Machine Learning Designer には、さまざまな業界シナリオの要件を満たすために、さまざまなフレームワークに基づいて開発された数十のプリセットテンプレートが用意されています。 プリセットテンプレートを使用してパイプラインを作成し、コンポーネントまたはコンポーネント構成を変更して、ビジネス要件に基づいてモデルを構築できます。 このトピックでは、心臓病予測テンプレートを使用して、モデルを視覚的に構築する方法について説明します。
前提条件
ステップ 1: プリセットテンプレートを使用してパイプラインを作成する
Machine Learning Designer では、パイプラインを使用してモデルを構築できます。 モデルを構築するには、パイプラインを作成し、パイプラインにさまざまなコンポーネントを追加してから、モデルのロジックに基づいてコンポーネントを配置する必要があります。
PAI コンソールにログオンし、ビジュアルモデリング (Designer) ページに移動します。 ビジュアルモデリング (Designer) ページで、ワークスペースを選択し、[ビジュアルモデリング (Designer) に入る] をクリックします。
ビジュアルモデリング (Designer) ページの [パイプライン] タブで、[プリセットテンプレート] タブをクリックします。 [プリセットテンプレート] タブで、[心臓病予測] テンプレートの [作成] をクリックします。
[パイプラインの作成] ダイアログボックスで、関連パラメーターを構成し、[OK] をクリックします。
パラメーター
説明
パイプライン名
作成するパイプラインの名前を指定します。
データストレージ
パイプラインの実行中に生成された一時データとモデルを格納する Object Storage Service (OSS) バケットのパス。 このパラメーターを構成することをお勧めします。 このパラメーターを空のままにすると、ワークスペースのデフォルトストレージが使用されます。
システムは、各実行に対して
<Pipeline data path>/<Task ID>/<Node ID>形式の一時ディレクトリを自動的に作成します。 これにより、各コンポーネントのデータを格納するための OSS ディレクトリを作成する手間が省け、データを一元的に管理できます。可視性
[自分のみ]: ワークフローは [マイパイプライン] フォルダーに作成され、ワークスペースの自分と管理者のみが表示できます。
[現在のワークスペースに表示]: パイプラインは [ワークスペースに表示されるパイプライン] フォルダーに作成され、現在のワークスペースのすべてのメンバーが表示できます。
構成方法とパラメーターの詳細については、「パイプラインを作成する」をご参照ください。
表示されるページで、[開く] をクリックします。
ステップ 2: モデルを構築する
次の図は、プリセットテンプレートを使用して構築されたモデルを示しています。
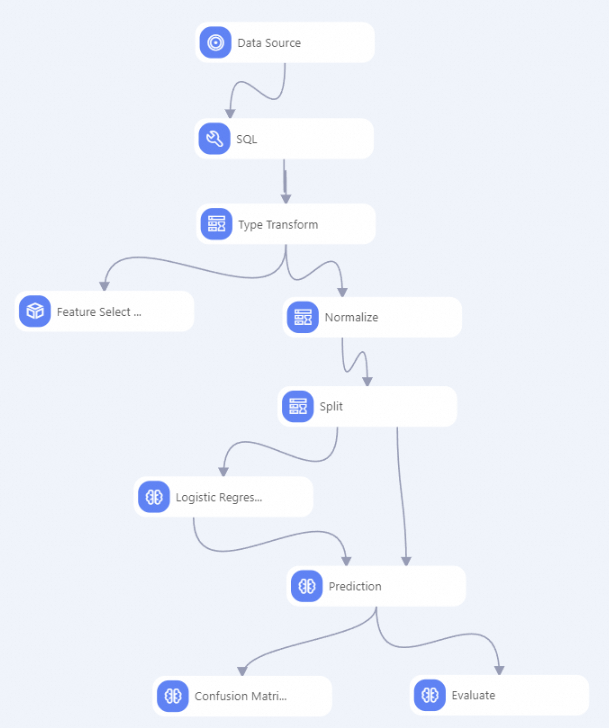
モデルをすばやく構築するために、プリセットテンプレートには各コンポーネントの事前構成済みパラメーターが含まれています。 コンポーネントをクリックすると、関連パラメーターを表示できます。 詳細については、「心臓病を予測する」をご参照ください。
(オプション) ステップ 4: モデルをデプロイするを実行する必要がある場合は、[ロジスティック回帰 (二項分類)] ノードをクリックし、右側にある [フィールド設定] タブで [PMML を生成するかどうか] を選択する必要があります。
ステップ 3: モデルをデバッグする
キャンバスの左上隅にある ![]() アイコンをクリックして、パイプラインを実行します。
アイコンをクリックして、パイプラインを実行します。
データを表示し、視覚分析を実行する
コンポーネントの実行後、コンポーネントを右クリックし、[データの表示] を選択して、生成されたデータを表示できます。
混同行列や二項分類評価コンポーネントなどの特定のコンポーネントの場合、Machine Learning Designer では、データをグラフやチャートに変換して、複雑なデータと分析結果を直感的でシンプルな方法で表示できます。 これにより、重要な情報をすばやく取得し、傾向やパターンを特定して、より効率的な分析と意思決定を行うことができます。 データを視覚的に分析するには、コンポーネントを右クリックして [視覚分析] を選択するか、キャンバスの上部にある視覚化アイコンをクリックします。 詳細については、「視覚化分析」をご参照ください。
ログを表示する
コンポーネントが実行に失敗した場合、コンポーネントを右クリックし、[ログの表示] を選択して、問題のトラブルシューティングを行うことができます。
(オプション) ステップ 4: モデルをデプロイする
Machine Learning Designer は、Elastic Algorithm Service (EAS) とシームレスに統合されています。 Machine Learning Designer でオフラインでモデルをトレーニングおよび評価した後、モデルをオンラインサービスとして EAS にデプロイできます。
パイプラインを実行した後、[モデル] をクリックし、デプロイするモデルを選択して、[EAS にデプロイ] をクリックします。

パラメーターの構成を確認します。 詳細については、「モデルをオンラインサービスとしてデプロイする」をご参照ください。
[サービスのデプロイ] ページでは、[モデルファイル] パラメーターと [プロセッサの種類] パラメーターが自動的に構成されます。 ビジネス要件に基づいて他のパラメーターを変更できます。
[デプロイ] をクリックします。
サービスステータスが [作成中] から [実行中] に変わると、モデルがデプロイされます。
重要モデルを一時的に使用しない場合は、[アクション] 列の [停止] をクリックして、不要な課金を回避します。
参考資料
パイプラインでモデルを構築およびデバッグできます。 詳細については、「モデルを構築およびデバッグする」をご参照ください。
空のパイプラインを作成し、さまざまなコンポーネントを配置して、ビジネス要件に基づいて最初からスケジューリングロジックを処理できます。 詳細については、「カスタムパイプライン」をご参照ください。
DataWorks では、オフラインパイプラインをスケジュールし、モデルを定期的に変更できます。 詳細については、「DataWorks タスクを使用して Machine Learning Designer でパイプラインをスケジュールする」をご参照ください。
Machine Learning Designer の課金については、「Machine Learning Designer の課金」をご参照ください。
コンポーネントについては、「コンポーネントリファレンス: すべてのコンポーネントの概要」をご参照ください。
モデルを視覚的に構築する方法については、「Designer のユースケース」をご参照ください。