Machine Learning Designer では、ワークフローを使用してモデルを構築します。ワークフローを作成した後、さまざまなコンポーネントの処理ロジックとスケジューリングロジックを構成して、モデリングのニーズを満たすことができます。このトピックでは、空のワークフローを使用して心臓病予測の二値分類モデルを構築し、ビジュアルモデリングとデプロイメントの全プロセスを説明します。
前提条件
PAI を有効化し、ワークスペースを作成している必要があります。詳細については、「PAI の有効化とデフォルトワークスペースの作成」をご参照ください。
ワークスペースが MaxCompute リソースに関連付けられています。詳細については、「クイックスタート: 準備」をご参照ください。
ステップ 1:ワークフローの作成
Machine Learning Designer に移動し、ワークスペースを選択して Designer ページを開き、ワークフローを作成して開きます。
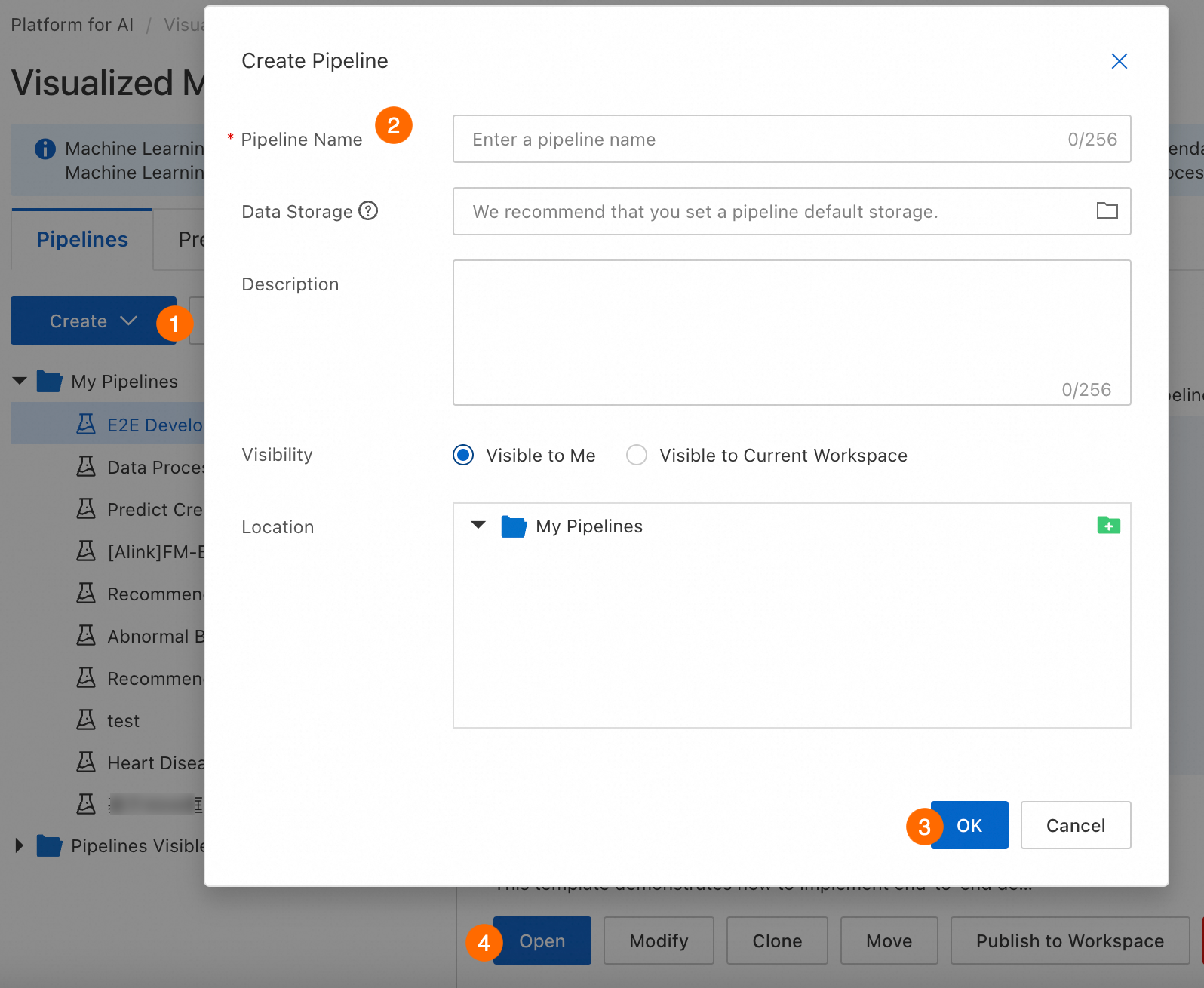
パラメーター | 説明 |
ワークフロー名 | カスタム名。 |
ワークフローデータストレージ | このパラメーターを設定します。実行時に生成される一時データとモデルを格納するために、OSS バケットのストレージパスに設定します。このパラメーターが設定されていない場合、ワークスペースのデフォルトのストレージが使用されます。 実行ごとに、システムは |
可視性 |
|
ステップ 2:データの準備と前処理
モデルを構築する前に、データソースを準備し、データを前処理する必要があります。このステップにより、ビジネスニーズに基づいてモデルのトレーニング用にデータを準備できます。
データの準備
[ソース/ターゲット] カテゴリからコンポーネントを追加することで、ワークフローにデータを読み込むことができます。これらは MaxCompute や OSS などのデータソースをサポートしています。詳細については、「コンポーネントリファレンス:ソース/ターゲット」をご参照ください。このトピックでは、[テーブルの読み込み] コンポーネントを使用して、PAI が提供する公開の心臓病データセットを読み込みます。データセットの詳細については、「Heart Disease Data Set」をご参照ください。
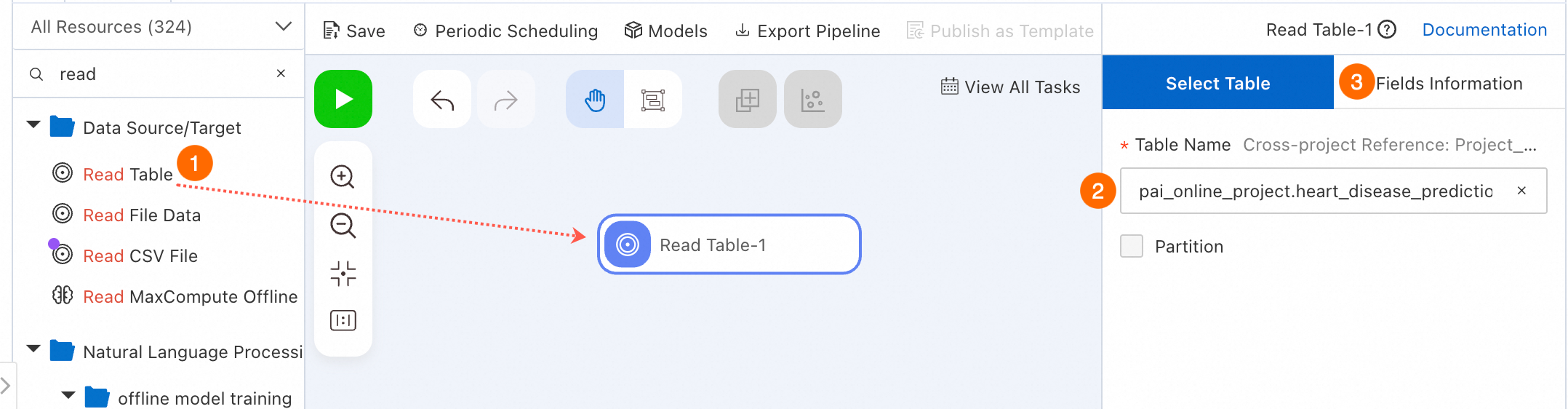
[ソース/ターゲット] コンポーネントを選択してデータを読み込みます。
左側のコンポーネントリストで [ソース/ターゲット] をクリックします。[テーブルの読み込み] コンポーネントをキャンバスにドラッグします。このコンポーネントは MaxCompute テーブルからデータを読み込みます。Read Table-1 という名前のノードが自動的にワークフローに追加されます。
ソーステーブル名を設定します。
キャンバス上の Read Table-1 ノードをクリックします。右側の設定ペインの [テーブル名] フィールドに、MaxCompute テーブルの名前を入力します。この例では、
pai_online_project.heart_disease_predictionと入力して、PAI が提供する公開の心臓病データセットを読み込みます。右側の設定ペインの [ソーステーブルの列] タブをクリックして、データセット内のフィールドの詳細を表示します。
データの前処理
心臓病予測は二値分類問題です。ロジスティック回帰モデルコンポーネントには、DOUBLE 型または BIGINT 型の入力データが必要です。したがって、このセクションでは、型変換などのタスクを実行して心臓病データセットを前処理し、モデルのトレーニング用にデータを準備します。
非数値フィールドを数値型に変換します。
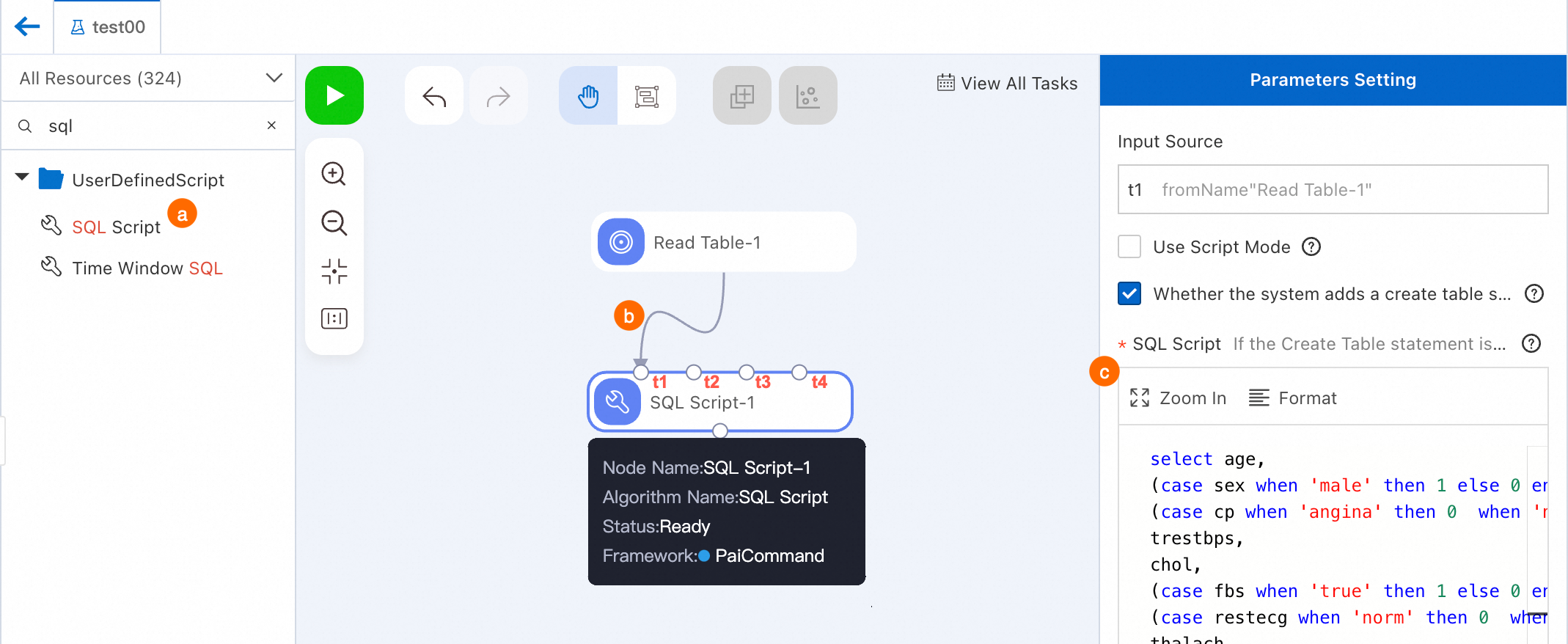
[SQL スクリプト] コンポーネントを見つけてキャンバスにドラッグします。SQL Script-1 という名前のノードがワークフローに追加されます。
Read Table-1 ノードの出力を SQL Script-1 ノードの t1 入力ポートに接続します。
ノードを設定します。
SQL Script-1 ノードをクリックします。右側の設定ペインに、次のコードを入力します。[パラメーター設定] ペインの [入力ソース] は t1 です。
select age, (case sex when 'male' then 1 else 0 end) as sex, (case cp when 'angina' then 0 when 'notang' then 1 else 2 end) as cp, trestbps, chol, (case fbs when 'true' then 1 else 0 end) as fbs, (case restecg when 'norm' then 0 when 'abn' then 1 else 2 end) as restecg, thalach, (case exang when 'true' then 1 else 0 end) as exang, oldpeak, (case slop when 'up' then 0 when 'flat' then 1 else 2 end) as slop, ca, (case thal when 'norm' then 0 when 'fix' then 1 else 2 end) as thal, (case status when 'sick' then 1 else 0 end) as ifHealth from ${t1};キャンバスの左上隅にある [保存] をクリックしてワークフローを保存します。
SQL Script-1 コンポーネントを右クリックし、[ルートノードからここまで実行] を選択して、ワークフローのこの部分をデバッグおよび実行します。
ワークフロー内のノードは順次実行されます。ノードが正常に実行されると、その右上隅に
 アイコンが表示されます。説明
アイコンが表示されます。説明キャンバスの左上隅にある
 (実行) アイコンをクリックして、ワークフロー全体を実行することもできます。ワークフローが複雑な場合は、特定のノードまたはノードのサブセットを実行してデバッグを容易にすることができます。ノードの実行に失敗した場合は、ノードを右クリックして [ログの表示] を選択し、失敗の原因を特定できます。
(実行) アイコンをクリックして、ワークフロー全体を実行することもできます。ワークフローが複雑な場合は、特定のノードまたはノードのサブセットを実行してデバッグを容易にすることができます。ノードの実行に失敗した場合は、ノードを右クリックして [ログの表示] を選択し、失敗の原因を特定できます。ノードが正常に実行された後、SQL Script-1 ノードを右クリックし、 を選択して、出力データが正しいことを確認します。
ロジスティック回帰モデルの入力要件を満たすために、フィールドのデータ型を DOUBLE に変換します。
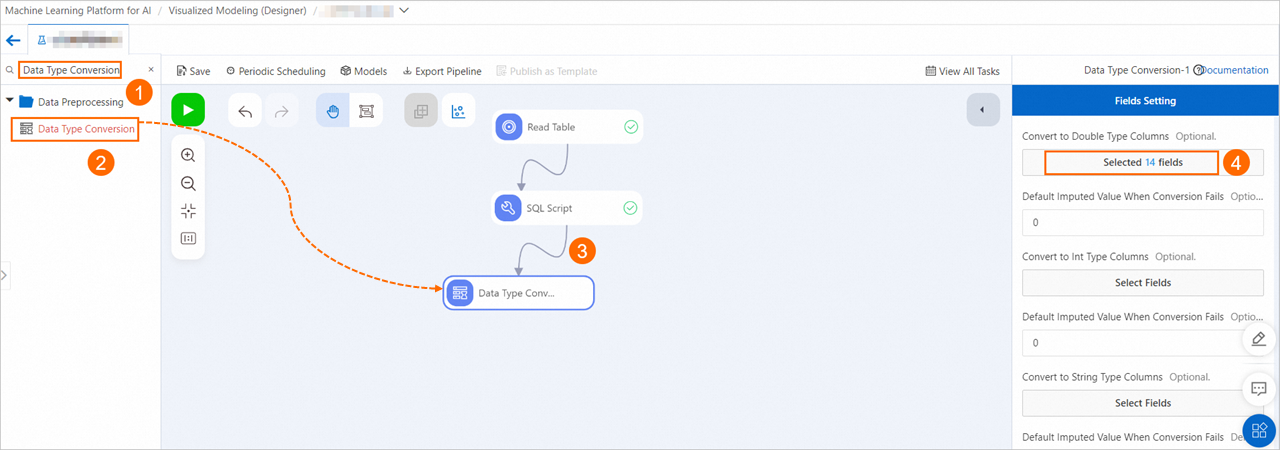
[型変換] コンポーネントをキャンバスにドラッグし、SQL Script-1 ノードの出力に接続します。新しいノードをクリックします。[フィールド設定] タブで、[DOUBLE 型に変換する列] の [フィールドの選択] をクリックし、すべてのフィールドを選択します。
データを正規化して、各特徴量の値の範囲を [0, 1] に変換し、異なるディメンションが結果に与える影響を排除します。
[正規化] コンポーネントをキャンバスにドラッグし、Type Conversion-1 ノードの出力に接続します。新しいノードをクリックします。[フィールド設定] タブで、正規化するすべてのフィールドを選択します。
データをトレーニングセットと予測セットに分割します。
[分割] コンポーネントをキャンバスにドラッグし、Normalization-1 ノードの出力に接続します。このコンポーネントは 2 つのデータテーブルを出力します。
デフォルトでは、[分割] コンポーネントはデータを 4:1 の比率でトレーニングセットと予測セットに分割します。Split-1 ノードをクリックし、右側のペインの [パラメーター] タブで [分割比率] を設定できます。他のパラメーターの詳細については、「分割」をご参照ください。
Type Conversion-1 コンポーネントを右クリックし、[ここから実行] をクリックして、ワークフローの残りのノードを実行します。
ステップ 3:モデルのトレーニング
心臓病予測は、各サンプルが患者が病気か健康かを示すため、二値分類問題です。このセクションでは、二値分類ロジスティック回帰コンポーネントを使用して心臓病予測モデルを構築します。
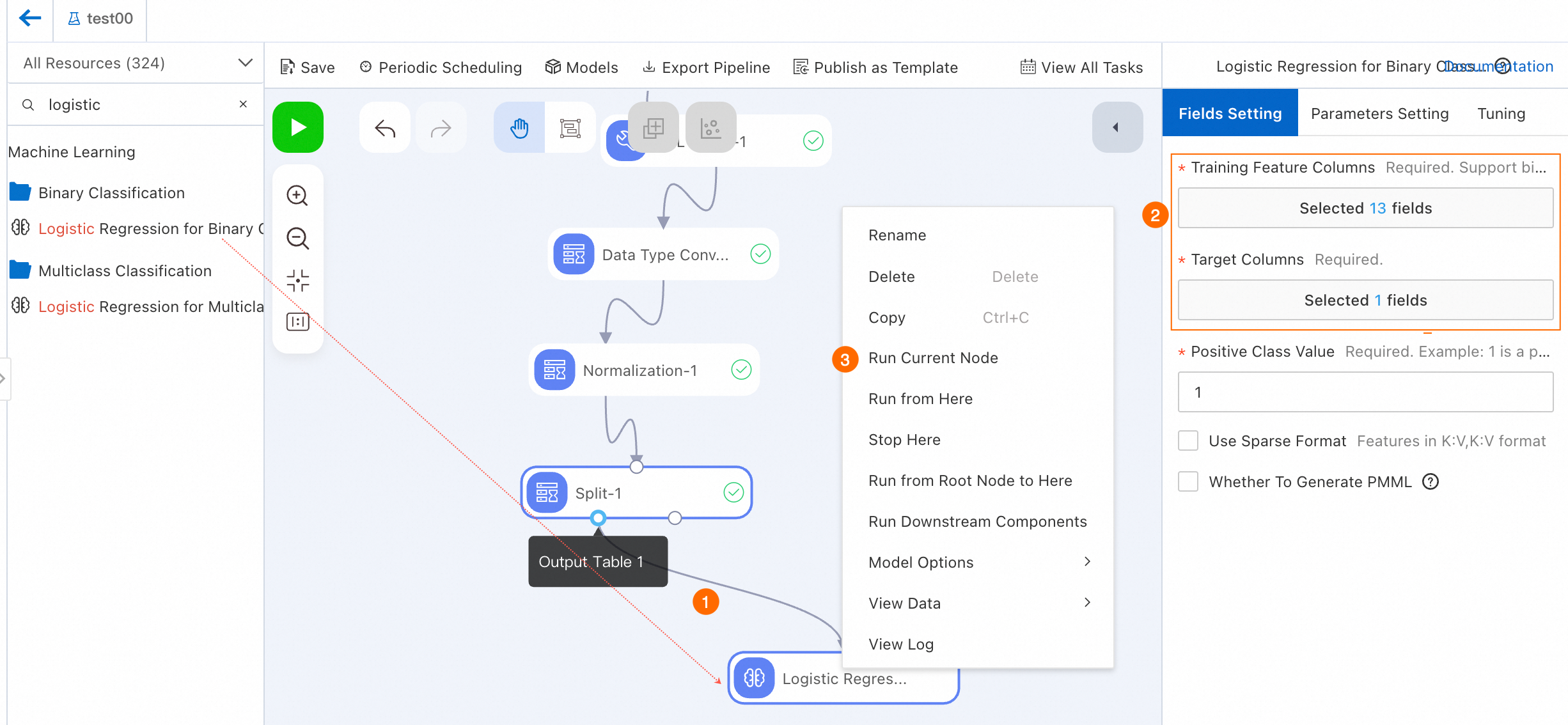
Binary Logistic Regression コンポーネントをドラッグし、Split-1 ノードの Output Table 1 の子孫ノードとして接続します。
ノードを設定します。
Logistic Regression Binary Classification-1 ノードをクリックします。右側の [フィールド設定] タブで、[ターゲット列] を ifhealth に設定し、他のすべての列を [トレーニング特徴量列] として選択します。パラメーターの詳細については、「二値分類ロジスティック回帰」をご参照ください。
説明任意の ステップ 6:モデルのデプロイメント (任意) を実行するには、Logistic Regression Binary Classification-1 ノードをクリックし、[フィールド設定] タブで [PMML の生成] チェックボックスをオンにします。
ノードを実行します。
ステップ 4:モデルの予測
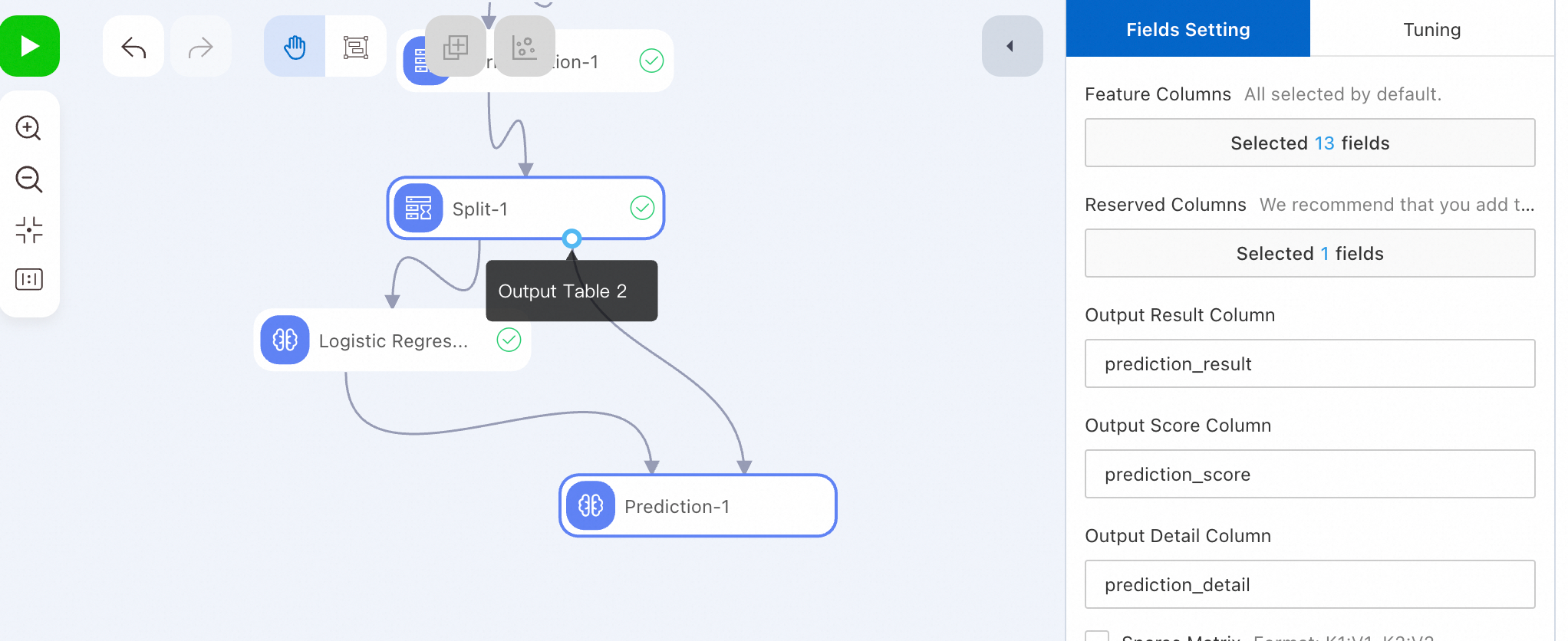
予測ノードを実行し、予測結果を表示します。
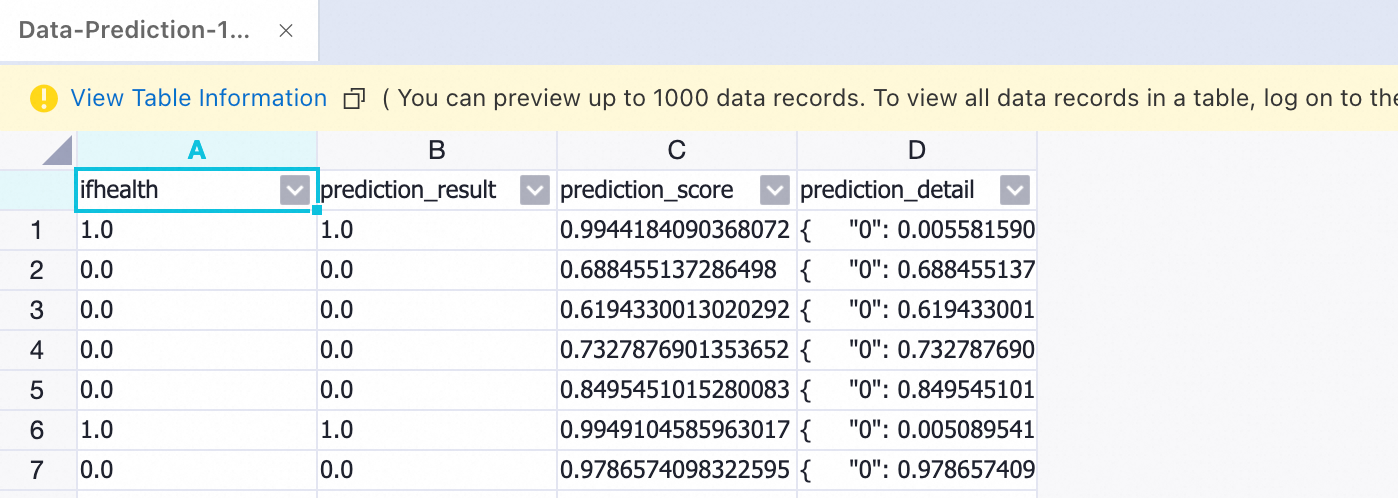
ノードが正常に実行された後、ノードを右クリックし、[データの表示] > [予測結果の出力] を選択して予測データを表示します。
ステップ 5:モデルの評価
[二値分類評価] コンポーネントをキャンバスにドラッグし、Prediction-1 ノードの出力に接続します。
Binary Classification Evaluation-1 ノードをクリックします。右側のペインの [フィールド設定] タブで、[元のラベル列名] を ifhealth に設定します。
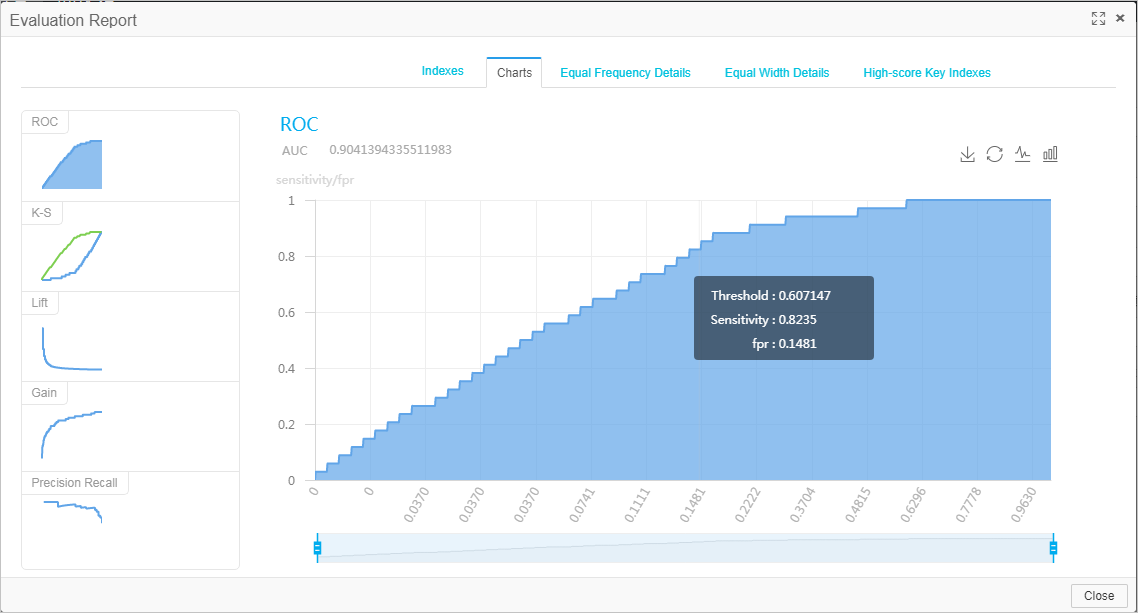
評価ノードを実行し、モデルの評価結果を表示します。
実行が完了したら、Binary Classification Evaluation-1 ノードを右クリックし、[可視化分析] を選択して、評価メトリックの視覚的な表現を表示します。
ステップ 6:モデルのデプロイメント (任意)
Machine Learning Designer は Elastic Algorithm Service (EAS) とシームレスに統合されています。オフラインでのトレーニング、予測、評価が完了したら、モデルを EAS にデプロイしてオンラインモデルサービスを作成できます。
ワークフローが正常に実行された後、キャンバスの上部にある [モデルリスト] をクリックします。デプロイするモデルを選択し、[EAS にデプロイ] をクリックします。

設定パラメーターを確認します。詳細については、「モデルをオンラインサービスとしてデプロイする」をご参照ください。
EAS デプロイページでは、[モデルファイル] と [プロセッサタイプ] はデフォルトで設定されています。必要に応じて他のパラメーターを設定できます。
[デプロイ] をクリックします。
[サービスステータス] が [作成中] から [実行中] に変わると、モデルは正常にデプロイされています。
重要デプロイしたオンラインモデルが不要になった場合は、[アクション] 列の [停止] をクリックして、不要な料金が発生しないようにしてください。
参考文献
Machine Learning Designer は、モデルを迅速に構築するために使用できる包括的なワークフローテンプレートセットを提供します。詳細については、「テンプレートワークフロー」をご参照ください。
DataWorks を使用してワークフローのオフラインスケジューリングを実行し、モデルを定期的に更新できます。詳細については、「DataWorks を使用した Designer ワークフローのオフラインスケジューリング」をご参照ください。
ワークフローでグローバル変数を設定し、オンラインサービスや DataWorks のオフラインスケジューリングで使用して、ワークフローの柔軟性と効率を向上させることができます。詳細については、「グローバル変数」をご参照ください。
詳細については、「Machine Learning Designer の課金」をご参照ください。