このトピックでは、MaxComputeデータソースのテーブルを作成する方法について説明します。
前提条件
MaxComputeについて理解していること。MaxComputeの詳細については、MaxComputeとは を参照してください。
OpenSearch Vector Search Editionコンソールへのログオンに使用するアカウントには、構成するMaxComputeテーブルに対する次の権限が付与されていること。テーブルに対するDESCRIBE、SELECT、およびDOWNLOAD権限、テーブルのフィールドに対するLABEL権限。
次のステートメントを実行して、必要な権限をアカウントに付与できます。
-- アカウントを追加します。
add user ****@aliyun.com;
-- 必要な権限をアカウントに付与します。
GRANT describe,select,download ON TABLE table_xxx TO USER ****@aliyun.com
GRANT describe,select,download ON TABLE table_xxx_done TO USER ****@aliyun.com
-- MaxComputeテーブルのフィールド権限検証を有効にすると、データのプル時に権限の高いフィールドへのアクセスがシステムによって禁止され、テーブルのインデックスを作成できません。この場合、すべてのフィールドにアクセスするための権限をアカウントに付与する必要があります。
-- プロジェクト全体に対する権限を付与します。
SET LABEL 3 to USER ****@aliyun.com
-- 単一のテーブルに対する権限を付与します。
GRANT LABEL 3 ON TABLE table_xxx(col1, col2) TO ****@aliyun.comMaxComputeテーブルに含まれるフィールドは、STRING、BOOLEAN、DOUBLE、BIGINT、およびDATETIMEのデータ型であること。
テーブル作成ステートメントとMaxComputeデータソースを追加するためのパラメータの詳細については、MaxComputeデータソースにテーブルを作成するためのCREATE TABLEステートメント を参照してください。
テーブルの作成
OpenSearch Vector Search Editionコンソールにログオンします。左側のナビゲーションペインで、[インスタンス] をクリックします。[インスタンス] ページで、テーブルを作成するインスタンスを見つけ、インスタンス名またはIDをクリックします。インスタンスの詳細ページで、左側のペインのテーブル管理をクリックします。表示されるページで、テーブルの追加をクリックします。

作成ウィザードの[基本テーブル情報] ステップで、次のパラメータを構成し、次へをクリックします。
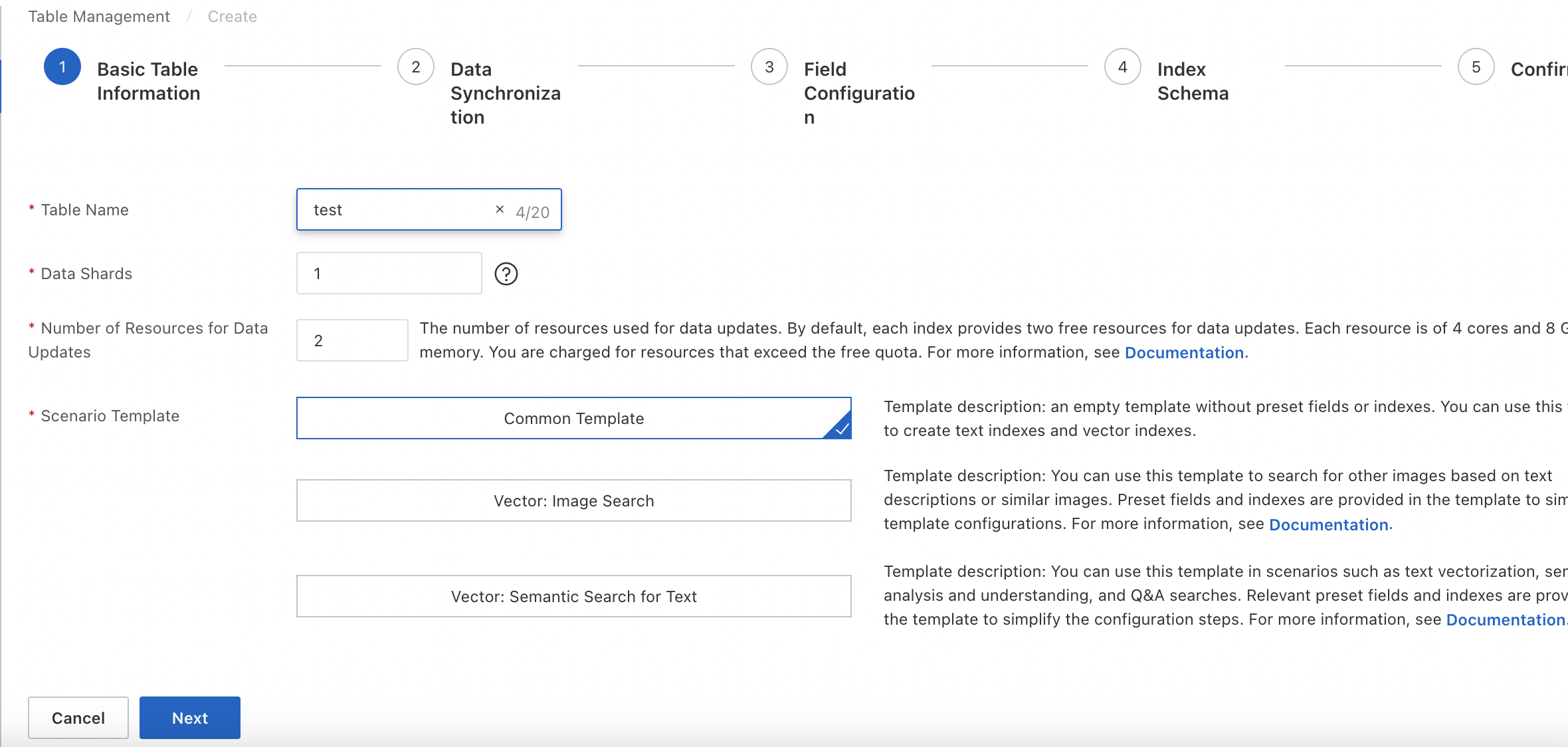
パラメータ:
テーブル名: テーブルの名前。テーブル名はカスタマイズできます。
データシャード: テーブルに含まれるデータシャードの数。OpenSearchインスタンスに複数のインデックステーブルを作成する場合は、インデックステーブルに同じ数のシャードが含まれていることを確認してください。または、少なくとも1つのインデックステーブルに1つのシャードが含まれており、他のインデックステーブルに同じ数のシャードが含まれていることを確認してください。
データ更新のリソース数: データ更新に使用されるリソースの数。デフォルトでは、OpenSearchはOpenSearch Vector Search Editionインスタンスの各データソースに対して、データ更新用に2つのリソースの無料クォータを提供します。各リソースは4つのCPUコアと8GBのメモリで構成されています。無料クォータを超えるリソースについては課金されます。詳細については、 を参照してください。
シナリオテンプレート: テーブルの作成に使用されるテンプレート。有効な値: 共通テンプレート、ベクトル: 画像検索、およびベクトル: テキストのセマンティック検索。
データ同期ステップで、次のパラメータを構成してデータソースを追加し、[チェック] をクリックしてデータソース情報を確認します。チェックに合格したら、次へをクリックします。
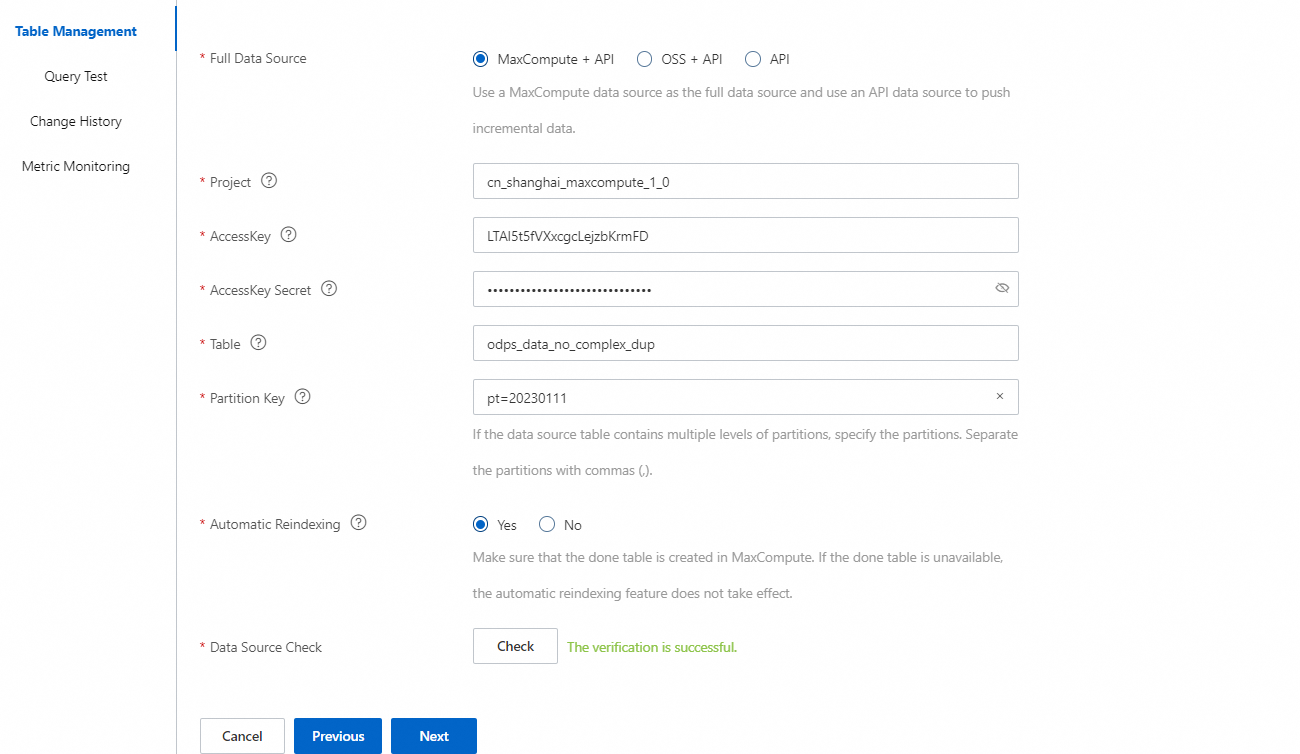
パラメータ:
完全なデータソース: データソースのタイプ。有効な値: MaxCompute + API、OSS + API、およびAPI。この例では、MaxCompute + APIが選択されています。
プロジェクト: アクセスするMaxComputeプロジェクトの名前。
AccessKey: Alibaba CloudアカウントまたはAlibaba Cloudアカウント内のResource Access Management (RAM)ユーザーのAccessKey ID。
AccessKeyシークレット: AccessKey IDに対応するAccessKeyシークレット。
テーブル: アクセスするMaxComputeテーブルの名前。
パーティションキー: MaxComputeデータソースのパーティションキー。このパラメータは必須です。例: ds=20170626。
タイムスタンプ: API操作を使用して増分データがプッシュされる場合、このパラメータは、システムがデータソースから増分データを同期する時点を指定します。過去72時間以内の日時を選択できます。
自動再インデックス化: 自動再インデックス化機能を有効にするかどうかを指定します。自動再インデックス化機能が有効になっている場合、システムはデータソースのデータ変更を検出するたびに、データソースを参照するインデックステーブルの再インデックス化を自動的に実行します。
自動再インデックス化を有効にする場合は、完了テーブルを作成する必要があります。詳細については、このトピックの自動再インデックス化の構成セクションを参照してください。
フィールド構成ステップで、テーブルのフィールドを構成し、[次へ] をクリックします。
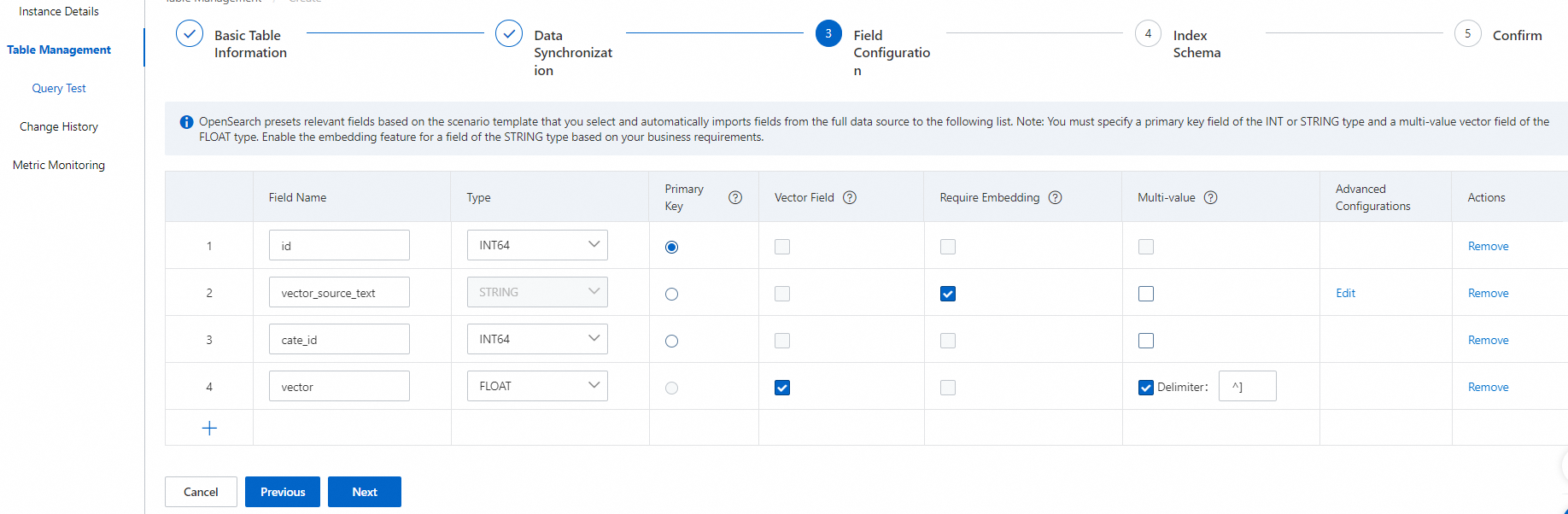
プライマリキーフィールドとベクトルフィールドは必須です。プライマリキーフィールドはINTまたはSTRING型である必要があります。ベクトルフィールドはFLOAT型である必要があります。
デフォルトでは、ベクトルフィールドはFLOAT型の複数値フィールドであり、ベクトルフィールドの複数の値はHA3区切り文字(^])で区切られます。この区切り文字はUTF形式で\x1Dとしてエンコードされます。カスタムの複数値区切り文字を入力することもできます。
インデックススキーマステップで、テーブルのインデックスを構成し、[次へ] をクリックします。
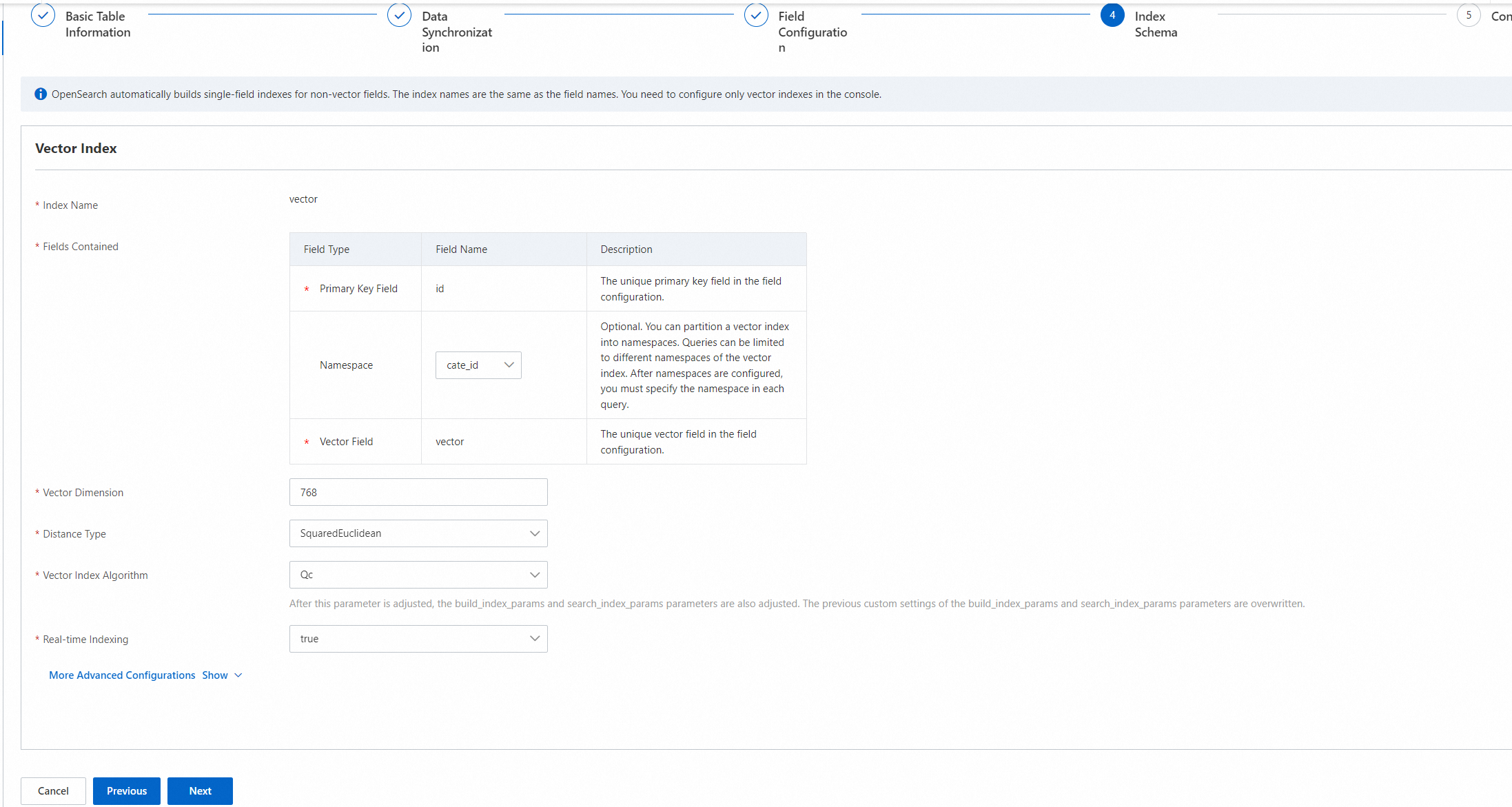
[ベクトルインデックス] セクションで次のパラメータを構成します。
プライマリキーフィールドとベクトルフィールドは必須です。名前空間フィールドはオプションであり、空のままにすることができます。
[含まれるフィールド] パラメータには3つの固定フィールドのみを構成でき、フィールドを追加することはできません。
ベクトル次元: ベクトルの次元。選択したベクトルモデルに基づいてベクトル次元を指定します。
距離タイプ: ベクトル距離のタイプ。有効な値: SquareEuclideanとInnerProduct。選択したベクトルモデルに基づいて距離タイプを指定します。
ベクトルインデックスアルゴリズム: ベクトルインデックスの作成に使用されるアルゴリズム。有効な値: Qc、Linear、およびHNSW。選択したベクトルモデルに基づいてアルゴリズムを指定します。
リアルタイムインデックス化: API操作によってプッシュされる増分データのリアルタイムインデックスを構築するかどうかを指定します。有効な値: trueとfalse。デフォルト値: true。
ベクトルインデックスの詳細構成のパラメータも構成できます。詳細については、ベクトルインデックスの共通構成 を参照してください。
[確認] ステップで、[確認] をクリックします。構成したテーブルが自動的に作成されます。
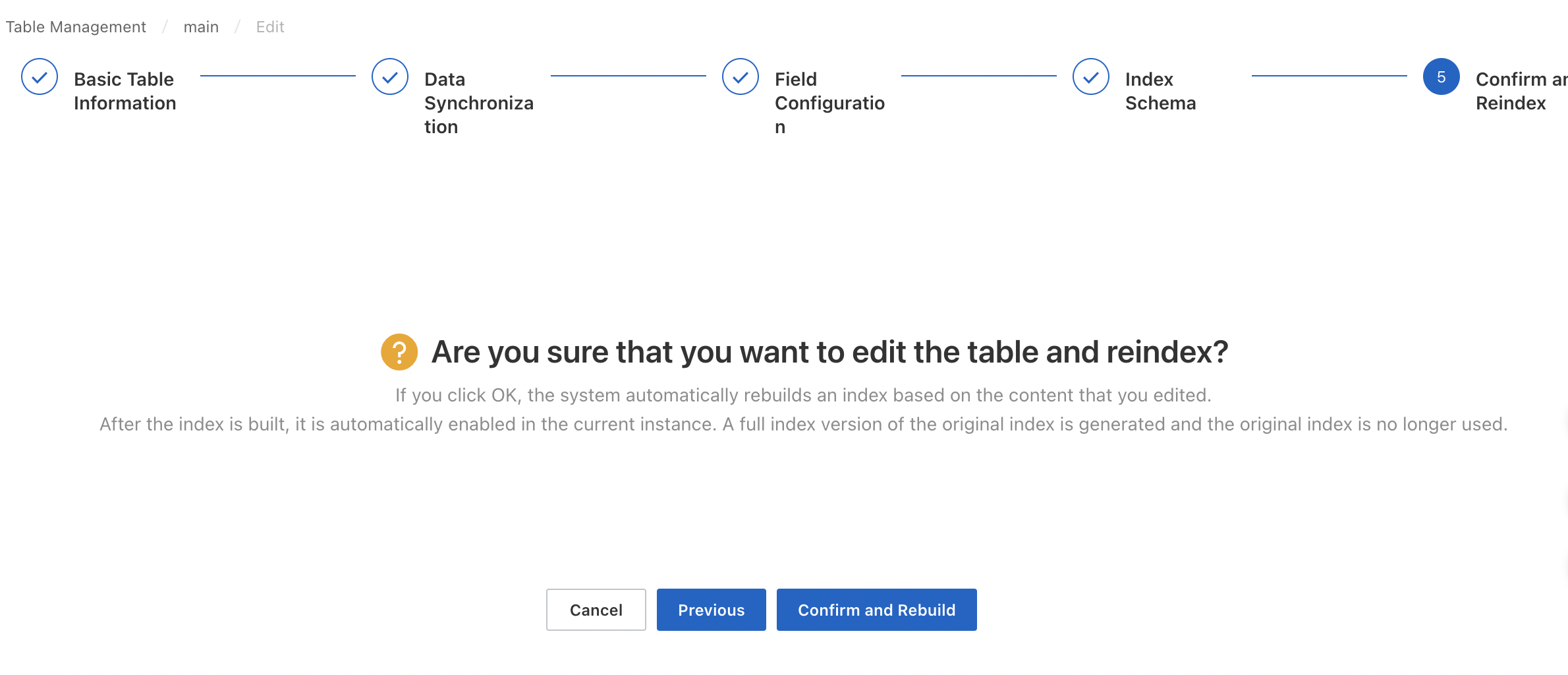
テーブルの作成進捗状況を表示するには、インスタンスの詳細ページの左側のペインにある[変更履歴] をクリックし、[データソースの変更] タブをクリックします。
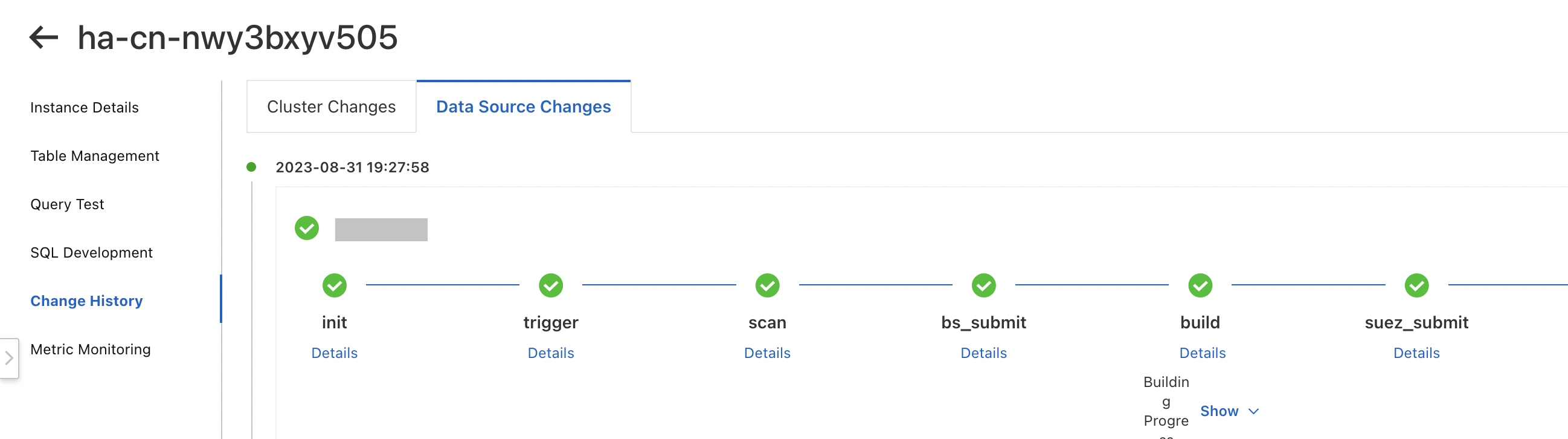
テーブルが[使用中] 状態になったら、[クエリテスト] ページでクエリテストを実行できます。
自動再インデックス化の構成
完了テーブルの説明: データソースを構成するときに自動再インデックス化を有効にすると、OpenSearch Vector Search Editionは完了テーブルの変更に基づいて自動的に再インデックス化を実行します。
例: MaxComputeデータソースを構成するときに、MaxComputeテーブルとしてmytableを、パーティションとしてds=20220113を指定します。データソースの再インデックス化を初めて構成した後、システムは毎日新しいパーティションを生成します。各新しいパーティションには、テーブルの完全なデータが含まれています。新しいパーティションが生成されるたびに、OpenSearch Vector Search Editionは新しいパーティションをスキャンし、新しいパーティションのデータに基づいて自動的に再インデックス化を実行する必要があります。この要件を満たすために、自動再インデックス化機能と完了テーブルを使用できます。
手順
データソースを追加するときに自動再インデックス化を有効にします。
MaxComputeで対応する完了テーブルを構成します。MaxComputeテーブルの名前がmytableで、mytableテーブルのパーティションキーの名前がdsの場合、完了テーブルの名前はmytable_doneで、完了テーブルのパーティションキーの名前はdsです。次のコードブロックは、2つのテーブルがMaxComputeにどのように表示されるかを示しています。
odps:sql:xxx> show tables;
InstanceId: xxx
SQL: .
ALIYUN$****@aliyun.com:mytable # データソースの完全なデータを格納するテーブル。
ALIYUN$****@aliyun.com:mytable_done # ソーステーブルの完全なデータが自動的に同期される完了テーブル。次の図は、完了テーブルを示しています。
次のステートメントを実行して、完了テーブルを作成できます。
create table mytable_done (attribute string) partitioned by (ds string);mytableテーブルのds=20220114パーティションが生成されたら、完了テーブルを構成してOpenSearch Vector Search Editionが再インデックス化を実行するようにトリガーします。
-- パーティションを追加します。
alter table mytable_done add if not exists partition (ds="20220114");
-- セマフォを挿入して、自動完全データ同期を有効にします。
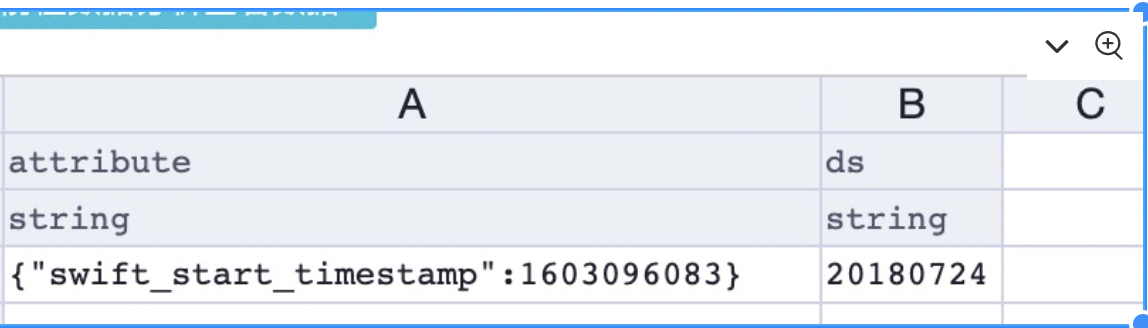
insert into table mytable_done partition (ds="20220114") select '{"swift_start_timestamp":1642003200}';完了テーブルには次の内容が含まれています。
odps:sql:xxx> select * from mytable_done where ds=20220114 limit 1;
InstanceId: xxx
SQL: .
+-----------+----+
| attribute | ds |
+-----------+----+
| {"swift_start_timestamp":1642003200} | 20220114 |
+-----------+----+自動完全データ同期のセマフォが完了テーブルに挿入されると、OpenSearch Vector Search Editionは完了テーブルのセマフォをスキャンし、自動的に再インデックス化をトリガーします。
完了テーブルには少なくとも1つのパーティションキーを指定してください。完了テーブルのパーティションキーの名前は、MaxComputeテーブルのパーティションキーの名前と同じである必要があります。MaxComputeテーブルのパーティションキーがdsの場合、完了テーブルのパーティションキーはdsに設定する必要があります。
完了テーブルには、STRING型のフィールドが1つだけ含まれています。フィールド名はattributeである必要があります。
完了テーブルに追加するパーティションは、MaxComputeテーブルに存在する必要があります。たとえば、MaxComputeテーブルにds=20220114、ds=20220115、およびds=20220116パーティションが含まれている場合、完了テーブルに追加するパーティションを3つのパーティションから選択する必要があります。
完了テーブルにデータを挿入する場合、attributeフィールドの値はJSON文字列(例: {"swift_start_timestamp":1642003200})である必要があります。タイムスタンプは、リアルタイムの増分データ同期の開始オフセットを指定します。
使用上の注意
MaxComputeは外部テーブルをサポートしていません。内部テーブルを作成する必要があります。
MaxComputeデータソースを追加するときに指定するMaxComputeテーブルは、パーティションテーブルである必要があります。
MaxComputeテーブルの完全なデータをデータソースとして使用して、OpenSearch Vector Search Editionでインデックスを構築し、APIデータソースを使用して増分データをリアルタイムで同期できます。