Elastic Algorithm Service (EAS) は、デプロイされたモデル推論サービスを呼び出すための共有ゲートウェイと専用ゲートウェイを提供します。これらのサービスには、インターネットまたはプライベートネットワーク経由でアクセスできます。どちらの方法でもプロセスは似ています。ニーズに最適なゲートウェイタイプとアクセス方法を選択してください。
ゲートウェイタイプの選択
EAS は共有ゲートウェイと専用ゲートウェイを提供します。違いは以下のとおりです。
比較 | 共有ゲートウェイ | 専用ゲートウェイ |
パブリックネットワークからの呼び出し | デフォルトでサポート | サポートされていますが、最初に有効にする必要があります |
プライベートネットワークアクセス | デフォルトでサポート | サポートされていますが、最初に有効にする必要があります |
コスト | 無料 | 追加料金が必要 |
帯域幅 | 共有 | 専用 |
シナリオ | トラフィックが少なく、カスタムアクセスポリシーを必要としないステージング環境のサービス | 高いセキュリティ、安定性、パフォーマンスを必要とする高トラフィックのサービス |
構成方法 | デフォルト構成。すぐに使用可能。 | 最初に作成し、デプロイ時に選択する必要があります。詳細については、「専用ゲートウェイの使用」をご参照ください。 |
推奨事項:
開発およびテスト環境には 共有ゲートウェイ を使用します。
本番環境には 専用ゲートウェイ を使用します。
アクセス方法の選択
インターネットエンドポイント
環境にインターネットアクセスがある場合は、この方法を使用します。リクエストは EAS 共有ゲートウェイを介してデプロイされたサービスに転送されます。
シナリオ:
Alibaba Cloud の外部からのサービス呼び出し
ローカルでの開発とテスト
外部アプリケーションとの統合
VPC アドレス
アプリケーションと EAS サービスが 同じリージョン にデプロイされている場合は、この方法を使用します。同じリージョン内の VPC ネットワークは、安全な通信のために VPC 接続を確立できます。
シナリオ:
アプリケーションが EAS サービスと同じリージョンの Alibaba Cloud 上で実行されている場合。
より低いレイテンシーとコストが求められます。
サービスをインターネットに公開すべきではない場合。
インターネット経由での呼び出しと比較して、VPC 内での呼び出しは、インターネットアクセスによるネットワークパフォーマンスのオーバーヘッドを回避するため、高速です。また、プライベートネットワークトラフィックは通常無料であるため、コストも安くなります。
サービスの呼び出し方法
EAS サービスを呼び出すには、次の3つの主要な要素が必要です。
サービスエンドポイント
認証トークン
モデルの API 仕様に従って構造化されたリクエスト
ステップ 1: エンドポイントとトークンの取得
サービスをデプロイすると、システムは自動的にエンドポイントと認証トークンを生成します。
コンソールはベースエンドポイントを提供します。通常、完全なリクエスト URL を形成するには、正しい API パスを追加する必要があります。不正確なパスは、404 Not Found エラーの最も一般的な原因です。
Inference Service タブで、対象のサービス名をクリックして、Overview ページに移動します。
Basic Information セクションで、View Endpoint Information をクリックします。
Invocation Method パネルで、エンドポイントとトークンをコピーします。
必要に応じて インターネットエンドポイント または VPC エンドポイント を選択します。
以下の例では、エンドポイントに <EAS_ENDPOINT>、トークンに <EAS_TOKEN> を使用しています。

ステップ 2: リクエストの構築と送信
インターネットエンドポイントを使用する場合でも VPC エンドポイントを使用する場合でも、リクエスト形式は同じです。標準リクエストには通常、次の4つのコア要素が含まれます。
メソッド: 最も一般的なメソッドは POST と GET です。
URL:
形式: <EAS_ENDPOINT> + API パス
例:
http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test+/v1/chat/completion
ヘッダー:
Authorization: <EAS_TOKEN>(認証に必要)Content-Type: application/json(通常、POST リクエストに必要)
ボディ: JSON などの形式は、デプロイされたモデルの API 仕様によって異なります。
重要ゲートウェイ経由で呼び出す場合、リクエストボディサイズは 1 MB を超えることはできません。
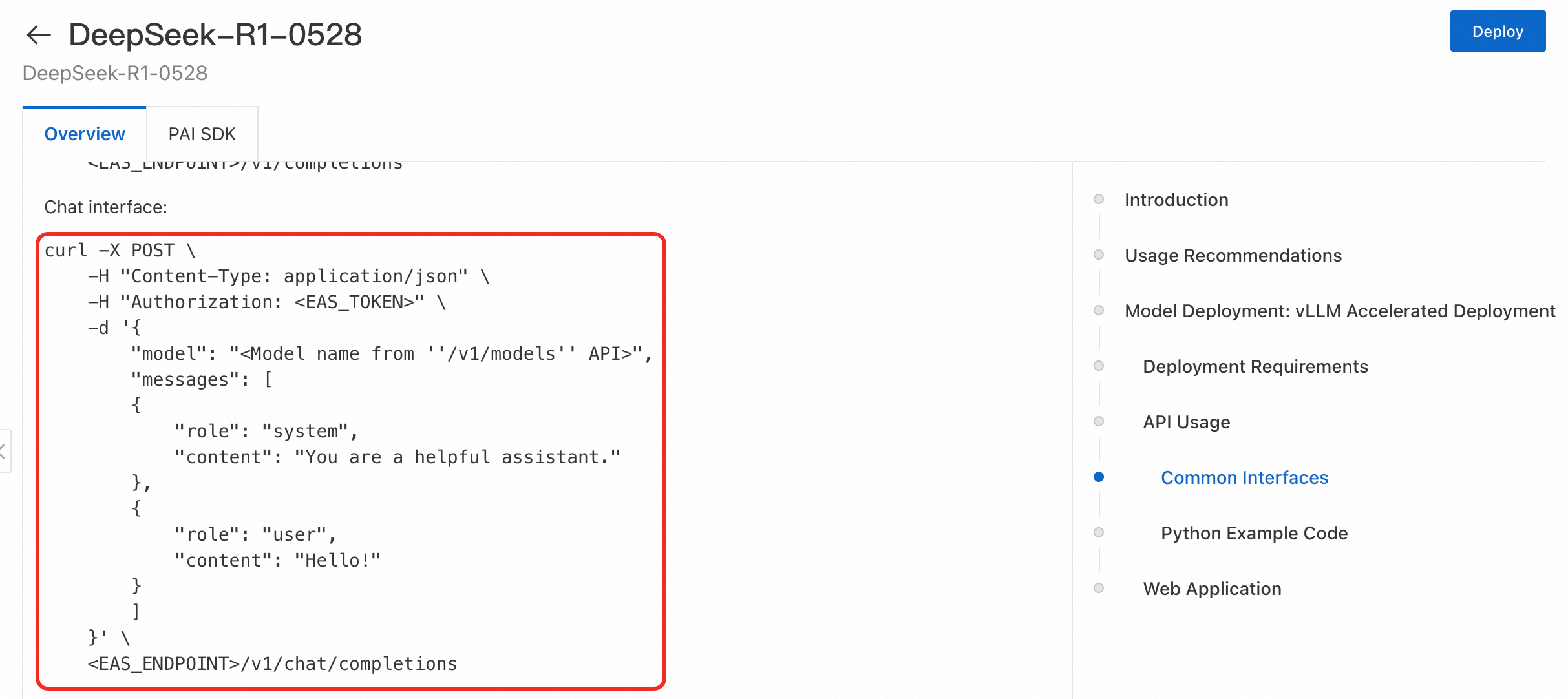
呼び出し例
vLLM でデプロイされた DeepSeek-R1-Distill-Qwen-7B モデルサービスを呼び出すには、次の要素が必要です。
メソッド: POST
リクエストパス: <EAS_ENDPOINT>/v1/chat/completions (チャット API)
ヘッダー:
Authorization: <Token>
Content-Type: application/json
リクエストボディ:
{ "model": "DeepSeek-R1-Distill-Qwen-7B", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "hello!" } ] }
コード例:
<EAS_ENDPOINT> が http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test であると仮定します。
curl http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: *********5ZTM1ZDczg5OT**********" \
-X POST \
-d '{
"model": "DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "hello!"
}
]
}' import requests
# Replace with your actual endpoint.
url = 'http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test/v1/chat/completions'
# The value of Authorization in the header is your actual token.
headers = {
"Content-Type": "application/json",
"Authorization": "*********5ZTM1ZDczg5OT**********",
}
# Construct the service request based on the data format required by the specific model.
data = {
"model": "DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "hello!"
}
]
}
# Send the request.
resp = requests.post(url, json=data, headers=headers)
print(resp)
print(resp.content)大規模言語モデル (LLM) サービスの呼び出しの詳細については、「LLM サービス呼び出し」をご参照ください。
その他のシナリオ
モデルギャラリーからデプロイされたモデル: これらのモデルの Overview ページには、通常、完全な URL パスおよびリクエストフォーマットを含む API 呼び出しの例が記載されています。
cURL コマンド
基本構文:
curl [options] [URL]一般的なパラメーター (オプション):
-X:-X POSTのように HTTP メソッドを指定します。-H:-H "Content-Type: application/json"のようにリクエストヘッダーを追加します。-d:-d '{"key": "value"}'のようにリクエストボディを追加します。
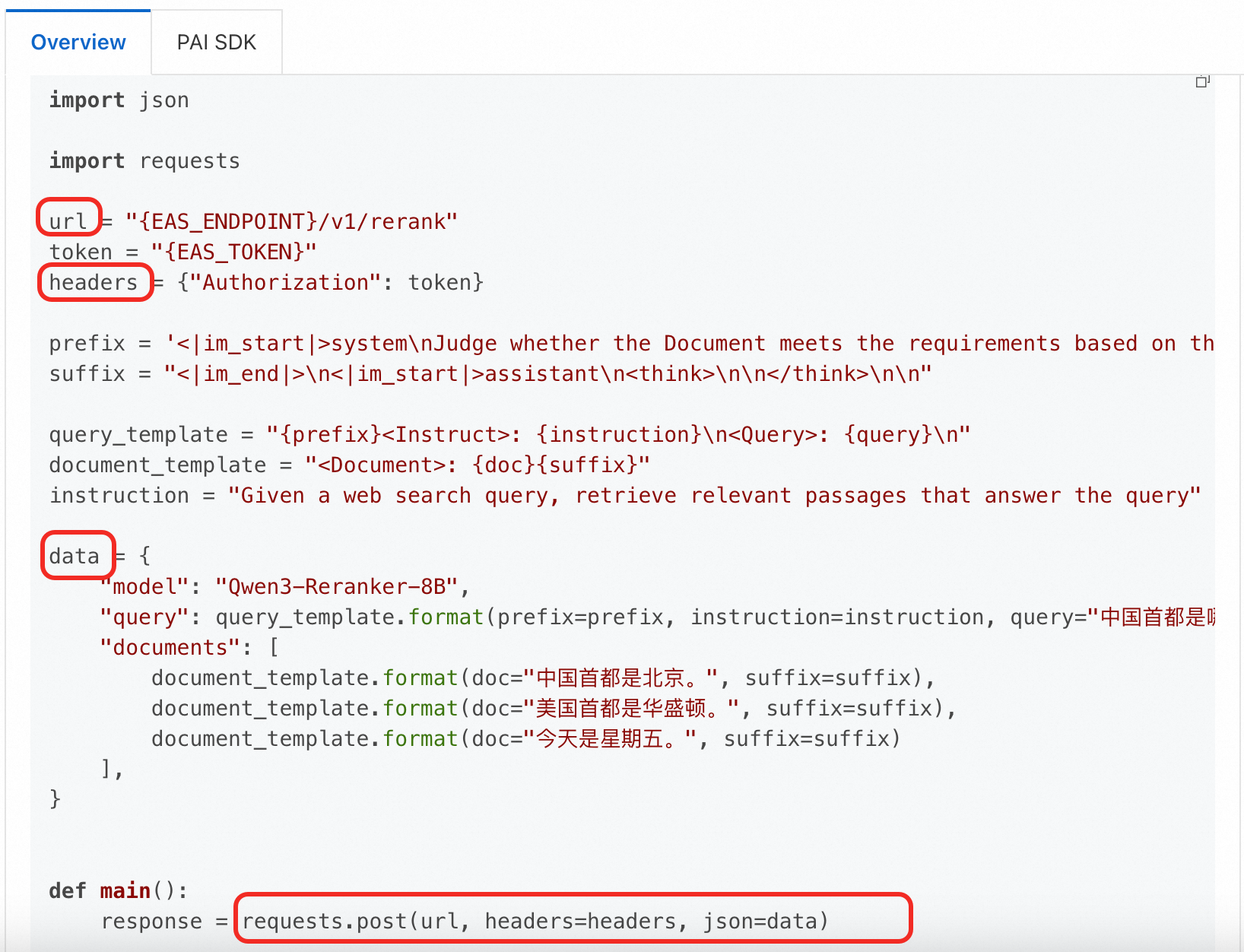
Python コード
以下の Python コードは、Qwen3-Reranker-8B モデルを例として使用しています。その URL とリクエストボディは cURL コマンドの例とは異なることに注意してください。対応するモデルの紹介を必ず参照してください。
シナリオベースのデプロイメント:
TensorFlow、Caffe、PMML などの汎用プロセッサを使用してデプロイされたサービス: 詳細については、「汎用プロセッサに基づいてサービスリクエストを構築」をご参照ください。
その他のカスタムサービス: リクエスト形式は、カスタムイメージまたはコードで定義するデータ入力形式によって決定されます。
自分でトレーニングしたモデル: 呼び出し方法は元のモデルと同じです。
よくある質問
サービス呼び出しに関連するよくある質問とソリューションについては、「サービス呼び出しのよくある質問」をご参照ください。