This blog post is based on the presentation "Unleashing the Power of Flink: Alibaba Cloud Enterprise-Grade Streaming at Scale" by Perry Huang, Product Lead of Alibaba Cloud Realtime Compute for Apache Flink at Flink Forward Asia Singapore 2025.
In today's data-driven world, real-time data processing has become not just an advantage, but a necessity for enterprises seeking to stay competitive. As businesses generate vast amounts of streaming data from applications, IoT devices, user interactions, and various other sources, the challenge of processing this information in real-time while maintaining reliability, security, and cost-effectiveness has never been more critical.
Apache Flink has emerged as a leading open-source framework for distributed stream processing. However, as organizations scale their real-time data operations, they encounter significant challenges that go beyond what standard open-source Flink can address. This is where Alibaba Cloud Realtime Compute for Apache Flink steps in, offering enterprise-grade capabilities that transform real-time data processing from a complex challenge into a competitive advantage.
Modern enterprises face four fundamental challenges when implementing real-time data processing at scale:

1. Performance vs. Cost Efficiency Organizations require low-latency data processing capabilities, but scaling infrastructure to meet these demands often results in exponentially increasing operational expenses. The traditional approach of throwing more resources at the problem becomes unsustainable as data volumes grow.
2. Operational Complexity Engineering teams find themselves spending excessive time on maintenance, troubleshooting, and system administration rather than focusing on innovation and business value creation. The complexity of managing distributed streaming systems can overwhelm even experienced teams.
3. Root Cause Analysis Difficulties When incidents occur in complex streaming pipelines, identifying the underlying cause becomes a time-consuming process that can impact business operations. Traditional monitoring tools often provide data but lack the intelligence to pinpoint actual issues.
4. AI Integration Barriers While there's strong demand for real-time AI-driven insights, integrating streaming data pipelines with AI models remains highly challenging due to architectural complexity and performance requirements.
These challenges are not unique to any single organization—they represent common obstacles faced by enterprises striving for real-time intelligence across industries.

Alibaba Cloud Realtime Compute for Apache Flink transforms these challenges into opportunities through four key innovation areas:
Our Ultra Performance Cloud Runtime Engine delivers consistent performance even as workloads grow exponentially. Unlike traditional solutions that force you to choose between speed and scale, our platform maintains sub-millisecond latency while handling massive throughput.
Intelligent auto-scaling and elastic resource adjustment capabilities actually reduce operational costs. The system dynamically grows resources when needed and shrinks them when demand decreases, automatically balancing performance with cost efficiency.
From development to operations and maintenance, everything integrates into a single, seamless experience. Development teams can focus on building innovative applications instead of juggling multiple tools and platforms.
Real-time predictions and instant insights are built directly into the streaming platform. AI capabilities aren't just add-ons—they're native features that work at stream speed.
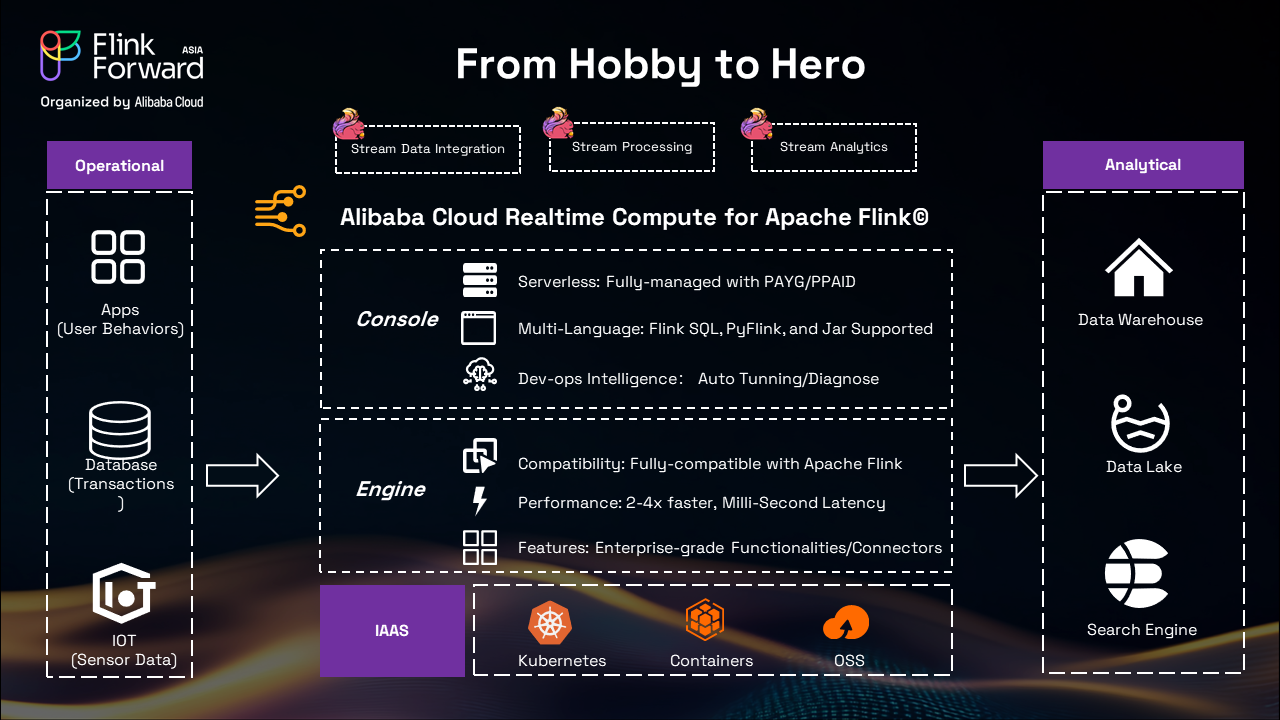
Our enterprise-grade architecture for Apache Flink encompasses three main processing stages: Stream Data Integration, Stream Processing, and Stream Analytics.
The platform supports diverse data sources including:
At the heart of the system is Alibaba Cloud Realtime Compute for Apache Flink, featuring:
The platform runs on robust infrastructure including:
Processed data flows to various destinations including:
This architecture delivers both operational and analytical capabilities, making it ideal for enterprises requiring real-time data processing at scale.

The VVR (Ververica Runtime) Engine represents our enhanced version of Apache Flink, built on the solid foundation of the open-source project while delivering significant performance improvements.
Full API Compatibility: Your existing Flink code and APIs work exactly the same way, ensuring seamless migration and adoption.
Dynamic Scaling: Adjust worker count while jobs are running, with state safely preserved throughout the scaling process.
Comprehensive Connector Ecosystem: Support for three connector families:
Dynamic Rule Updates: Update processing rules and CEP (Complex Event Processing) patterns dynamically without service interruption.
Enhanced Performance: 2x faster than open-source Flink while maintaining full compatibility.
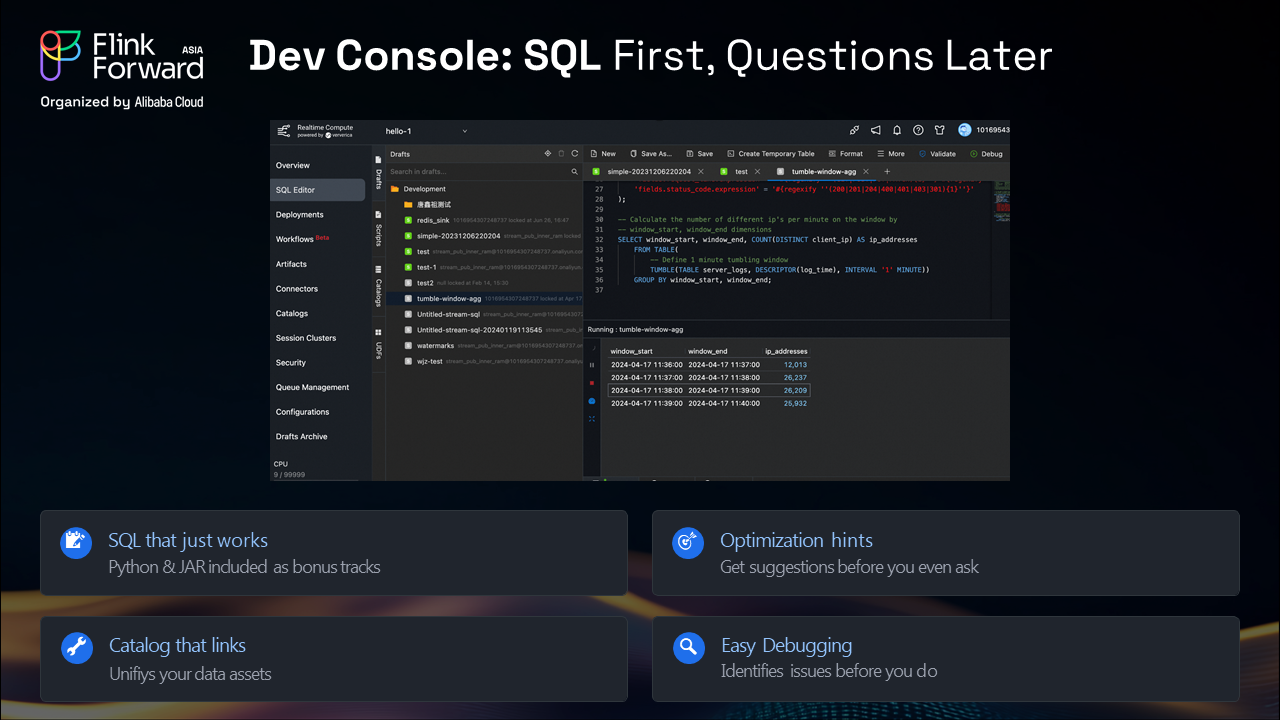
Our development console combines SQL simplicity with enterprise-grade development tools:
This professional IDE is designed specifically for stream processing, making complex real-time applications accessible to developers of all skill levels.
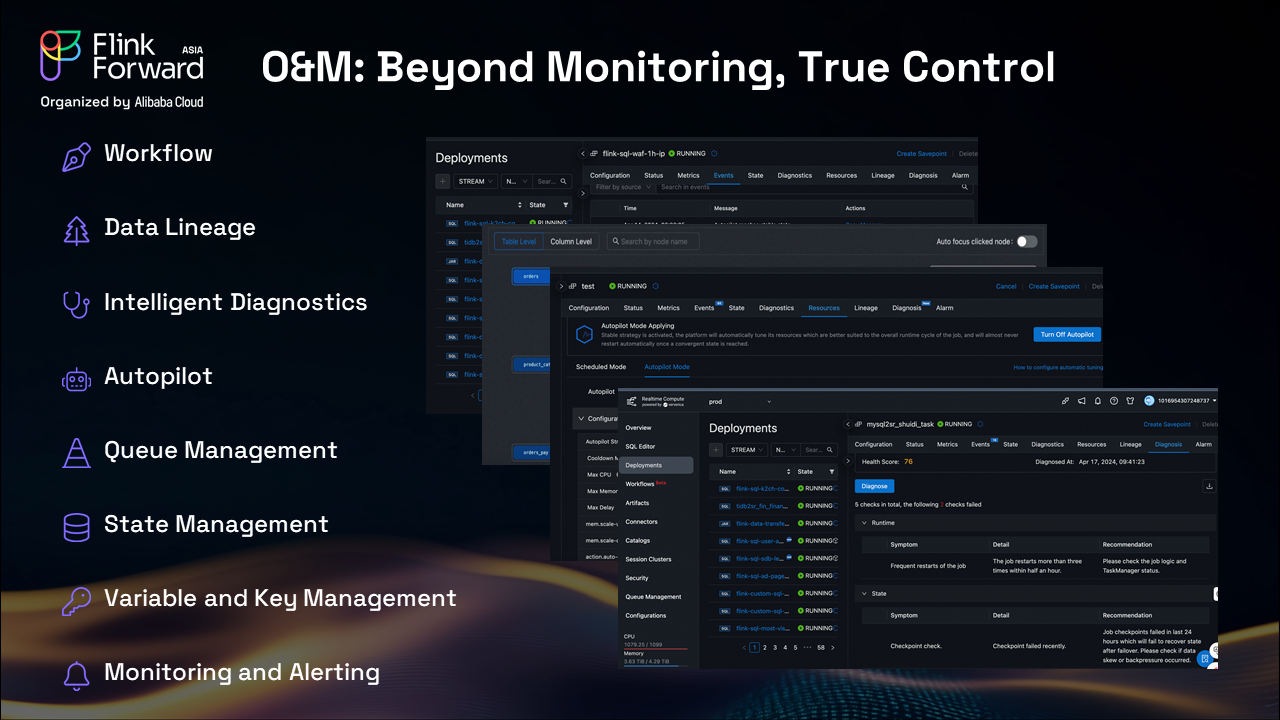
Traditional monitoring represents just the beginning of effective operations management. Our platform provides true operational control through comprehensive O&M features designed for enterprise scale:
Easily organize, deploy, and manage all streaming pipelines from a unified console, simplifying the tracking of complex workflows as business requirements evolve.
Real-time dashboards and intelligent alerts ensure constant awareness of job health and performance, enabling instant response to any issues.
Automated analysis of job behavior that pinpoints bottlenecks and suggests actionable fixes, reducing troubleshooting time while increasing innovation focus.
Automated routine operations including resource tuning, job restart, and failover handling, ensuring maximum uptime with minimal manual intervention.
Detailed records of every event and operation provide complete transparency, making auditing and troubleshooting straightforward.
Trace the journey of every data point from source to sink, making compliance and impact analysis effortless.
Fine-grained control over state snapshots, recovery, and scaling ensures application robustness and resilience.
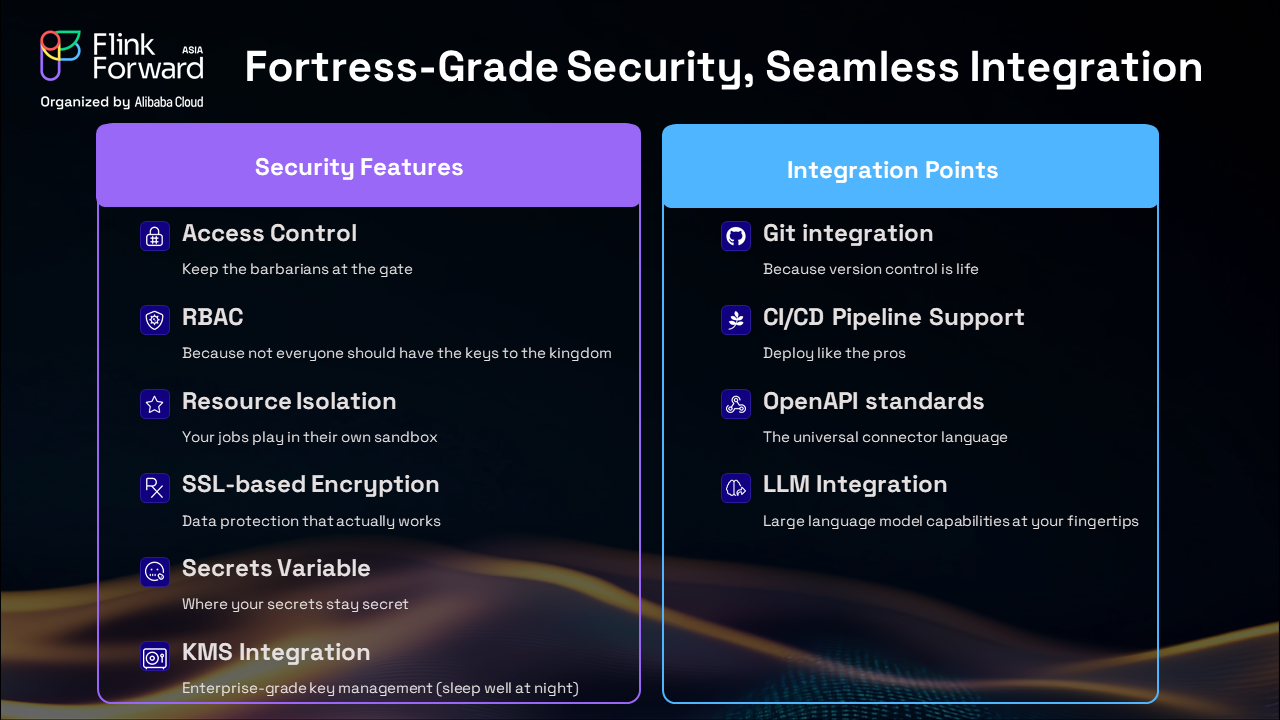
Enterprise-grade security and seamless integration form the foundation of our platform:
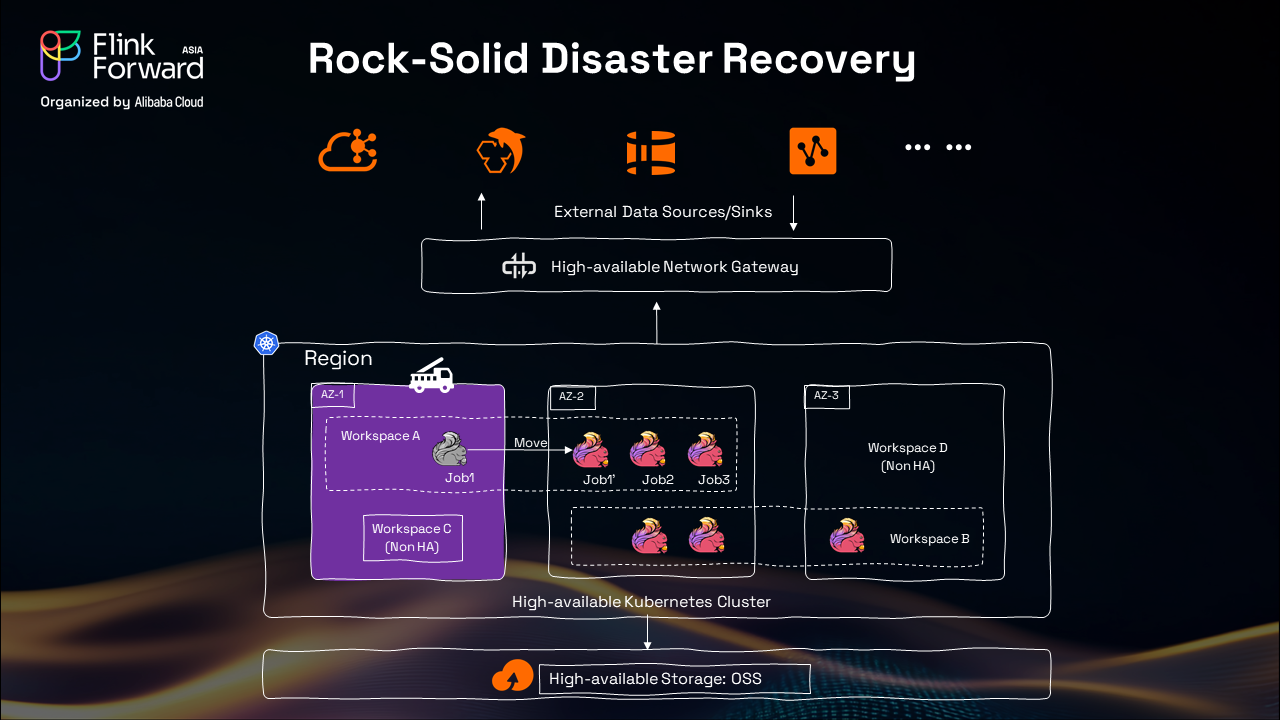
Our architecture prioritizes downtime prevention through multi-layered resilience:
While Kafka has been the traditional choice for streaming data, Flussrepresents a next-generation approach that addresses Kafka's fundamental limitations:
Unified Streaming and Analytics: Fluss works seamlessly with Apache Paimon, providing instant access to both real-time and historical data through a unified interface.
Native Update Support: Unlike Kafka's append-only model that creates duplicates, Fluss supports updates natively, eliminating waste and improving efficiency.
Direct SQL Querying: No need for external tools or complex workarounds—query your streaming data directly with SQL.
Network Efficiency: Fluss only transmits the data columns you actually need, dramatically reducing network overhead compared to Kafka's all-or-nothing approach.
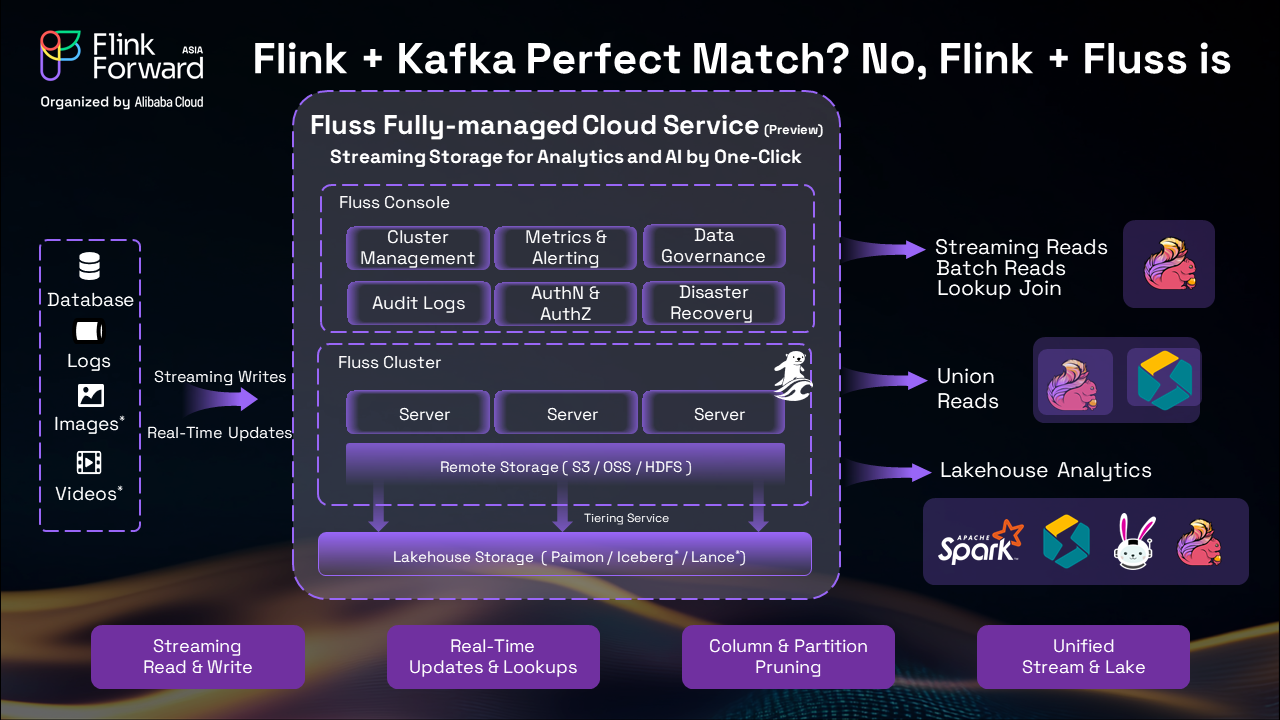
Our managed Fluss service provides:
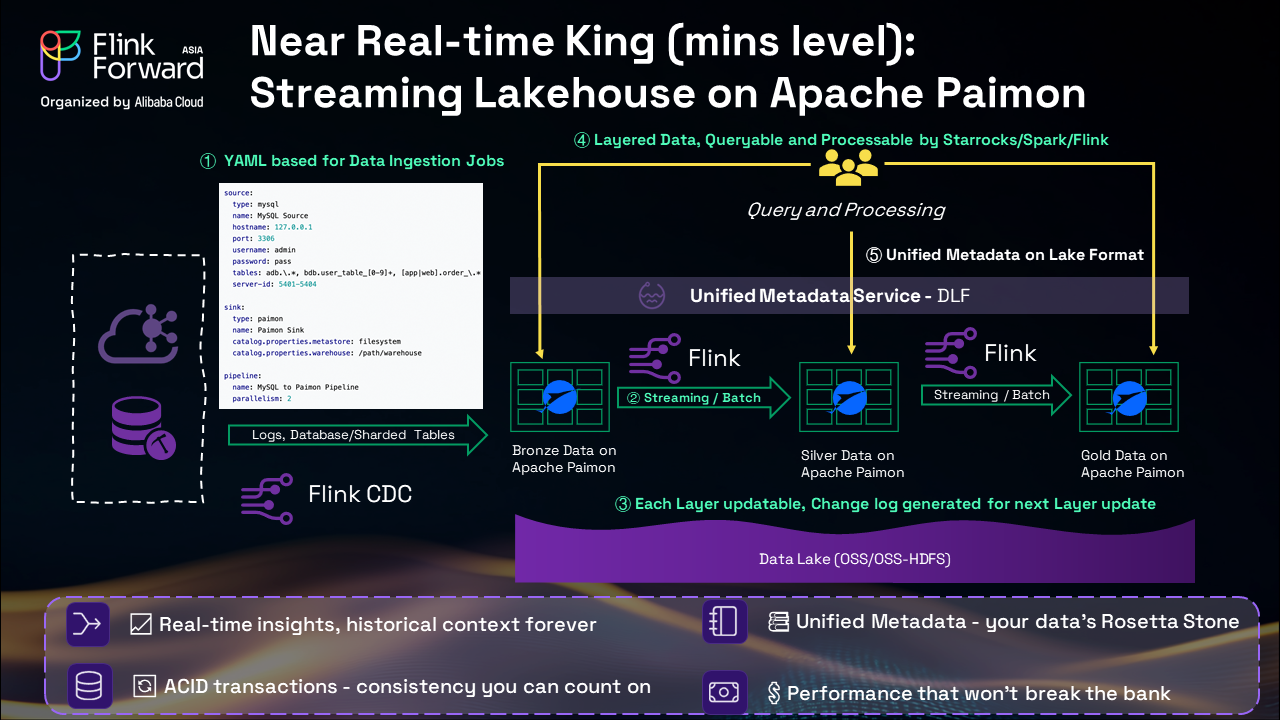
For scenarios requiring cost-effective near real-time analytics, Apache Paimon delivers the optimal balance between latency and cost:
This solution provides minute-level latency with unified governance and significant cost savings compared to traditional real-time solutions.
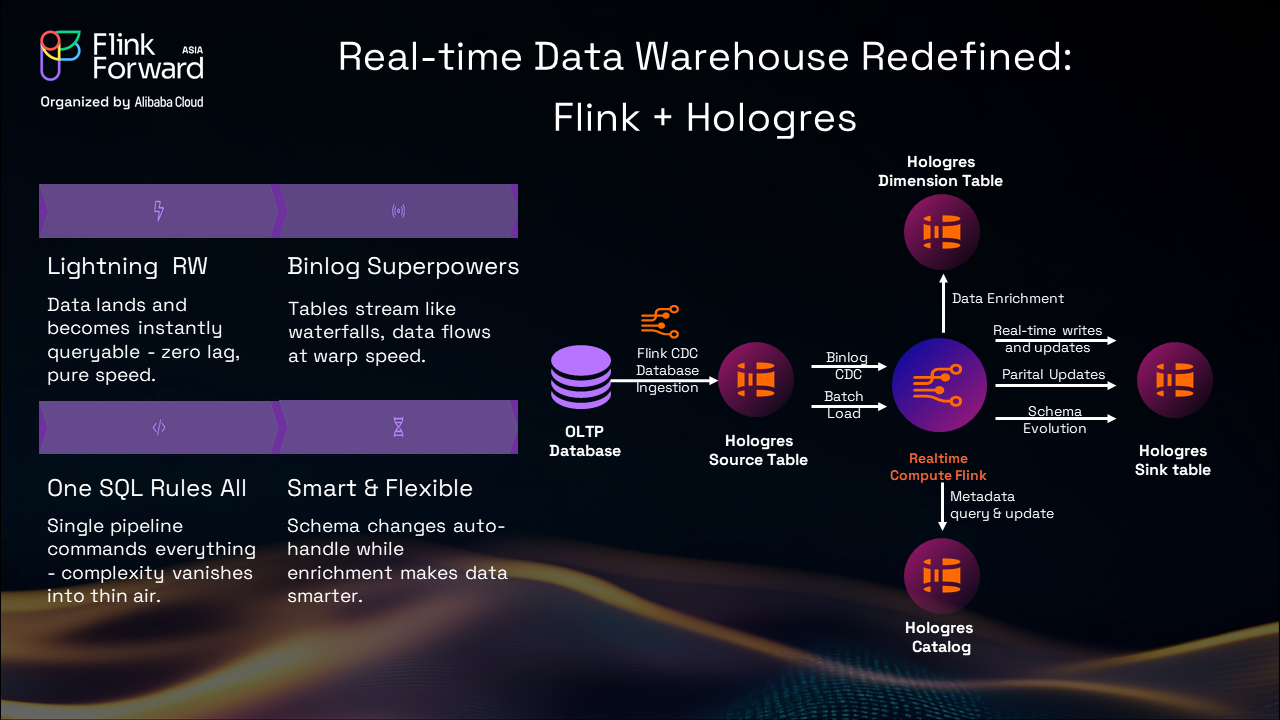
For scenarios demanding both extreme performance and full SQL analytics capabilities, the combination of Flink and Hologres delivers unmatched results:
Lightning RW: Data becomes queryable instantly upon arrival, with no indexing delays or batch windows.
Binlog Superpowers: Using Flink CDC, every database change streams directly into Hologres, supporting both real-time and batch processing patterns.
One SQL Rules All: A single SQL pipeline handles everything from data ingestion to transformation, dramatically reducing development complexity.
Smart & Flexible: Automatic adaptation to schema changes while enriching data on the fly, with zero downtime or manual intervention.
This represents real-time data warehousing without compromise, where speed meets simplicity.

The convergence of AI and real-time streaming unlocks unprecedented capabilities:
SELECT user_id, ML_PREDICT('sentiment_model', comment_text) as sentiment
FROM comment_stream
WHERE event_time > CURRENT_TIMESTAMP - INTERVAL '1' MINUTE;Optimized Milvus connector for millisecond similarity search across streaming data, with intelligent batch writing for maximum throughput.
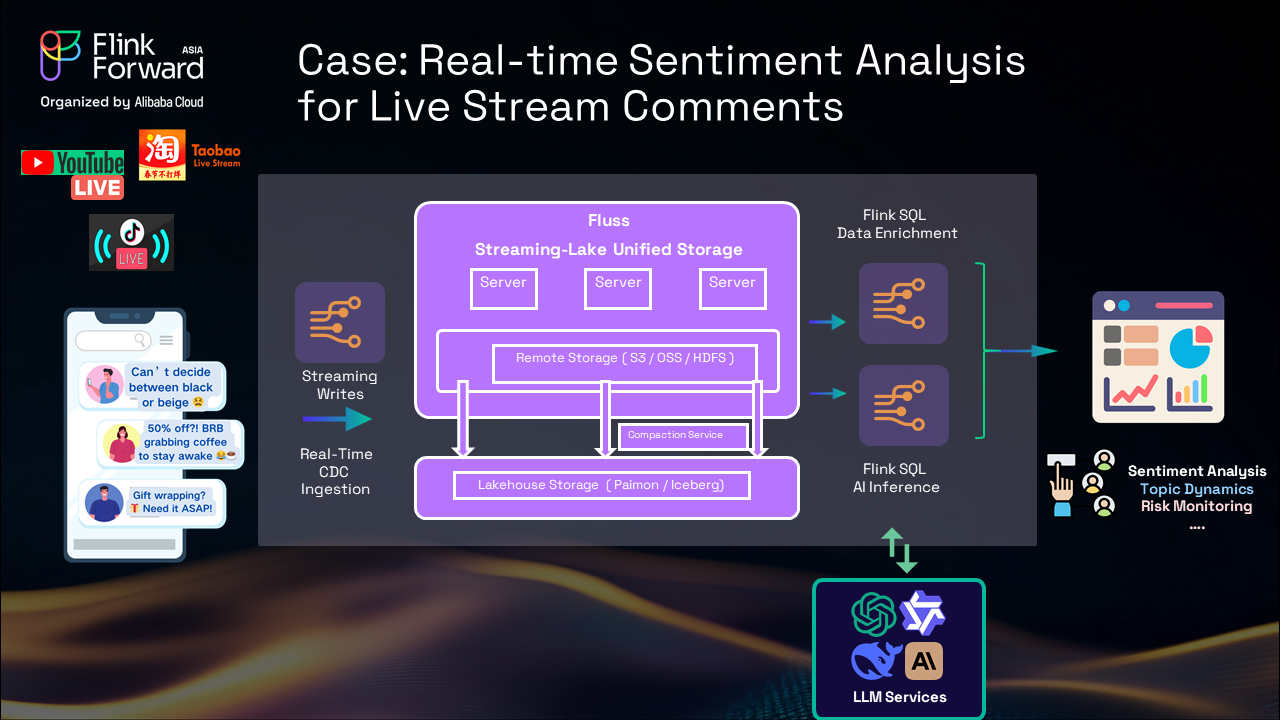
This real-world example demonstrates the power of combining Flink, unified storage, and AI:
Dual Flink SQL Processing:
Instant Insights:
The entire pipeline processes comments from posting to insights in milliseconds, demonstrating the platform's real-world performance capabilities.

Our platform's success is measured not just in technical capabilities, but in real-world impact:
Bilibili: Maintains smooth streaming for millions of videos with real-time processing Lazada: Powers e-commerce operations across Southeast Asia Panasonic: Enhances smart device intelligence through real-time analytics Midea: Improves home appliance functionality with streaming data insights
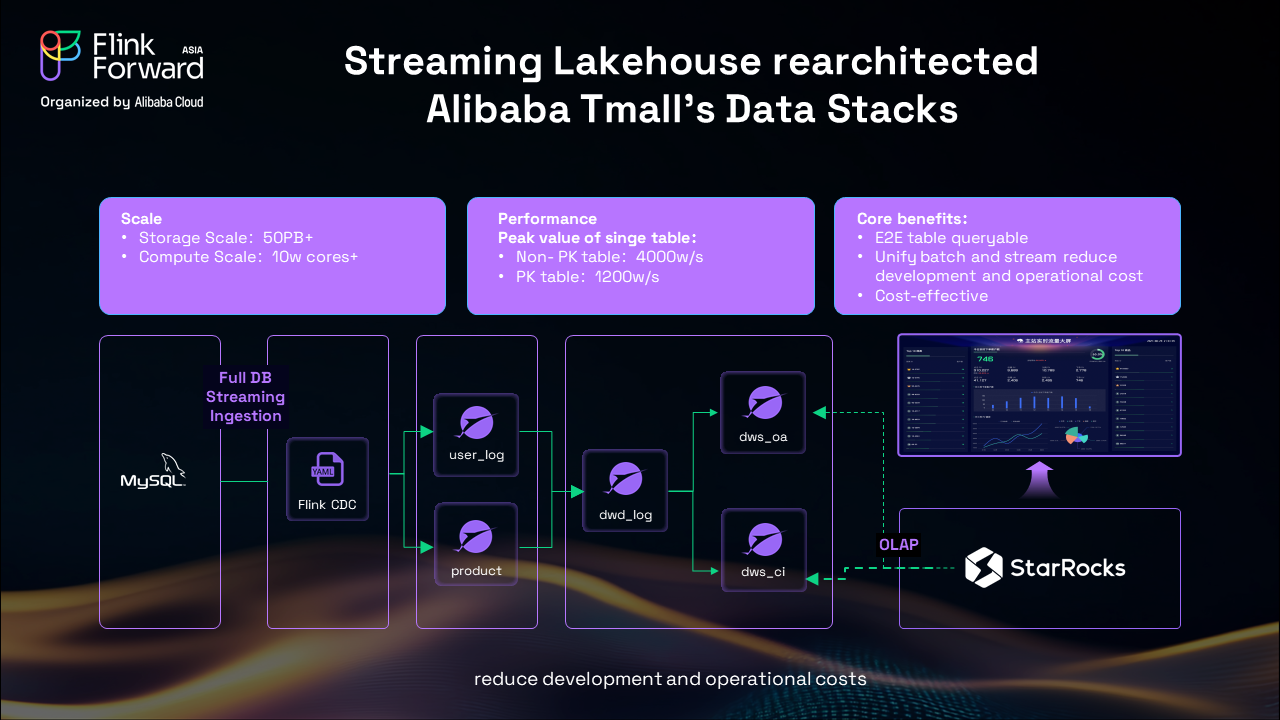
Tmall's implementation showcases enterprise-scale real-time processing:
Changes flow from MySQL databases through Flink CDC, cascade through bronze, silver, and gold tables in Paimon, and feed into StarRocks for lightning-fast analytics.
What previously took hours now happens in minutes. Customer purchase events instantly ripple through the entire system, enabling real-time business intelligence and immediate response to market trends.
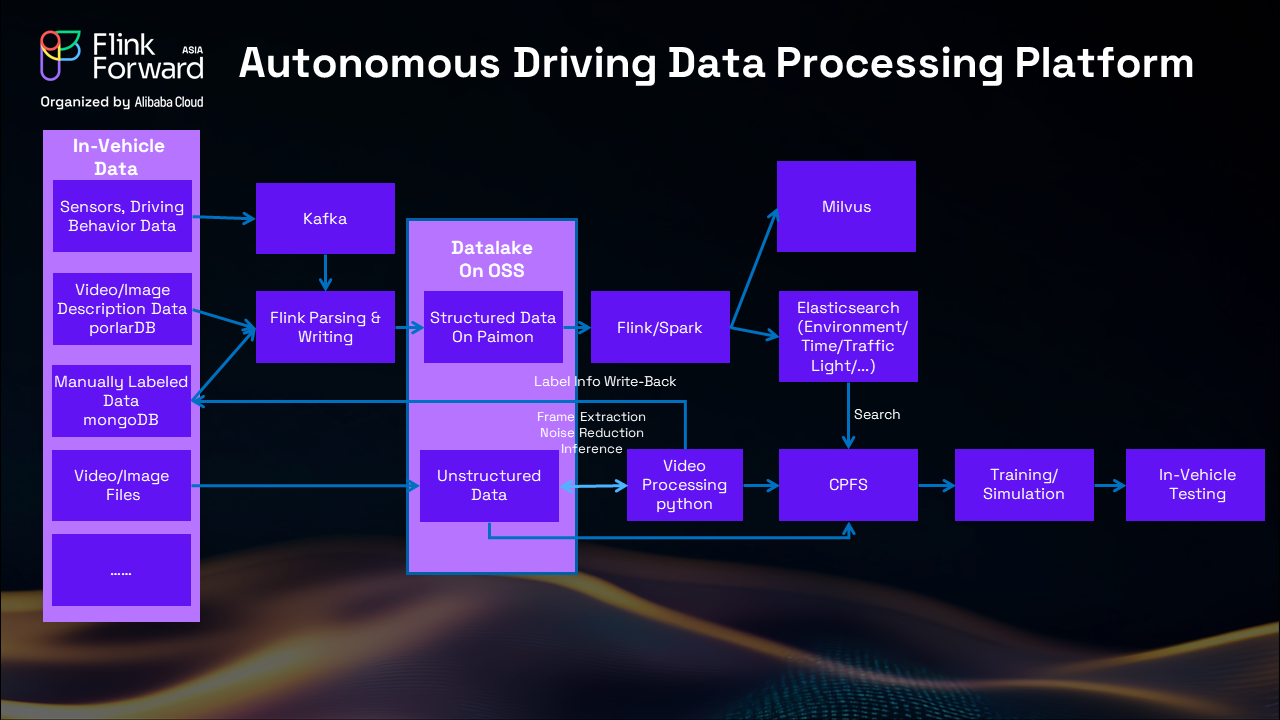
Our platform powers the future of autonomous driving through massive real-world data processing:
Structured Data: Kafka → Flink → Paimon → Elasticsearch analytics Unstructured Data: Video/image → Python processing → OPFS → Training simulations
This platform serves as the intelligent brain making autonomous vehicles smarter and safer with every mile driven.

We're investing in four key areas to shape the future of real-time streaming:
Smart agents that react and adapt to changing conditions in real-time, making systems more intelligent and responsive.
Enhanced lake-streaming unified real-time storage for seamless integration between lakehouse and streaming architectures.
Processing only changed data instead of full recomputation, delivering instant insights while conserving resources.
Intelligent video content analysis powered by AI recognition, unlocking new value from video data in real-time.

Ready to experience the power of enterprise-grade streaming? Join our ecosystem:
The evolution from traditional batch processing to real-time streaming represents more than a technological shift—it's a fundamental change in how businesses operate and compete. Alibaba Cloud Realtime Compute for Apache Flink doesn't just process data; it transforms raw information into actionable intelligence at the speed of business.
As enterprises continue to generate ever-increasing volumes of real-time data, the organizations that succeed will be those that can harness this information effectively. Our platform provides the foundation for this success, combining the power of Apache Flink with enterprise-grade capabilities, intelligent operations, and native AI integration.
The future belongs to those who can act on data as it happens, not hours or days later. With Alibaba Cloud Realtime Compute for Apache Flink, that future is available today.
Fluss: Redefining Streaming Storage for Real-time Data Analytics and AI
Apache Flink FLIP-13: Side Outputs for Multi-Stream Processing

206 posts | 56 followers
FollowAlibaba Cloud Community - January 4, 2026
Alibaba Cloud Big Data and AI - October 27, 2025
Apache Flink Community - August 21, 2025
Apache Flink Community - November 7, 2025
Apache Flink Community - August 29, 2025
Apache Flink Community - October 15, 2025
206 posts | 56 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More MaxCompute
MaxCompute
Conduct large-scale data warehousing with MaxCompute
Learn More Real-Time Streaming
Real-Time Streaming
Provides low latency and high concurrency, helping improve the user experience for your live-streaming
Learn More Message Queue for Apache Kafka
Message Queue for Apache Kafka
A fully-managed Apache Kafka service to help you quickly build data pipelines for your big data analytics.
Learn MoreMore Posts by Apache Flink Community

