このトピックでは、Java および Python 用の OpenSearch Vector Search Edition SDK を使用してテーブルデータを更新する方法について説明します。ドキュメントのアップロード、更新、および削除を実行できます。
依存関係
Java
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-sdk-ha3engine-vector</artifactId>
<version>1.1.8</version>
</dependency>Python
# Requires: Python >=3.6
pip install alibabacloud_ha3engine_vectorGo
go get github.com/aliyun/alibabacloud-ha3-go-sdk@v1.1.8-vector非同期モードの Java
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-sdk-ha3engine-async</artifactId>
<version>1.1.4</version>
</dependency>パラメーターの説明
Java および Python 用の SDK では、endpoint、instance_id、access_user_name、access_pass_word、および data_source_name の各パラメーターを指定する必要があります。,
endpoint: 内部エンドポイントまたはパブリックエンドポイント。
[インスタンスの詳細] ページの [ネットワーク情報] セクションと [API エンドポイント] セクションでエンドポイントを確認できます。
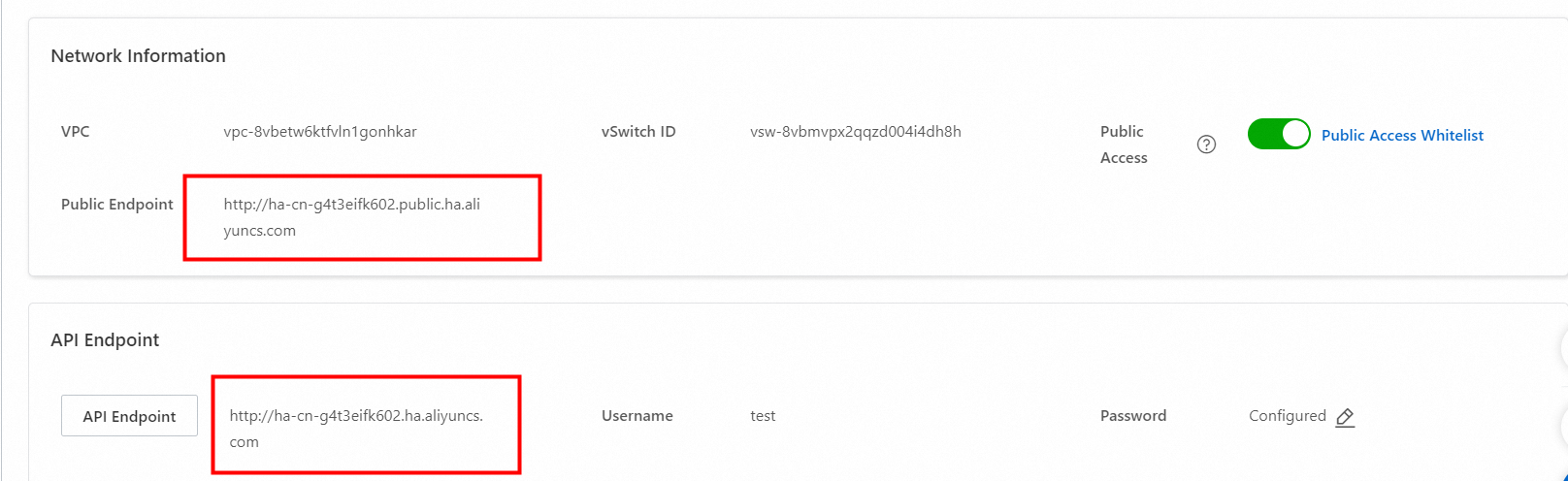
[パブリックアクセス] をオンにすると、オンプレミス マシンでインスタンスの パブリック エンドポイント「ネットワーク情報」セクション を使用して OpenSearch Vector Search Edition インスタンスにアクセスできます。パブリックエンドポイントには「public」という語が含まれています。インスタンスへのアクセス用に IP アドレスのホワイトリストを設定できます。詳細については、「インスタンスの詳細の表示」トピックの をご参照ください。このような IP アドレスのホワイトリストを設定しないと、アクセス禁止エラーが返されます。インスタンスを使用する前に、インスタンスに ping を実行してアクセス可能であることを確認することをお勧めします。
Elastic Compute Service (ECS) インスタンスを使用して OpenSearch Vector Search Edition インスタンスにアクセスする場合、API エンドポイントを使用して OpenSearch Vector Search Edition インスタンスにアクセスするために ECS インスタンスと同じ vSwitch を指定できます。
instance_id: OpenSearch Vector Search Edition インスタンスの ID。
access_user_name: ユーザー名。
access_pass_word: パスワード。
[インスタンスの詳細] ページの [API エンドポイント] セクションでユーザー名とパスワードを確認できます。パスワードはインスタンスの購入時に指定され、変更できます。

data_source_name: API データソースの名前。デフォルト値は、[インスタンス ID]_ [テーブル名] の形式です。
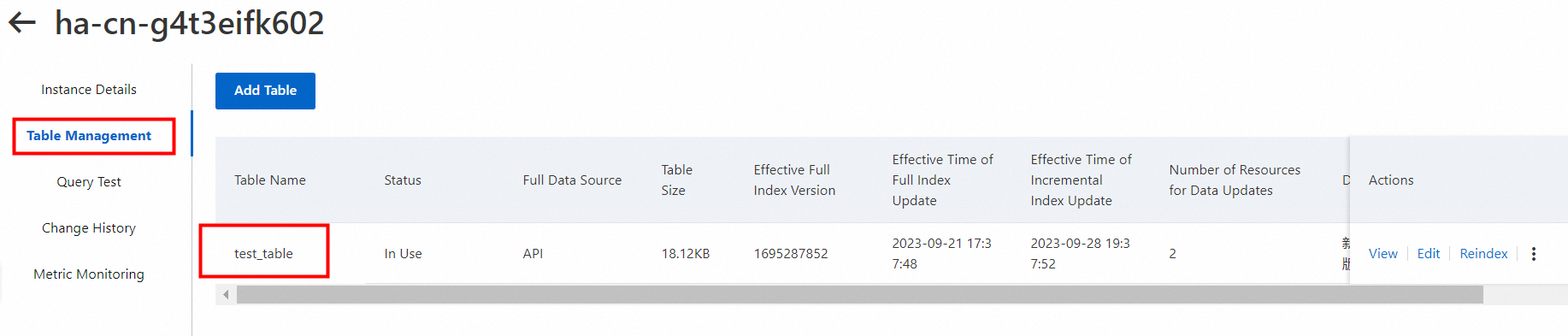
例: ha-cn-zpr3dgzxg04_test_image_vector。
データ更新のデモ
ドキュメントのアップロード
Java
import com.aliyun.ha3engine.vector.Client;
import com.aliyun.ha3engine.vector.models.Config;
import com.aliyun.ha3engine.vector.models.PushDocumentsRequest;
import com.aliyun.ha3engine.vector.models.PushDocumentsResponse;
import com.aliyun.tea.TeaException;
import org.junit.Before;
import org.junit.Test;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
/**
* @author alibaba
*/
public class PushDoc {
/**
* OpenSearch Vector Search Edition インスタンスのエンジン クライアント。
*/
private Client client;
@Before
public void clientInit() throws Exception {
/*
エンジン クライアントを初期化します。
*/
Config config = new Config();
// インスタンスの名前。[インスタンスの詳細] ページの左上隅にインスタンス名が表示されます。例: ha-cn-i7*****605。
config.setInstanceId("ha-cn-i7*****605");
// ユーザー名。[インスタンスの詳細] ページの [API エンドポイント] セクションにユーザー名が表示されます。
config.setAccessUserName("username");
// パスワード。[インスタンスの詳細] ページの [API エンドポイント] セクションでパスワードを変更できます。
config.setAccessPassWord("password");
// インスタンスの API エンドポイント。[インスタンスの詳細] ページの [API エンドポイント] セクションに API エンドポイントが表示されます。
config.setEndpoint("ha-cn-i7*****605.public.ha.aliyuncs.com");
client = new Client(config);
}
@Test
public void add() throws Exception {
// ドキュメントのプッシュ先のテーブルの名前。形式: <インスタンス ID>_<テーブル名>。
String tableName = "<instance_id>_<table_name>";
// データをプッシュするドキュメントのプライマリキー フィールド。
String pkField = "<field_pk>";
try {
// ドキュメントをプッシュするために使用される外部構造。この構造には、1 つ以上のドキュメント操作を指定できます。
ArrayList<Map<String, ?>> documents = new ArrayList<>();
// アップロードするドキュメント。
Map<String, Object> add2Document = new HashMap<>();
Map<String, Object> add2DocumentFields = new HashMap<>();
// ドキュメントの内容。キーと値はペアで一致する必要があります。
// field_pk フィールドの値は、pkField フィールドの値と同じである必要があります。
add2DocumentFields.put("<field_pk>", "<field_pk_value>");
add2DocumentFields.put("<field_map_key_1>", "<field_map_value_1>");
add2DocumentFields.put("<field_map_key_2>", "<field_map_value_2>");
// コンテンツは、OpenSearch Vector Search Edition でサポートされている複数値属性タイプにすることができます。インデックステーブルを設定するときに、multi_value パラメーターを true に設定します。
ArrayList<Object> addDocumentMultiFields = new ArrayList<>();
addDocumentMultiFields.add("multi_value_1");
addDocumentMultiFields.add("multi_value_2");
add2DocumentFields.put("<multi_value_key>", addDocumentMultiFields);
// add2Document 構造にドキュメントの内容を追加します。
add2Document.put("fields", add2DocumentFields);
// add コマンドを実行してドキュメントをアップロードします。
add2Document.put("cmd", "add");
documents.add(add2Document);
// データをプッシュします。
PushDocumentsRequest request = new PushDocumentsRequest();
request.setBody(documents);
PushDocumentsResponse response = client.pushDocuments(tableName, pkField, request);
String responseBody = response.getBody();
System.out.println("result:" + responseBody);
} catch (TeaException e) {
System.out.println(e.getCode());
System.out.println(e.getMessage());
Map<String, Object> exceptionData = e.getData();
System.out.println(com.aliyun.teautil.Common.toJSONString(exceptionData));
}
}
}Python
from alibabacloud_ha3engine_vector.client import Client
from alibabacloud_ha3engine_vector.models import Config
from alibabacloud_ha3engine_vector import models
from Tea.exceptions import TeaException, RetryError
config = Config(
# インスタンスの API エンドポイント。[インスタンスの詳細] ページの [API エンドポイント] セクションに API エンドポイントが表示されます。
endpoint="http://ha-cn-i7*****605.public.ha.aliyuncs.com",
# ユーザー名。[インスタンスの詳細] ページの [API エンドポイント] セクションにユーザー名が表示されます。
access_user_name="username",
# パスワード。[インスタンスの詳細] ページの [API エンドポイント] セクションでパスワードを変更できます。
access_pass_word="password")
# エンジン クライアントを初期化します。
client = Client(config)
def push():
# ドキュメントのプッシュ先のテーブルの名前。形式: <インスタンス ID>_<テーブル名>。
tableName = "<instance_id>_<table_name>";
try:
# アップロードするドキュメント。
# ドキュメントが既に存在する場合は、既存のドキュメントが削除され、指定されたドキュメントがアップロードされます。
# =====================================================
# ドキュメントの内容。
add2DocumentFields = {
"id": 1, # プライマリキー フィールドの ID。値は INT タイプです。
"name": "Search", # この単一値フィールドの値は STRING タイプです。
"str_arr": "a\x1Db\x1Dc\x1Dd" # この複数値フィールドの値は STRING タイプです。
}
# add2Document 構造にドキュメントの内容を追加します。
add2Document = {
"fields": add2DocumentFields,
"cmd": "add" # add コマンドを実行してドキュメントをアップロードします。
}
optionsHeaders = {}
# ドキュメントをプッシュするために使用される外部構造。この構造には、1 つ以上のドキュメント操作を指定できます。
documentArrayList = []
documentArrayList.append(add2Document)
pushDocumentsRequest = models.PushDocumentsRequest(optionsHeaders, documentArrayList)
# データをプッシュするドキュメントのプライマリキー フィールド。
pkField = "id"
# リクエストにデフォルトのランタイム パラメーターを使用します。
response = client.push_documents(tableName, pkField, pushDocumentsRequest)
print(response.body)
except TeaException as e:
print(f"send request with TeaException : {e}")
except RetryError as e:
print(f"send request with Connection Exception : {e}")
if __name__ == "__main__":
push()Go
このデモでは、ドキュメント データを Map オブジェクトに動的にカプセル化し、add() メソッドを呼び出してこれらの Map オブジェクトをキャッシュに追加します。次に、pushDocuments() メソッドを呼び出して、これらの Map オブジェクト内のドキュメント データを一度に送信します。
package main
import (
"fmt"
"github.com/alibabacloud-go/tea/tea"
ha3engine "github.com/aliyun/alibabacloud-ha3-go-sdk/client"
)
func main() {
// Config インスタンスを作成します。
config := &ha3engine.Config{
// インスタンスの API エンドポイント。[インスタンスの詳細] ページの [API エンドポイント] セクションに API エンドポイントが表示されます。
Endpoint: tea.String("ha-cn-i7*****605.public.ha.aliyuncs.com"),
// ユーザー名。[インスタンスの詳細] ページの [API エンドポイント] セクションにユーザー名が表示されます。
AccessUserName: tea.String("username"),
// パスワード。[インスタンスの詳細] ページの [API エンドポイント] セクションでパスワードを変更できます。
AccessPassWord: tea.String("password"),
}
// リクエストを送信するためのクライアントを初期化します。
client, _clientErr := ha3engine.NewClient(config)
// システムがクライアントの作成時にエラーが発生した場合、_clientErr とエラー メッセージが返されます。
if _clientErr != nil {
fmt.Println(_clientErr)
return
}
docPush(client)
}
func docPush(client *ha3engine.Client) {
pushDocumentsRequestModel := &ha3engine.PushDocumentsRequest{}
// ドキュメントのプッシュ先のテーブルの名前。形式: <インスタンス ID>_<テーブル名>。
tableName := "<instance_id>_<table_name>"
// データをプッシュするドキュメントのプライマリキー フィールド。
keyField := "<field_pk>"
a := [20]int{}
array := []map[string]interface{}{}
for x := range a {
filed := map[string]interface{}{
"fields": map[string]interface{}{
"id": tea.ToString(x),
"fb_boolean": tea.BoolValue(nil),
"fb_datetime": "2167747200000",
"fb_string": "409a6b18-a10b-409e-af91-07121c45d899",
},
"cmd": tea.String("add"),
}
array = append(array, filed)
pushDocumentsRequestModel.SetBody(array)
// リクエストを送信するためのメソッドを呼び出します。
response, _requestErr := client.PushDocuments(tea.String(dataSourceName), tea.String(keyField), pushDocumentsRequestModel)
// システムがリクエストの送信時にエラーが発生した場合、_requestErr とエラー メッセージが返されます。
if _requestErr != nil {
fmt.Println(_requestErr)
return
}
// エラーが発生しない場合は、レスポンスを表示します。
fmt.Println(response)
}
}非同期モードの Java
このデモでは、ドキュメント データを Map オブジェクトに動的にカプセル化し、add() メソッドを呼び出してこれらの Map オブジェクトをキャッシュに追加します。次に、pushDocuments() メソッドを呼び出して、これらの Map オブジェクト内のドキュメント データを一度に送信します。
import com.aliyun.ha3engine.async.AsyncClient;
import com.aliyun.ha3engine.async.models.PushDocumentsRequest;
import com.aliyun.ha3engine.async.models.PushDocumentsResponse;
import com.aliyun.sdk.ha3engine.async.core.AsyncConfigInfoProvider;
import com.aliyun.tea.TeaException;
import darabonba.core.client.ClientOverrideConfiguration;
import org.junit.Before;
import org.junit.Test;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
/**
* @author alibaba
*/
public class AddDoc {
/**
* OpenSearch Vector Search Edition インスタンスのエンジン クライアント。
*/
private AsyncClient client;
@Before
public void clientInit() {
// インスタンスへのアクセスに使用するユーザー名とパスワード。[インスタンスの詳細] ページの [API エンドポイント] セクションにユーザー名とパスワードが表示されます。
AsyncConfigInfoProvider provider = AsyncConfigInfoProvider.create("username", "password");
// 非同期クライアントを初期化します。
client = AsyncClient.builder()
.credentialsProvider(provider)
.overrideConfiguration(
ClientOverrideConfiguration.create()
.setEndpointOverride("ha-cn-i7*****605.public.ha.aliyuncs.com")
.setProtocol("http")
).build();
}
@Test
public void add() {
try {
// ドキュメントのプッシュ先のテーブルの名前。形式: <インスタンス ID>_<テーブル名>。
String tableName = "<instance_id>_<table_name>";
// データをプッシュするドキュメントのプライマリキー フィールド。
String pkField = "<field_pk>";
// ドキュメントをプッシュするために使用される外部構造。この構造には、1 つ以上のドキュメント操作を指定できます。
ArrayList<Map<String, ?>> documents = new ArrayList<>();
// アップロードするドキュメント。
Map<String, Object> add2Document = new HashMap<>();
Map<String, Object> add2DocumentFields = new HashMap<>();
// ドキュメントの内容。キーと値はペアで一致する必要があります。
// field_pk フィールドの値は、pkField フィールドの値と同じである必要があります。
add2DocumentFields.put("<field_pk>", "<field_pk_value>");
add2DocumentFields.put("<field_map_key_1>", "<field_map_value_1>");
add2DocumentFields.put("<field_map_key_2>", "<field_map_value_2>");
// コンテンツは、OpenSearch Vector Search Edition でサポートされている複数値属性タイプにすることができます。インデックステーブルを設定するときに、multi_value パラメーターを true に設定します。
ArrayList<Object> addDocumentMultiFields = new ArrayList<>();
addDocumentMultiFields.add("multi_value_1");
addDocumentMultiFields.add("multi_value_2");
add2DocumentFields.put("<multi_value_key>", addDocumentMultiFields);
// add2Document 構造にドキュメントの内容を追加します。
add2Document.put("fields", add2DocumentFields);
// add コマンドを実行してドキュメントをアップロードします。
add2Document.put("cmd", "add");
documents.add(add2Document);
// データをプッシュします。
PushDocumentsRequest request = PushDocumentsRequest.builder().body(documents).build();
CompletableFuture<PushDocumentsResponse> responseCompletableFuture = client.pushDocuments(tableName, pkField, request);
String responseBody = responseCompletableFuture.get().getBody();
System.out.println("result:" + responseBody);
} catch (ExecutionException | InterruptedException e) {
System.out.println(e.getMessage());
} catch (TeaException e) {
System.out.println(e.getCode());
System.out.println(e.getMessage());
Map<String, Object> abc = e.getData();
System.out.println(com.aliyun.teautil.Common.toJSONString(abc));
}
}
}add() メソッドを呼び出してデータをプッシュすると、古いデータと同じプライマリキーを使用する新しいデータによって古いデータが上書きされます。
ドキュメントの削除
Java
import com.aliyun.ha3engine.vector.Client;
import com.aliyun.ha3engine.vector.models.*;
import com.aliyun.tea.TeaException;
import org.junit.Before;
import org.junit.Test;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
/**
* @author alibaba
*/
public class PushDoc {
/**
* OpenSearch Vector Search Edition インスタンスのエンジン クライアント。
*/
private Client client;
@Before
public void clientInit() throws Exception {
/*
エンジン クライアントを初期化します。
*/
Config config = new Config();
// インスタンスの名前。[インスタンスの詳細] ページの左上隅にインスタンス名が表示されます。例: ha-cn-i7*****605。
config.setInstanceId("ha-cn-i7*****605");
// ユーザー名。[インスタンスの詳細] ページの [API エンドポイント] セクションにユーザー名が表示されます。
config.setAccessUserName("username");
// パスワード。[インスタンスの詳細] ページの [API エンドポイント] セクションでパスワードを変更できます。
config.setAccessPassWord("password");
// インスタンスの API エンドポイント。[インスタンスの詳細] ページの [API エンドポイント] セクションに API エンドポイントが表示されます。
config.setEndpoint("ha-cn-i7*****605.public.ha.aliyuncs.com");
client = new Client(config);
}
@Test
public void delete() throws Exception {
// ドキュメントのプッシュ先のテーブルの名前。形式: <インスタンス ID>_<テーブル名>。
String tableName = "<instance_id>_<table_name>";
// データをプッシュするドキュメントのプライマリキー フィールド。
String pkField = "<field_pk>";
try {
// ドキュメントをプッシュするために使用される外部構造。この構造には、1 つ以上のドキュメント操作を指定できます。
ArrayList<Map<String, ?>> documents = new ArrayList<>();
// 削除するドキュメント。
Map<String, Object> delete2Document = new HashMap<>();
Map<String, Object> delete2DocumentFields = new HashMap<>();
// ドキュメントの内容。キーと値はペアで一致する必要があります。
// field_pk フィールドの値は、pkField フィールドの値と同じである必要があります。
delete2DocumentFields.put("<field_pk>", "<field_pk_value>");
// delete2Document 構造にドキュメントの内容を追加します。
delete2Document.put("fields", delete2DocumentFields);
// delete コマンドを実行してドキュメントを削除します。
delete2Document.put("cmd", "delete");
documents.add(delete2Document);
// データをプッシュします。
PushDocumentsRequest request = new PushDocumentsRequest();
request.setBody(documents);
PushDocumentsResponse response = client.pushDocuments(tableName, pkField, request);
String responseBody = response.getBody();
System.out.println("result:" + responseBody);
} catch (TeaException e) {
System.out.println(e.getCode());
System.out.println(e.getMessage());
Map<String, Object> exceptionData = e.getData();
System.out.println(com.aliyun.teautil.Common.toJSONString(exceptionData));
}
}
}Python
from alibabacloud_ha3engine_vector.client import Client
from alibabacloud_ha3engine_vector.models import Config
from alibabacloud_ha3engine_vector import models
from Tea.exceptions import TeaException, RetryError
config = Config(
# インスタンスの API エンドポイント。[インスタンスの詳細] ページの [API エンドポイント] セクションに API エンドポイントが表示されます。
endpoint="http://ha-cn-i7*****605.public.ha.aliyuncs.com",
# ユーザー名。[インスタンスの詳細] ページの [API エンドポイント] セクションにユーザー名が表示されます。
access_user_name="username",
# パスワード。[インスタンスの詳細] ページの [API エンドポイント] セクションでパスワードを変更できます。
access_pass_word="password")
# エンジン クライアントを初期化します。
ha3EngineClient = Client(Config)
def pushDoc():
# ドキュメントのプッシュ先のテーブルの名前。形式: <インスタンス ID>_<テーブル名>。
tableName = "<instance_id>_<table_name>";
try:
# ドキュメントをプッシュするために使用される外部構造。この構造には、1 つ以上のドキュメント操作を指定できます。
documentArrayList = []
# 削除するドキュメント。
# ドキュメントを削除するには、ドキュメントのプライマリキー フィールドを指定する必要があります。
# 多レベル ハッシュ構造を使用してインデックスを作成する場合は、各レベルのハッシュのプライマリキー フィールドを指定する必要があります。
delete2DocumentFields = {
"id": 1 # プライマリキー フィールドの ID。値は INT タイプです。
}
delete2Document = {
"fields": delete2DocumentFields, # delete2Document 構造にドキュメントの内容を追加します。
"cmd": "delete" # delete コマンドを実行してドキュメントを削除します。
}
optionsHeaders = {}
documentArrayList.append(delete2Document)
pushDocumentsRequest = models.PushDocumentsRequest(
optionsHeaders, documentArrayList
)
# データをプッシュするドキュメントのプライマリキー フィールド。
pkField = "id"
# リクエストにデフォルトのランタイム パラメーターを使用します。
response = ha3EngineClient.push_documents(
tableName, pkField, pushDocumentsRequest
)
print(response)
except TeaException as e:
print(f"send request with TeaException : {e}")
except RetryError as e:
print(f"send request with Connection Exception : {e}")
if __name__ == "__main__":
pushDoc()Go
package main
import (
"fmt"
"github.com/alibabacloud-go/tea/tea"
ha3engine "github.com/aliyun/alibabacloud-ha3-go-sdk/client"
)
func main() {
// Config インスタンスを作成します。
config := &ha3engine.Config{
// インスタンスの API エンドポイント。[インスタンスの詳細] ページの [API エンドポイント] セクションに API エンドポイントが表示されます。
Endpoint: tea.String("ha-cn-i7*****605.public.ha.aliyuncs.com"),
// ユーザー名。[インスタンスの詳細] ページの [API エンドポイント] セクションにユーザー名が表示されます。
AccessUserName: tea.String("username"),
// パスワード。[インスタンスの詳細] ページの [API エンドポイント] セクションでパスワードを変更できます。
AccessPassWord: tea.String("password"),
}
// リクエストを送信するためのクライアントを初期化します。
client, _clientErr := ha3engine.NewClient(config)
// システムがクライアントの作成時にエラーが発生した場合、_clientErr とエラー メッセージが返されます。
if _clientErr != nil {
fmt.Println(_clientErr)
return
}
deleteDoc(client)
}
func deleteDoc(client *ha3engine.Client) {
pushDocumentsRequestModel := &ha3engine.PushDocumentsRequest{}
// ドキュメントのプッシュ先のテーブルの名前。形式: <インスタンス ID>_<テーブル名>。
tableName := "<instance_id>_<table_name>"
// データをプッシュするドキュメントのプライマリキー フィールド。
keyField := "<field_pk>"
var array []map[string]interface{}
filed := map[string]interface{}{
"fields": map[string]interface{}{
"id": 2,
},
"cmd": tea.String("delete"),
}
array = append(array, filed)
pushDocumentsRequestModel.SetBody(array)
// リクエストを送信するためのメソッドを呼び出します。
response, _requestErr := client.PushDocuments(tea.String(tableName), tea.String(keyField), pushDocumentsRequestModel)
// システムがリクエストの送信時にエラーが発生した場合、_requestErr とエラー メッセージが返されます。
if _requestErr != nil {
fmt.Println(_requestErr)
return
}
// エラーが発生しない場合は、レスポンスを表示します。
fmt.Println(response)
}非同期モードの Java
import com.aliyun.ha3engine.async.AsyncClient;
import com.aliyun.ha3engine.async.models.PushDocumentsRequest;
import com.aliyun.ha3engine.async.models.PushDocumentsResponse;
import com.aliyun.sdk.ha3engine.async.core.AsyncConfigInfoProvider;
import com.aliyun.tea.TeaException;
import darabonba.core.client.ClientOverrideConfiguration;
import org.junit.Before;
import org.junit.Test;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
/**
* @author alibaba
*/
public class DeleteDoc {
/**
* OpenSearch Vector Search Edition インスタンスのエンジン クライアント。
*/
private AsyncClient client;
@Before
public void clientInit() {
// インスタンスへのアクセスに使用するユーザー名とパスワード。[インスタンスの詳細] ページの [API エンドポイント] セクションにユーザー名とパスワードが表示されます。
AsyncConfigInfoProvider provider = AsyncConfigInfoProvider.create("username", "password");
// 非同期クライアントを初期化します。
client = AsyncClient.builder()
.credentialsProvider(provider)
.overrideConfiguration(
ClientOverrideConfiguration.create()
.setEndpointOverride("ha-cn-i7*****605.public.ha.aliyuncs.com")
.setProtocol("http")
).build();
}
@Test
public void delete() throws Exception {
try {
// ドキュメントのプッシュ先のテーブルの名前。形式: <インスタンス ID>_<テーブル名>。
String tableName = "<instance_id>_<table_name>";
// データをプッシュするドキュメントのプライマリキー フィールド。
String pkField = "<field_pk>";
// ドキュメントをプッシュするために使用される外部構造。この構造には、1 つ以上のドキュメント操作を指定できます。
ArrayList<Map<String, ?>> documents = new ArrayList<>();
// 削除するドキュメント。
Map<String, Object> deleteDocument = new HashMap<>();
Map<String, Object> deleteDocumentFields = new HashMap<>();
// ドキュメントの内容。キーと値はペアで一致する必要があります。
// field_pk フィールドの値は、pkField フィールドの値と同じである必要があります。
deleteDocumentFields.put("<field_pk>", "<field_pk_value>");
// deleteDocument 構造にドキュメントの内容を追加します。
deleteDocument.put("fields", deleteDocumentFields);
// delete コマンドを実行してドキュメントを削除します。
deleteDocument.put("cmd", "delete");
documents.add(deleteDocument);
// データをプッシュします。
PushDocumentsRequest request = PushDocumentsRequest.builder().body(documents).build();
CompletableFuture<PushDocumentsResponse> responseCompletableFuture = client.pushDocuments(tableName, pkField, request);
String responseBody = responseCompletableFuture.get().getBody();
System.out.println("result:" + responseBody);
} catch (ExecutionException | InterruptedException e) {
System.out.println(e.getMessage());
} catch (TeaException e) {
System.out.println(e.getCode());
System.out.println(e.getMessage());
Map<String, Object> exceptionData = e.getData();
System.out.println(com.aliyun.teautil.Common.toJSONString(exceptionData));
}
}
}追加情報
リクエストへのレスポンスについては、データの更新をご参照ください。
go get github.com/aliyun/alibabacloud-ha3-go-sdkコマンドを実行して依存関係をプルしないでください。OpenSearch Vector Search Edition と OpenSearch Retrieval Engine Edition の SDK 依存関係は、GitHub の同じタグに分類されます。依存関係をプルするときは、インスタンスのエディションに基づいて対応するエディションを指定する必要があります。