This article is based on a presentation given at Flink Forward Asia Singapore 2025 by Richard Chen, Executive Vice President and Head of Supply Technology at Lazada Group. The implementation described represents the collaborative efforts of the entire Lazada technical team and demonstrates the practical application of Apache Flink and Alibaba Cloud Hologres in large-scale e-commerce environments.
In the rapidly evolving landscape of e-commerce, the ability to make data-driven decisions in real-time has become a critical competitive advantage. Lazada Group, one of Southeast Asia's leading e-commerce platforms, faced the monumental challenge of managing billions of product SKUs across six countries while providing personalized experiences to millions of customers. This article explores Lazada Group's journey in building a comprehensive product selection platform using Alibaba Cloud's Realtime Compute for Apache Flink and Hologres, demonstrating how modern stream processing and real-time analytics can transform e-commerce operations at scale.

Product selection in e-commerce is fundamentally different from traditional retail. While a physical 7-Eleven store might carry 2,500 SKUs constrained by physical space, e-commerce platforms can list millions of products in a single category. However, the challenge lies not in the unlimited storage capacity, but in the limited screen real estate and the need to provide personalized, relevant product recommendations to each customer.
Lazada operate in six diverse markets with a massive supply ecosystem that includes local sellers, cross-border merchants, and international suppliers. This creates a tremendously complex environment where we must efficiently manage and analyze billions of product SKUs while ensuring optimal user experience through intelligent product selection and real-time analytics.
The product selection process involves three critical layers of operation. The foundational layer consists of data services that provide the infrastructure for all product-related information. Above this, we have the selection layer where SKUs are grouped into pools and processed according to business requirements. Finally, the analytics layer enables business intelligence teams to perform real-time analysis and make data-driven decisions.
This multi-layered approach becomes particularly crucial during high-traffic events like our mega sales campaigns, similar to Alibaba's Double 11. During these peak periods, we need to analyze product performance in real-time, identify inventory risks, detect potential fraud, and monitor competitive activities. The ability to make business decisions within minutes, or even seconds, can determine the success of an entire campaign.
 Business-Side Challenges
Business-Side Challenges
From a business perspective, Lazada inherited infrastructure from Alibaba, which initially created scattered data silos across different business units. Our supply team, retail 1P business, cross-border operations, and marketplace divisions each maintained their own data sources for products and SKUs. This fragmentation significantly hindered efficiency when business teams needed to create consolidated data pools for comprehensive product analysis.
Data freshness presented another critical challenge. In our previous system, launching a new product or updating product properties could take more than a day to sync across all systems. This delay made it impossible to rely on outdated data for time-sensitive business decisions, particularly during flash sales or promotional campaigns where market conditions change rapidly.
The data richness was also limited by our previous technical architecture. Business teams frequently requested additional metrics and tags to better understand product performance and customer preferences, but our legacy system couldn't accommodate these evolving requirements efficiently.
From a technical standpoint, our previous architecture suffered from several significant limitations. Full-scale data synchronization took more than a day to complete, which was unacceptable for a fast-paced e-commerce environment. The system's throughput was limited and couldn't handle the high TPS (Transactions Per Second) demands that our business operations required.
Cost effectiveness remained a persistent concern, with high machine resource costs and substantial maintenance overhead consuming valuable technical resources. These limitations made it clear that we needed a comprehensive solution that could support massive data volumes with scalable efficiency and lower operational costs.
The technical challenges were compounded by the need to support heterogeneous data sources, real-time streaming capabilities, and the ability to perform both batch and stream processing efficiently. Our legacy system simply couldn't meet these evolving requirements while maintaining the performance and reliability standards that our business demanded.

The emergence of mature stream processing technologies, particularly Apache Flink, presented us with unprecedented opportunities to address our challenges. The Flink community's contributions, along with Alibaba's extensive development work, had created a robust ecosystem for batch and streaming integration that could handle our complex requirements.
The capability to support heterogeneous data sources was particularly appealing, as Lazada utilizes various data sources and technologies inherited from Alibaba. The open-source nature of these technologies meant that we could leverage community innovations while maintaining the flexibility to customize solutions for our specific needs.
This technological foundation enabled us to envision a unified platform that could seamlessly integrate real-time streaming with batch processing, providing the flexibility and performance required for modern e-commerce operations.

Our solution centers around Alibaba Cloud’s Realtime Compute for Apache Flink and Hologres as core components, creating a unified architecture that supports both real-time streaming and batch processing capabilities. This architecture provides runtime availability through mature container and resource scheduling systems, along with sophisticated task management capabilities.
The platform seamlessly integrates with various databases that Lazada already uses, minimizing integration complexity and reducing migration risks. Support for common message queues, including Kafka and MetaQ, ensures compatibility with our existing data pipeline infrastructure.
For batch computing, we leverage MaxCompute (internally called ODPS) for both input and output operations. Hologres provides exceptional performance for both batch and stream processing, supporting the high-throughput demands of our product selection platform while maintaining low latency for real-time analytics.
This integrated approach enables our business teams to create product selection tasks with a single click, automatically generating the most promising SKUs available on the platform for specific markets and campaigns. The system supports real-time analysis capabilities, allowing business teams to monitor campaign performance and make inventory adjustments during live events like flash sales.

Our analysis revealed that approximately 70% of the metrics in our e-commerce platform come from offline batch data warehouse operations, typically with T+1D (next day) latency. The remaining 30% consists of incremental data that requires more timely updates, which we further categorized into two distinct streams.
Half of the incremental data comes from hourly batch updates (T+1H), which includes aggregated metrics and processed analytics that don't require real-time processing but need more frequent updates than daily batches. The other half consists of real-time streaming data (T+1S) that includes customer browsing behavior, order placement activities, GMV calculations, and dynamic pricing changes.
This real-time component is particularly critical because sellers can change prices at any time, and the platform can launch campaigns or create subsidy vouchers instantly. These dynamic changes must be reflected immediately in our incremental data streams to ensure accurate product selection and pricing information.
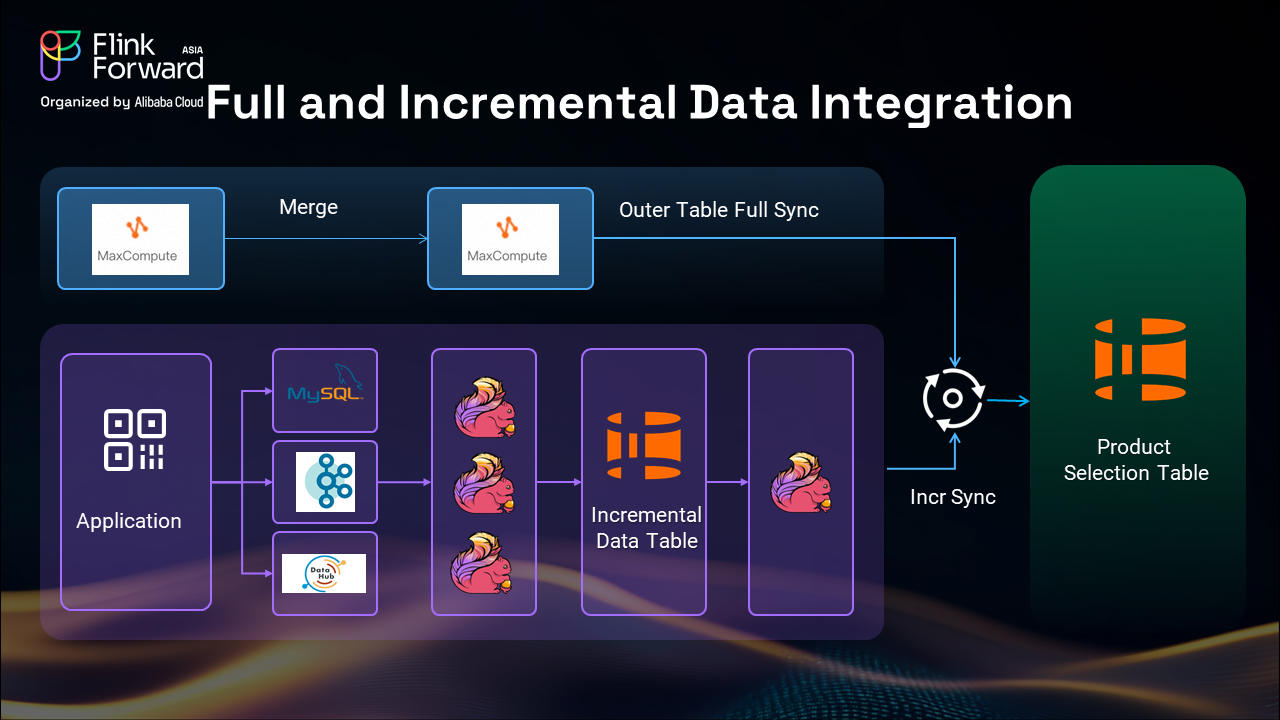
For the batch data component, we use table syncing from MaxCompute to Hologres, leveraging the unified metadata management across the Alibaba ecosystem. This approach, proven successful in Taobao's operations, provides reliable and efficient batch data processing.
The incremental data processing involves multiple data sources including MySQL, Kafka, and hourly data updates from MaxCompute. We use Flink to synchronize this data to an intermediate incremental data table in Hologres, which serves as a consolidation point for different data sources.
This intermediate table approach provides several advantages. First, it enables easier binlog replay and flexible recovery mechanisms, ensuring data integrity during disaster recovery scenarios. Second, it allows us to consolidate heterogeneous upstream data sources at this intermediate stage rather than at the final product selection table, reducing processing time and complexity.
The intermediate incremental data table also serves as a buffer for external system data, helping to optimize storage costs by maintaining only the necessary incremental changes. We use Flink pipelines to manage binlog updates, maintaining one primary partition for business operations and two standby partitions for quick switching during disaster recovery or data backfill operations.
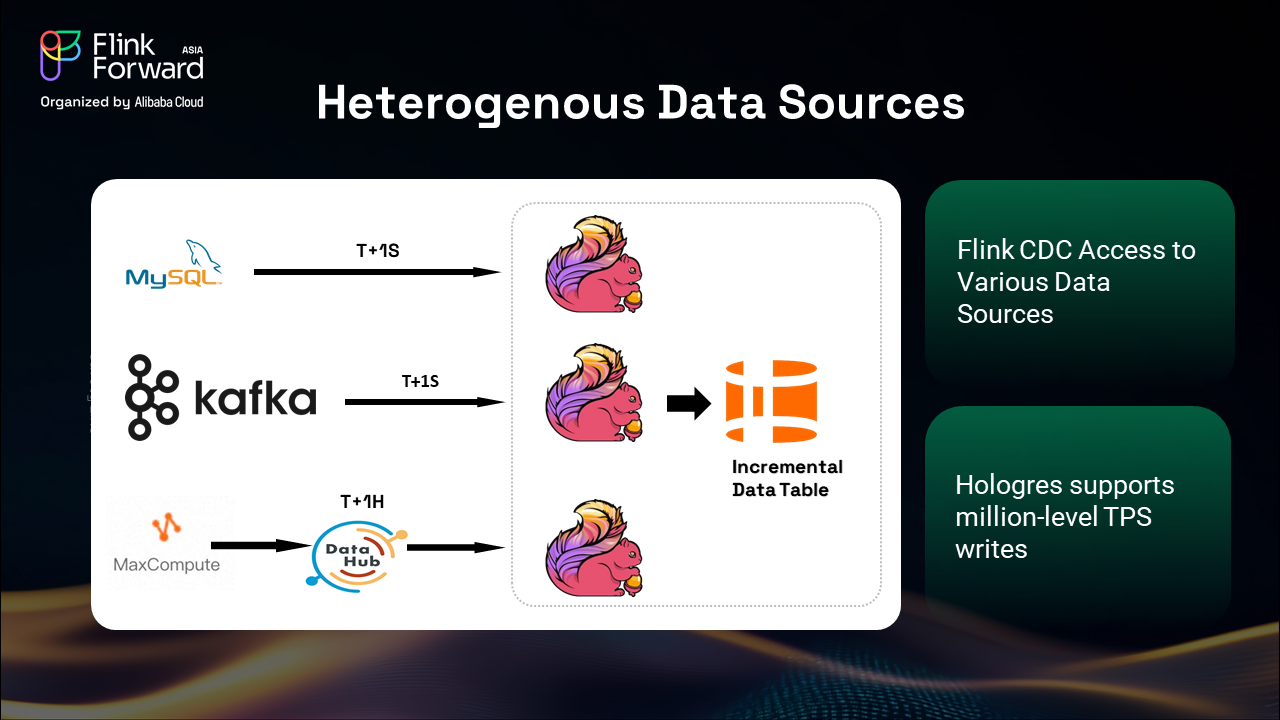
Our platform successfully handles diverse data sources through Flink's Change Data Capture (CDC) capabilities. Real-time data from MySQL and Kafka streams are processed with sub-second latency (T+1S), while hourly updates from MaxCompute provide T+1H processing for less time-sensitive metrics.
Flink CDC access enables us to monitor data changes across various sources, while Hologres supports million-level TPS writes, ensuring that our system can handle peak traffic loads during major sales events. This combination provides the scalability and performance required for enterprise-level e-commerce operations.
The sharding technology in Hologres, combined with its high TPS write capacity, allows us to process millions of transactions per second from Kafka and MaxCompute through Flink pipelines. This capability is essential for maintaining real-time data freshness across our massive product catalog.
Our daily operational workflow demonstrates the sophisticated orchestration required for large-scale e-commerce data processing. Each day begins with creating an initial partition in our data table, starting from the previous day's offline full data snapshot.
The system monitors synchronization tasks and triggers binlog replay operations based on the incremental data table once initial synchronization completes. This process includes sophisticated monitoring to determine when replay tasks finish, considering that new real-time data continues to arrive even during the replay process.
We use two trigger points to identify task completion: monitoring data income patterns to detect when incremental replay is finished, and tracking the temporal proximity of replayed data to current time. This dual-trigger approach ensures comprehensive data capture while maintaining operational efficiency.
The lightweight solution combines full cycle batch processing with real-time incremental updates through the intermediate incremental data table on Hologres, providing both reliability and performance for our daily operations.
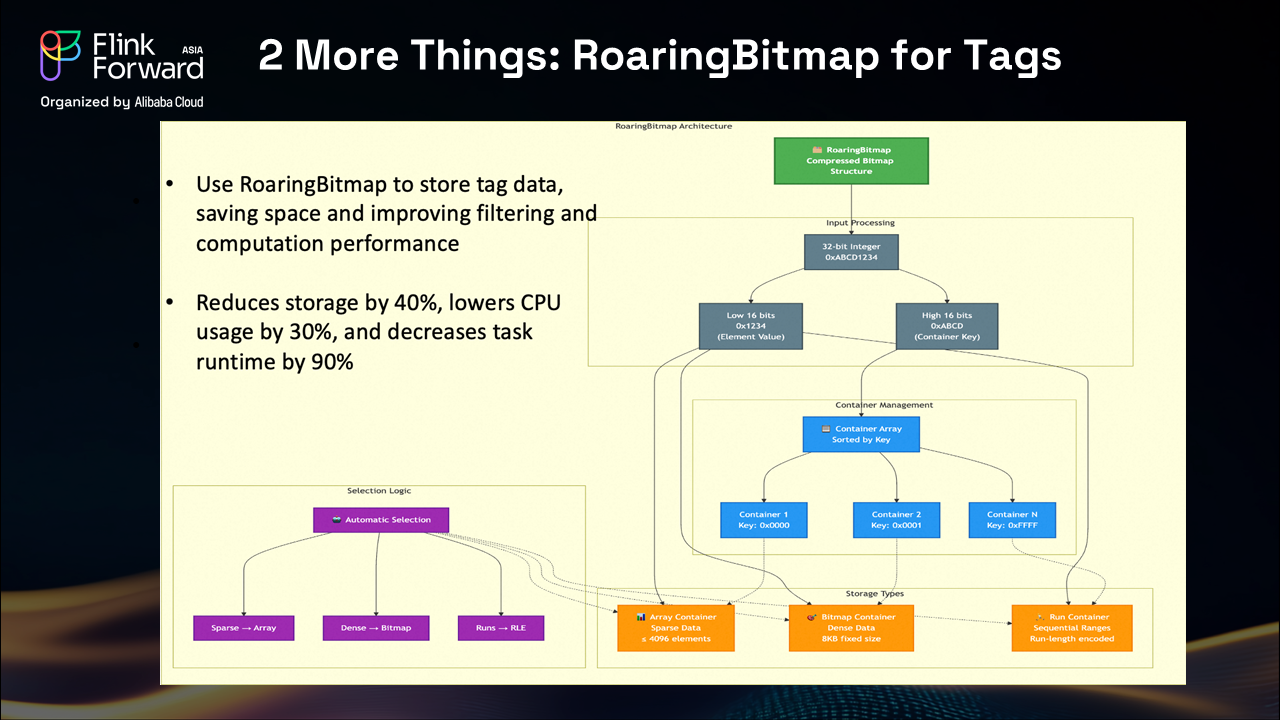
One of our most significant technical innovations involves the implementation of Roaring Bitmap technology for tag management. In e-commerce platforms, two systems heavily depend on tagging: user profiling and product categorization. For users, we need to understand customer preferences including category preferences, item types, and price ranges. For products, we must tag items with detailed attributes like color, origin, material, and style characteristics.
Tags create substantial challenges for data systems due to their dynamic nature and sheer volume. In our initial Hologres deployment, we used arrays to store tags, which created significant performance bottlenecks, particularly during tag retrieval and analysis operations.
Our team investigated and implemented Roaring Bitmap technology, which compresses tag data efficiently using 32-bit integers split into lower 16 and higher 16 bits. The system utilizes three types of data containers: sparse data with array containers, high-density data with bitmap containers, and sequential ranges with run containers.
This implementation resulted in remarkable performance improvements: 40% reduction in storage requirements, 30% decrease in CPU usage, and an overall 90% reduction in runtime for tag-related operations. These improvements significantly enhanced our product selection platform's ability to handle complex tagging scenarios at scale.

E-commerce platforms generate substantial amounts of semi-structured data, particularly from social media comments, product reviews, and complex business relationships. Our product selection platform needed to handle scenarios where products are connected to campaigns, orders, and various business decisions, creating intricate semi-structured data relationships.
Hologres' JSON-B support provided the flexibility we needed for columnar storage while maintaining the ability to switch between storage modes based on specific requirements. When columnar storage isn't needed, we use standard storage modes, but when analytical queries require columnar access, we can easily switch to optimized columnar storage.
This flexibility proved invaluable for product selection scenarios involving downstream teams, especially when combining product data with business operations at granularities finer than individual SKUs. The JSON-B implementation enables us to handle complex business relationships while maintaining query performance and storage efficiency.

The implementation of our Flink and Hologres-based product selection platform has delivered substantial business value across multiple dimensions. Today, we operate more than 200 real-time tasks processing over 20TB of data daily, with incremental updates handling 100 million records per day.
This high-throughput capability enables our business teams to consume real-time incremental metrics and make timely business decisions during critical periods like flash sales and promotional campaigns. The platform's ability to process massive data volumes while maintaining real-time responsiveness has transformed how we approach product selection and campaign management.

From a technical perspective, our simplified architecture based on Flink and Hologres has significantly reduced both development and maintenance costs compared to our previous system. The unified platform approach eliminated the complexity of managing multiple disparate systems while providing superior performance and reliability.
Machine resource costs have been reduced by 50%, allowing us to reinvest savings into expanding our SKU selection capabilities and improving customer experience. The streamlined architecture also reduced the technical expertise required for system maintenance, enabling our team to focus on innovation rather than operational overhead.
The platform's ability to support multiple data freshness requirements means we can accommodate both time-critical real-time analysis during campaigns and comprehensive historical analysis for strategic planning. This flexibility has proven invaluable for supporting diverse business requirements across our organization.
Our enhanced product selection platform now supports multiple types of data freshness and analysis timeframes based on business requirements. Whether teams need real-time data during campaign execution or comprehensive historical analysis for yearly planning, the platform delivers appropriate data granularity and performance.
The elimination of previous data limitations has enabled significant expansion of our tagging capabilities. We can now import extensive tag datasets, including leveraging Tmall and Taobao product tags from the Chinese market through translation and adaptation processes. This capability has dramatically improved our system's ability to understand and categorize products effectively.
Support for external data sources has been greatly enhanced through Hologres' capability to handle diverse upstream systems. Whether data originates from Alibaba's internal systems or external seller platforms, our unified platform can efficiently process and integrate information from multiple sources.
The platform now functions as a hybrid transactional and analytical system, providing business teams with comprehensive capabilities for both operational tasks and strategic analysis. This unified approach has eliminated the need for multiple specialized systems while improving overall efficiency and data consistency.

Looking ahead, our technical planning focuses heavily on artificial intelligence integration and advanced analytics capabilities. We have already begun implementing AI-powered product selection for theme-based scenarios, such as creating campaigns for Christmas, F1 events, or celebrity concerts in specific markets.
Our AI-powered product selection system can recommend the most promising SKUs from billions of available products based on campaign themes and historical performance data. This capability leverages vector query features in Hologres and upcoming enhancements like 64-bit Roaring Bitmap support, which will enable even more sophisticated tagging and AI-generated product understanding.
We expect AI-generated product tags to create more data than human-generated tags, requiring enhanced storage and processing capabilities. The expanded Roaring Bitmap support will be crucial for handling this increased data volume while maintaining query performance.
Our future development includes capabilities for identifying products not yet available on our platform or even in the broader e-commerce ecosystem. This involves detecting conceptual items and emerging trends that could represent new business opportunities.
Integration with open search engines and AI-powered trend analysis will enable us to identify new assortment opportunities proactively. This capability aims to help our business teams capture market opportunities in advance by identifying emerging customer demands and product categories.
The never-ending nature of customer satisfaction drives continuous innovation in product selection. Customers constantly seek more attractive, newer, and more satisfying product assortments, creating ongoing opportunities for our technical team to apply cutting-edge technologies to solve real business problems.
Our implementation revealed several critical performance optimization strategies that are essential for large-scale e-commerce platforms. The use of intermediate data tables as buffers significantly improved system resilience and recovery capabilities while reducing the complexity of data source management.
Partitioning strategies proved crucial for maintaining system availability during maintenance and disaster recovery scenarios. Our three-partition approach (one primary, two standby) enables seamless switching without service interruption, ensuring business continuity during critical operations.
The combination of Flink's stream processing capabilities with Hologres' high-performance storage created synergies that exceeded the sum of individual component capabilities. This integration demonstrates the importance of selecting complementary technologies that enhance each other's strengths.
Designing for scalability from the beginning proved essential for handling Lazada's growth trajectory. Our architecture accommodates increasing data volumes, user traffic, and business complexity without requiring fundamental redesign.
The heterogeneous data source support ensures that we can integrate new data streams and business systems as Lazada expands into new markets or adds new business lines. This flexibility has been crucial for supporting our rapid growth across Southeast Asia.
Resource optimization through efficient data processing and storage strategies enables us to scale cost-effectively. The 50% reduction in machine costs while improving performance demonstrates that proper architectural choices can deliver both technical and economic benefits.
Our experience highlighted several key principles for designing effective data architectures in e-commerce environments. First, the importance of separating concerns through layered architecture enables independent optimization of different system components while maintaining overall system coherence.
Second, the value of intermediate data layers for managing complexity and providing flexibility cannot be overstated. These layers serve as buffers, transformation points, and recovery mechanisms that significantly improve system resilience and maintainability.
Third, the need to design for both batch and streaming workloads from the beginning ensures that systems can handle diverse business requirements without architectural compromises. The unified approach we adopted with Flink and Hologres exemplifies this principle.
Choosing technologies that complement each other and align with existing infrastructure reduces integration complexity and accelerates implementation timelines. Our selection of Flink and Hologres leveraged existing Alibaba ecosystem investments while providing the advanced capabilities we needed.
Open-source technologies with strong community support provide long-term sustainability and continuous innovation. The active Flink community ensures ongoing development and support for emerging use cases in stream processing and real-time analytics.
Performance characteristics must align with business requirements, particularly for systems handling high-volume, low-latency workloads. The million-level TPS capability of Hologres was essential for meeting our peak traffic demands during major sales events.
The transformation of Lazada's product selection platform using Apache Flink and Hologres demonstrates the profound impact that modern stream processing and real-time analytics technologies can have on e-commerce operations. Our journey from a fragmented, batch-oriented system to a unified, real-time platform has delivered substantial benefits across technical, operational, and business dimensions.
The 50% reduction in infrastructure costs, combined with dramatic improvements in data freshness and analytical capabilities, validates the strategic value of investing in modern data architectures. More importantly, the platform's ability to support real-time decision-making during critical business events has transformed how we approach campaign management and customer experience optimization.
Our experience illustrates that successful digital transformation requires more than just technology adoption; it demands thoughtful architectural design, careful technology selection, and a deep understanding of business requirements. The combination of Apache Flink's stream processing capabilities with Hologres' high-performance analytics created synergies that enabled capabilities neither technology could provide independently.
As we continue to evolve our platform with AI integration and advanced analytics capabilities, the foundation we've built provides the flexibility and performance required for future innovations. The never-ending journey of satisfying customer demands drives continuous improvement, ensuring that our technical investments deliver lasting business value.
For organizations considering similar transformations, our experience demonstrates that the benefits of modern stream processing and real-time analytics extend far beyond technical improvements. The ability to make data-driven decisions in real-time, support diverse business requirements with unified infrastructure, and scale cost-effectively creates competitive advantages that directly impact business success.
The future of e-commerce lies in the ability to process and analyze data at the speed of business, and our implementation of Flink and Hologres has positioned Lazada to thrive in this data-driven landscape. As we continue to push the boundaries of what's possible with real-time analytics and AI-powered insights, we remain committed to sharing our learnings with the broader technical community.
Building a Real-Time Advertising Lakehouse: Alibaba Mama's Practice with Flink & Paimon
Accelerate Data Ingestion in Real-time Lakehouse with Apache Flink CDC

206 posts | 58 followers
FollowApache Flink Community - August 1, 2025
Apache Flink Community - July 28, 2025
Ila Bandhiya - May 7, 2026
Alibaba Clouder - October 29, 2020
Hologres - June 16, 2022
Apache Flink Community - March 7, 2025
206 posts | 58 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More Media Solution
Media Solution
An array of powerful multimedia services providing massive cloud storage and efficient content delivery for a smooth and rich user experience.
Learn More MaxCompute
MaxCompute
Conduct large-scale data warehousing with MaxCompute
Learn More E-Commerce Solution
E-Commerce Solution
Alibaba Cloud e-commerce solutions offer a suite of cloud computing and big data services.
Learn MoreMore Posts by Apache Flink Community

