このトピックでは、テーブル作成時のベクトルインデックスの構成方法について説明します。これらの構成を使用して、パフォーマンス、コスト、リアルタイム機能に関するビジネス要件を満たします。
パラメーター構成
テーブル作成のステップ 4 で、インデックス構造 を構成します。このステップでベクトルフィールドを詳細に構成できます。
ベクトルディメンション
ベクトルの特徴数を指定します。この値は、ベクトルモデルの出力ディメンションと正確に一致するように設定します。
推奨事項:
一貫性を保つ: 構成されたディメンションが実際のベクトルデータと一致しない場合、インデックス構築は失敗します。
パフォーマンスへの影響: ディメンションが高いほど、より多くの情報を取得できますが、メモリ使用量と計算オーバーヘッドが増加します。ディメンションを 2 倍にすると、メモリ使用量もほぼ 2 倍になります。
距離タイプ
ベクトル間の類似度を計算する方法を指定します。データ特性とビジネスシナリオに最適な距離タイプを選択します。この選択は、取得品質に直接影響します。
選択ガイド:
距離タイプ
ベクトルスコアの意味
コサイン距離
スコアは
[-1, 1]の範囲です。スコアが高いほど類似度が高くなります。スコアが1の場合、ベクトルは同一です。スコアが-1の場合、ベクトルは反対です。内積距離 (InnerProduct)
スコアが高いほど類似度が高くなります。
ユークリッド距離の二乗 (SquareEuclidean)
スコアが低いほど類似度が高くなります。スコアが
0の場合、ベクトルは同一です。
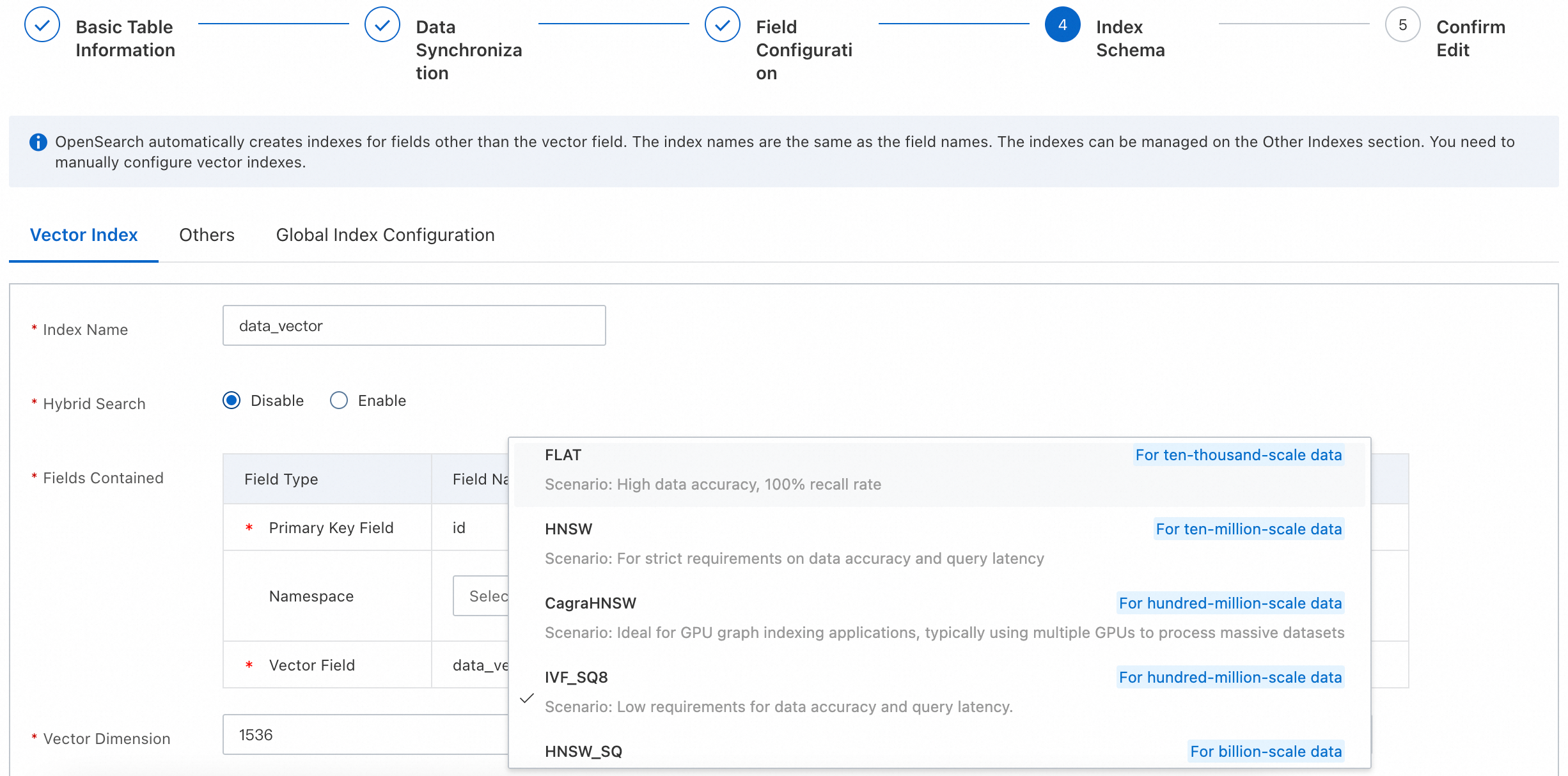
ベクトルインデックスアルゴリズム
ベクトルインデックスの構築に使用される基盤となるアルゴリズムを指定します。各アルゴリズムは、構築速度、メモリ使用量、クエリパフォーマンス、取得率のバランスが異なります。
選択ガイド:
アルゴリズム
説明
距離タイプ
データ規模
再現率
レイテンシー
RAM 使用量
シナリオ
FLAT
(旧 Linear)
データ規模: 数万個のベクトルまで。
説明: 高精度。取得率 100%。
InnerProduct、SquaredEuclidean、Cosine
非常に小さい (<10k)
数万個
100% (正確)
非常に遅い
非常に低い
ベンチマーク。非常に小規模なデータセットに対する正確なランキング。
HNSW
データ規模: 数千万個のベクトルまで。
説明: パフォーマンスベンチマーク。精度とレイテンシーに対する厳格な要件。
InnerProduct、SquaredEuclidean、および Cosine
中規模 (1,000 万以上)
数千万個
非常に高い
低い
非常に高い
高パフォーマンスのインメモリオンライン検索。
HNSW_RaBitQ
ベクトル規模: 最大 10 億個のベクトルデータ量をサポートします。
説明: 厳格なメモリ制約下にある大規模データセット向けに最適化されています。精度要件は低めです。
SquaredEuclidean
中規模から大規模 (1 億以上)
数億個
高い
非常に低い
非常に低い
バイナリ量子化向けに最適化された軽量検索。
CagraHNSW
データ規模: 数億個のベクトルまで。
説明: GPU アクセラレーションによるグラフインデックス作成。大規模ワークロードには複数の GPU との併用が最適です。
InnerProduct、SquaredEuclidean
中規模から大規模 (1 億以上)
数億個
非常に高い
非常に低い (GPU)
非常に高い
GPU アクセラレーション。非常に高いスループット。
HNSW_SQ
(旧 QGraph)
データ規模: 最大数十億個のベクトルまで。
説明: 高いクエリ速度とパフォーマンス。精度要件は低めです。
InnerProduct、SquaredEuclidean、Cosine
中規模 (1 億以上)
数十億個
高い
低い
高い
IVF_SQ8
データ規模: 数億個のベクトルまで。
説明: バランスの取れたトレードオフ。精度とレイテンシーの両方に中程度の要件。
InnerProduct、SquaredEuclidean、および Cosine
大規模
5 億個
中程度から高い
中央
低い
予算制約のある大規模ワークロード向けのコールド・ホット階層型ストレージ。ベクトルを圧縮することでメモリ使用量を削減します。コストと規模の古典的なバランス。
DiskANN
データ規模: 数十億個以上のベクトル。
説明: ローカルディスクを使用します。より高いレイテンシーを許容し、最小限のメモリを使用します。
InnerProduct、SquaredEuclidean、または Cosine
大規模 (10 億以上)
数十億個以上
高い
中程度から高い
非常に低い
ディスク常駐型、超大規模検索。
リアルタイムインデックス作成
API 経由で書き込まれた増分データの即時インデックス作成とクエリを有効にします。データは数秒以内に可視になります。
仕組み: システムはまず、リアルタイム書き込み用の一時的なインメモリインデックスを構築します。十分なデータが蓄積されると、それらのインデックスを完全なディスクベースインデックスとマージします。
推奨事項:
有効にする (
true): データがすぐに検索可能である必要があるオンラインサービスに使用します。これにより、追加のメモリと CPU リソースが使用されます。無効にする (
false): 更新頻度が低いバッチインポートやオフライン分析に使用します。
高度な構成
線形構築のしきい値
シャード内のドキュメント数がこのしきい値より少ない場合、別のベクトルインデックスアルゴリズムを選択した場合でも、システムは検索に
Linear(力まかせ探索) を使用します。推奨事項:
デフォルト:
5000。これは経験値です。この規模では、力まかせ探索は複雑なインデックスを構築するのと同等か、それ以上のパフォーマンスを発揮することがよくあります。必要な場合にのみ調整: 通常、これは変更しないでください。クエリ同時実行数が非常に高く、データ量がこのしきい値に近い場合は、
HNSWなどの高パフォーマンスインデックスの使用を強制するために値を下げてください。これにより、インデックス構築のオーバーヘッドが増加する可能性があることに注意してください。
無効なベクトルデータの無視
完全または増分インデックス構築中に、ディメンションの不一致や空の値などの異常なベクトルをシステムがどのように処理するかを制御します。
推奨事項:
オプション
動作
推奨シナリオ
true無効なベクトルを含む行をスキップします。インデックス構築は続行されます。ログに警告が表示されます。
開発とテスト。少数の不正なレコードによってジョブ全体が中断されることなく、迅速なデバッグに役立ちます。
falseインデックス構築を停止し、無効なベクトルがある場合はエラーを返します。
本番環境。データ品質を確保し、サイレントデータ損失を防ぎます。アップストリームのデータクリーンアップワークフローと併用します。
リアルタイムインデックス作成パラメーター
リアルタイムインデックス作成が有効になった後、リアルタイムデータストリームがどのように処理されるかを調整します。
例:
{"proxima.oswg.streamer.segment_size":2048}説明:
proxima.oswg.streamer.segment_sizeパラメーターは、小さなインメモリセグメント (Segment) にフラッシュされる前に、メモリに蓄積されるレコードの数を制御します。チューニングの推奨事項:
高い書き込み QPS: メモリ内のセグメント数を減らし、インデックス管理オーバーヘッドを低減するために、この値 (たとえば、
4096に) を増やします。これにより、書き込みとクエリの可用性の間の遅延がわずかに増加します。低い書き込み QPS: 新しく書き込まれたデータがクエリでより速く利用可能になるように、デフォルト値
2048を維持するか、わずかに減らします。
リアルタイム取得パラメーター
インデックスアルゴリズムごとに検索動作を動的に調整し、取得率とレイテンシーのバランスを取ります。キーと値は、選択されたベクトルインデックスアルゴリズムによって異なります。
一般的な注意: これらのパラメーターは通常、検索範囲を制御します。たとえば、
HNSWの場合、efパラメーターは、検索中に走査する近傍ノードの数を設定します。efが大きいほど取得率は向上しますが、レイテンシーが増加します。例 (HNSW):
{"searcher_name":"HNSW", "ef":200}efの値は通常、k(要求されたトップ K 結果の数) から4096の範囲です。100からテストを開始し、取得率とレイテンシーの要件に基づいて調整してください。
ベクトルセパレーター
文字列形式のベクトルデータにおけるベクトルディメンション間のデリミタを指定します。
例:
1.05,0.15,0.14では、デリミタはコンマ (,) です。これがデフォルトです。変更する必要があることはめったにありません。