This article aims to provide insights into Apache Paimon, a unified data lake storage solution. We'll be focusing on its role in addressing key challenges in big data systems, why Apache Paimon can be the solution to these problems, its adoption in China, and its integration with various data processing and AI technologies.

Big data practitioners often face several significant challenges. Based on interactions with numerous companies and their employees, we discover that the following three challenges are particularly noteworthy:
1)Balancing Low Latency and Cost: Many real-time applications are being deployed using technologies such as Flink, Kafka, key-value systems and OLAP systems. However, the cost of these systems is becoming increasingly important. The challenge is to achieve both low latency and low cost, which is a significant concern.
2)Complex Data Architecture: In big data systems, there are multiple solutions for computing and storage, all aiming at different aspects. As a consequence of this bloom in big data frameworks, data often needs to be moved between different systems, such as from a batch system to Flink or Kafka when streaming processing is needed. This frequent data movement is complex and difficult to manage, leading to a cumbersome architecture.
3)Integration with AI: AI is a hot topic, and integrating it with big data systems is crucial. There is a need for a universal structure that can support both big data and AI. Effective combination of these two domains is essential.
The concept of data lakes is gaining popularity globally, and here we're introducing Paimon, a lake format that enables building a Realtime Lakehouse Architecture with Flink and Spark for both streaming and batch operations. Let's explore how Paimon can address the aforementioned challenges.
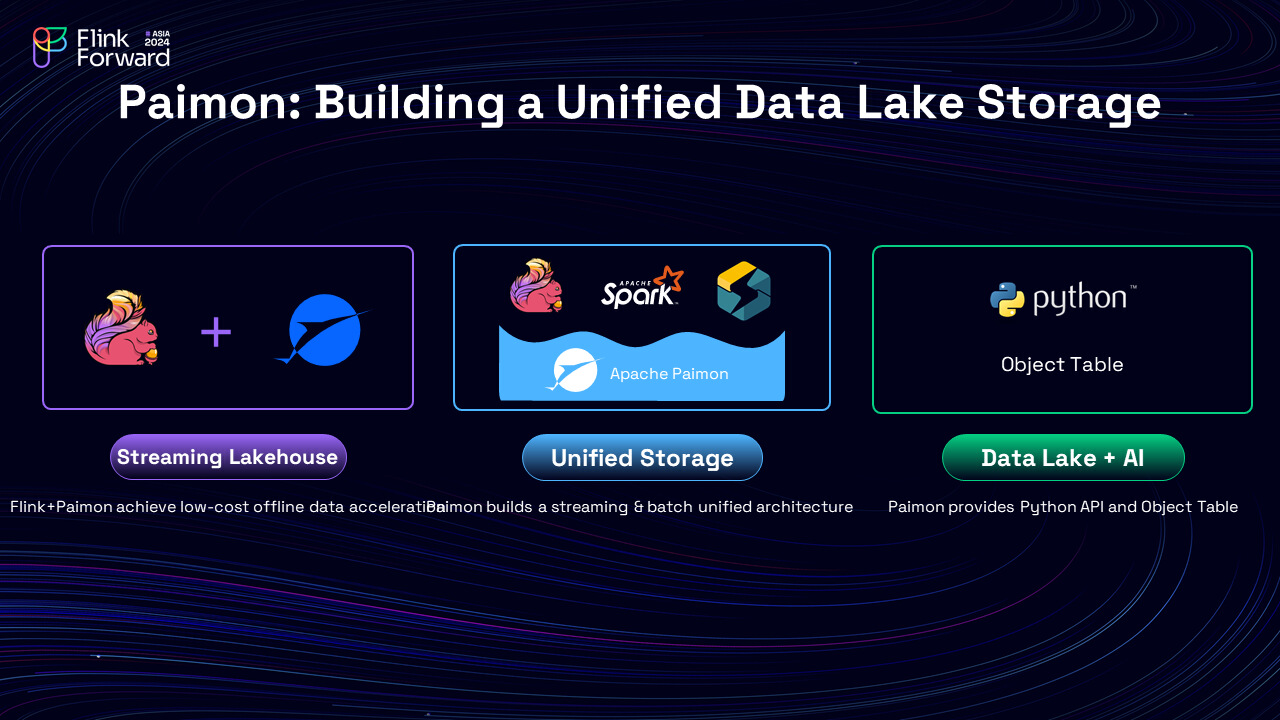
1)Achieving Low Latency and Cost: To achieve both low latency and cost, one can use Flink and Paimon to build a streaming house. On one hand, Kafka, with its SSD storage, and other fast KV systems provide low latency, but for many business cases, minute-level latency is sufficient. While on the other hand, Paimon, which is a lake format, can be used with HDFS, OSS, or S3, making it a cost-effective solution. By combining Flink and Paimon, it is possible to achieve low-cost offline batch data processing while maintaining low latency.
2)Unified Storage and Processing: Paimon supports batch processing, streaming, and OLAP. In many companies, Paimon is used to build a unified storage system. For streaming, Flink can be used to read from and write to Paimon; for batch processing, it comes to Spark; and for OLAP, StarRocks steps in. Paimon, as the unified storage, simplifies the system and reduces the need for multiple storage solutions.
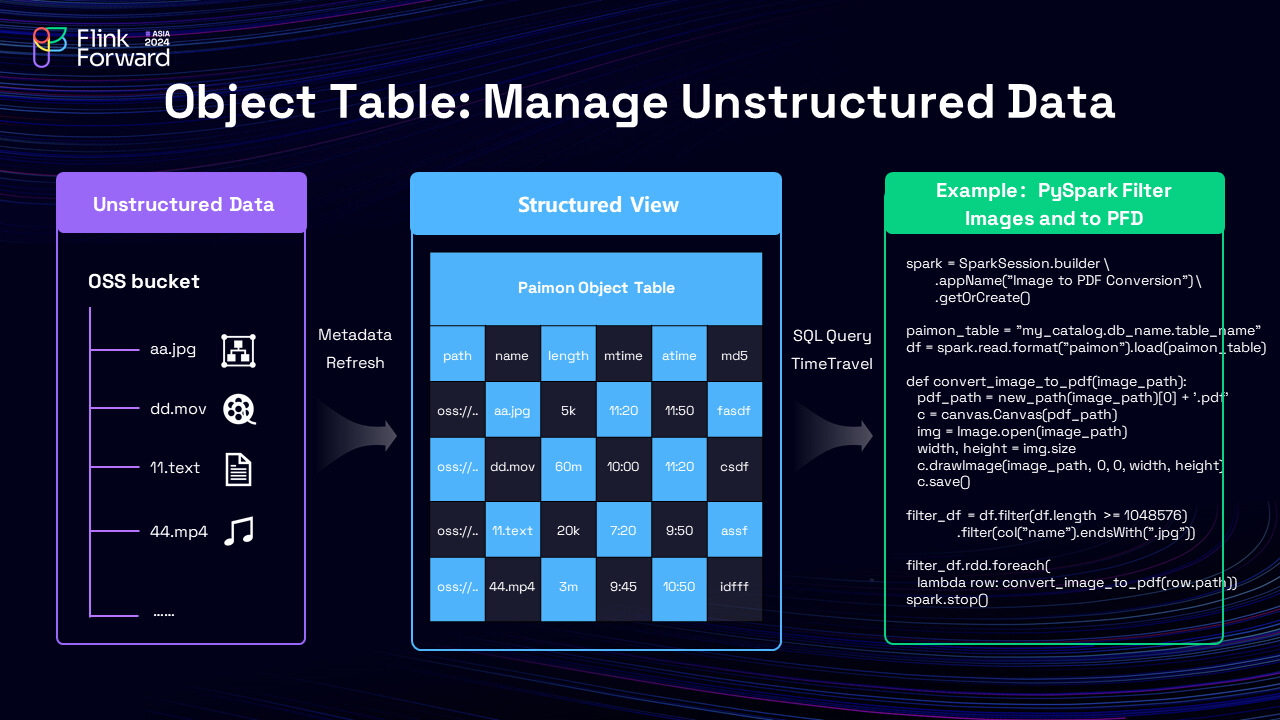
3)Integration with AI: Paimon provides Python APIs, which are essential for AI development. Data can be read from and written to Paimon using Python, and Paimon also introduces the Object Table feature, which maps unstructured data (e.g., images, videos) to structured tables, enabling analysis with tools like PySpark or Flink SQL.
To better understand the unique advantages and use cases of Paimon, it is essential to compare it with other popular data storage solutions, such as the classic Apache Hive and the lake format Apache Iceberg.

Apache Hive is one of the earliest and most widely used data warehousing solutions for Hadoop. It provides a SQL-like interface for querying and managing large datasets stored in distributed storage systems like HDFS. However, it is costly in Hive to update records, for the user must merge all records in the old partition with new data, and rewrite the whole partition with the merged result.
Apache Iceberg is a shared lake format mainly for batch processing, offering ACID transactions and more features than Hive, such as the delete and update for records, the data skipping ability and the time travel ability. However, it is not optimized for streaming processing.
Apache Paimon is designed for both batch and streaming processing. It combines the lake format with LSM (Log-Structured Merge), allowing for automatic compaction and fast updates…… Paimon integrates well with Flink, unlocking the ability for efficient streaming writes and reads. Also, Paimon supports query optimizations such as z-order, deletion vectors and indexing, allowing for fast OLAP style analysis.
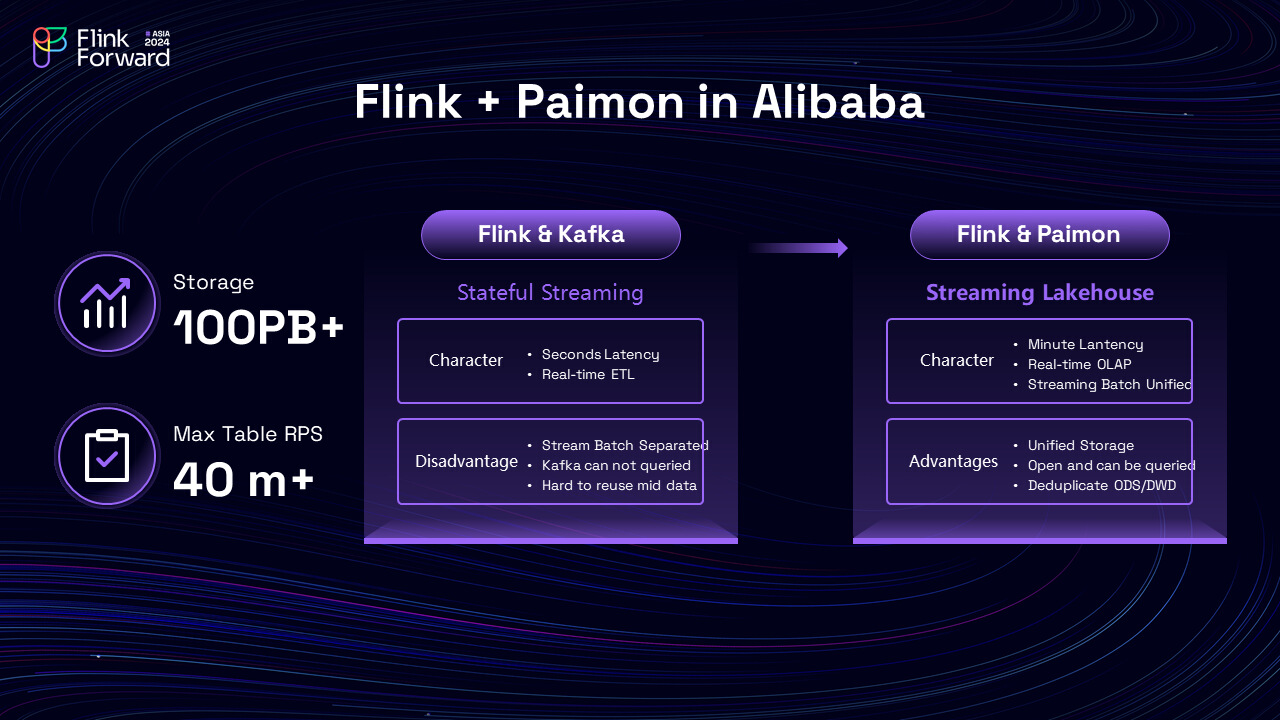
With all these advantages, Paimon has gained significant traction in the Chinese community, with over ten thousand Flink streaming jobs in one company and numerous enterprise adoptions. For example at Alibaba, large tables, such as page views and orders, have been moved to Paimon. There are now over 100PBs of Paimon data files residing in its storage cluster, and among them the largest Paimon table supports a processing rate of more than 40 million rows per second.

Also at Alibaba, the Flink + Paimon architecture is replacing many of the old Flink + message queue architecture, upgrading a stateful streaming pipeline into a streaming lakehouse. Previously during the Flink + message queue days, as records in message queues cannot be queried efficiently, engineers in Alibaba have to build separated pipelines for batch and streaming processing. Also message queues require high-speed local disks, which also increases the cost. Now with Flink + Paimon, the migration has reduced the latency of batch pipelines to a few minutes, made the total time of processing one hour less, improved development and operational efficiency by over 50% as batch and streaming storage are now unified, and enabled real-time OLAP for business intelligence. Also, Paimon can store its data on distributed storage or object storage, decreasing the storage cost.
As an open-source project, Paimon continues to innovate, with contributions from Alibaba, ByteDance, Vivo, Xiaomi, and others. Paimon has graduated to an Apache top-level project and has a wide range of ecosystem support, opening to other engines like Spark, Starrocks, Presto, and more.

It also provides CDC (Change Data Capture) capabilities and Python APIs, unlocking the Python ecosystem. The Python API, called PyPaimon, allows interaction with Paimon using Python. It leverages Py4J and Arrow to enable data exchange between Java and Python, while enabling analysis with tools like PySpark. Paimon Python API covers a lot of interfaces in the Java API, including the catalog API to manage Paimon tables in filesystems or other management systems such as Hive, and also the basic read/write API with projection and filter push-down.

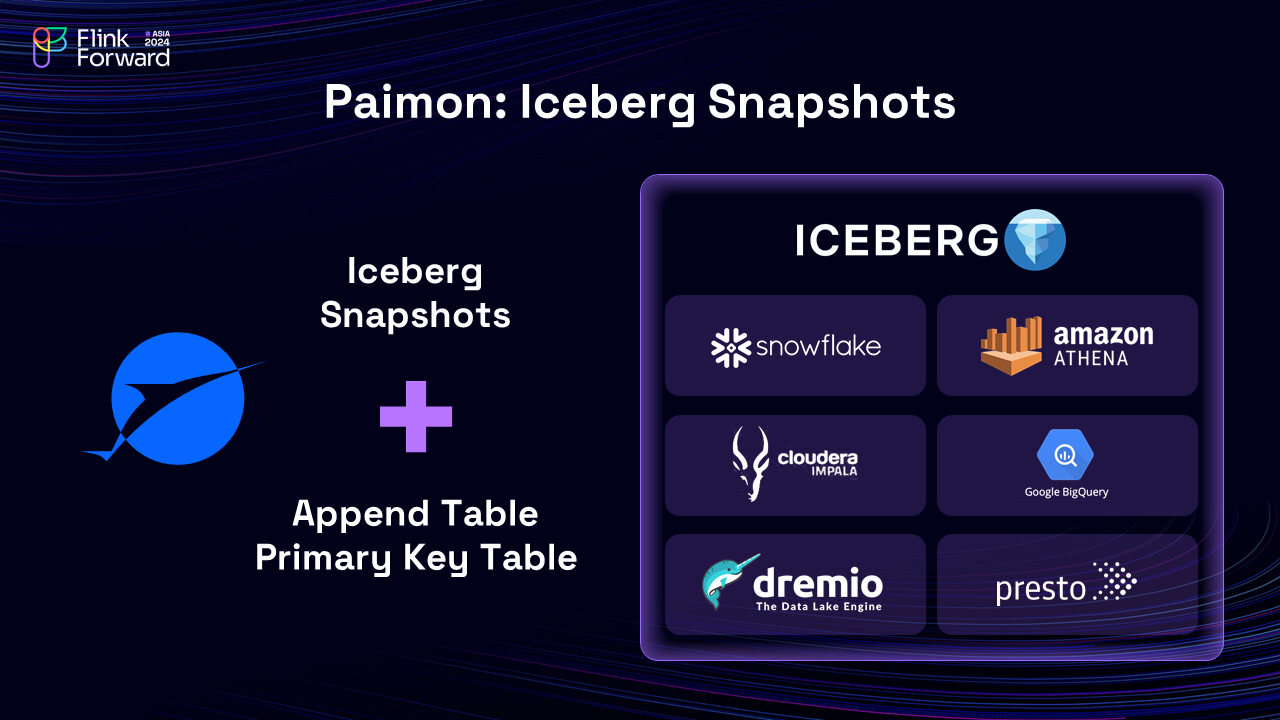
Finally, Paimon also welcomes Iceberg users by providing Iceberg compatible snapshots. Iceberg users can query Paimon tables just like Iceberg tables with their favorite tools, including Amazon Athena, Impala, Presto and much more.
To conclude, this article has provided an in-depth overview of Paimon, its key features, and its role in addressing the challenges faced by big data systems. For those interested in exploring Paimon further, the official Paimon website offers a wealth of resources and the latest version for download. We also welcome developers to visit our source code repository on GitHub to collaborate and build the lake format with efficiency and rich features together.
Harnessing Streaming Data for AI-Driven Applications with Apache Flink
How we build a Scalable, Cost-effective Cloud-Native Streaming platform in Lalamove

207 posts | 58 followers
FollowApache Flink Community - August 21, 2025
Apache Flink Community - May 30, 2025
ApsaraDB - March 20, 2026
Alibaba EMR - August 5, 2024
Alibaba Cloud Big Data and AI - December 29, 2025
Apache Flink Community - July 5, 2024
207 posts | 58 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More Big Data Consulting for Data Technology Solution
Big Data Consulting for Data Technology Solution
Alibaba Cloud provides big data consulting services to help enterprises leverage advanced data technology.
Learn More Data Lake Formation
Data Lake Formation
An end-to-end solution to efficiently build a secure data lake
Learn More Big Data Consulting Services for Retail Solution
Big Data Consulting Services for Retail Solution
Alibaba Cloud experts provide retailers with a lightweight and customized big data consulting service to help you assess your big data maturity and plan your big data journey.
Learn MoreMore Posts by Apache Flink Community

