Realtime Compute for Apache Flinkの強力なリアルタイムデータ処理機能と、Hologresのバイナリログ、ハイブリッド行-列ストレージ、強力なリソース分離などの機能に基づいて、効率的かつスケーラブルなリアルタイムデータ処理と分析を実装するリアルタイムデータウェアハウスを構築できます。 これにより、増加するデータ量とリアルタイムのビジネス要件に適切に対応できます。 このトピックでは、Realtime Compute for Apache FlinkとHologresを使用してリアルタイムデータウェアハウスを構築する方法について説明します。
背景情報
デジタル化が進むにつれて、企業のデータ鮮度に対する需要はますます高まっています。 ユーザーは、従来のオフラインデータ処理シナリオに加えて、多くのビジネスシナリオでデータをリアルタイムで処理、保存、分析する必要があります。 従来のオフラインデータウェアハウスでは、オペレーショナルデータストア (ODS)、データウェアハウスの詳細 (DWD)、データウェアハウスサービス (DWS)、およびアプリケーションデータサービス (ADS) の各データレイヤーでデータを処理するために定期的なスケジューリングが実行されます。 ただし、リアルタイムデータウェアハウスの方法論システムは明確ではありません。 Streaming Warehouse の概念を使用して、データレイヤー間でリアルタイムデータの効率的なフローを実装します。 これにより、リアルタイムデータウェアハウスのデータレイヤーに関連する問題を解決できます。
概要
この例では、Flink と Hologres を使用して E コマースプラットフォームのリアルタイムデータウェアハウスを構築する方法を示します。 リアルタイムデータウェアハウスは、データをリアルタイムで処理およびクレンジングし、外部アプリケーションからデータをクエリするために構築されています。 このようにして、リアルタイムデータは階層化され、再利用されて、データレポートやトランザクションデータダッシュボード、クリックストリーム分析、ユーザープロファイリングとタグ付け、パーソナライズされた推奨など、複数のビジネスシナリオをサポートします。
アーキテクチャ

ODS レイヤー: Flink はデータをリアルタイムでデータウェアハウスに取り込みます。
MySQL には、orders、orders_pay、product_catalog の 3 つのビジネステーブルがあります。 Realtime Compute for Apache Flink は、テーブルから Hologres にデータをリアルタイムで取り込み、ODS レイヤーを形成します。
DWD レイヤー: Flink は関連テーブルのデータをリアルタイムで統合します。
Flink は orders、orders_pay、product_catalog の各テーブルをリアルタイムで結合し、DWD レイヤーで dwd_orders テーブルを形成します。
DWS レイヤー: Flink はリアルタイム計算を実行します。
Flink は dwd_orders テーブルのバイナリログイベントを消費し、DWS レイヤーで dws_users 集計テーブルと dws_shops 集計テーブルを生成します。
Hologres はクエリに応答します。
Hologres は DWS レイヤーのテーブルに対するクエリを処理し、最大 100 万 レコード/秒 (RPS) をサポートします。
Hologres は dwd_orders テーブルに基づいて OLAP 分析を実行するか、リアルタイムレポートを生成し、数秒以内にクエリ応答を提供します。
ソリューションのメリットとサービス機能
このソリューションには、次の利点があります。
効率的な更新とアドホッククエリ: 従来のリアルタイムウェアハウスでは、中間レイヤーでのデータのクエリ、更新、修正が困難でした。 Hologres は、効率的なデータの更新と修正をサポートし、すべてのレイヤーで書き込み後読み取り整合性を確保することで、これらの問題に対処します。
データの再利用性: Hologres では、すべてのレイヤーのデータを外部サービスで個別に使用できるため、データウェアハウス内のデータを効率的に再利用できます。
合理化されたアーキテクチャと強化された効率: Flink SQL を使用してリアルタイム ETL パイプラインを構築し、ODS、DWD、DWS レイヤーのデータを Hologres に一元的に保存します。 このアプローチにより、データウェアハウスアーキテクチャが合理化され、データ処理効率が向上します。
このソリューションは、Hologres の 3 つのコア機能に依存しています。
機能 | 説明 |
Hologres は、Flink がリアルタイム計算を実行し、ストリーミングパイプラインのアップストリームコンポーネントとして機能するように駆動するバイナリロギングを備えています。 | |
Hologres はハイブリッド行-列ストレージをサポートしています。 Hologres テーブルは、行指向データと列指向データの両方を保存し、それらの間の強力な整合性を確保します。 この機能により、中間レイヤーのテーブルを Flink のソーステーブルとして、またプライマリキーに基づくルックアップ結合とポイントクエリの Flink のディメンションテーブルとして使用できます。 中間レイヤーのテーブルは、オンライン分析処理 (OLAP) アプリやオンラインサービスなどの他のアプリケーションでクエリすることもできます。 | |
強力なリソース分離 | Hologres インスタンスの負荷が高い場合、ポイントクエリに応答する中間レイヤーのパフォーマンスが影響を受ける可能性があります。 Hologres は、プライマリインスタンスとセカンダリインスタンス (共有ストレージ) の読み取り/書き込み分離を構成するか、仮想ウェアハウスのアーキテクチャを使用することで、強力なリソース分離を実装します。 これにより、Flink が Hologres からバイナリログデータをプルするときにオンラインサービスが影響を受けないようにします。 |
使用上の注意
Hologres の排他的インスタンスがあります。
ApsaraDB RDS for MySQL インスタンスと Hologres インスタンスは、Realtime Compute for Apache Flink ワークスペースと同じ VPC に存在する必要があります。 同じ VPC に存在しない場合は、VPC 間の接続を確立するか、Realtime Compute for Apache Flink がインターネット経由で他のサービスにアクセスできるようにする必要があります。 詳細については、「Realtime Compute for Apache Flink は VPC 間でサービスにどのようにアクセスしますか?」および「Realtime Compute for Apache Flink はインターネットにどのようにアクセスしますか?」をご参照ください。
Flink、Hologres、MySQL へのアクセスに使用される RAM ユーザーまたは RAM ロールには、必要な権限があります。
ステップ 1: 準備を行う
ApsaraDB RDS for MySQL インスタンスを作成し、データを準備する
ApsaraDB RDS for MySQL インスタンスを作成する。
ApsaraDB RDS for MySQL インスタンス、Flink ワークスペース、Hologres インスタンスは、同じ VPC に存在する必要があります。
MySQL CDC データソースを準備します。
MySQL インスタンスの詳細ページの右上隅にある [データベースにログオン] をクリックします。
ダイアログで、アカウントとパスワードを入力し、[ログイン] をクリックします。
左側のナビゲーションウィンドウで、order_dw データベースをダブルクリックします。
SQL コンソール タブで、DDL ステートメントを記述して 3 つのビジネステーブルを作成し、テーブルにデータを挿入します。
CREATE TABLE `orders` ( order_id bigint not null primary key, user_id varchar(50) not null, shop_id bigint not null, product_id bigint not null, buy_fee numeric(20,2) not null, create_time timestamp not null, update_time timestamp not null default now(), state int not null ); /* 注文テーブルを作成 */ CREATE TABLE `orders_pay` ( pay_id bigint not null primary key, order_id bigint not null, pay_platform int not null, create_time timestamp not null ); /* 支払いテーブルを作成 */ CREATE TABLE `product_catalog` ( product_id bigint not null primary key, catalog_name varchar(50) not null ); /* 製品カタログテーブルを作成 */ -- データを準備します。 INSERT INTO product_catalog VALUES(1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'),(4, 'phone_ddd'),(5, 'phone_eee'); /* 製品カタログデータを追加 */ INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000.05, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1), (100002, 'user_002', 12346, 2, 4000.04, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1), (100003, 'user_003', 12347, 3, 3000.03, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1), (100004, 'user_001', 12347, 4, 2000.02, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1), (100005, 'user_002', 12348, 5, 1000.01, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1), (100006, 'user_001', 12348, 1, 1000.01, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1), (100007, 'user_003', 12347, 4, 2000.02, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1); /* 注文データを追加 */ INSERT INTO orders_pay VALUES (2001, 100001, 1, '2023-02-15 17:40:56'), (2002, 100002, 1, '2023-02-15 17:40:56'), (2003, 100003, 0, '2023-02-15 17:40:56'), (2004, 100004, 0, '2023-02-15 17:40:56'), (2005, 100005, 0, '2023-02-15 18:40:56'), (2006, 100006, 0, '2023-02-15 18:40:56'), (2007, 100007, 0, '2023-02-15 18:40:56'); /* 支払いデータを追加 */[実行(F8)] をクリックします。 表示されるパネルで、[実行] をクリックします。
Hologres インスタンスと 仮想ウェアハウス を作成する
製品タイプ で、必要に応じて [排他インスタンス (サブスクリプション)] または [排他インスタンス (従量課金)] を選択します。
仕様 で、[計算グループタイプ] を選択します。
仮想ウェアハウスの予約済み計算リソース に 64 と入力して、追加の仮想ウェアハウスを追加できるようにします。
VPC で、ドロップダウンリストから MySQL インスタンスの VPC を選択します。
Hologres インスタンスにログオンし、データベースを作成します。
Hologres コンソールの左側のナビゲーションウィンドウで、[インスタンス] を選択します。
ターゲット Hologres インスタンス名をクリックします。
インスタンスの詳細ページで、[インスタンスに接続] をクリックします。
表示される HoloWeb コンソールの上部ナビゲーションバーで、[データベースの作成] を選択します。
データベース名 に order_dw と入力します。
ポリシー で、[SPM] を選択します。
[OK] をクリックします。
Alibaba Cloud アカウント、RAM ユーザー、またはロールに管理者ロールを割り当てます。 詳細については、「データベースの管理」をご参照ください。
説明ユーザー ドロップダウンリストに RAM ユーザーまたはロールが見つからない場合は、 ページで RAM ユーザーをインスタンスのスーパーユーザーとして追加します。
バイナリログの拡張は、Hologres V2.0 以降でデフォルトで有効になっています。
クエリを処理するために、read_warehouse_1 という名前の仮想ウェアハウスを作成します。
初期仮想ウェアハウス init_warehouse はデータの書き込みに使用されます。
予約済みの計算リソースは初期仮想ウェアハウスに自動的に割り当てられるため、仮想ウェアハウスインスタンスを作成する前に、その計算リソースを削減する必要があります。 次の手順を実行します。
HoloWeb コンソールの上部ナビゲーションバーで、 をクリックします。 インスタンス名が正しいことを確認します。
初期仮想ウェアハウス init_warehouse を見つけ、操作 列の [構成の変更] をクリックします。
ダイアログで計算グループリソースを削減し、[OK] をクリックします。
[計算グループの作成] をクリックします。 計算グループ名 フィールドに read_warehouse_1 と入力し、[OK] をクリックします。
Realtime Compute for Apache Flinkワークスペースとカタログを作成する
ApsaraDB RDS for MySQL インスタンスと Hologres インスタンスと同じ VPC で Flink ワークスペースを起動します。
Realtime Compute for Apache Flink コンソール にログオンします。 ターゲットワークスペースを見つけ、操作 列の [コンソール] をクリックします。
セッションクラスタを作成すると、カタログとスクリプトを作成するための実行環境が提供されます。
Flink SQL を介して Hologres カタログを作成します。
Realtime Compute for Apache Flink の開発コンソールの左側のナビゲーションウィンドウで、 を選択します。
[新規] をクリックして新しいスクリプトを作成し、次のコードをエディターにコピーして、プレースホルダー値を実際の値に置き換えます。
次に、実行するコードを選択し、[実行] をクリックします。
ページの右下隅に、実行環境が作成したセッションクラスタであることが表示されます。
CREATE CATALOG dw WITH (
'type' = 'hologres',
'endpoint' = '<ENDPOINT>',
'username' = 'BASIC$flinktest',
'password' = '${secret_values.holosecrect}',
'dbname' = 'order_dw@init_warehouse', --init_warehouse 仮想ウェアハウスに接続します。
'binlog' = 'true', -- Hologres カタログの作成時に指定するコネクタオプションは、このカタログで作成された新しいテーブルにも適用されます。
'sdkMode' = 'jdbc', -- 推奨モード。
'cdcmode' = 'true',
'connectionpoolname' = 'the_conn_pool',
'ignoredelete' = 'true', -- テーブルを統合するときにデータの取り消しを防ぐには、このオプションを有効にします。
'partial-insert.enabled' = 'true', -- テーブルの統合が含まれる場合は、部分更新を有効にします。
'mutateType' = 'insertOrUpdate', -- テーブルの統合が含まれる場合は、部分更新を有効にします。
'table_property.binlog.level' = 'replica', -- カタログを作成するときに、永続テーブルプロパティ (この場合はバイナリロギングが有効) を渡します。 このプロパティは、このカタログで後続に作成されるすべてのテーブルに適用されます。
'table_property.binlog.ttl' = '259200'
);次のプレースホルダー値を置き換えます。
オプション | 説明 | 備考 |
endpoint | Hologres インスタンスのエンドポイント。 | エンドポイント値を取得するには、次の手順に従います。
詳細については、「Hologres に接続するためのエンドポイント」をご参照ください。 |
username | 次のいずれかを入力します。
|
|
password |
|
カタログを作成するときに、コネクタオプションを定義できます。これは、後でそのカタログ内に作成されるテーブルに自動的に適用されます。 さらに、table_property プレフィックスが付いたものなど、Hologres 物理テーブルのデフォルトプロパティを指定できます。 詳細については、「Hologres カタログの管理」および「Hologres コネクタ」トピックの「WITH 句のコネクタオプション」セクションをご参照ください。
MySQLカタログを作成します。
SQL エディターで次のコードをコピーし、プレースホルダー値を置き換え、実行するコードを選択して、[実行] をクリックします。 ページの右下隅に、実行環境が作成したセッションクラスタであることが表示されます。
CREATE CATALOG mysqlcatalog WITH( 'type' = 'mysql', 'hostname' = '<hostname>', 'port' = '<port>', 'username' = '<username>', 'password' = '${secret_values.mysql_pw}', 'default-database' = 'order_dw' );次のプレースホルダー値を実際の値に置き換えます。
オプション
説明
hostname
ApsaraDB RDS for MySQL データベースへのアクセスに使用される IP アドレスまたはホスト名。 内部エンドポイントを取得するには、次の手順に従います。
ApsaraDB RDS コンソールの左側のナビゲーションウィンドウで、[インスタンス] を選択します。
ターゲットインスタンスの名前をクリックします。
表示されるページの 基本情報 セクションで、ネットワークタイプ フィールドの横にある [詳細の表示] をクリックします。
表示されるパネルで、内部エンドポイント値をコピーします。
port
ApsaraDB RDS for MySQL データベースのポート番号。 デフォルト値: 3306。
username
ApsaraDB RDS for MySQL データベースへのアクセスに使用されるユーザー名。
password
ApsaraDB RDS for MySQL データベースへのアクセスに使用されるパスワード。
セキュリティを強化するために、この例ではプレーンテキストの AccessKey シークレットの代わりに mysql_pw 変数を使用しています。 詳細については、「変数の管理」をご参照ください。
ステップ 2: リアルタイムデータウェアハウスを構築する
ODS レイヤーを構築する: Flink を使用して Hologres にデータをリアルタイムで取り込む
カタログに関連する CREATE DATABASE AS (CDAS) ステートメント を実行して、ODS レイヤーを簡単に作成できます。 ODS レイヤーは、多くの場合、OLAP やポイントクエリには使用されません。 代わりに、ストリーミングジョブのイベントドライバーとして使用されます。 したがって、このレイヤーのバイナリロギングを有効にするだけで十分です。 バイナリロギングは、Hologres のコア機能の 1 つです。 Hologres コネクタを使用してすべてのレコードを読み取り、次に増分バイナリログデータを消費できます。
同期ジョブを作成します。
左側のナビゲーションウィンドウで、 を選択します。 表示されるページで、ODS という名前の SQL ストリームドラフトを作成し、次のコードを SQL エディターにコピーします。
CREATE DATABASE IF NOT EXISTS dw.order_dw -- Hologres カタログの作成時に table_property.binlog.level オプションが指定されているため、CDAS ステートメントを使用して作成されたすべてのテーブルでバイナリロギングが有効になります。 AS DATABASE mysqlcatalog.order_dw INCLUDING all tables -- アップストリームデータベース内のデータウェアハウスに取り込む必要のあるテーブルを選択できます。 /*+ OPTIONS('server-id'='8001-8004') */ ; -- MySQL CDC インスタンスの server-id パラメーターの値の範囲を指定します。説明この例では、データはデフォルトでorder_dwデータベースのパブリックスキーマに同期されます。 データをデスティネーションHologresデータベースの指定されたスキーマに同期することもできます。 詳細については、「Hologresカタログを管理する」トピックの「CREATE TABLE ASステートメントで使用されるデスティネーションストアのカタログとして、作成したHologresカタログを使用する」セクションをご参照ください。 スキーマを指定した後、カタログを使用すると、テーブル名の形式が変更されます。 詳細については、「Hologresカタログを管理する」トピックの「Hologresカタログを使用する」セクションをご参照ください。
ソーステーブルのスキーマ更新は、ソーステーブルのデータが削除、挿入、または更新されるまで、ターゲットテーブルに反映されません。
SQL エディターの右上隅にある [デプロイ] をクリックします。
ジョブを開始します。
左側のナビゲーションウィンドウで、 を選択します。
[デプロイメント] ページで、
ODSという名前のデプロイメントを見つけ、[アクション] 列の [開始] をクリックします。[ジョブの開始] パネルで、[初期モード] を選択し、[開始] をクリックします。
仮想ウェアハウスにデータを読み込みます。
order_dwデータベースにデータを格納するorder_dw_tg_defaultテーブルグループ をread_warehouse_1仮想ウェアハウスに読み込みます。このようにして、read_warehouse_1仮想ウェアハウスは外部クエリを処理し、init_warehouse仮想ウェアハウスはデータの書き込みに使用されます。HoloWeb ページの上部ナビゲーションバーで、[SQL エディター] を選択します。正しいインスタンスとデータベースを使用していることを確認した後、次のコマンドを実行します。詳細については、「仮想ウェアハウスインスタンスを作成する」をご参照ください。正常に実行されると、
order_dw_tg_defaultテーブルグループが read_warehouse_1 仮想ウェアハウスにロードされたことがわかります。-- 現在のデータベースのテーブルグループを表示します。 SELECT tablegroup_name FROM hologres.hg_table_group_properties GROUP BY tablegroup_name; /* 現在のデータベースのテーブルグループを表示 */ -- テーブルグループを仮想ウェアハウスにロードします。 CALL hg_table_group_load_to_warehouse ('order_dw.order_dw_tg_default', 'read_warehouse_1', 1); /* テーブルグループを仮想ウェアハウスにロード */ -- テーブルグループがロードされているかどうかを確認します。 select * from hologres.hg_warehouse_table_groups; /* テーブルグループがロードされているかどうかを確認 */右上隅で、クエリと分析のために仮想ウェアハウスを read_warehouse_1 に切り替えます。

同期の結果を確認するには、[SQL エディター] で以下のコマンドを実行します。
--- ordersテーブルのデータをクエリします。 SELECT * FROM orders; --- orders_payテーブルのデータをクエリします。 SELECT * FROM orders_pay; --- product_catalogテーブルのデータをクエリします。 SELECT * FROM product_catalog;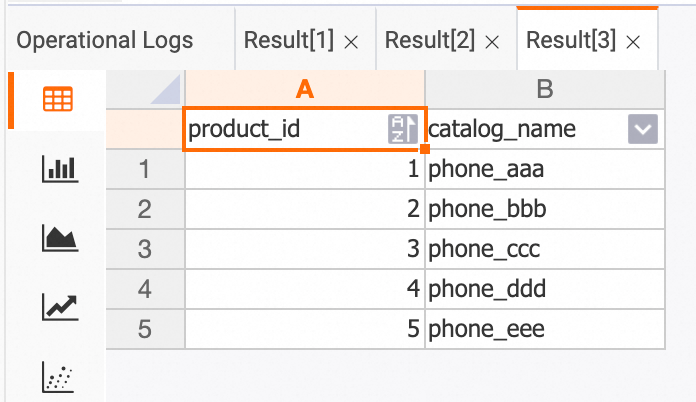
DWD レイヤーを構築する: テーブルを統合する
Hologres コネクタでサポートされている特定の列を更新する機能を使用して、DWD レイヤーを構築します。 INSERT ステートメントを使用して、効率的な部分更新を実行できます。 列指向データストレージと Hologres のハイブリッド行-列データストレージに基づく高パフォーマンスのポイントクエリは、さまざまなディメンションテーブルのデータをクエリするのに役立ちます。 Hologres は強力なリソース分離アーキテクチャを使用しており、書き込み、読み取り、分析ワークロード間の干渉を防ぎます。
Flink の Hologres カタログを使用して、Hologres の DWD レイヤーに dwd_orders という名前のテーブルを作成します。
Realtime Compute for Apache Flink の開発コンソールの左側のナビゲーションウィンドウで、 を選択します。 SQL エディターで次のコードをコピーし、コードを選択して、[実行] をクリックします。
-- 異なるソースからのデータが単一のシンクテーブルに書き込まれると、テーブルの任意の列に null 値が表示される場合があります。 したがって、ワイドテーブルのフィールドが null 許容であることを確認してください。 CREATE TABLE dw.order_dw.dwd_orders ( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int comment 'プラットフォーム 0: 電話、1: PC', pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ); /* 注文ワイドテーブルを作成 */ -- Hologres カタログを使用して、Hologres 物理テーブルのプロパティを変更できます。 ALTER TABLE dw.order_dw.dwd_orders SET ( 'table_property.binlog.ttl' = '604800' -- バイナリログデータのタイムアウト期間を 1 週間に変更します。 ); /* ワイドテーブルのバイナリログの有効期限を設定 */ODS レイヤーの orders テーブルと orders_pay テーブルのバイナリログデータをリアルタイムで消費します。
左側のナビゲーションウィンドウで、 を選択します。
表示されるページで、DWD という名前の SQL ストリームドラフトを作成し、次のコードを SQL エディターにコピーします。
BEGIN STATEMENT SET; /* 複数の insert 文をバッチで送信 */ INSERT INTO dw.order_dw.dwd_orders ( order_id, order_user_id, order_shop_id, order_product_id, order_fee, order_create_time, order_update_time, order_state, order_product_catalog_name ) SELECT o.*, dim.catalog_name FROM dw.order_dw.orders as o LEFT JOIN dw.order_dw.product_catalog FOR SYSTEM_TIME AS OF proctime() AS dim ON o.product_id = dim.product_id; /* 注文テーブルと製品カタログテーブルを結合してワイドテーブルに挿入 */ INSERT INTO dw.order_dw.dwd_orders (pay_id, order_id, pay_platform, pay_create_time) SELECT * FROM dw.order_dw.orders_pay; /* 支払いテーブルをワイドテーブルに挿入 */ END;[デプロイ] をクリックして、ドラフトからデプロイメントを作成します。
に移動し、デプロイメントの 操作 列の [開始] をクリックします。
上記の SQL 文は、
ordersテーブルとproduct_catalogテーブルを結合し、最終結果をdwd_ordersに書き込みます。このようにして、データが統合され、dwd_ordersテーブルにリアルタイムで書き込まれます。dwd_orders テーブルのデータを表示します。
HoloWeb コンソールで、Hologres インスタンスに接続し、宛先データベースにログオンします。次に、SQL エディターで次のステートメントを実行します。
SELECT * FROM dwd_orders;
DWS レイヤーを構築する: リアルタイム計算を実行する
Flink の Hologres カタログを使用して、Hologres に dws_users 集計テーブルと dws_shops 集計テーブルを作成します。
左側のナビゲーションウィンドウで、 を選択します。
SQL エディターで次のコードをコピーし、コードを選択して、[実行] をクリックします。
-- ユーザーディメンション集計テーブルを作成します。 CREATE TABLE dw.order_dw.dws_users ( user_id string not null, ds string not null, paied_buy_fee_sum numeric(20,2) not null comment 'その日に完了した支払いの合計金額', primary key(user_id,ds) NOT ENFORCED ); /* ユーザーディメンション集計テーブルを作成 */ -- ベンダーディメンション集計テーブルを作成します。 CREATE TABLE dw.order_dw.dws_shops ( shop_id bigint not null, ds string not null, paied_buy_fee_sum numeric(20,2) not null comment 'その日に完了した支払いの合計金額', primary key(shop_id,ds) NOT ENFORCED ); /* ベンダーディメンション集計テーブルを作成 */
DWD レイヤーの
dw.order_dw.dwd_ordersテーブルのデータをリアルタイムで消費し、Flink で集計を実行し、結果を Hologres の DWS レイヤーのテーブルに書き込みます。左側のナビゲーションウィンドウで、 を選択します。
表示されるページで、DWS という名前の SQL ストリームドラフトを作成し、次のコードを SQL エディターにコピーします。
BEGIN STATEMENT SET; /* 複数の insert 文をバッチで送信 */ INSERT INTO dw.order_dw.dws_users SELECT order_user_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds, SUM (order_fee) FROM dw.order_dw.dwd_orders c WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- 注文ストリーミングデータと支払いストリーミングデータの両方がすでにワイドテーブルに書き込まれています。 GROUP BY order_user_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd'); /* ユーザーディメンション集計テーブルに集計結果を挿入 */ INSERT INTO dw.order_dw.dws_shops SELECT order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds, SUM (order_fee) FROM dw.order_dw.dwd_orders c WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- 注文ストリーミングデータと支払いストリーミングデータの両方がワイドテーブルに書き込まれています。 GROUP BY order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd'); /* ベンダーディメンション集計テーブルに集計結果を挿入 */ END;[デプロイ] をクリックして、ドラフトからデプロイメントを作成します。
に移動し、デプロイメントの 操作 列の [開始] をクリックします。
DWS レイヤーの集計結果を表示します。 結果は、入力データの変更に基づいてリアルタイムで更新されます。
Hologres コンソールで結果を表示します。
dws_users テーブル
SELECT * FROM dws_users; /* ユーザーディメンション集計テーブルのデータを表示 */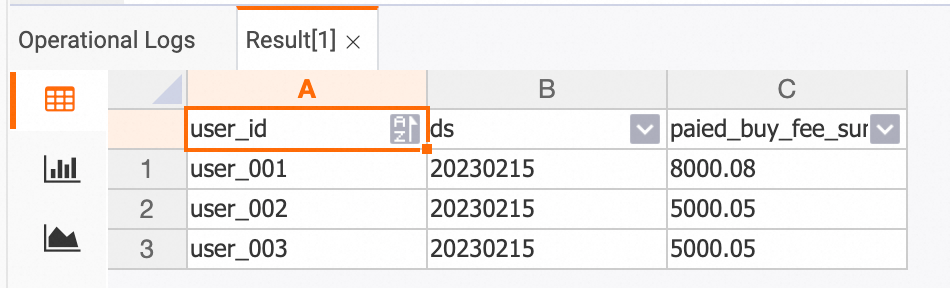
dws_shops テーブル
SELECT * FROM dws_shops; /* ベンダーディメンション集計テーブルのデータを表示 */
ApsaraDB RDS コンソールで、
order_dwデータベースのordersテーブルとorders_payテーブルにデータレコードを挿入します。INSERT INTO orders VALUES (100008, 'user_003', 12345, 5, 6000.02, '2023-02-15 09:40:56', '2023-02-15 18:42:56', 1); /* orders テーブルにデータを追加 */ INSERT INTO orders_pay VALUES (2008, 100008, 1, '2023-02-15 19:40:56'); /* orders_pay テーブルにデータを追加 */Hologres コンソールで、更新されたデータを表示します。
dwd_orders テーブル
SELECT * FROM dwd_orders;
dws_users テーブル
SELECT * FROM dws_users; /* ユーザーディメンション集計テーブルの更新されたデータを表示 */
dws_shops テーブル
SELECT * FROM dws_shops;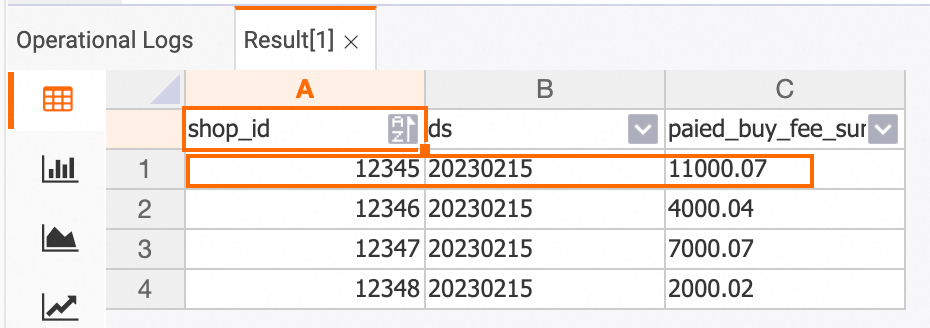
データプロファイリングを実行する
バイナリロギングが有効になっているため、データプロファイリングを実行して、データの変更を直接表示できます。 さらに、すべてのレイヤーのデータが永続化されるため、中間結果に対してアドホッククエリを実行したり、最終的な計算結果の正確性を確認したりできます。
ストリーミングモード
Print コネクタを使用して、他のシンクテーブルに送信されたメッセージが期待どおりかどうかを確認できます。
データプロファイリング用のストリーミングジョブを作成して開始します。
Realtime Compute for Apache Flink の開発コンソールに移動します。
左側のナビゲーションウィンドウで、 を選択します。
[新規] をクリックして、
Data-explorationという名前の SQL ストリームドラフトを作成し、次のコードを SQL エディターにコピーします。-- ストリーミングモードでデータプロファイリングを実行します。プリントテーブルを作成して、データの変更を表示できます。 CREATE TEMPORARY TABLE print_sink( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int, pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'print' ); INSERT INTO print_sink SELECT * FROM dw.order_dw.dwd_orders /*+ OPTIONS('startTime'='2023-02-15 12:00:00') */ -- startTime パラメーターは、バイナリログデータが生成される時間を指定します。 WHERE order_user_id = 'user_001';[デプロイ] をクリックして、ドラフトからデプロイメントを作成します。
に移動し、デプロイメントの [アクション] 列の [開始] をクリックします。
データプロファイリング結果を表示します。
開発コンソールの左側のナビゲーションウィンドウで、 を選択します。
[デプロイメント] ページで、対象のデプロイメントの名前をクリックします。
[ログ] タブで、[ログ] 左側のサブタブをクリックします。
[実行中のタスク マネージャー] タブを選択し、[パス、ID] 列の値をクリックします。
[標準出力] タブで、
user_001に関連するログを検索します。
バッチモード
バッチモードでは、データはシンクテーブルに書き込まれません。代わりに、現時点での最終データが取得され、表示できるようになります。次の手順を実行します。
左側のナビゲーションウィンドウで、 を選択します。
表示されるページで、[新規] をクリックして SQL ストリームドラフトを作成します。
次のコードを SQL エディターにコピーし、[デバッグ] をクリックします。詳細については、「デプロイをデバッグする」をご参照ください。
SELECT *
FROM dw.order_dw.dwd_orders /*+ OPTIONS('binlog'='false') */
WHERE order_user_id = 'user_001' and order_create_time > '2023-02-15 12:00:00'; -- バッチモードでのデータプロファイリングは、バッチジョブの実行効率を高めるためにフィルタープッシュダウンをサポートしています。次の図は、データプロファイリングの結果を示しています。

ステップ 3: リアルタイムデータウェアハウスを使用する
前のセクションでは、Realtime Compute for Apache Flink と Hologres を使用して階層型ストリーミングウェアハウスを構築する方法について説明しました。このセクションでは、ストリーミングウェアハウスの一般的なユースケースをいくつか紹介します。
キーベースのクエリ
DWS レイヤーの集計テーブルをプライマリキーに基づいてクエリします。最大 100 万 RPS がサポートされています。
次のサンプルコードは、HoloWeb コンソールで特定のユーザーの特定の日付の支払い金額をクエリする方法を示しています。
-- holo sql
SELECT * FROM dws_users WHERE user_id ='user_001' AND ds = '20230215';
注文詳細クエリ
DWD レイヤーの統合テーブルで OLAP 分析を実行します。
次のサンプルコードは、2023 年 2 月に HoloWeb コンソールで特定の決済プラットフォームにおける顧客の注文の詳細をクエリする方法の例を示しています。
-- holo sql
SELECT * FROM dwd_orders
WHERE order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
AND order_user_id = 'user_001'
AND pay_platform = 0
ORDER BY order_create_time LIMIT 100;
リアルタイムレポート
DWD レイヤーの統合テーブルのデータに基づいて、リアルタイムレポートを表示します。Hologres のハイブリッド行 - 列データストレージと列指向データストレージは、高い OLAP 分析機能を提供します。データクエリは数秒以内に応答できます。
次のサンプルコードは、HoloWeb コンソールで 2023 年 2 月における各カテゴリの合計注文ボリュームと合計注文額をクエリする方法の例を示します。
-- holo sql
SELECT
TO_CHAR(order_create_time, 'YYYYMMDD') AS order_create_date,
order_product_catalog_name,
COUNT(*),
SUM(order_fee)
FROM
dwd_orders
WHERE
order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
GROUP BY
order_create_date, order_product_catalog_name
ORDER BY
order_create_date, order_product_catalog_name;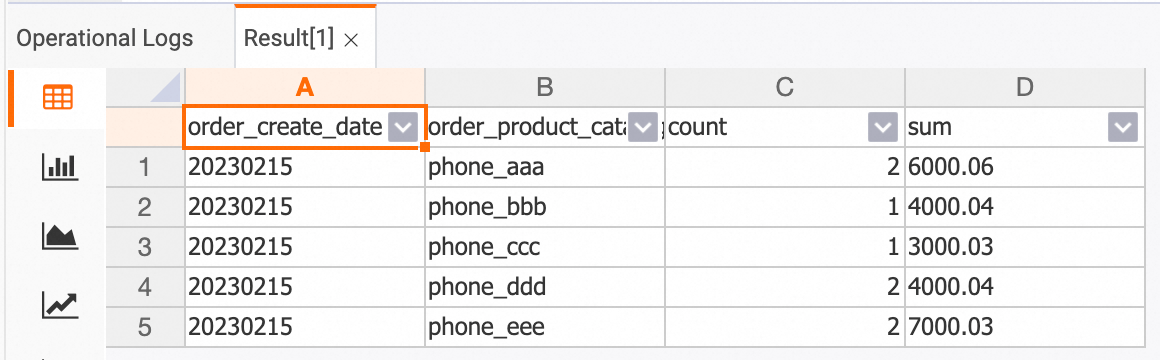
リファレンス
ハンズオン:
Hologresのバイナリログの詳細については、「Hologresバイナリログをサブスクライブする」をご参照ください。
Realtime Compute for Apache Flinkの1つのデプロイメントに複数のINSERT INTOステートメントを記述できます。 INSERT INTOステートメントの構文の詳細については、「INSERT INTOステートメント」をご参照ください。
Realtime Compute for Apache Flinkは、さまざまなコネクターをサポートしています。 詳細については、「サポートされているコネクター」をご参照ください。