TensorFlow Serving は、ディープ ラーニングモデル向けの推論サービスエンジンです。標準の TensorFlow SavedModel 形式で保存されたモデルをオンラインサービスとしてデプロイし、ローリングアップデートやモデルバージョン管理などの機能をサポートします。本トピックでは、TensorFlow Serving イメージを用いてモデルサービスをデプロイする方法について説明します。
前提条件
モデル構成ファイル
TensorFlow Serving イメージを使用してサービスをデプロイするには、モデルファイルを OSS バケットに格納する必要があります。ストレージディレクトリは、次の要件を満たす必要があります:
モデルバージョンディレクトリ:各モデルには、少なくとも1つのモデルバージョンディレクトリが必要です。ディレクトリは、バージョン番号として機能する数値で命名する必要があります。数値が大きいほど、新しいバージョンを示します。
モデルファイル:モデルバージョンディレクトリには、SavedModel フォーマットでエクスポートされたモデルファイルが含まれています。サービスは、最新のバージョン番号を持つディレクトリからモデルファイルを自動的にロードします。
以下の手順に従ってください。
OSS バケットに、
oss://examplebucket/models/tf_serving/のようなモデルストレージディレクトリを作成します。詳細については、「ディレクトリの管理」をご参照ください。手順1で作成したディレクトリにモデルファイルをアップロードします。このトピックでは、サンプルの TensorFlow Serving モデルファイル をダウンロードして使用できます。モデルストレージディレクトリのフォーマットは次のとおりです:
tf_serving ├── modelA │ └── 1 │ ├── saved_model.pb │ └── variables │ ├── variables.data-00000-of-00001 │ └── variables.index │ ├── modelB │ ├── 1 │ │ └── ... │ └── 2 │ └── ... │ └── modelC ├── 1 │ └── ... ├── 2 │ └── ... └── 3 └── ...
モデル構成ファイル
単一のサービスで複数のモデルを実行するには、構成ファイルを使用します。単一モデルのサービスのみをデプロイする場合は、このセクションをスキップしてください。
以下の手順に従って構成ファイルを作成し、OSS にアップロードします。『モデルファイル』セクションで提供されるサンプルファイルには、すでに model_config.pbtxt という名前のモデル構成ファイルが含まれています。このファイルをそのまま使用するか、必要に応じて編集してください。本例では、モデル構成ファイルを oss://examplebucket/models/tf_serving/ ディレクトリにアップロードしています。
以下に、model_config.pbtxt モデル構成ファイルの内容例を示します:
model_config_list {
config {
name: 'modelA'
base_path: '/models/modelA/'
model_platform: 'tensorflow'
model_version_policy{
all: {}
}
}
config {
name: 'modelB'
base_path: '/models/modelB/'
model_platform: 'tensorflow'
model_version_policy{
specific {
versions: 1
versions: 2
}
}
version_labels {
key: 'stable'
value: 1
}
version_labels {
key: 'canary'
value: 2
}
}
config {
name: 'modelC'
base_path: '/models/modelC/'
model_platform: 'tensorflow'
model_version_policy{
latest {
num_versions: 2
}
}
}
}主なパラメーターの説明は以下のとおりです:
パラメーター | 必須 | 説明 |
name | いいえ | モデルのカスタム名です。このパラメーターを設定してください。モデル名を指定しない場合、model_name は空になり、モデルサービスを呼び出せません。 |
base_path | はい | インスタンス内のモデルストレージディレクトリのパスです。このパスは、サービスデプロイメント時にモデルファイルを読み取るために使用されます。たとえば、マウントディレクトリが |
model_version_policy | いいえ | モデルバージョンの読み込みポリシーです。
|
version_labels | いいえ | モデルバージョンに対するカスタムタグを設定します。version_labels を設定しない場合、モデルバージョンはバージョン番号のみで識別できます。リクエストの URI は version_labels を設定すると、リクエスト内でバージョンラベルを指定して特定のバージョン番号を参照できます: 説明 デフォルトでは、ラベルは正常に読み込まれ、サービスとして起動済みのモデルバージョンにのみ割り当て可能です。まだ読み込まれていないモデルバージョンにラベルを割り当てるには、Command to Run 構成において、起動パラメーター |
サービスのデプロイ
TensorFlow Serving イメージは、以下の 2 つの方法のいずれかでデプロイできます。
シナリオベースのモデルデプロイ:基本的なデプロイシナリオに適しています。数個のパラメーターを設定するだけで、TensorFlow Serving モデルサービスをワンクリックでデプロイできます。
カスタムモデルデプロイ:ポートの変更やモデルファイルのポーリング期間の設定など、より多くの構成オプションを調整できます。
TensorFlow Serving モデルサービスは、ポート 8501 および 8500 の 2 つのポートをサポートします。
8501:HTTP リクエストをサポートします。ポート 8501 では HTTP または REST サービスが起動します。
8500:gRPC リクエストをサポートします。ポート 8500 では gRPC サービスが起動します。
シナリオベースのモデルデプロイでは、デフォルトでポート 8501 が使用され、変更できません。ポート 8500 を使用するには、カスタムモデルデプロイを選択してください。
シナリオベースのモデルデプロイ
以下の手順に従ってください。
-
PAI コンソール にログインします。ページ上部でリージョンを選択し、目的のワークスペースを選択して、Elastic Algorithm Service (EAS) をクリックします。
Elastic Algorithm Service (EAS) ページで、Deploy Service をクリックします。その後、Scenario-based Model Deployment セクションで、Tensorflow Serving Deployment をクリックします。
Tensorflow Serving Deployment ページで、パラメーターを設定します。以下に主要なパラメーターについて説明します。その他のパラメーターの設定については、「カスタムデプロイ」をご参照ください。
パラメーター
説明
Deployment Method
以下の 2 つのデプロイ方法がサポートされています。
Standard Model Deployment:単一モデルのサービスをデプロイします。
Configuration File Deployment:マルチモデルのサービスをデプロイします。
Model Settings
Deployment Method を Standard Model Deployment に設定した場合、モデルファイルが格納されている OSS パスを設定する必要があります。
Deployment Method を Configuration File Deployment に設定した場合、以下のパラメーターを設定する必要があります。
OSS:モデルファイルが格納されている OSS パスを選択します。
Mount Path:サービスインスタンス内でのマウント先の宛先パスです。このパスは、モデルファイルを読み取るために使用されます。
Configuration File:モデル構成ファイルが格納されている OSS パスを選択します。
パラメーター設定の例を以下に示します。
パラメーター
単一モデルの例(modelA のデプロイ)
マルチモデルの例
Service Name
modela_scene
multi_scene
Deployment Method
Standard Model Deployment を選択します。
Configuration File Deployment を選択します。
Model Settings
OSS:
oss://examplebucket/models/tf_serving/modelA/。OSS:
oss://examplebucket/models/tf_serving/。Mount Path:/models
Configuration File:
oss://examplebucket/models/tf_serving/model_config.pbtxt
パラメーターを設定した後、Deploy をクリックします。
カスタムモデルデプロイ
以下の手順に従ってください。
-
PAI コンソール にログインします。ページ上部でリージョンを選択し、目的のワークスペースを選択して、Elastic Algorithm Service (EAS) をクリックします。
-
サービスのデプロイ をクリックします。カスタムモデルデプロイ セクションで、カスタムデプロイ をクリックします。
Custom Deployment ページで、パラメーターを設定できます。主なパラメーターについて以下に説明します。その他のパラメーター設定については、「カスタムデプロイ」をご参照ください。
パラメーター
説明
Image Configuration
Alibaba Cloud Image リストから tensorflow-serving および対応するイメージ名を選択します。最新バージョンの使用を推奨します。
説明サービスに GPU が必要な場合、イメージバージョンは x.xx.x-gpu である必要があります。
Model Settings
モデルファイルの構成には複数の方法がサポートされています。本例では、OSS タイプを使用します。
Uri:モデルファイルが格納されている OSS パスを選択します。
Mount Path:サービスインスタンス内でのマウント先の宛先パスです。このパスは、モデルファイルを読み取るために使用されます。
Command to Run
tensorflow-serving の起動パラメーターです。tensorflow-serving イメージを選択すると、コマンド
/usr/bin/tf_serving_entrypoint.shが自動的に読み込まれます。その他の設定が必要なパラメーターについては、以下に説明します。単一モデルデプロイの起動パラメーター:
--model_name:サービスリクエストの URL で使用されるモデル名です。このパラメーターを設定しない場合、デフォルト名は model です。--model_base_path:インスタンス内のモデル格納ディレクトリのパスを指定します。このパラメーターを設定しない場合、デフォルトのパスは/models/modelです。
マルチモデルデプロイの起動パラメーター:
--model_config_file:必須。モデル構成ファイルを指定します。--model_config_file_poll_wait_seconds:任意。サービス起動後にモデル構成ファイルの内容を変更する場合、モデルファイルのポーリング間隔(秒単位)を設定する必要があります。サービスは、設定された間隔でモデル構成ファイルの内容を定期的に読み取ります。たとえば、--model_config_file_poll_wait_seconds=30は、サービスが 30 秒ごとにモデル構成ファイルを読み取ることを意味します。説明モデルサービスが新しいモデル構成ファイルを読み取ると、新しいファイルの内容のみが実行されます。たとえば、古い構成ファイルにモデル A が含まれており、新しい構成ファイルでモデル A が削除され、モデル B の構成が追加された場合、サービスはモデル A をアンインストールし、モデル B を読み込みます。
--allow_version_labels_for_unavailable_models:任意。デフォルト値は false です。まだ読み込まれていないモデルバージョンにタグを割り当てる場合は、このパラメーターを true に設定します。たとえば、--allow_version_labels_for_unavailable_models=trueです。
パラメーター設定の例を以下に示します。
パラメーター
単一モデルの例(modelA のデプロイ)
マルチモデルの例
Deployment Method
Image-based Deployment を選択します。
Image Configuration
Alibaba Cloud Image で、tensorflow-serving > tensorflow-serving:2.14.1 を選択します。
Model Settings
モデルタイプを OSS に設定します。
Uri:
oss://examplebucket/models/tf_serving/。Mount Path:
/modelsに設定します。
Command to Run
/usr/bin/tf_serving_entrypoint.sh --model_name=modelA --model_base_path=/models/modelA/usr/bin/tf_serving_entrypoint.sh --model_config_file=/models/model_config.pbtxt --model_config_file_poll_wait_seconds=30 --allow_version_labels_for_unavailable_models=trueデフォルトのポート番号は 8501 です。サービスはポート 8501 で HTTP または REST サービスを起動し、HTTP リクエストをサポートします。サービスが gRPC リクエストをサポートするようにするには、以下の操作を行います。
Environment Information セクションで、Port Number を 8500 に変更します。
Environment Information で、Enable gRPC スイッチをオンにします。
Service Configurations で、以下の構成を追加します。
"networking": { "path": "/" }
Deploy をクリックします。
サービスリクエストの送信
サービスは、サービスデプロイ時の実行コマンドで設定されたポート番号に応じて、HTTP および gRPC の両方のリクエストプロトコルをサポートします。以下では、modelA に対するサービスリクエストの例を示します。
テストデータの準備
modelA は画像分類モデルです。トレーニングデータセットは Fashion-MNIST であり、サンプルは 28×28 のグレースケール画像です。モデルの出力は、サンプルが 10 クラスのいずれかに属する確率です。テスト目的で、modelA サービスリクエストのテストデータとして
[[[[1.0]] * 28] * 28]を使用します。リクエストの例
HTTP リクエスト
ポート番号を 8501 に設定した場合、サービスは HTTP リクエストをサポートします。以下の表に、単一モデルおよびマルチモデルデプロイにおける HTTP リクエストパスをまとめます。
単一モデル
マルチモデル
パス形式:
<service_url>/v1/models/<モデル名>:predict以下:
シナリオベースのデプロイ: <モデル名> はカスタマイズできず、デフォルトで model になります。
カスタムデプロイ:<モデル名> は、Command to Run で設定されたモデル名です。モデル名が設定されていない場合、デフォルトは
modelです。
バージョンを指定しないリクエストおよびモデルバージョンを指定するリクエストの両方がサポートされています。パス形式は以下のとおりです。
バージョンを指定しない場合(デフォルトで最新バージョンが読み込まれます):
<service_url>/v1/models/<モデル名>:predictモデルバージョンを指定する場合:
<service_url>/v1/models/<モデル名>/versions/<バージョン番号>:predictversion_labels が設定されている場合:
<service_url>/v1/models/<モデル名>/labels/<バージョンラベル>:predict
ここで、<モデル名> はモデル構成ファイルで設定されたモデル名です。
<service_url> パラメーターは、デプロイ済みサービスのエンドポイントです。エンドポイントを確認するには、Elastic Algorithm Service (EAS) ページに移動し、対象サービスの Service Type 列で Invocation Information をクリックします。コンソールでオンラインデバッグを実行する場合、このパスは自動的に入力されます。
単一モデル modelA のシナリオベースデプロイを例にとると、HTTP リクエストパスは
<service_url>/v1/models/model:predictとなります。以下に、コンソールでのオンラインデバッグおよび Python コードを用いたサービスリクエスト送信の例を示します。
オンラインデバッグ
サービスがデプロイされた後、サービスの Actions 列をクリックし、Online Debugging をクリックします。Request Parameter Online Tuning には、すでに <service_url> が入力されています。アドレスにパス
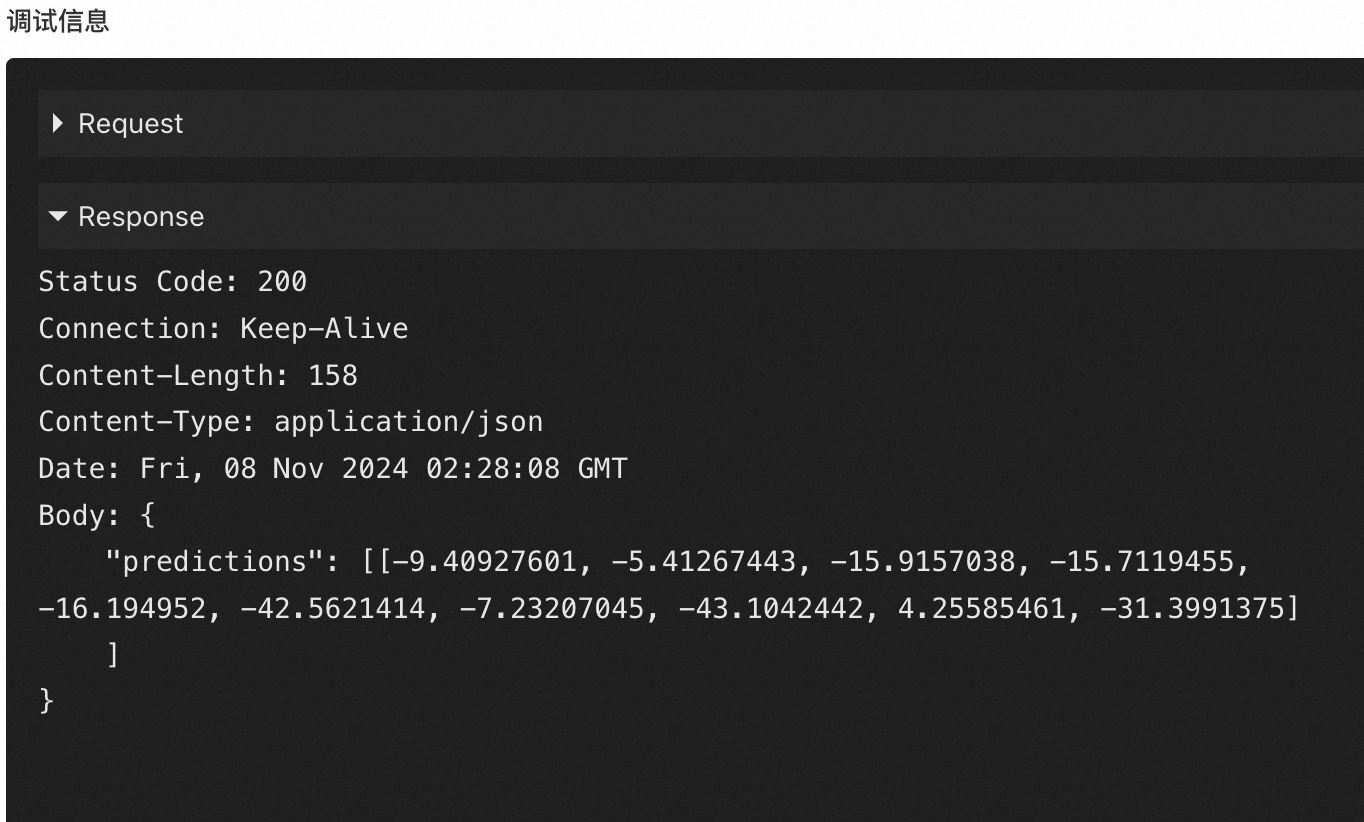
/v1/models/model:predictを追加し、本文 にサービスリクエストデータを設定します。{"signature_name": "serving_default", "instances": [[[[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0......, [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]]]]}パラメーターを設定した後、Send Request をクリックすると、以下のような出力が得られます。
Python コードを用いた HTTP リクエストの送信
以下に Python コードのサンプルを示します。
from urllib import request import json # ご利用のサービスエンドポイントとトークンに置き換えてください。 # これらは、呼び出し情報ページの共有ゲートウェイ - インターネットエンドポイントタブで確認できます。 service_url = '<service_url>' token = '<token>' # シナリオベースの単一モデルデプロイの場合、モデル名は 'model' です。その他のケースについては、上記のパス説明表をご参照ください。 model_name = "model" url = "{}/v1/models/{}:predict".format(service_url, model_name) # HTTP リクエストを作成します。 req = request.Request(url, method="POST") req.add_header('authorization', token) data = { 'signature_name': 'serving_default', 'instances': [[[[1.0]] * 28] * 28] } # サービスを呼び出します。 response = request.urlopen(req, data=json.dumps(data).encode('utf-8')).read() # 結果を表示します。 response = json.loads(response) print(response)gRPC リクエスト
ポート番号が 8500 に設定され、gRPC 関連の構成が追加されている場合、サービスは gRPC リクエストをサポートします。以下に Python コードのサンプルを示します。
import grpc import tensorflow as tf from tensorflow_serving.apis import predict_pb2 from tensorflow_serving.apis import prediction_service_pb2_grpc from tensorflow.core.framework import tensor_shape_pb2 # サービスエンドポイントです。フォーマットについては、以下の host パラメーターの説明をご参照ください。 host = "tf-serving-multi-grpc-test.166233998075****.cn-hangzhou.pai-eas.aliyuncs.com:80" # <token> をサービストークンに置き換えてください。トークンは、共有ゲートウェイ - インターネットエンドポイントタブで確認できます。 token = "<token>" # モデル名です。以下の name パラメーターの説明をご参照ください。 name = "<model_name>" signature_name = "serving_default" # モデルのバージョン番号に設定します。一度にリクエストを送信できるのは、単一のモデルバージョンのみです。 version = "<version_num>" # gRPC リクエストを作成します。 request = predict_pb2.PredictRequest() request.model_spec.name = name request.model_spec.signature_name = signature_name request.model_spec.version.value = version request.inputs["keras_tensor"].CopyFrom(tf.make_tensor_proto([[[[1.0]] * 28] * 28])) # サービスを呼び出します。 channel = grpc.insecure_channel(host) stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) metadata = (("authorization", token),) response, _ = stub.Predict.with_call(request, metadata=metadata) print(response)主なパラメーターは以下のように設定します。
パラメーター
説明
host
サービスエンドポイントとして設定する必要があります。エンドポイントは
http://を省略し、:80で終わる必要があります。エンドポイントは、Elastic Algorithm Service (EAS) ページで、呼び出したいサービスの Service Type 列にある Invocation Information をクリックすることで確認できます。name
単一モデルの gRPC リクエストを送信する場合:
シナリオベースのデプロイ:model に設定します。
カスタムデプロイ:Command to Run 構成で指定されたモデル名として設定します。実行コマンドでモデル名が指定されていない場合、デフォルトで model になります。
複数モデルの gRPC リクエストを送信する場合:
モデル構成ファイルで設定されたモデル名に設定します。
version
モデルのバージョン番号に設定します。一度にリクエストを送信できるのは、単一のモデルバージョンのみです。
metadata
サービスのトークンです。Invocation Information ページでトークンを確認できます。
参照
Triton Inference Server エンジンに基づく Elastic Algorithm Service (EAS) サービスのデプロイ方法については、「Triton Inference Server イメージを用いたサービスデプロイ」をご参照ください。
カスタムイメージを開発し、それを使用して EAS サービスをデプロイすることもできます。詳細については、「カスタムイメージ」をご参照ください。