of the tab, click Create Node. Click the required node type or drag it onto the canvas.
After creating the node, configure the Engine Instance and Name parameters in the dialog box that appears, then click Confirm.
Step 4: Define the task code
On the configuration tab of the node, write the task code using the syntax appropriate for your compute engine.
To pass values dynamically at runtime, define variables in your code using the ${Variable name} format. You can then assign built-in parameters or custom values to these variables in the Scheduling Parameter section.
The scheduling parameter format varies by node type. For Shell nodes, define parameters in the $N format, where N is an integer starting from 1. For more information, see Configure scheduling parameters for different types of nodes.
(Optional) Step 5: Specify the execution sequence
By default, all tasks in a manually triggered workflow run at the same time. To run tasks in sequence, draw lines between nodes on the workflow configuration tab.
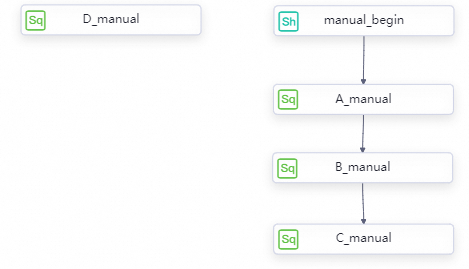
Drawing lines between manually triggered nodes sets the execution order but does not configure scheduling dependencies between them.
Step 6: Configure task properties
If the task needs to access compute engine data in the production environment, configure its properties. On the node configuration tab, click General in the right-side navigation pane to open the properties panel.
| Property | Description |
|---|---|
| General | Displays the node name, node ID, node type, and owner. No additional configuration is required. By default, the owner is the current user. You can modify the owner, but you can select only a member in the current workspace as the owner. An ID is generated after the task is committed. |
| Scheduling Parameter | Parameters assigned to variables defined in the task code. Supports custom parameters and built-in variables for dynamic value assignment at runtime. |
| Resource Group | The resource group used to run the task after deployment. We recommend that you purchase a DataWorks serverless resource group for on-demand execution. For more information, see Create and use a serverless resource group. |
(Optional) Step 7: Configure workflow parameters
If multiple tasks in the workflow share variables with the same name, configure workflow parameters to assign values in one place rather than per task.
In the production environment, you can assign a value to each workflow parameter each time you run the workflow, or use the default values. For more information, see Use workflow parameters.
Step 8: Debug the task
Before deploying, debug the task in the development environment. On the node configuration tab, use the ![]() and
and ![]() icons in the toolbar to run a debug session. To debug the entire workflow, click
icons in the toolbar to run a debug session. To debug the entire workflow, click ![]() on the workflow configuration tab.
on the workflow configuration tab.
Debugging uses your personal account to access the data source configured in the development environment. To check data source settings, go to SettingCenter > . For more information, see Add and manage data sources.
Step 9: Commit and deploy the task
To run the task in the production environment, save your changes, then commit and deploy the task to Operation Center.
For deployment steps, see Deploy nodes.
Deployment is not always successful. After deploying, confirm the final status of the task on the Manually Triggered Nodes page in Operation Center.
Step 10: Run the task in the production environment
After deployment, go to the Manually Triggered Nodes page in Operation Center to trigger the task.
From this page, you can:
Run the entire workflow or selected tasks within it
Specify the time at which tasks run
Assign values to workflow parameters (if configured) before each run
When tasks run with an execution sequence specified, they run in the order you defined:

Each time you run a manually triggered task, DataWorks generates a new instance. To view execution results and status, go to Manually Triggered Node O&M > Manually Triggered Instances in Operation Center.
What's next
If you do not need production environment access and want a lighter workflow, consider creating an ad hoc query instead.
To understand how manually triggered tasks differ from auto triggered tasks in DataStudio, see Features on the DataStudio page.