In today's fast-paced digital landscape, organizations are continuously seeking ways to harness real-time data for immediate business insights. Traditional data architectures often struggle with latency issues, data consistency challenges, and complex infrastructure requirements. This is where Apache Flink CDC (Change Data Capture) emerges as a transformative solution for accelerating data ingestion in real-time lakehouse architectures.
This comprehensive guide explores how Apache Flink CDC enables seamless real-time data ingestion to power modern lakehouse architectures, addressing the critical needs of enterprises requiring up-to-the-minute data analytics and decision-making capabilities.

Traditional lakehouse architectures have served organizations well, but they come with inherent limitations that impact modern business requirements:
Data Freshness Challenges: In conventional setups, operational data from application logs and database changes are ingested into data lakes and processed using batch-oriented computing engines like Apache Spark. This batch processing approach typically results in data freshness windows of one to three hours, which is insufficient for real-time business decision-making.
Limited CDC Support: Traditional formats like Apache Iceberg, while powerful for many use cases, have limitations when it comes to handling change logs effectively. When you need to update existing records, the process becomes complex and resource-intensive.
Infrastructure Complexity: Traditional CDC ingestion pipelines require multiple systems working in coordination—snapshot synchronization tools, change log processors, schedulers, and merge operations—creating a complex data infrastructure that's difficult to maintain and scale.
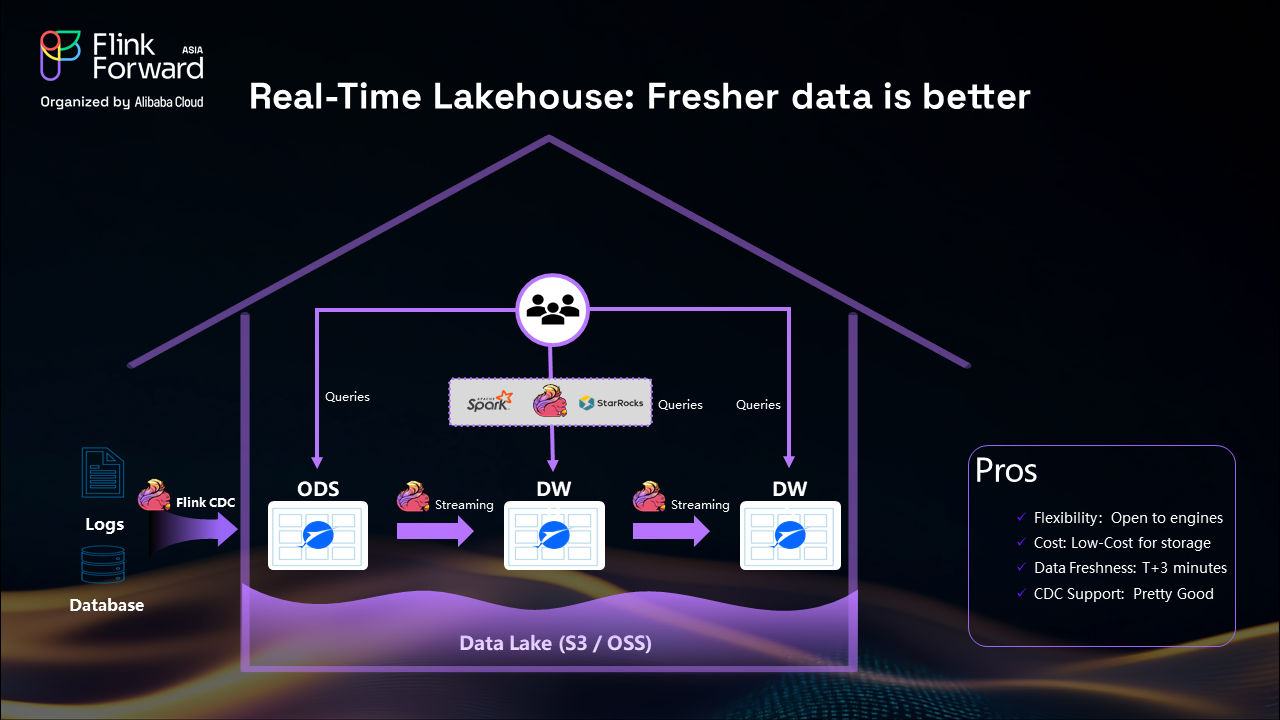
The transformation to a real-time lakehouse addresses these fundamental limitations by replacing batch processing with streaming architectures:
Streaming-First Approach: By replacing Spark batch processing with Apache Flink streaming, end-to-end data latency improves from one hour to minutes, enabling near real-time analytics and decision-making.
Advanced Change Log Support: Migrating from Iceberg to Apache Paimon provides superior change log processing capabilities, making CDC operations more efficient and reliable.
Unified Architecture: Real-time lakehouses eliminate the complexity of maintaining multiple systems by providing a unified streaming data ingestion framework.
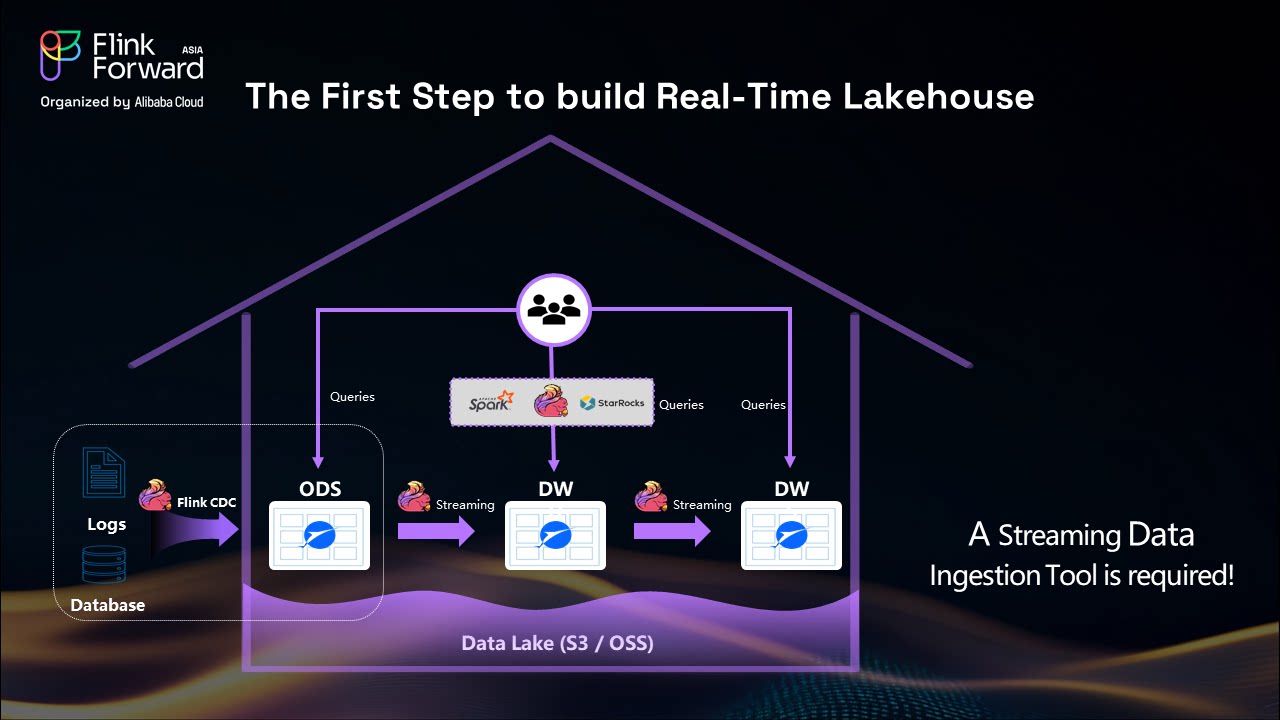
Creating an effective real-time lakehouse requires careful consideration of four essential components:
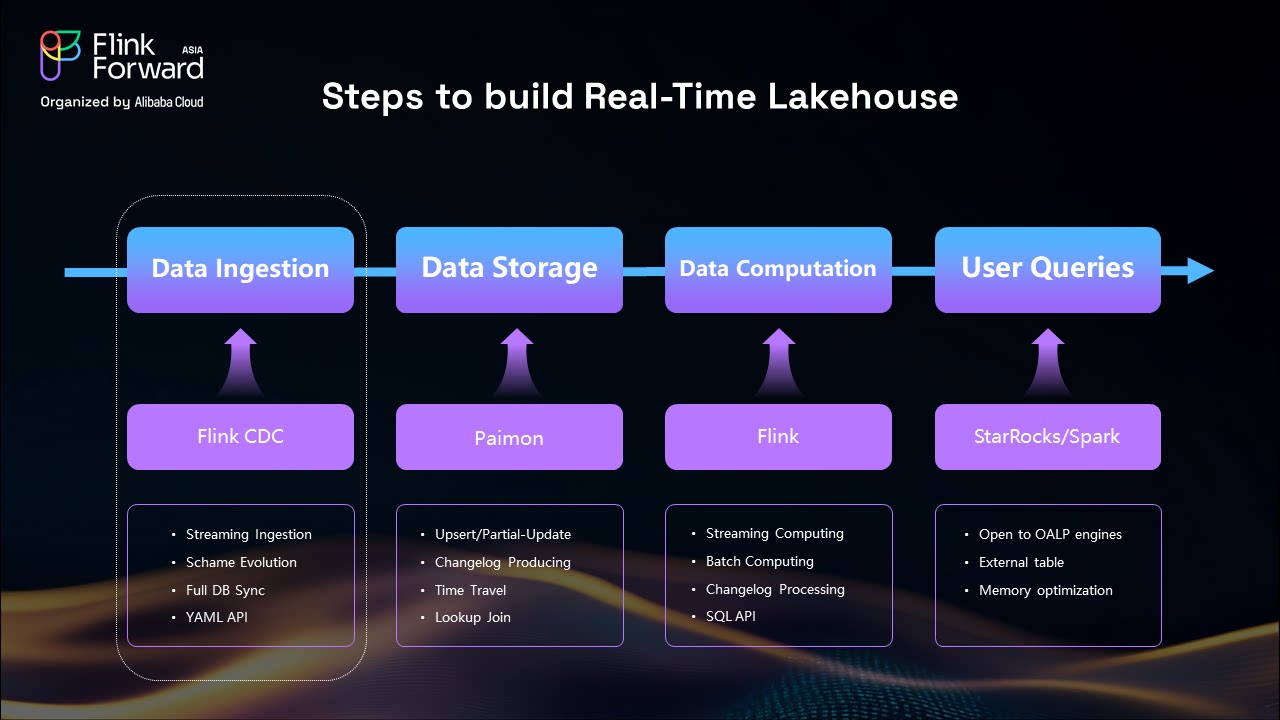
The foundation of any real-time lakehouse is a robust streaming data ingestion tool. Apache Flink CDC serves as this critical component, enabling seamless data capture from various sources including business databases and message queues.
Choosing the right storage format is crucial. Apache Paimon excels in change log support, making it ideal for real-time lakehouse architectures where data updates and modifications are frequent.
Apache Flink serves as the streaming processing engine, providing the computational power needed for real-time data processing with sub-second latency capabilities.
The final component is a real-time OLAP engine like StarRocks, optimized for immediate data analytics and query processing on streaming data.

Apache Flink CDC is an end-to-end streaming data ingestion tool that implements unified snapshot reading and incremental reading based on database CDC technology. It revolutionizes how organizations handle data synchronization by providing a single, unified framework for both historical and real-time data capture.
Unified Data Capture: Flink CDC automatically handles both snapshot data (historical records) and incremental data (real-time changes) within a single framework. Users don’t need to manage separate systems for different types of data synchronization.
Automatic Log Reading: The system reads incremental changes directly from database binary logs (such as MySQL binlog) while simultaneously handling snapshot data through JDBC queries.
Consistent Data Delivery: Downstream systems receive a real-time, consistent stream of data without needing to understand the complexities of snapshot versus incremental processing.

Traditional CDC Complexity: Conventional approaches require maintaining multiple systems—snapshot synchronization tools (like DataX or Sqoop), change log processors (like Debezium or Canal), schedulers, and merge operations. This results in: - Complex infrastructure management - Data consistency challenges - Poor data freshness due to periodic merge operations - High learning curve for development teams
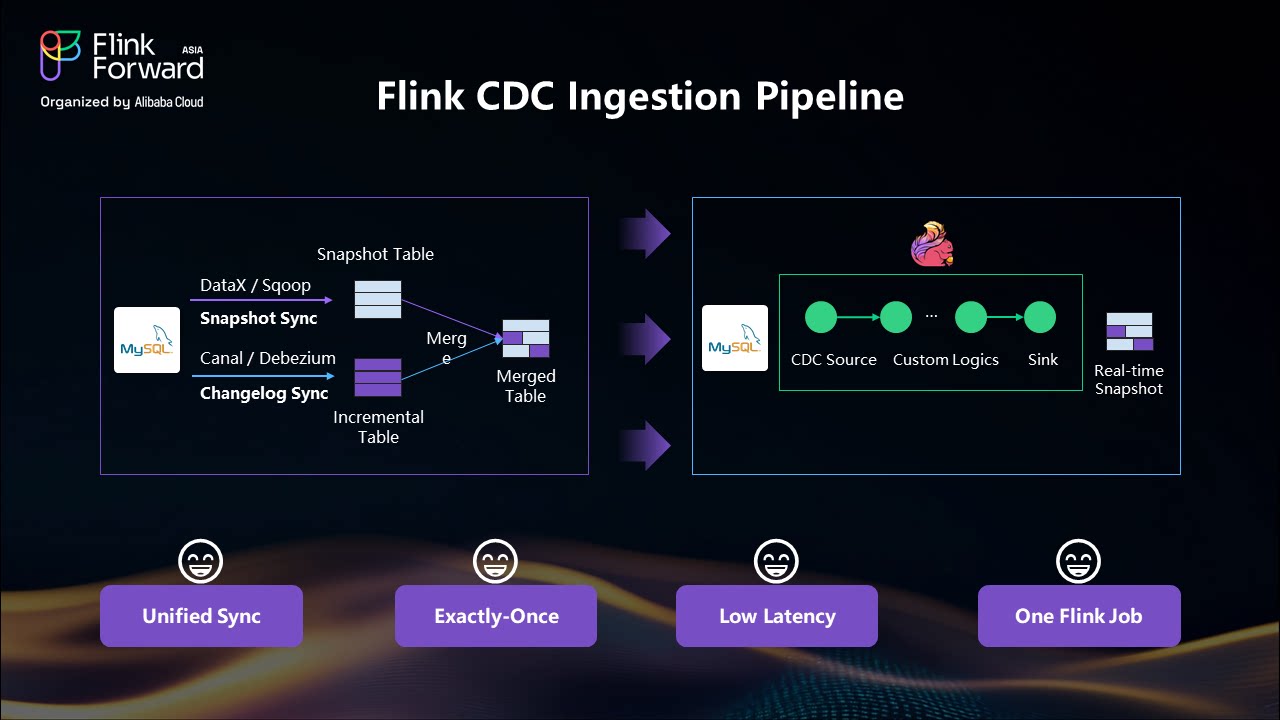
Flink CDC Simplification: With Flink CDC, the entire pipeline becomes a single Flink job that: - Handles both snapshot and incremental data automatically - Provides exactly-once semantics for data consistency - Delivers sub-second latency for real-time processing - Simplifies maintenance and operations
Apache Flink CDC leverages Flink's exactly-once processing guarantees to ensure data consistency across the entire pipeline. This eliminates the data quality issues commonly associated with traditional CDC approaches where merge operations can introduce inconsistencies.
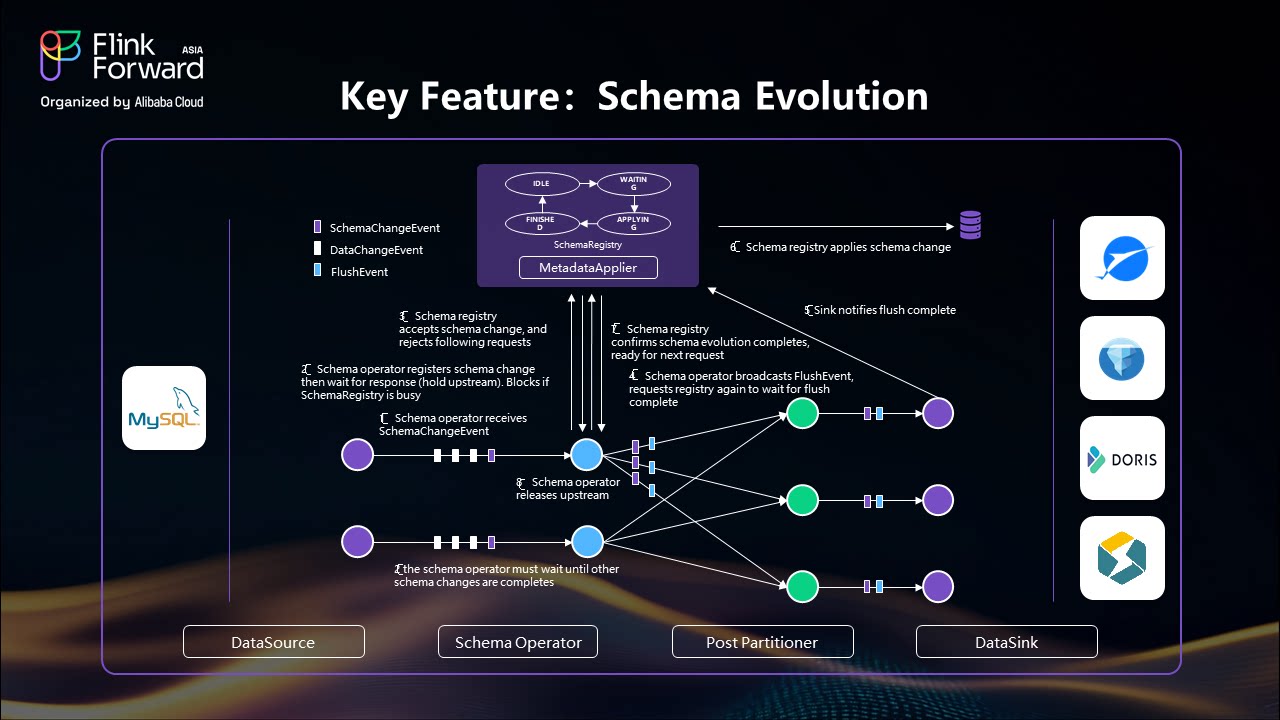
One of Apache Flink CDC's most powerful features is automatic schema evolution support. When schema changes occur in upstream databases (such as adding columns, dropping columns, or renaming fields), Flink CDC automatically applies these changes to downstream tables without manual intervention.
The framework handles three types of events:
When a schema change occurs, Apache Flink CDC:
This seamless process ensures zero downtime during schema modifications while maintaining data integrity throughout the pipeline.
Apache Flink CDC supports various schema evolution scenarios including adding columns, dropping columns, changing default values, modifying column comments, and renaming existing columns. The framework automatically propagates these changes across the entire data pipeline, from source databases to downstream lakehouse storage systems.

Apache Flink CDC provides powerful transformation capabilities including:
Projection and Filtering: Select specific columns and filter records based on custom expressions using SQL-like syntax. This reduces data volume and improves downstream processing efficiency.
Computed Columns: Generate new fields using built-in functions or user-defined functions. For example, calculate age by subtracting 18 from a birth year field, or create composite keys from multiple columns.
Primary Key and Bucket Key Definition: Configure data partitioning and organization strategies to optimize query performance and data distribution in downstream lakehouse storage systems.
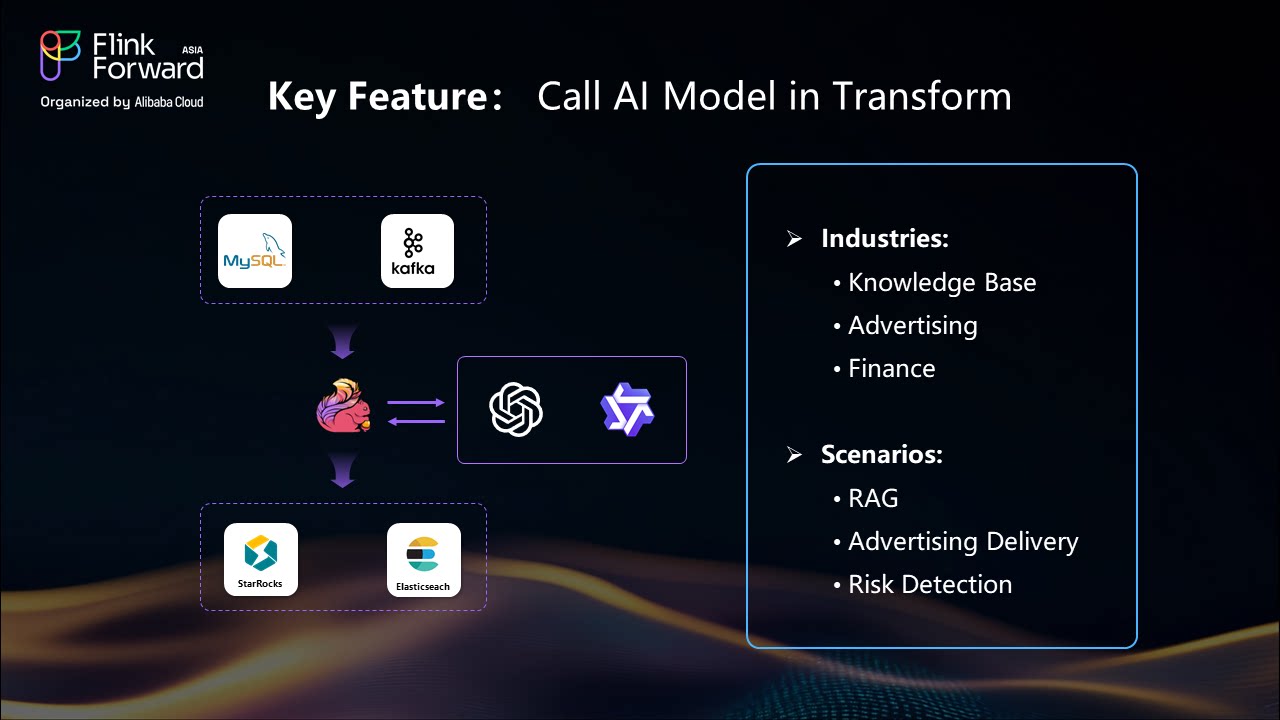
The integration of AI models within Apache Flink CDC pipelines enables sophisticated real-time data processing scenarios:
Embedding Generation: Generate vector embeddings for text content using OpenAI models directly within the streaming pipeline. This enables real-time semantic search capabilities and content recommendation systems.
Real-time Enrichment: Process streaming data through machine learning models for immediate insights, such as sentiment analysis, content classification, or anomaly detection.
Intelligent Data Transformation: Apply AI-driven transformations to enhance data quality and value, including automated data cleansing, entity recognition, and content summarization.
Here's a practical example of AI integration as demonstrated in the original presentation:
Use Case: Article content processing with automatic embedding generation
Technical Implementation:
transform:
- source-table: "app_db.articles"
projection: "id, title, content, get_embedding(content) as embedding_vector"
ai-models:
- name: "get_embedding"
type: "openai"
model: "text-embedding-ada-002"This approach enables sophisticated features like content recommendation, semantic search, and automated content categorization in real-time, without requiring separate batch processing jobs.

Most Common Use Case: Synchronizing entire databases to data lakes represents the most frequent implementation scenario.
Example Scenario: Consider an application database in your MySQL instance containing multiple tables with different schemas - products, shipment, and orders tables. With Apache Flink CDC, you need only one pipeline to synchronize all these tables to downstream systems like Iceberg or Paimon.
Technical Implementation:
Supported Destinations: Apache Flink CDC supports multiple downstream systems including Iceberg, Paimon, Doris, StarRocks, and others.
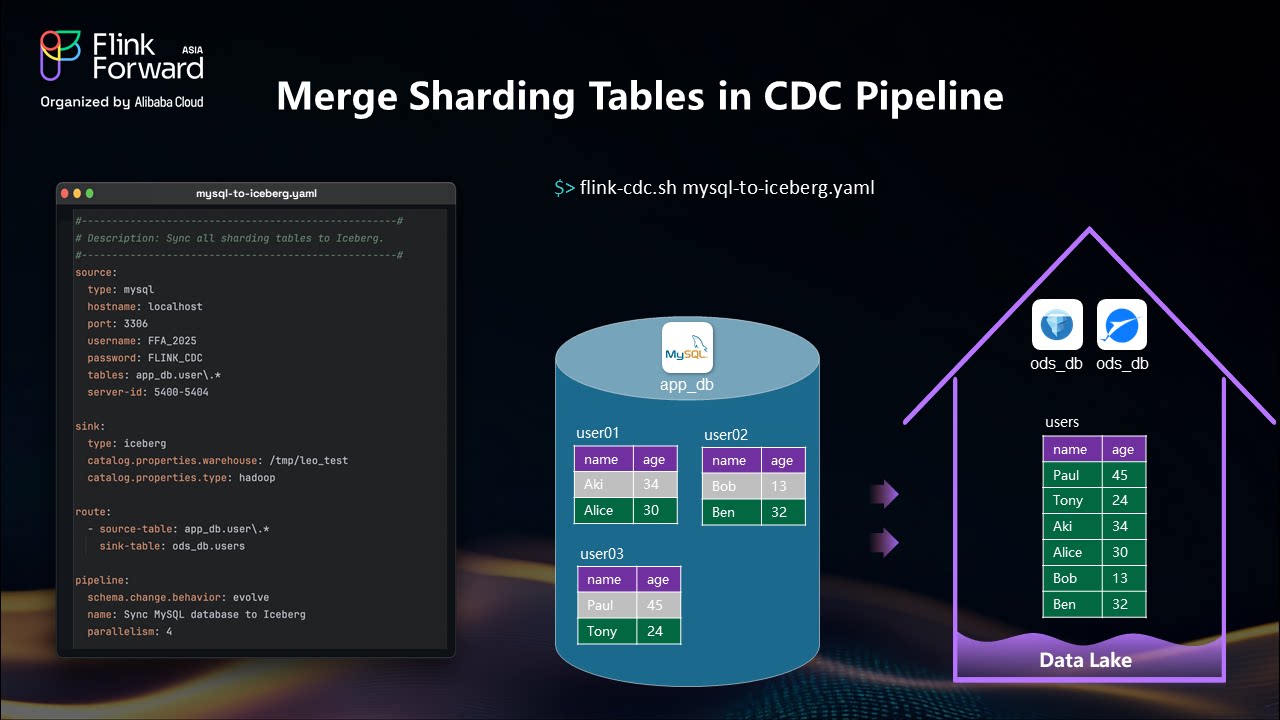
Business Context: Table sharding becomes common when businesses expand to huge scale, requiring multiple user tables like user_01, user_02, user_03.
Merging Solution: Apache Flink CDC can merge all sharded tables into a single unified table using routing rules and regular expressions.
Implementation Approach:
Benefits:
sformation and Filtering

Projection and Filtering Example: When working with tables containing multiple columns but needing only specific fields:
Scenario: Orders table with multiple columns, but you only need ID, price, and amount Solution: Define transformer rules using SQL-like expressions
Configuration Pattern:
transform:
- source-table: "app_db.orders"
projection: "id, price, amount"
filter: "price > 100 OR amount > 5"
Advanced Use Case: Real-time AI model integration for data enrichment
Implementation Example (as demonstrated in the presentation):
Practical Application: Article processing pipeline
Key Advantages:
YAML-Based Configuration: All use cases utilize YAML API for configuration, making it easy to learn and control for both humans and machines.
Single Command Deployment: Start complex pipelines with a single batch script execution.
Schema Evolution Support: Automatic handling of schema changes without manual intervention.
Regular Expression Flexibility: Leverage regular expressions for flexible table matching and routing patterns.
Apache Flink CDC has experienced tremendous community growth:

2020: Project kickoff at Ververica
2021: Implementation of unified snapshot and incremental framework
2023: Introduction of YAML API for simplified configuration
2024: Donation to Apache Software Foundation, release of versions 3.3 and 3.4



Ecosystem Expansion: - PostgreSQL pipeline source support - Enhanced Doris pipeline sink capabilities - Additional database connector support
Production Stability Improvements: - Configurable exception handling - Enhanced version compatibility - Performance optimization for large-scale deployments
Apache Flink CDC represents a paradigm shift in real-time data ingestion for modern lakehouse architectures. By providing a unified framework for both snapshot and incremental data capture, it eliminates the complexity traditionally associated with CDC pipelines while delivering superior performance and reliability.
The key benefits of adopting Flink CDC include:
As organizations continue to demand faster, more reliable data processing capabilities, Flink CDC provides the foundation for building next-generation real-time analytics platforms that can adapt to evolving business requirements while maintaining operational excellence.
The future of data processing lies in streaming-first architectures, and Apache Flink CDC is leading this transformation by making real-time data ingestion accessible, reliable, and scalable for organizations of all sizes.
Apache Flink FLIP-14: CrossGroup Operator for Graph Processing

207 posts | 58 followers
FollowApsaraDB - February 29, 2024
Apache Flink Community - March 31, 2025
Apache Flink Community - March 7, 2025
Apache Flink Community - May 10, 2024
Apache Flink Community - April 8, 2024
Apache Flink Community - August 1, 2025
207 posts | 58 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More Big Data Consulting for Data Technology Solution
Big Data Consulting for Data Technology Solution
Alibaba Cloud provides big data consulting services to help enterprises leverage advanced data technology.
Learn More Data Security Center (Original SDDP)
Data Security Center (Original SDDP)
An all-in-one data security solution that provides various features, such as sensitive data detection, classification, grading, and de-identification, to help you meet compliance requirements specified in General Data Protection Regulation (GDPR) and personal information protection
Learn More Cloud Migration Solution
Cloud Migration Solution
Secure and easy solutions for moving you workloads to the cloud
Learn MoreMore Posts by Apache Flink Community

