NVIDIA Triton Inference Server は、TensorRT、TensorFlow、PyTorch、ONNX、およびその他のフレームワークのモデルをサポートする、パフォーマンス専有型の推論サービングプラットフォームです。このガイドでは、Alibaba Cloud Elastic Algorithm Service (EAS) 上で Triton ベースの推論サービスをデプロイする方法について説明します。
前提条件
PAI ワークスペースと同じリージョンにある Object Storage Service (OSS) バケット
トレーニング済みのモデルファイル (例:
.pt、.onnx、.plan、.savedmodel)
クイックスタート:単一モデルサービスのデプロイ
ステップ 1:モデルリポジトリの準備
Triton では、ご利用の Object Storage Service (OSS) バケット内に特定のディレクトリ構造が必要です。以下のフォーマットでディレクトリを作成してください。詳細については、ディレクトリの管理およびファイルのアップロードをご参照ください。
oss://your-bucket/models/triton/
└── your_model_name/
├── 1/ # バージョンディレクトリ (数字である必要があります)
│ └── model.pt # モデルファイル
└── config.pbtxt # モデル設定ファイル
主な要件:
モデルのバージョンディレクトリは、数字 (
1、2、3など) で命名する必要があります。数字が大きいほど、新しいバージョンを示します。
各モデルには
config.pbtxt設定ファイルが必要です。
ステップ 2:モデル設定ファイルの作成
モデルの基本情報を定義するために、config.pbtxt ファイルを作成します。以下に例を示します。
name: "your_model_name"
platform: "pytorch_libtorch"
max_batch_size: 128
input [
{
name: "INPUT__0"
data_type: TYPE_FP32
dims: [ 3, -1, -1 ]
}
]
output [
{
name: "OUTPUT__0"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]
# 推論に GPU を使用
# instance_group [
# {
# kind: KIND_GPU
# }
# ]
# モデルバージョンポリシー
# 最新バージョンのみをロード (デフォルトの動作)
# version_policy: { latest: { num_versions: 1 }}
# すべてのバージョンをロード
# version_policy: { all { }}
# 最新の 2 つのバージョンをロード
# version_policy: { latest: { num_versions: 2 }}
# 特定のバージョンをロード
# version_policy: { specific: { versions: [1, 3] }}
パラメーターの説明
パラメーター | 必須 | 説明 |
| いいえ | モデルの名前。指定する場合、モデルのディレクトリ名と一致する必要があります。 |
| はい | モデルのフレームワーク。有効な値には 標準的なモデルファイル (例:.pt、.onnx、.savedmodel) をデプロイする場合に選択します。 |
| はい |
前処理/後処理またはコア推論のためにカスタム Python コードを記述する必要がある場合に選択します。 説明 Triton のアーキテクチャは C++ などの他の言語でのカスタムバックエンド開発をサポートしていますが、これは一般的な方法ではなく、このガイドでは扱いません。 |
| はい | 最大バッチサイズ。バッチ処理を無効にするには |
| はい | 入力テンソルの設定: |
| はい | 出力テンソルの設定: |
| いいえ | 推論デバイスを指定します: |
| いいえ | どのモデルバージョンをロードするかを制御します。設定の詳細については、 |
platform または backend のいずれかを指定する必要があります。
ステップ 3:サービスのデプロイ
PAI コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS)] をクリックします。
[推論サービス] タブで [サービスをデプロイ] をクリックし、Scenario-based Model Deployment セクションで Triton Deployment をクリックします。
デプロイメントパラメーターを設定します。
Service Name:カスタムサービス名を入力します。
[モデル設定]:[タイプ] で OSS を選択します。モデルリポジトリへのパス (例:
oss://your-bucket/models/triton/) を入力します。Number of Replicas と [リソースグループタイプ]:要件に基づいて値を選択します。モデルに必要な GPU メモリを見積もるには、大規模モデルに必要な VRAM の見積もりをご参照ください。
Deploy をクリックし、サービスが開始されるのを待ちます。
ステップ 4:gRPC の有効化 (任意)
デフォルトでは、Triton はポート 8000 で HTTP サービスを提供します。gRPC を使用するには:
サービス設定ページの右上隅にある [カスタムデプロイに変換] をクリックします。
Environment Information セクションで、Port Number を
8001に変更します。Features > Advanced Networking で、[gRPC を有効にする] をクリックします。
Deploy をクリックします。
サービスが正常にデプロイされた後、サービスを呼び出すことができます。
複数モデルサービスのデプロイ
単一の Triton インスタンスに複数のモデルをデプロイするには、すべてのモデルを同じリポジトリディレクトリに配置します。
oss://your-bucket/models/triton/
├── resnet50_pytorch/
│ ├── 1/
│ │ └── model.pt
│ └── config.pbtxt
├── densenet_onnx/
│ ├── 1/
│ │ └── model.onnx
│ └── config.pbtxt
└── classifier_tensorflow/
├── 1/
│ └── model.savedmodel/
│ ├── saved_model.pb
│ └── variables/
└── config.pbtxt
デプロイ手順は単一モデルの場合と同じです。Triton はリポジトリ内のすべてのモデルを自動的にロードします。
Python バックエンドを使用した推論ロジックのカスタマイズ
Triton の Python バックエンドを使用して、前処理、後処理、またはコア推論ロジックをカスタマイズします。
ディレクトリ構造
your_model_name/
├── 1/
│ ├── model.pt # モデルファイル
│ └── model.py # カスタム推論ロジック
└── config.pbtxt
Python バックエンドの実装
model.py ファイルを作成し、TritonPythonModel クラスを定義します。
import json
import os
import torch
from torch.utils.dlpack import from_dlpack, to_dlpack
import triton_python_backend_utils as pb_utils
class TritonPythonModel:
"""クラス名は 'TritonPythonModel' である必要があります。"""
def initialize(self, args):
"""
任意。モデルがロードされるときに一度だけ呼び出されます。この関数を使用して、
モデルのプロパティと設定を初期化します。
パラメーター
----------
args : キーと値が両方とも文字列である辞書。以下を含みます:
* model_config: JSON 形式のモデル設定。
* model_instance_kind: デバイスの種類。
* model_instance_device_id: デバイス ID。
* model_repository: モデルリポジトリへのパス。
* model_version: モデルのバージョン。
* model_name: モデル名。
"""
# JSON 表現からモデル設定を解析します。
self.model_config = model_config = json.loads(args["model_config"])
# モデル設定ファイルからプロパティを取得します。
output_config = pb_utils.get_output_config_by_name(model_config, "OUTPUT__0")
# Triton の型を NumPy の型に変換します。
self.output_dtype = pb_utils.triton_string_to_numpy(output_config["data_type"])
# モデルリポジトリへのパスを取得します。
self.model_directory = os.path.dirname(os.path.realpath(__file__))
# モデル推論用のデバイスを取得します。この例では GPU を使用します。
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("device: ", self.device)
model_path = os.path.join(self.model_directory, "model.pt")
if not os.path.exists(model_path):
raise pb_utils.TritonModelException("Cannot find the pytorch model")
# .to(self.device) を使用して PyTorch モデルを GPU にロードします。
self.model = torch.jit.load(model_path).to(self.device)
print("Initialized...")
def execute(self, requests):
"""
必須。このメソッドはすべての推論リクエストに対して呼び出されます。バッチ処理が有効な場合、
バッチ処理ロジックを自分で実装する必要があります。
パラメーター
----------
requests : pb_utils.InferenceRequest オブジェクトのリスト。
戻り値
-------
pb_utils.InferenceResponse オブジェクトのリスト。リストには、各リクエストに対して
1 つの応答が含まれている必要があります。
"""
output_dtype = self.output_dtype
responses = []
# リクエストリストを反復処理し、各リクエストに対応する応答を作成します。
for request in requests:
# 入力テンソルを取得します。
input_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT__0")
# Triton テンソルを Torch テンソルに変換します。
pytorch_tensor = from_dlpack(input_tensor.to_dlpack())
if pytorch_tensor.shape[2] > 1000 or pytorch_tensor.shape[3] > 1000:
responses.append(
pb_utils.InferenceResponse(
output_tensors=[],
error=pb_utils.TritonError(
"Image shape should not be larger than 1000"
),
)
)
continue
# ターゲットデバイスで推論を実行します。
prediction = self.model(pytorch_tensor.to(self.device))
# Torch の出力テンソルを Triton テンソルに変換します。
out_tensor = pb_utils.Tensor.from_dlpack("OUTPUT__0", to_dlpack(prediction))
inference_response = pb_utils.InferenceResponse(output_tensors=[out_tensor])
responses.append(inference_response)
return responses
def finalize(self):
"""
任意。モデルがアンロードされるときに呼び出されます。リソースの解放などの
クリーンアップタスクに使用します。
"""
print("Cleaning up...")Python バックエンドを使用する場合、Triton の一部の動作が変更されることにご注意ください。
max_batch_sizeは効果がありません:config.pbtxtのmax_batch_sizeパラメーターは、Python バックエンドで動的バッチ処理を有効にしません。executeメソッドのrequestsリストを反復処理し、推論用のバッチを手動で構築する必要があります。instance_groupは効果がありません:config.pbtxtのinstance_groupは、Python バックエンドが CPU と GPU のどちらを使用するかを制御しません。pytorch_tensor.to(torch.device("cuda"))のようなコードを使用して、initializeおよびexecuteメソッドでモデルとデータをターゲットデバイスに明示的に移動する必要があります。
設定ファイルの更新
name: "resnet50_pt"
backend: "python"
max_batch_size: 128
input [
{
name: "INPUT__0"
data_type: TYPE_FP32
dims: [ 3, -1, -1 ]
}
]
output [
{
name: "OUTPUT__0"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]
parameters: {
key: "FORCE_CPU_ONLY_INPUT_TENSORS"
value: {string_value: "no"}
}主要なパラメーターの説明は以下の通りです。
backend:
pythonに設定する必要があります。parameters:GPU を推論に使用する場合、オプションで
FORCE_CPU_ONLY_INPUT_TENSORSパラメーターをnoに設定して、CPU と GPU 間での入力テンソルのコピーによるオーバーヘッドを回避できます。
サービスのデプロイ
Python バックエンドには共有メモリが必要です。 で、以下の JSON 設定を入力し、[デプロイ] をクリックします。
{
"metadata": {
"name": "triton_server_test",
"instance": 1
},
"cloud": {
"computing": {
"instance_type": "ml.gu7i.c8m30.1-gu30",
"instances": null
}
},
"containers": [
{
"command": "tritonserver --model-repository=/models",
"image": "eas-registry-vpc.<region>.cr.aliyuncs.com/pai-eas/tritonserver:25.03-py3",
"port": 8000,
"prepare": {
"pythonRequirements": [
"torch==2.0.1"
]
}
}
],
"storage": [
{
"mount_path": "/models",
"oss": {
"path": "oss://oss-test/models/triton_backend/"
}
},
{
"empty_dir": {
"medium": "memory",
// 1 GB の共有メモリを設定します。
"size_limit": 1
},
"mount_path": "/dev/shm"
}
]
}
主要な JSON 設定の説明:
containers[0].image:Triton の公式イメージ。<region>をサービスが配置されているリージョンに置き換えてください。containers[0].prepare.pythonRequirements:ここに Python の依存関係をリストアップします。EAS はサービス開始前にこれらを自動的にインストールします。storage:2 つのマウントポイントを含みます。1 つ目は、OSS モデルリポジトリのパスをコンテナー内の
/modelsディレクトリにマウントします。2 つ目の
storageエントリは、必須である共有メモリを設定します。Triton サーバーと Python バックエンドは、/dev/shmパスを使用してゼロコピーでテンソルデータを渡し、パフォーマンスを最大化します。size_limitの単位は GB です。モデルと予想される同時実行数に基づいて必要なサイズを見積もってください。
サービスの呼び出し
サービスエンドポイントとトークンの取得
Elastic Algorithm Service (EAS) ページで、サービス名をクリックします。
Service Details タブで、View Endpoint Information をクリックします。Internet Endpoint と Token をコピーします。
HTTP リクエストの送信
ポート番号が 8000 に設定されている場合、サービスは HTTP リクエストをサポートします。
import numpy as np
# tritonclient パッケージをインストールするには、pip install tritonclient を実行します
import tritonclient.http as httpclient
# サービスエンドポイントの URL。`http://` スキームは含めないでください。
url = '1859257******.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/triton_server_test'
triton_client = httpclient.InferenceServerClient(url=url)
image = np.ones((1,3,224,224))
image = image.astype(np.float32)
inputs = []
inputs.append(httpclient.InferInput('INPUT__0', image.shape, "FP32"))
inputs[0].set_data_from_numpy(image, binary_data=False)
outputs = []
outputs.append(httpclient.InferRequestedOutput('OUTPUT__0', binary_data=False)) # 1000 次元のベクターを取得
# モデル名、リクエストトークン、入力、出力を指定します。
results = triton_client.infer(
model_name="<your-model-name>",
model_version="<version-num>",
inputs=inputs,
outputs=outputs,
headers={"Authorization": "<your-service-token>"},
)
output_data0 = results.as_numpy('OUTPUT__0')
print(output_data0.shape)
print(output_data0)gRPC リクエストの送信
ポート番号が 8001 に設定され、gRPC 関連の設定が行われている場合、サービスは gRPC リクエストをサポートします。
gRPC エンドポイントは HTTP エンドポイントとは異なります。サービス詳細ページから正しい gRPC エンドポイントを取得してください。
#!/usr/bin/env python
import grpc
# tritonclient パッケージをインストールするには、pip install tritonclient を実行します
from tritonclient.grpc import service_pb2, service_pb2_grpc
import numpy as np
if __name__ == "__main__":
# サービスデプロイ後に生成されるアクセス URL (サービスエンドポイント)。
# `http://` スキームは含めないでください。ポート `:80` を追加します。
# Triton は内部的にポート 8001 でリッスンしますが、PAI-EAS は外部にポート 80 を介して gRPC を公開します。クライアントでは :80 を使用してください。
host = (
"service_name.115770327099****.cn-beijing.pai-eas.aliyuncs.com:80"
)
# サービストークン。実際のアプリケーションでは、ご自身のトークンを使用してください。
token = "<your-service-token>"
# モデル名とバージョン。
model_name = "<your-model-name>"
model_version = "<version-num>"
# トークン認証用の gRPC メタデータを作成します。
metadata = (("authorization", token),)
# サーバーと通信するための gRPC チャンネルとスタブを作成します。
channel = grpc.insecure_channel(host)
grpc_stub = service_pb2_grpc.GRPCInferenceServiceStub(channel)
# 推論リクエストを構築します。
request = service_pb2.ModelInferRequest()
request.model_name = model_name
request.model_version = model_version
# 入力テンソルを構築します。モデル設定の入力と一致する必要があります。
input_tensor = service_pb2.ModelInferRequest().InferInputTensor()
input_tensor.name = "INPUT__0"
input_tensor.datatype = "FP32"
input_tensor.shape.extend([1, 3, 224, 224])
# 出力テンソルを構築します。モデル設定の出力と一致する必要があります。
output_tensor = service_pb2.ModelInferRequest().InferRequestedOutputTensor()
output_tensor.name = "OUTPUT__0"
# 入力テンソルと出力テンソルをリクエストに追加します。
request.inputs.extend([input_tensor])
request.outputs.extend([output_tensor])
# ランダムな配列を作成し、入力データとしてバイトシーケンスにシリアル化します。
request.raw_input_contents.append(np.random.rand(1, 3, 224, 224).astype(np.float32).tobytes())
# 推論リクエストを送信し、応答を受信します。
response, _ = grpc_stub.ModelInfer.with_call(request, metadata=metadata)
# 応答から出力テンソルを抽出します。
output_contents = response.raw_output_contents[0] # 出力テンソルが 1 つだけであると仮定します。
output_shape = [1, 1000] # 出力テンソルの形状が [1, 1000] であると仮定します。
# 出力バイトを NumPy 配列に変換します。
output_array = np.frombuffer(output_contents, dtype=np.float32)
output_array = output_array.reshape(output_shape)
# モデルの出力を表示します。
print("Model output:\n", output_array)デバッグのヒント
詳細ログの有効化
verbose=True を設定して、リクエストと応答の JSON データを表示します。
client = httpclient.InferenceServerClient(url=url, verbose=True)
出力例:
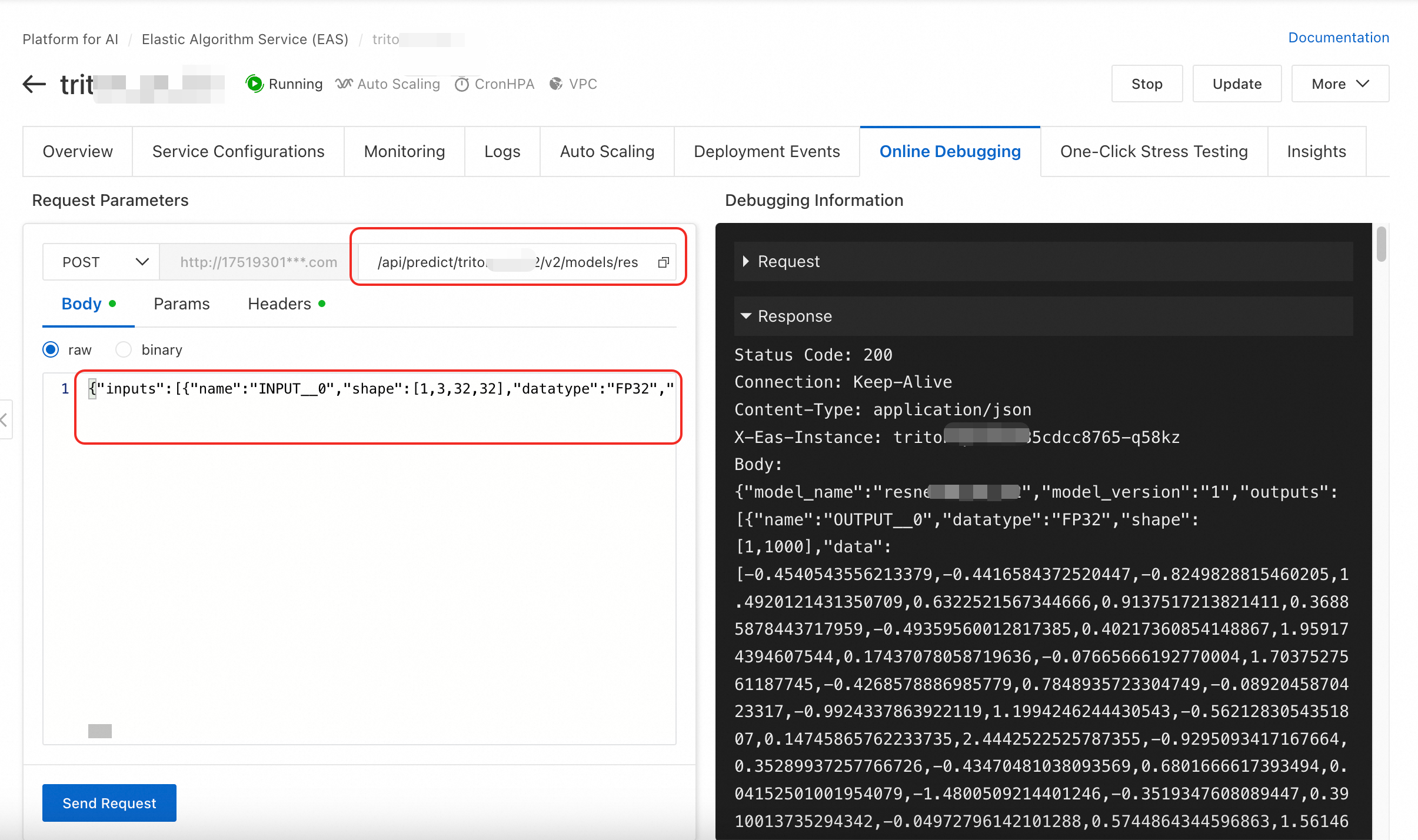
POST /api/predict/triton_test/v2/models/resnet50_pt/versions/1/infer, headers {'Authorization': '************1ZDY3OTEzNA=='}
b'{"inputs":[{"name":"INPUT__0","shape":[1,3,32,32],"datatype":"FP32","data":[1.0,1.0,1.0,.....,1.0]}],"outputs":[{"name":"OUTPUT__0","parameters":{"binary_data":false}}]}'オンラインデバッグ
コンソールのオンラインデバッグを使用して直接テストできます。リクエスト URL を /api/predict/triton_test/v2/models/resnet50_pt/versions/1/infer に補完し、詳細ログの JSON リクエストデータを [本文] として使用します。
サービスのストレステスト
以下の手順では、単一のデータを例として使用してストレステストを実行する方法について説明します。ストレステストの詳細については、一般的なシナリオにおけるサービスのストレステストをご参照ください。
[ワンクリックストレステスト] タブで [ストレステストタスクの作成] をクリックし、デプロイした Triton サービスを選択して、ストレステストの URL を入力します。
[データソース] を [単一データ入力] に設定します。 次のコードを使用して、JSON リクエストボディを Base64 エンコードします:
import base64 # 既存の JSON リクエストボディ文字列 json_str = '{"inputs":[{"name":"INPUT__0","shape":[1,3,32,32],"datatype":"FP32","data":[1.0,1.0,.....,1.0]}]}' # 直接エンコーディング base64_str = base64.b64encode(json_str.encode('utf-8')).decode('ascii') print(base64_str)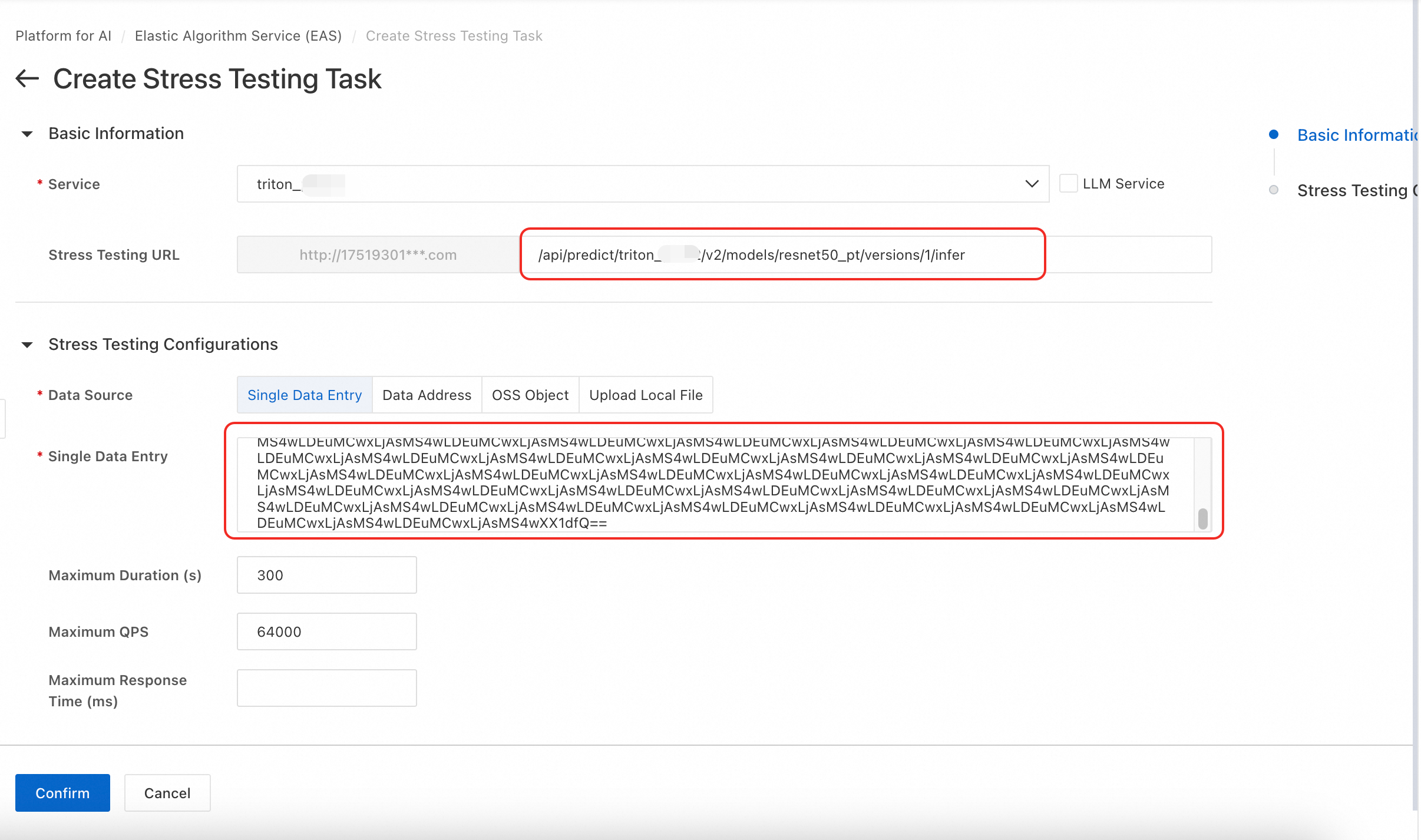
よくある質問
Q:「CUDA error: no kernel image is available for execution on the device」というエラーが表示されるのはなぜですか?
このエラーは、Triton イメージの CUDA バージョンと、選択した GPU インスタンスのアーキテクチャとの間に互換性の不一致があることを示しています。
これを解決するには、イメージの CUDA バージョンと互換性のある別の GPU インスタンスタイプに切り替えてください。例えば、A10 または T4 インスタンスの使用を試みてください。
Q:HTTP リクエストで「InferenceServerException: url should not include the scheme」を修正するにはどうすればよいですか?
このエラーは、tritonclient.http.InferenceServerClient が、プロトコルスキーム (例:http:// や https://) を含まない URL を要求するために発生します。
これを修正するには、URL 文字列からスキームを削除してください。
Q:gRPC 呼び出しを行う際に「DNS resolution failed」エラーを解決するにはどうすればよいですか?
このエラーは、サービスホストが正しくないために発生します。サービスエンドポイントのフォーマットは http://we*****.1751930*****.cn-hangzhou.pai-eas.aliyuncs.com/ です (これは HTTP エンドポイントとは異なることに注意してください)。http:// プレフィックスと末尾の / を削除します。次に、末尾に :80 を追加します。最終的なフォーマットは we*****.1751930*****.cn-hangzhou.pai-eas.aliyuncs.com:80 となります。
関連ドキュメント
TensorFlow Serving 推論エンジンを使用して EAS サービスをデプロイする方法については、TensorFlow Serving イメージのデプロイをご参照ください。
カスタムイメージを開発し、それを使用して EAS サービスをデプロイすることもできます。詳細については、カスタムイメージをご参照ください。
NVIDIA Triton の詳細については、Triton 公式ドキュメントをご参照ください。