背景情報
OpenSearch Vector Search Edition のハイブリッドクエリ
ハイブリッドクエリ機能は、セマンティック検索とキーワード検索を組み合わせることで、テキスト検索のパフォーマンスを向上させます。
OpenSearch Vector Search Edition を使用する場合、スパースベクトルとデンスベクトルを使用してハイブリッドクエリを実行できます。 テキスト検索とベクトル検索 に基づく従来のマルチモーダル検索機能と比較して、ハイブリッドクエリ機能はスパースベクトルとデンスベクトルに基づいて提供されます。OpenSearch は、デンスベクトルとスパースベクトルを 1 つのベクトルに結合します。スパースベクトルは、テキストのベクトル化を実行した後に生成されます。デンスベクトルは従来のベクトルです。スパースベクトルとデンスベクトルは異なる種類の情報を表し、異なる種類の検索をサポートします。
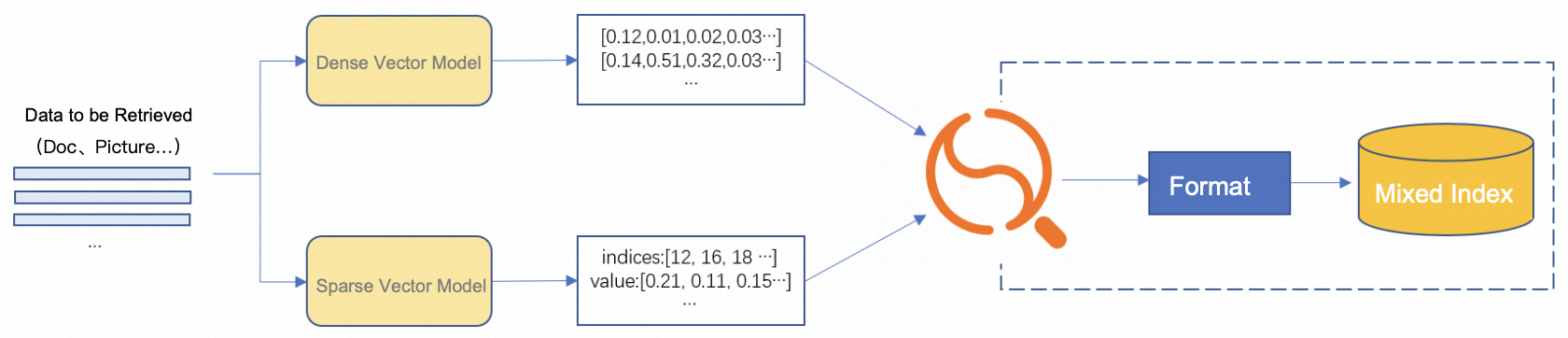
ハイブリッドクエリを実行するには、次の手順を実行します。
デンスベクトルモデルを使用してデンスベクトルを生成します。
スパースベクトルモデルを使用してスパースベクトルを生成します。
OpenSearch Vector Search Edition インスタンスを購入し、インスタンスのスパースベクトルとデンスベクトルベースのインデックステーブルを作成します。
デンスベクトルデータとスパースベクトルデータをインデックステーブルに追加します。
スパースベクトルとデンスベクトルを使用してハイブリッドクエリを実行します。
OpenSearch Vector Search Edition は、クエリ結果を返します。
デンスベクトル
OpenSearch Vector Search Edition の基本ベクトルはデンスベクトルです。セマンティック検索は、デンスベクトルに基づいて提供されます。セマンティック検索は、完全に一致する結果がない場合、計算された距離に基づいて最も類似性の高い結果を返します。従来のテキスト検索を使用する場合、OpenSearch は特定のアナライザーに基づいて検索クエリとドキュメントのテキスト分析を実行し、分析結果を照合し、分析結果が検索クエリの分析結果と完全に一致するドキュメントのみを返します。
テキスト検索機能の制限は、セマンティック検索機能には適用されません。セマンティック検索機能は、検索クエリと意味的に類似したドキュメントを返すことができます。
スパースベクトル
スパースベクトルは、多数の次元を持ちます。少数の次元の値のみがゼロ以外の値です。キーワード検索にスパースベクトルを使用する場合、各スパースベクトルはドキュメントを表し、各次元は辞書の単語を表し、次元の値はドキュメント内の単語の重要度を示します。キーワード検索アルゴリズムは、ドキュメント内の一致するキーワードの数や頻度などの指標に基づいて、ドキュメントの関連性を計算します。
スパースベクトルの表現:
V=[0,0,0,0,2,0,4,0,0,0]
V ベクトルのスパース表現は (10,[4,6],[2,4]) です。
10 はベクトルの要素数を表し、[4,6] はベクトル内のゼロ以外の要素の添え字を表し、[2,4] はベクトル内のゼロ以外の要素の値を表します。
スパースベクトルモデルを使用してテキストのベクトル化を実行できます。次のサンプルコードは、特定のテキストがベクトル化された後に生成されるスパースベクトルを示しています。
{
"indices": [0, 100, 40, 50, 20], // インデックス
"values": [0.5, 0.9, 0.3, 0.7, 0.6] // 値
}OpenSearch Vector Search Edition では、2 つの独立した複数値フィールドを使用して、スパースベクトルの添え字と値を表します。2 つのフィールドの値の数は同じである必要があります。2 つのフィールドの値の位置は 1 対 1 で対応しています。
前の例では、indices はスパースベクトルの配列内のゼロ以外の要素の添え字を表します。
values はスパースベクトルの配列内のゼロ以外の要素の値を表します。
データの書き込みまたはクエリを実行するときは、添え字を昇順に並べ、添え字に基づいて値を調整する必要があります。次のコードは、調整された複数値フィールドを示しています。
{
"indices": [0, 20, 40, 50, 100], // インデックス
"values": [0.5, 0.6, 0.3, 0.7, 0.9] // 値
}クエリウェイト
ハイブリッドクエリでは、同じドキュメントの最終スコアは、デンスベクトルの距離とスパースベクトルの距離の合計です。スパースベクトルとデンスベクトルに異なるウェイトを設定する場合は、次のコードに基づいて設定を実行できます。
{
"vector": [v * weight for v in dense_vector], # dense_vector に weight を乗算
"sparseData": {
"indices": sparse_data["indices"], # sparse_data の indices
"values": [v * (1 - weight) for v in sparse_data["values"]] # sparse_data の values に (1 - weight) を乗算
}
}OpenSearch Vector Search Edition インスタンスを購入する
詳細については、「OpenSearch Vector Search Edition インスタンスを購入する」をご参照ください。
インスタンスを設定する
購入したインスタンスの詳細ページで、インスタンスは [構成保留中] 状態です。システムは、データを含まないインスタンスを自動的にデプロイします。クエリ結果サーチャー(QRS)ワーカーとサーチャーワーカーの数と仕様は、購入したインスタンスと同じです。インスタンスを検索に使用する前に、次の手順を実行します。テーブルの構成、データソースの追加、フィールドの構成、インデックススキーマの構成、そしてインスタンスの再インデックスを実行します。
1. テーブルの基本情報を設定する
インスタンスの詳細ページの左側のペインで、[テーブル管理] をクリックします。[テーブル管理] ページで、[テーブルの追加] をクリックします。作成ウィザードの [基本テーブル情報] ステップで、[テーブル名]、[データシャード]、[データ更新のリソース数]、および [シナリオテンプレート] パラメーターを構成します。このトピックでは、[シナリオテンプレート] パラメーターは [ベクトル: テキストのセマンティック検索] に設定され、[密ベクトルと疎ベクトルによるハイブリッド検索] が選択されています。
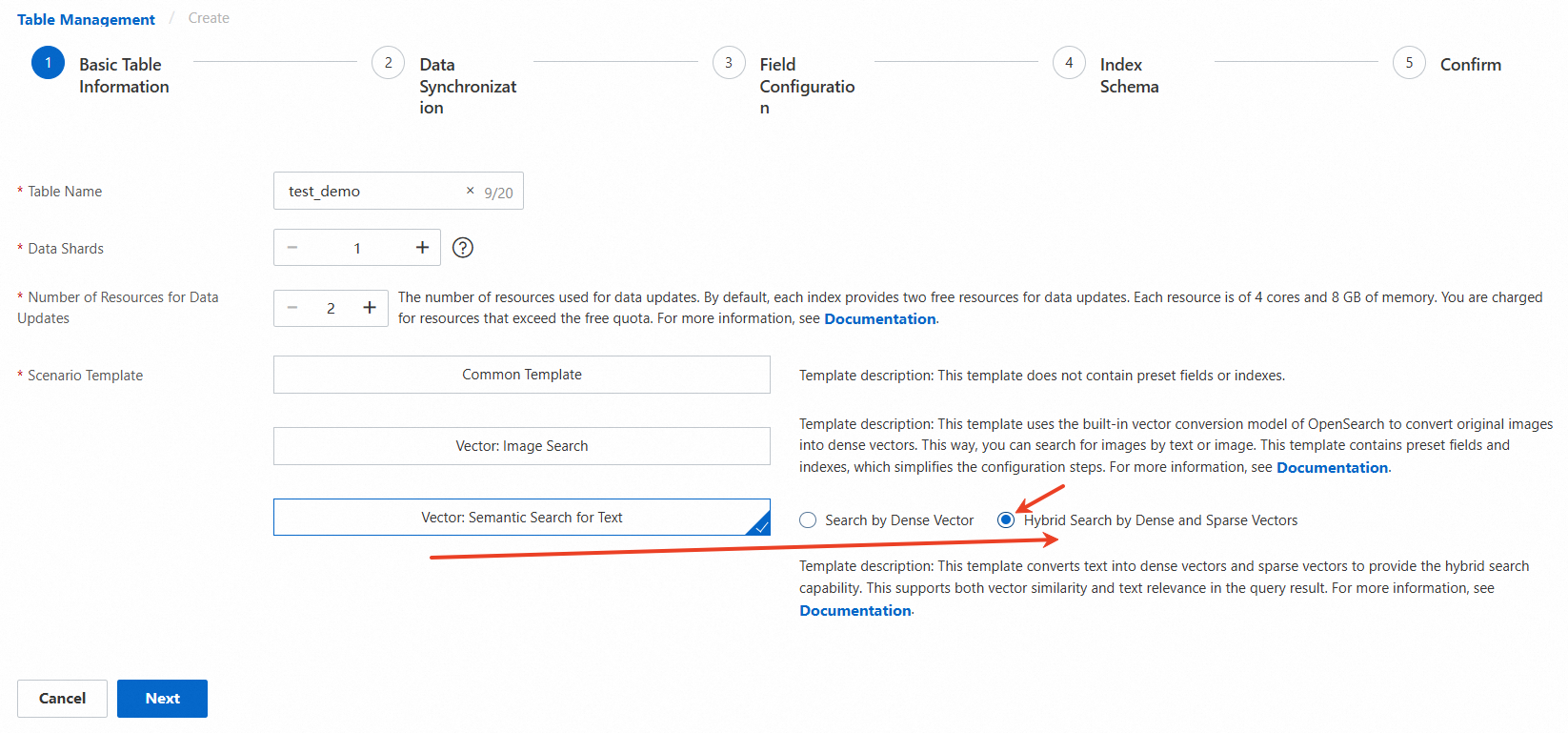
パラメーター:
[テーブル名]: テーブルの名前。カスタムテーブル名を入力できます。
[データシャード]: テーブルに含まれるデータシャードの数。1 ~ 256 の範囲の正の整数を入力します。シャーディングを実行してフルインデックス作成を高速化し、単一クエリのフォーマンスを向上させることができます。既存の OpenSearch インスタンスに複数のインデックステーブルを作成する場合は、インデックステーブルに同じ数のシャードが含まれていることを確認してください。または、少なくとも 1 つのインデックステーブルに 1 つのシャードが含まれており、他のインデックステーブルに同じ数のシャードが含まれていることを確認してください。
[データ更新のリソース数]: データ更新に使用されるリソースの数。デフォルトでは、データソースごとにデータ更新用の 2 つのリソースの無料枠が提供されます。各リソースは、4 つの CPU コアと 8 GB のメモリで構成されています。無料枠を超えるリソースに対しては課金されます。詳細については、「OpenSearchベクトル検索版の課金概要」をご参照ください。
2. データソースを追加する
データ同期ステップで、データソースを追加します。Object Storage Service(OSS)データソース、MaxComputeデータソース、Data Lake Formation(DLF)データソース、またはAPIデータソースを追加できます。この例では、フルデータソースとしてMaxCompute + APIが選択されています。プロジェクト名、AccessKey、AccessKey Secret、テーブル名、パーティション、タイムスタンプ、および自動再インデックス化パラメーターを構成します。次に、[確認]をクリックして、データソース情報を確認します。確認に合格したら、[次へ] をクリックします。
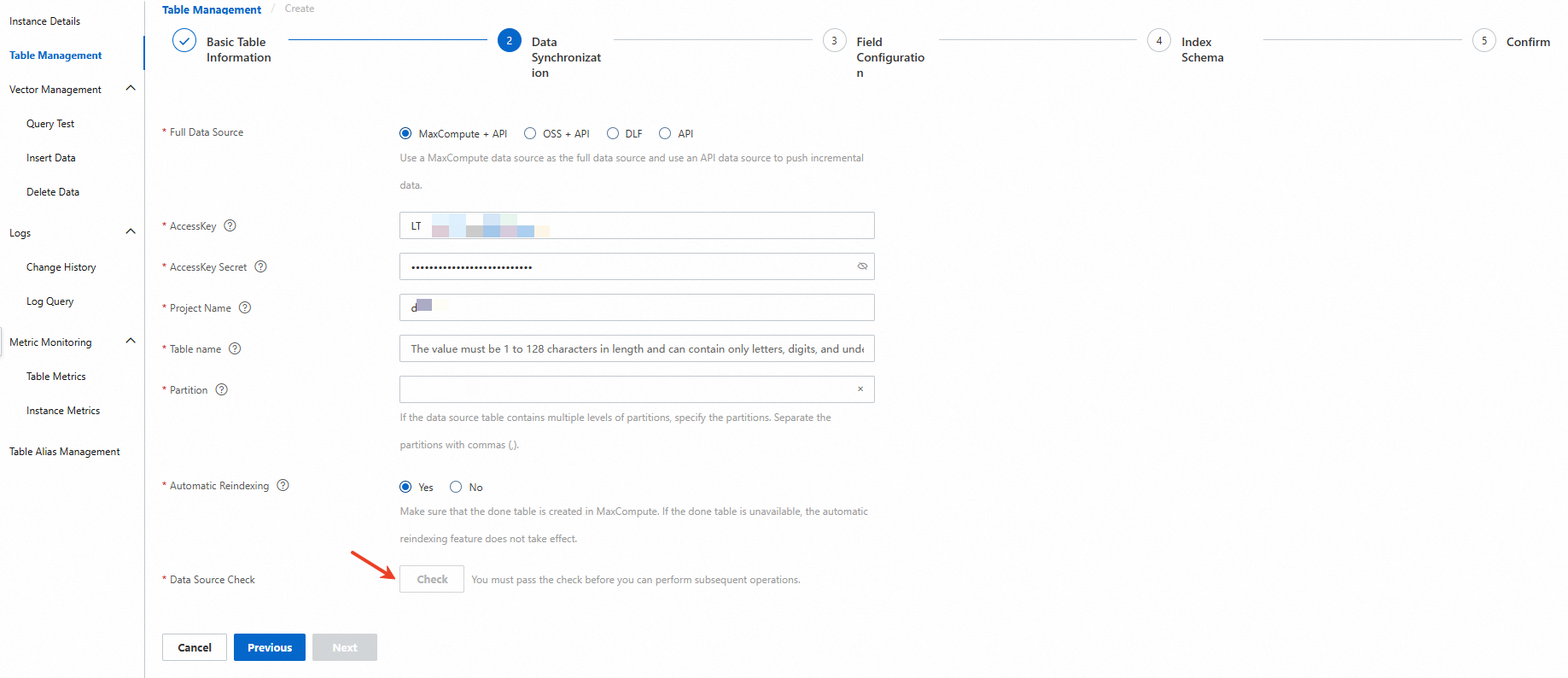
MaxCompute データソースの詳細については、「MaxCompute データソースのテーブルを作成する」をご参照ください。
API データソースの詳細については、「API データソースのテーブルを作成する」をご参照ください。
OSS データソースの詳細については、「OSS データソースのテーブルを作成する」をご参照ください。
DLF データソースの詳細については、「DLF データソースのテーブルを作成する」をご参照ください。
3. フィールドを設定する
[フィールド設定] ステップで、フィールドを設定します。[テーブルの基本情報] ステップで [デンスベクトルとスパースベクトルによるハイブリッド検索] を選択した場合は、id を主キーフィールド、vector をデンスベクトルフィールド、sparse_values をスパースベクトル値フィールド、sparse_indices をスパースベクトル添え字フィールドとして定義する必要があります。
次の情報に注意してください:
主キーフィールドとベクトルフィールドは必須です。主キーフィールドの場合は、[タイプ] パラメーターを [INT] または [STRING] に設定し、[主キー] 列を選択する必要があります。ベクトルフィールドの場合は、[タイプ] パラメーターを [FLOAT] に設定し、[ベクトルフィールド] 列を選択する必要があります。
ベクトルフィールドは必須です。ベクトルフィールドには複数のベクトルを指定できます。[FLOAT] タイプの複数値フィールドとしてベクトルフィールドを定義する必要があります。
スパースベクトル添え字フィールドとスパースベクトル値フィールドをペアで設定する必要があります。スパースベクトル添え字フィールドは [INT32] タイプの複数値フィールドとして定義され、スパースベクトル値フィールドは [FLOAT] タイプの複数値フィールドとして定義されます。
ベクトルインデックスを設定する場合は、主キーフィールド、名前空間フィールド、ベクトルフィールドの順にフィールドを指定する必要があります。名前空間フィールドはオプションです。前の図は例を示しています。
4. インデックススキーマを設定する
[インデックススキーマ] ステップで、インデックススキーマを設定します。[ハイブリッド検索] パラメーターを [有効] に設定し、[含まれるフィールド] パラメーターで主キー、ベクトル、スパースベクトル添え字、スパースベクトル値フィールドを設定する必要があります。
パラメーター:
[インデックス名]: このパラメーターは必須です。カスタムインデックス名を入力できます。
[ハイブリッド検索]: 値を [有効] に設定します。
[ハイブリッド検索] を有効にした後、スパースベクトル添え字フィールドとスパースベクトル値フィールドを設定します。
[ベクトル次元]: デンスベクトルの次元。
デフォルトでは、[ハイブリッド検索] を有効にした後、[距離タイプ] パラメーターは [InnerProduct] に設定され、[ベクトルインデックスアルゴリズム] パラメーターは [HNSW] に設定されます。これらのパラメーターは変更できません。
ベクトルインデックスの詳細設定のパラメーターは個別に設定する必要があります。詳細については、「ベクトルインデックスの共通設定」をご参照ください。
このトピックで提供されているテストデータを使用する場合は、[ベクトル次元] パラメーターを 1536 に設定します。
5. 作成を確認する
[確認] ステップで、[確認] をクリックします。
6. 変更履歴を表示する
インスタンスの詳細ページの左側のペインで、[変更履歴] をクリックします。表示されるページで、テーブルの作成、インデックスの作成、フルデータの再インデックスの実行のプロセスに関連するすべての有限状態マシン (FSM) を表示できます。検索エンジンが構築された後、インスタンスでクエリテストを実行できます。
7. クエリテストを実行する
{
"tableName": "dense_sparse_tb", // テーブル名
"indexName": "vector", // インデックス名
"vector": [
0.1,
0.2,
0.3,
0.4,
0.5
], // ベクトル
"sparseData": { // スパースデータ
"indices": [ // インデックス
0,
2
],
"values": [ // 値
1.2,
2.4
]
},
"topK": 2, // topK
"order": "DESC" // 順序
}tableName: テーブルの名前。
indexName: インデックスの名前。この例では、indexName パラメーターは vector に設定されています。
vector: クエリ対象のデンスベクトル。
sparseData: クエリ対象のスパースベクトル。
indices: スパースベクトルの要素の添え字。
values: スパースベクトルの要素の値。
topK: 返される上位 K 件の結果。
order: 結果のソート順。DESC の値は、結果が降順でソートされることを指定します。
構文
詳細については、「ハイブリッドクエリ」をご参照ください。