Welcome to an in-depth exploration of Apache Fluss (Incubating), a groundbreaking streaming storage solution designed to revolutionize real-time data analytics and AI. This blog post, inspired byJark Wu's keynote at Flink Forward Asia Singapore 2025, introduces Fluss as the next-generation streaming storage, meticulously optimized for modern analytical and AI use cases. We will delve into how Fluss effectively bridges the gap between traditional streaming systems and cutting-edge lakehouse architectures, significantly enhancing storage capabilities for machine learning feature engineering and multi-modal AI data ingestion. Join us as we uncover the motivations behind Fluss, its key architectural advantages, and compelling real-world use cases.

In today's data-driven landscape, Apache Kafka has emerged as the backbone of nearly every streaming data infrastructure. It excels in event-driven communication between microservices and high-throughput log collection. And then if you want to deliver some real time insights, you need to process the streaming data and transform it with Apache Flink. And to transform the data, you may need to write it back to Kafka topics across multiple layers, like the bronze layer, silver layer, and gold layer, which is also known as the medallion architecture.
But what happens when you need to perform a key-value lookup for data enrichment? Typically, you end up copying the data into a key-value store like Redis to support that use case. And what if you want to query Kafka topics for data exploration or debugging? Kafka isn’t designed to be queryable. To address this limitation, you’re forced to copy the data again, this time into an OLAP system like ClickHouse. Similarly, if you aim to build a data lakehouse for batch processing, you’ll need to copy the data yet again—this time into a format like Apache Iceberg.
As a result, you end up maintaining multiple copies of the same data across Kafka, Redis, ClickHouse, Iceberg, and potentially other systems. This proliferation of data introduces significant costs, complexity, and operational overhead. Worse still, it creates isolated data silos that are difficult to keep consistent, leading to challenges in data governance and reliability.

Consider the common scenarios where Kafka falls short for analytical needs:
Ultimately, the Kafka topics in such setups often provide zero business value beyond intermediate storage.
They are not designed for querying, lookups, or long-term data retention, acting merely as a black box in the data pipeline. This isn't a fault of Kafka itself, but rather a misuse of its capabilities. Kafka is optimized for operational workloads and event-driven communication, not for the demands of analytical and AI applications. Its lack of built-in schema, absence of update support, and poor optimization for long-term data storage limit its utility in modern data warehouses and analytical use cases.

This realization led to the inception of the Fluss project two years ago, a streaming storage solution built from scratch specifically for analytics and AI. The goal was to address these inherent limitations and provide a unified, cost-effective, and highly performant solution for real-time data processing.
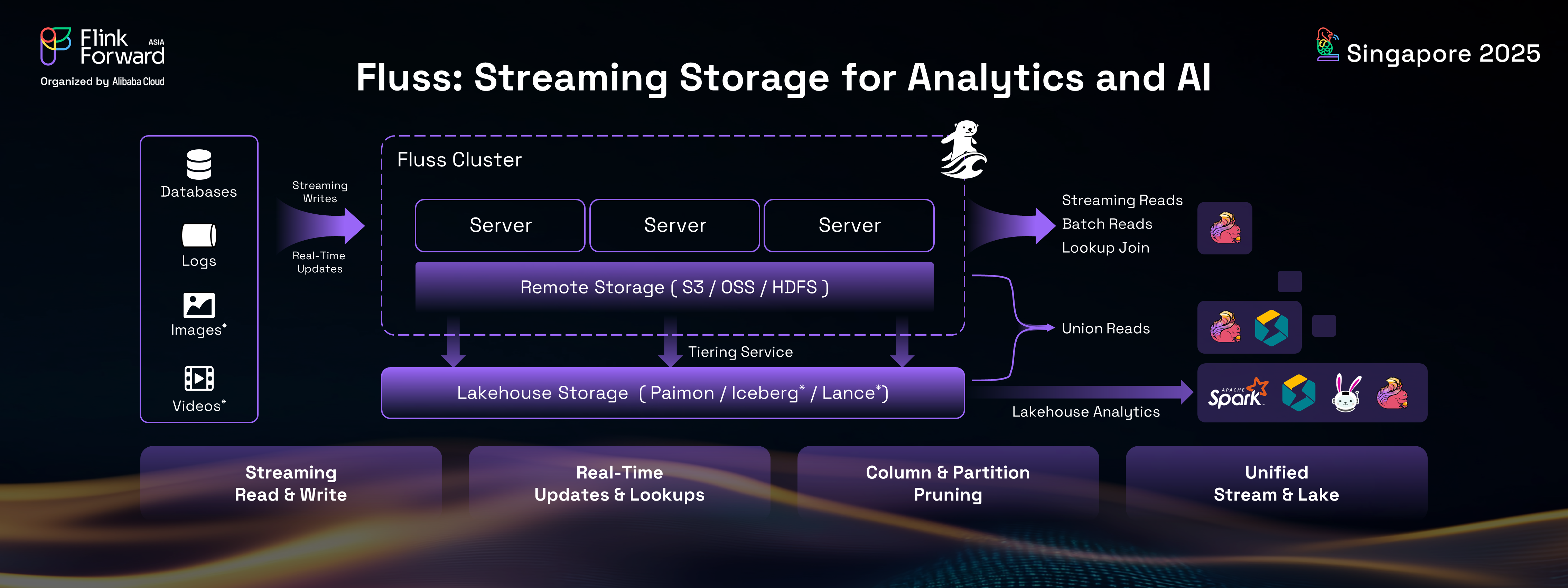
Fluss represents a significant leap forward in streaming storage technology. At its core, Fluss is a streaming storage solution that supports sub-second level latency for both streaming reads and writes. It is architected as a columnar log streaming storage built on top of Apache Arrow. This foundation in Apache Arrow, a columnar format, imbues Fluss with powerful analytical capabilities.
Key advantages of Fluss include:
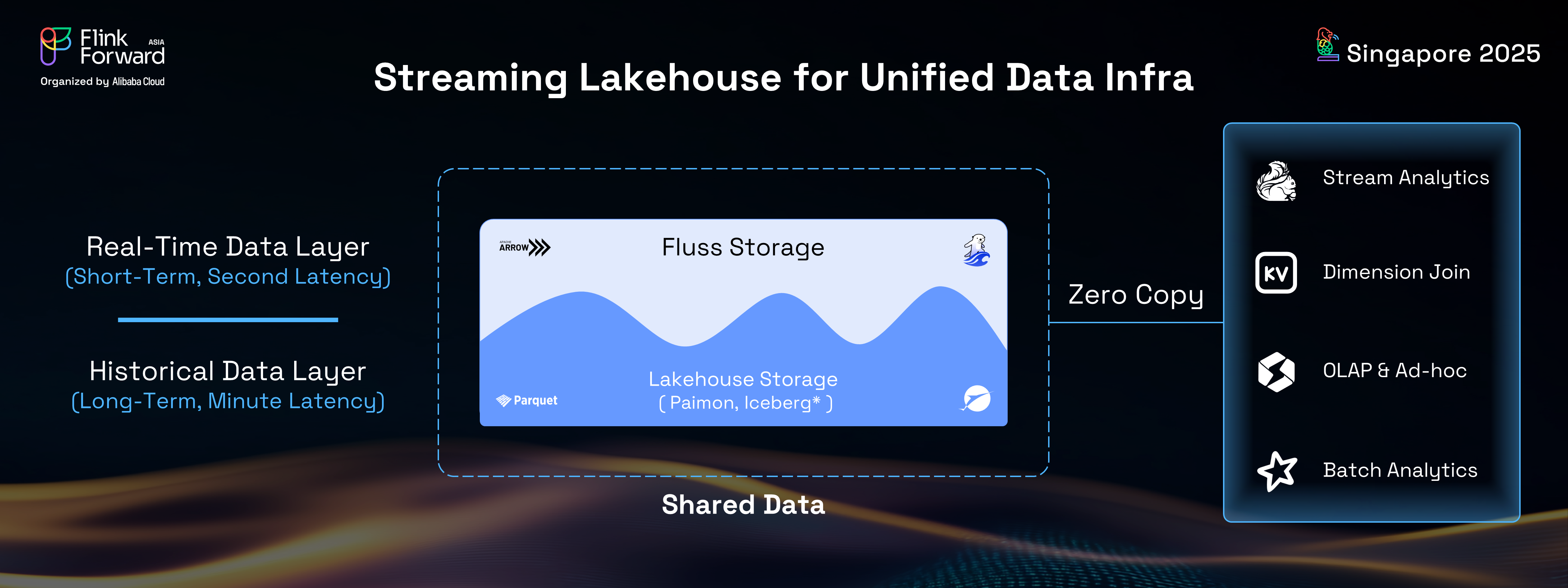
With Fluss, enterprises can now achieve a truly real-time streaming lakehouse, characterized by a single, unified copy of their data. This eliminates the need to maintain multiple data copies across disparate systems, drastically reducing costs and simplifying the overall data infrastructure. Fluss provides real-time streaming read and write capabilities for Flink stream analytics, offers KV lookup for dimension joins, enables Union Read for OLAP queries, and supports open lake formats for batch processing. It's important to note that the real-time streaming lakehouse facilitated by Fluss is not a new type of lakehouse; rather, it enhances existing lakehouse architectures with robust streaming capabilities, enabling seamless data sharing between data streams and the data lakehouse.
To achieve this data sharing, Fluss maintains a tiering service that continuously converts Fluss data into lakehouse formats like Iceberg and Paimon. This approach is analogous to database systems that employ multiple data layers (hot, warm, cold) with different storage media and formats, ensuring data consistency across layers. Fluss adopts a similar methodology, leveraging open lake formats as the cold layer, thereby making cold data openly accessible to the broader lakehouse ecosystem, including tools like Spark and Trino.
In essence, Fluss serves as the real-time data layer for the lakehouse, optimized for storing short-term, sub-second latency data. Conversely, the lakehouse functions as the historical data layer for streams, accommodating long-term, minutes-level latency data. When a stream needs to be read, the lakehouse provides historical data for fast catch-up. When batch analytics are performed, Fluss delivers the freshest data from the past few minutes to the lakehouse, ensuring that lakehouse analytics are truly real-time.
Fluss is not merely a theoretical concept; it is already in large-scale production at Alibaba, demonstrating its robustness and efficiency in real-world scenarios. Alibaba is actively migrating its internal Kafka system to Fluss, particularly for real-time analytics use cases, and the adoption is continuously growing as its usage expands.

Currently, Fluss manages over 3 PB (petabytes) of data in total, with clusters handling an impressive ingest throughput of 40 GB per second. Furthermore, it supports very high-performance KV lookups, reaching up to 500,000 QPS (queries per second) on a single table, with the largest table containing over 500 billion rows. These statistics underscore Fluss's capability to handle massive data volumes and high-velocity data streams.
Let's delve into some specific use cases from Alibaba's production environment:

At Taobao, China's largest online shopping platform, a vast array of logs are collected from applications and websites. These logs encompass critical data such as clickstreams, user behavior, and order streams, forming the foundation for downstream analytics and AI/machine learning initiatives. However, the Taobao team faced significant challenges when using Kafka for this purpose:
By switching to Fluss, the Taobao team leveraged the shared data capabilities of the streaming lakehouse. They could now retain long-term data in the lakehouse, significantly reducing the data volume in Fluss by 30%. As Fluss is a columnar streaming storage, it supports column pruning and partition pruning. This feature allowed them to drastically reduce network costs by avoiding the transfer of unnecessary columns or partitions. In total, compared to their previous solution, the Taobao team achieved a 30% reduction in overall cost and a remarkable 70% reduction in read traffic.
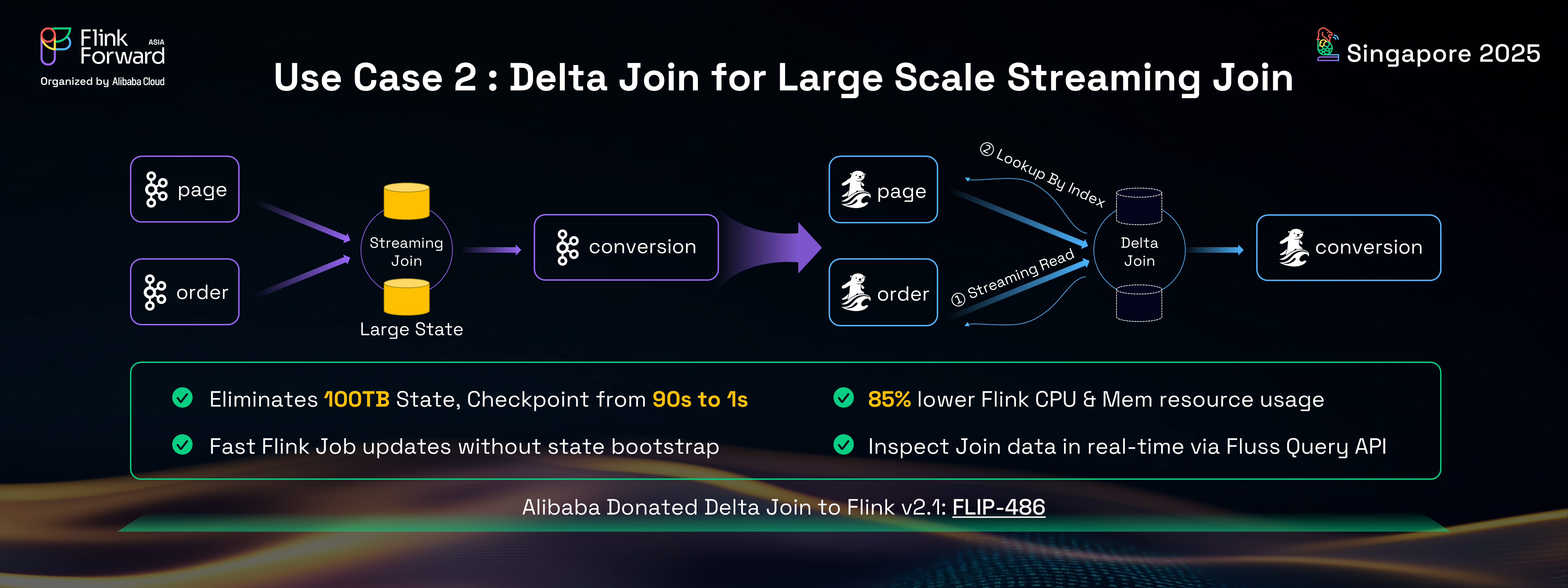
Streaming join is a fundamental operation in Flink, used to enrich data by joining two streams. This operation typically requires storing all upstream data in Flink's state, which can lead to very large Flink states and associated issues. For instance, in Alibaba's search and recommendation team, they needed to join page clickstreams and order streams for attribution analysis – understanding what a user saw that led to a purchase. The clickstream and order stream data were so massive that they resulted in a 100 TB state size, making the Flink jobs unstable and causing frequent checkpoint timeouts.
To address this, Alibaba introduced Delta Join in Flink, which leverages Fluss's key functionalities: streaming read, change log read, and KV lookups. Delta Join can be conceptualized as a bidirectional lookup join. When data arrives from the left stream, it performs a KV lookup on the right table using the join key. Conversely, when data arrives from the right stream, it performs the same operation on the left table. This approach offers the same semantics as a traditional streaming join but without the need to maintain a large state within the Flink job itself.
Implementing Delta Join with Fluss completely eliminated the 100 TB state size, leading to significantly more stable jobs. Checkpoint times were reduced from 90 seconds to a mere 1 second, and Flink resource usage was cut by an impressive 85%.
Beyond these immediate benefits, a major advantage of Delta Join is the decoupling of state and job logic. Changes to the Flink job no longer necessitate reprocessing the entire state, accelerating Flink job updates. Furthermore, users can directly inspect the joined data within Fluss.
The good news is that Delta Join has been open-sourced and donated to Apache Flink, and it is slated for inclusion in the upcoming Flink 2.1 release. This highlights the community's commitment to integrating and leveraging Fluss's capabilities within the broader Flink ecosystem.

The future roadmap for Fluss is ambitious and exciting, focusing on expanding its capabilities to meet the evolving demands of the AI era. The key areas of development include:
In the AI era, data infrastructure faces new demands and challenges, primarily centered around three key aspects: multimodal data, streaming data, and open data.
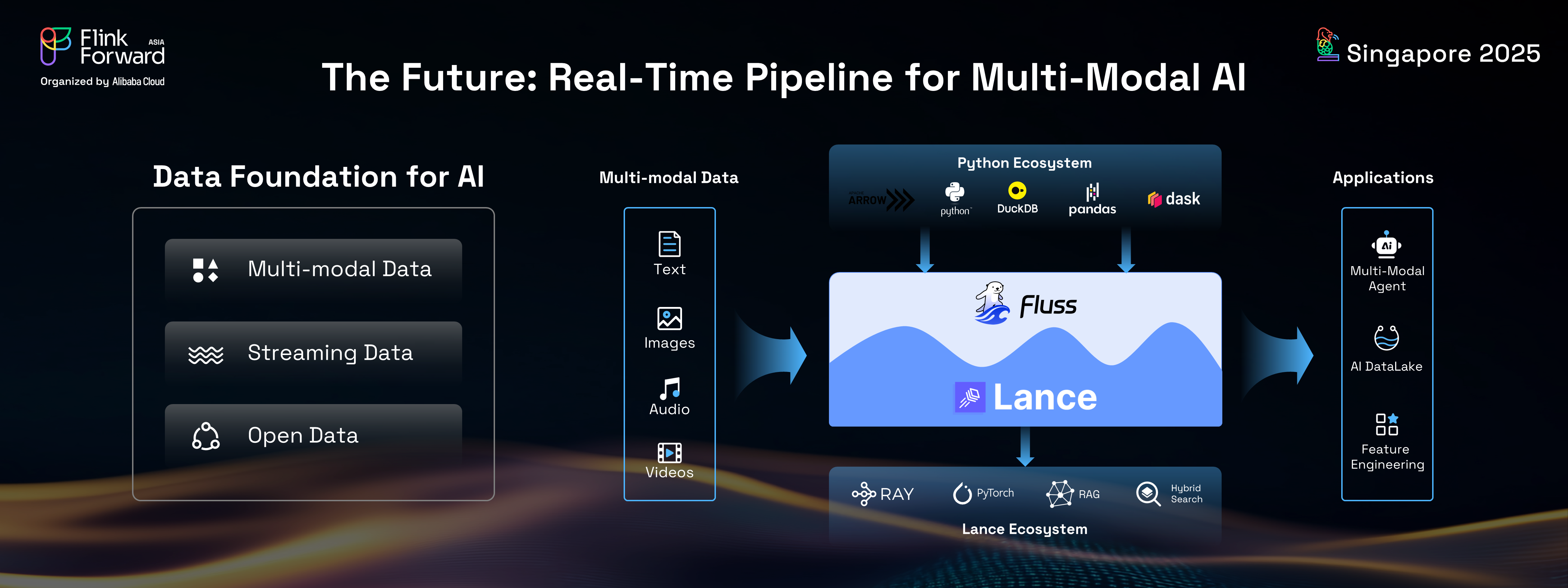
The full picture of the upcoming Fluss release reveals its evolution beyond analytics into a real-time pipeline for multimodal AI.
This will involve supporting real-time ingestion and storage of multimodal data in a streaming format, and then seamlessly converting it into the Lance format. From there, users can connect to the broader Lance ecosystem, including tools like Ray and PyTorch. With the upcoming Fluss Python client, integration with the Python data science ecosystem (Pandas, Polars, etc.) will unlock a multitude of use cases, such as real-time multimodal agents, real-time AI data lakes, and real-time feature engineering.

Fluss's open-source journey began with its live open-sourcing at Flink Forward Asia 2024 in Shanghai. Since then, the community has experienced continuous growth, boasting over 1,200 GitHub stars and more than 50 contributors from leading companies worldwide, including Alibaba, ByteDance, eBay, Xiaomi, and Tencent. The project has also maintained a rapid development pace, with three releases in just six months.
Half a year after its initial open-sourcing, Alibaba has proudly completed the donation of Fluss to the Apache Software Foundation (ASF) at Flink Forward Asia 2025. Fluss is now an incubating project under the ASF, officially known as Apache Fluss. The new repository can be accessed by simply replacing the "alibaba" with "apache" in the previous GitHub URL. Joining the Apache Software Foundation is a significant milestone for the Fluss community, marking a new beginning for its open-source journey towards becoming more open, community-driven, and with a brighter future.

Finally, a private preview of the managed service for Apache Fluss (incubating) has been launched on Alibaba Cloud, now available in the Singapore region. This offers an opportunity to explore the next-generation streaming storage. Users can apply for the private preview program of the managed service for Apache Fluss (incubating) on Alibaba Cloud by visiting this link or scanning the QR code in the slide below.

Fluss is poised to redefine real-time data analytics and AI by providing a unified, high-performance, and cost-effective streaming storage solution. Its seamless integration with lakehouse architectures, support for multimodal AI, and commitment to open data formats position it as a critical component for future data infrastructures. As Fluss continues its open-source journey under the Apache Software Foundation, it promises to empower developers and enterprises to unlock the full potential of real-time data and AI.
Apache®, Apache Fluss™, Fluss™ and the Apache feather logo are either registered trademarks or trademarks of The Apache Software Foundation in the United States and/or other countries. All other marks mentioned may be trademarks or registered trademarks of their respective owners.

207 posts | 58 followers
FollowApache Flink Community - January 7, 2025
Apache Flink Community - November 21, 2025
Apache Flink Community - December 20, 2024
Alibaba Cloud Big Data and AI - October 27, 2025
Apache Flink Community - November 7, 2025
Apache Flink Community - June 5, 2025
207 posts | 58 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More MaxCompute
MaxCompute
Conduct large-scale data warehousing with MaxCompute
Learn More
Hologres
A real-time data warehouse for serving and analytics which is compatible with PostgreSQL.
Learn More Personalized Content Recommendation Solution
Personalized Content Recommendation Solution
Help media companies build a discovery service for their customers to find the most appropriate content.
Learn MoreMore Posts by Apache Flink Community

