ファクト論理テーブルは、ビジネスアクティビティに属性を追加して作成されます。これには、プライマリキー、メジャー、およびファクト属性が含まれます。プライマリキーは、ソーステーブルからのデータ取得ロジックを定義します。メジャーは、サイズ、数量、または程度を示す数値フィールドです。
制限事項
データ標準 モジュールを購入していない場合、テーブルの [データ標準] フィールドは設定できません。
資産セキュリティ モジュールを購入していない場合、テーブルの [データ秘密度レベル] フィールドと [データ分類] フィールドは設定できません。
資産品質 モジュールを購入していない場合、プライマリキー フィールドに対して ユニーク および NOT NULL の検証を実行できません。
前提条件
ビジネスアクティビティオブジェクトを作成しておく必要があります。詳細については、「ビジネスエンティティの作成と管理」をご参照ください。
操作手順
ステップ 1: ファクト論理テーブルの作成
Dataphin ホームページの上部ナビゲーションバーで、[開発] > [データ開発] を選択します。
上部メニューで、[プロジェクト] を選択します。Dev-Prod モードの場合は、[環境] も選択します。
左側のナビゲーションペインで、[標準化モデリング] > [ファクト論理テーブル] を選択します。
右側のファクト論理テーブル一覧で、
 新規アイコンをクリックします。
新規アイコンをクリックします。[ファクト論理テーブルの作成] ダイアログボックスで、パラメーターを設定します。
パラメータ
説明
[ビジネスアクティビティ]
ファクト論理テーブルを作成するビジネスアクティビティを選択します。ビジネスアクティビティには、[ビジネスイベント]、[ビジネススナップショット]、[ビジネスプロセス] の 3 種類があります。
[テーブルタイプ]
ビジネスアクティビティのタイプによって、論理テーブルのタイプが決まります。
[ビジネスアクティビティ] を [ビジネスイベント] に、[テーブルタイプ] を [イベントファクト論理テーブル] に設定します。
[ビジネスアクティビティ] は [ビジネススナップショット] に設定され、[テーブルタイプ] は [スナップショットファクト論理テーブル] です。
[ビジネスアクティビティ] は [ビジネスプロセス] に設定され、[テーブルタイプ] は [プロセスファクト論理テーブル] です。
[データドメイン]
ビジネスアクティビティのデータドメインがデフォルトで設定されます。このパラメータは変更できません。
[サブジェクトドメイン]
ビジネスアクティビティのサブジェクトドメインがデフォルトで設定されます。このパラメータは変更できません。
コンピューティング[エンジン]
お使いの Dataphin インスタンスが Hadoop コンピュートエンジンを使用している場合、Hive、Impala、Spark などのコンピュートエンジンを選択できます。
重要コンピュートエンジンを選択する前に、有効化する必要があります。詳細については、「Hadoop コンピュートソースの作成」をご参照ください。
コンピュートエンジンには次の制限があります。
Hive:Kudu 形式で保存されたソーステーブルは読み取れません。
Impala:Kudu 形式で保存されたソーステーブルを読み取れますが、論理テーブルを Kudu に保存することはサポートされていません。Kudu 形式のソーステーブルがない場合は、Impala の使用は推奨しません。
Spark:Kudu 形式で保存されたソーステーブルは読み取れません。
[データ適時性]
本番環境における後続のファクト論理テーブルタスクのスケジューリングタイプを定義します。[オフライン T+1] (日次タスク)、[オフライン T+h] (時間単位のタスク)、または [オフライン T+m] (分単位のタスク) を選択できます。
説明ArgoDB、StarRocks、SelectDB、および Doris コンピューティングエンジンは、オフラインの [T+1] (日次テーブル) のみをサポートします。
[論理テーブル名]
論理テーブルの名前を入力します。名前は最大 100 文字です。ビジネスオブジェクトを選択すると、システムは次の形式に基づいてテーブル名を自動的に設定します:
{data_domain_name}.fct_{business_object_code}_{data_timeliness_suffix}。重要名前には、英字、数字、アンダースコア (_) のみを使用できます。英字で始まる必要があります。名前は大文字と小文字を区別せず、大文字は自動的に小文字に変換されます。
label_はシステムで予約されたプレフィックスです。識別子はlabel_で始めることはできません。AnalyticDB for PostgreSQL のテーブル名は 50 文字を超えることはできません。
{data_timeliness_suffix}は、データ適時性の設定によって異なります。di:T+1 の接尾辞、日次増分。当日の増分データを保存します。
hi:T+h の接尾辞、時間単位増分。現在の時間の増分データを保存します。
thi:T+h の接尾辞、時間単位増分。00:00 から現在の時間までの増分データを保存します。
mi:T+m の接尾辞、分単位増分。15 分ごとに、直近 15 分間の増分データをパーティションに保存します。
tmi:T+m の接尾辞、分単位増分。15 分ごとに、00:00 から現在の分までの増分データを保存します。
df/da:T+1 の接尾辞、日次フル。当日までのすべての履歴データを保存します。
hf:T+h の接尾辞、時間単位フル。現在の時間までのすべての履歴データを保存します。
mf:T+m の接尾辞、分単位フル。最新の 15 分間隔までのすべての履歴データを保存します。
[表示名]
表示名は、次のルールに従ってください。
日本語、英字、数字、アンダースコア (_)、ハイフン (-) を使用できます。
64 文字を超えることはできません。
[説明]
ファクト論理テーブルの簡単な説明を入力します (最大 1,000 文字)。
[OK] をクリックします。
ステップ 2: テーブルスキーマの設定
[テーブル構造] タブで、パラメーターを設定します。
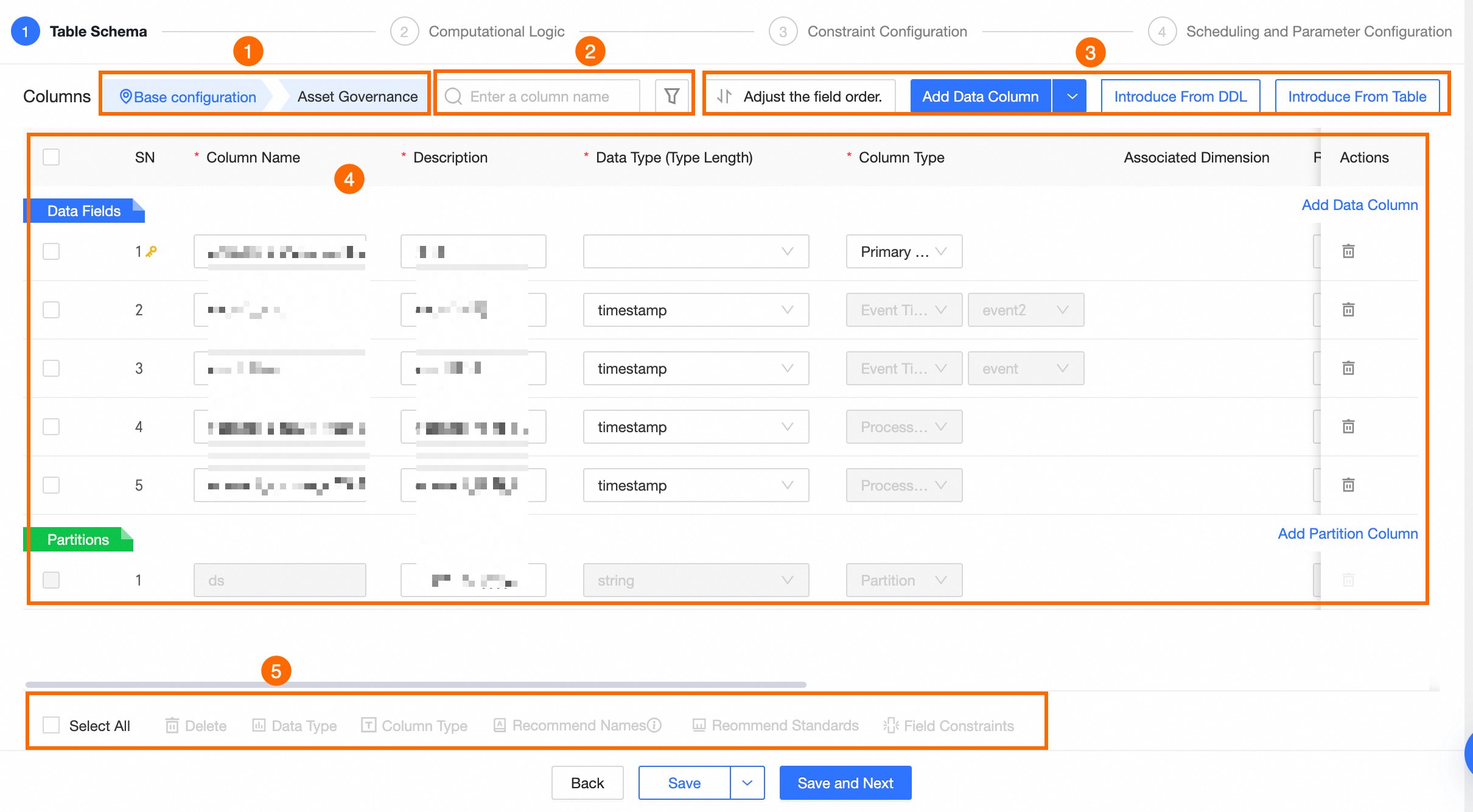
エリア
説明
① **テーブルフィールドロケーター**
クリックして、フィールドリストの[基本設定]または[データガバナンス]に移動します。
① **検索とフィルターエリア**
名前でフィールドを検索できます。
 をクリックして、[データ型]、[フィールドカテゴリ]、[関連ディメンションあり]、[関連ディメンション]、[フィールド制約]、または [データ秘密度レベル] でフィールドをフィルタリングします。
をクリックして、[データ型]、[フィールドカテゴリ]、[関連ディメンションあり]、[関連ディメンション]、[フィールド制約]、または [データ秘密度レベル] でフィールドをフィルタリングします。② **リスト操作**
[フィールド順序の調整]: フィールドの順序を変更する前に、データエラーを避けるため、この論理テーブルを参照する下流のコンシューマーで
select *クエリが使用されていないことを確認してください。[フィールドのインポート]: テーブルに新しいフィールドをインポートします。 [DDL ステートメントからインポート] または [テーブルからインポート] を使用できます。 詳細については、「ファクト論理テーブルにフィールドをインポートする」をご参照ください。
[フィールドの追加]: [データフィールド] または [パーティションフィールド] を追加します。フィールドの [名前]、[説明]、[データ型]、[フィールドカテゴリ]、[関連ディメンション]、[フィールド標準]、[フィールド制約]、[データ分類]、[データ機密度レベル]、および [備考] を設定できます。
説明MaxCompute エンジンでは、最大 6 レベルのパーティションフィールドを作成できます。
ArgoDB、StarRocks、SelectDB、Doris コンピュートエンジンは、パーティションフィールドの追加をサポートしていません。
③ **フィールドリスト**
フィールドリストには、各フィールドの [番号]、[フィールド名]、[説明]、[データ型]、[フィールドカテゴリ]、[関連ディメンション]、[フィールド標準]、[フィールド制約]、[データ分類]、[データ機密度レベル]、[備考] などの詳細情報が表示されます。
[シリアル番号]: テーブルフィールドのシリアル番号です。新しいフィールドが追加されると、自動的に 1 ずつ増加します。
[フィールド名]:フィールドの名前。フィールド名またはキーワードを入力すると、システムが標準のプリセットフィールド名と自動的に照合します。
[注]: テーブルフィールドの説明は 512 文字に制限されています。
[データ型]:[文字列]、[Bigint]、[Double]、[Timestamp]、[Decimal]、[テキスト]、[数値]、[日付/時刻]、および [その他] に対応しています。
[フィールドカテゴリ]: [プライマリキー]、[パーティション]、または [属性] に設定できます。
説明プライマリキーフィールドは 1 つのみ許可されます。
string、varchar、bigint、int、tinyint、または smallint 型のフィールドのみをパーティションフィールドとして使用できます。
[関連ディメンション]:詳細については、「関連ディメンションを追加する」をご参照ください。
[フィールド標準]:フィールドのデータ標準を選択します。 データ標準を作成するには、「データ標準の作成と管理」をご参照ください。
[フィールド制約]: フィールドの制約を選択します。[一意] と [非 NULL] の制約がサポートされています。
[データ分類]:フィールドのデータ分類を選択します。 データ分類を作成するには、「新しいデータ分類を作成する」をご参照ください。
[データ機密度レベル]:データ分類を選択すると、システムがデータ機密度レベルを自動的に識別します。
[説明]:フィールドの説明を入力します。最大長は 2048 文字です。
「操作」列の[削除]でフィールドを削除することもできます。
説明フィールドの削除は元に戻すことができません。
④ **バッチ操作**
複数のフィールドを選択して、次のバッチ操作を実行できます。
[削除]:
 アイコンをクリックして、選択したすべてのデータフィールドを削除します。
アイコンをクリックして、選択したすべてのデータフィールドを削除します。[データ型]:
 アイコンをクリックして、選択したデータ型を一括変更します。
アイコンをクリックして、選択したデータ型を一括変更します。[フィールドカテゴリ]:
アイコンをクリックして、選択したフィールドのカテゴリを一括変更します。[Radix ベースの命名]:
 アイコンをクリックします。 システムは、フィールドの[説明]の内容をトークン化し、トークンを既存の Radix と照合して、フィールド名を推奨します。 [Radix ベースの命名]ダイアログボックスで、選択したフィールドの名前を変更後の値に置き換えることができます。 次の図に示すように:説明
アイコンをクリックします。 システムは、フィールドの[説明]の内容をトークン化し、トークンを既存の Radix と照合して、フィールド名を推奨します。 [Radix ベースの命名]ダイアログボックスで、選択したフィールドの名前を変更後の値に置き換えることができます。 次の図に示すように:説明推奨名が不適切な場合は、[修正後のフィールド名] 入力ボックスで変更できます。
[リセット] をクリックすると、[変更後のフィールド名] がシステム推奨名に元に戻ります。
[フィールド標準]:
 アイコンをクリックします。 システムがフィールド名に基づいてフィールド標準を推奨します。 [フィールド標準] ダイアログボックスで、フィールドを推奨フィールド標準に設定できます。
アイコンをクリックします。 システムがフィールド名に基づいてフィールド標準を推奨します。 [フィールド標準] ダイアログボックスで、フィールドを推奨フィールド標準に設定できます。[フィールド制約]:
 アイコンをクリックして、フィールド制約を一括設定します。重要
アイコンをクリックして、フィールド制約を一括設定します。重要サブディメンション論理テーブルでは、フィールド制約はサポートされていません。
[保存して次へ] をクリックします。
フィールドのインポート
テーブルからインポート
ファクト論理テーブルの設定ページで、[テーブルからインポート] をクリックします。
[テーブルからインポート] ダイアログボックスで、[ソーステーブル] を選択し、追加するフィールドを選択します。
パラメータ
説明
[ソーステーブル]
読み取り権限のある、現在のテナント内の任意の物理テーブル (Dataphin によって自動生成されたものを除く)、論理テーブル、またはビュー (パラメータ化されたビューを除く) を選択できます。
物理テーブルの読み取り権限を取得するには、「テーブル権限の申請、更新、返却」をご参照ください。
[フィールドリスト]
追加するフィールドを選択します。
説明ソーステーブルを切り替えることで、複数のソーステーブルからフィールドを選択できます。
[選択されたフィールド]
追加されたフィールドは、選択されたフィールドリストに表示されます。このリストからフィールドを[削除]できます。
[追加] をクリックして、物理テーブルからファクト論理テーブルにフィールドをインポートします。
フィールドが[新規フィールド]エリアに追加されると、必要に応じて、それらの名前、データ型、カテゴリ、および関連ディメンションを編集できます。
DDL ステートメントからインポート
メジャーフィールドのソースは、ファクト論理テーブルにプライマリキーが定義されているかどうかによって異なります。プライマリキーが定義されている場合、メジャーフィールドはプライマリソーステーブルからのみ選択できます。プライマリキーが定義されていない場合、メジャーフィールドはプライマリソーステーブルと他のデータテーブルの両方から選択できます。
ファクト論理テーブルの設定ページで、[DDL ステートメントからインポート] をクリックします。
[DDL ステートメントからインポート] ダイアログボックスで、DDL ステートメントを入力し、[SQL を解析] をクリックします。
フィールドリストで必要なフィールドを選択し、[追加] をクリックしてファクト論理テーブルに新しいフィールドを作成します。
関連ディメンションの追加
ファクト論理テーブルのファクト属性内の外部キーフィールドをディメンションと関連付けることができます。
ファクト論理テーブルの設定ページで、
 アイコンをクリックして、**[モデル関係の編集]** ダイアログボックスを開きます。
アイコンをクリックして、**[モデル関係の編集]** ダイアログボックスを開きます。[モデルリレーションシップ編集] ダイアログボックスで、パラメーターを設定します。
エリア
パラメータ
説明
[Null 置換値]
ファクト論理テーブルの外部キーフィールドがディメンションテーブルと結合できない場合、システムは[デフォルト値の設定]を -110 に設定します。
[関連ディメンション]
[関連エンティティ]、[ディメンション論理テーブル]
既存の[関連エンティティ]と[ディメンション論理テーブル]を選択します。
[関連付けロジックの編集]
[関連付けロジック]
ファクト論理テーブルからフィールドを選択し、関連付けるディメンション論理テーブルのプライマリキーとの関係を設定します。
[ディメンションテーブルバージョンポリシー]
関連付けるディメンションテーブルのバージョン (パーティション) を選択します。デフォルトでは、システムはメインテーブルと同じサイクルのパーティションバージョンを使用します。
[不一致結合ポリシー]
不一致データポリシーでは、ソースメインテーブル (左テーブル) のデータがディメンション論理テーブル (右テーブル) に一致しない場合の処理方法を定義します。[一致しない元のデータを保持] と [一致しないデータをデフォルト値で置換] を選択できます。
[未一致の元データを保持]: 派生メトリックを作成する際に、左テーブルの元のデータを保持します。
[未結合のデータをデフォルト値に置き換える]: ディメンションテーブルのフィールドがファクト論理テーブルに関連付けられていない場合、デフォルト値 -110 が使用されます。
[ディメンションロールの編集]
[ロール名]、[表示名]
ディメンションロールは、ディメンションのエイリアスとして機能します。これにより、各ロールに一意の名前を定義すれば、1 つのディメンションで複数のロールを果たすことができます。[ロール英語名] と [ロール名] を定義する必要があります:
[ロール英語名] のプレフィックスはデフォルトで
dimとなり、カスタム部分の命名規則は次のとおりです。英字、数字、またはアンダースコア (_) を使用できます。
64 文字を超えることはできません。
[ロール名] の命名規則:
日本語、数字、英字、アンダースコア (_)、またはハイフン (-) を使用できます。
64 文字を超えることはできません。
[OK] をクリックします。
ステップ 3: 計算ロジックの設定
[計算ロジック] タブで、ソースデータとファクト論理テーブルのプライマリキーのマッピングを設定します。
[ソース設定] をクリックして [ソース設定] ダイアログボックスを開き、[ソース設定] ダイアログボックスでソースパラメーターを設定します。
説明フィルター条件やカスタム SQL に、イベント時刻のフィルターを追加しないでください。
プライマリキーのない論理テーブルでは、ソースを1つしか設定できません。複数のテーブルをソースとして使用するには、まずカスタム SQL を使用してそれらを結合する必要があります。
パラメータ
説明
[ソースタイプ]
サポートされているソースタイプは、[物理テーブル]、[カスタム SQL]、および[論理テーブル]です。
ソーステーブルタイプの説明:
プライマリキーを持つ論理テーブル: プライマリキーを持つ論理テーブルには、複数のソースを設定できます。最初のソースは常にメインソースであり、論理テーブルの合計行数を決定します。
プライマリキーを持たない論理テーブル: プライマリキーを持たない論理テーブルには、1 つのソースのみを設定できます。ソースが複数のテーブルで構成されている場合は、カスタム SQL を使用して事前に結合を実行してください。
説明複数のソースオブジェクトを設定するには、[ソースオブジェクトの追加] をクリックします。
[ソースオブジェクト]
[物理テーブル]: 現在のテナント内にある、読み取り権限のあるすべての物理テーブル (Dataphin によって自動生成されていないもの) および物理ビュー (パラメーター化されていないビュー) を選択できます。
物理テーブルの読み取り権限を取得するには、「テーブル権限の申請、更新、返却」をご参照ください。
[カスタム SQL] を選択し、
 アイコンをクリックして、編集ボックスに内容を入力します。例:
アイコンをクリックして、編集ボックスに内容を入力します。例:select id, name from project_name_dev.table_name1 t1 join project_name2_dev.table_name2 t2 on t1.id = t2.id[論理テーブル]: 現在のテナントで読み取り権限を持つすべての論理テーブルを選択できます。
論理テーブルの読み取り権限を取得するには、「テーブル権限の申請、更新、返却」をご参照ください。
重要論理テーブルを別の論理テーブルのデータソースとして使用すると、計算ロジックと運用・保守 (O&M) が複雑になります。このオプションは慎重に使用してください。
[オブジェクトエイリアス]
ソーステーブルのカスタムエイリアス (t1 や t2 など) を入力します。
[オブジェクトの説明]
オブジェクトの説明を入力します (最大 1,000 文字)。
[フィルター条件]
アイコンをクリックして、エディタにコンテンツを入力します。例:ds=${bizdate} and condition1=value1カスタム SQL にはフィルター条件がありません。
[結合フィールド]
ソースオブジェクト内のフィールドのうち、論理テーブルのプライマリキーに対応し、等結合に使用できるフィールドです。
[削除]
メインソースは削除できません。
プライマリキーのない論理テーブルの場合、ソースを削除すると、すべてのフィールドの計算ロジックがクリアされます。
[OK] をクリックしてソース設定を完了します。
ソースを設定した後、ソースフィールドを計算ロジックにドラッグします。
また、[同名フィールドをマップ] をクリックして、同名のソースデータフィールドと論理テーブルフィールドを自動的にマッピングすることもできます。
 アイコンをクリックして、エディタで計算ロジック式を編集します。sum、count、min などの集約関数は使用できません。例:
アイコンをクリックして、エディタで計算ロジック式を編集します。sum、count、min などの集約関数は使用できません。例:例 1:
substr(t1.column2, 3, 10)例 2:
case when t1.column2 != '1' then 'Y' else 'N' end例 3:
t1.column2 + t2.column1
下部の
 アイコンをクリックして、式を検証します。
アイコンをクリックして、式を検証します。[SQL プレビュー] をクリックすると、計算ロジックの SQL が表示されます。
[保存して次へ] をクリックします。
ステップ 4: 制約の設定
フィールド制約に基づいて、システムはデータ品質モジュールに現在の論理テーブルの品質ルールを作成します。各フィールドのルールの強度を強または弱に設定できます。詳細については、「データテーブル品質ルール」をご参照ください。
[保存して次へ] をクリックします。
ステップ 5: スケジューリングとパラメータの設定
[スケジューリングとパラメーター設定] タブで、ファクト論理テーブルの[データ遅延]、[スケジューリングプロパティ]、[上流の依存関係]、[パラメーター設定]、および[ランタイム設定]を設定します。
パラメータ
説明
データレイテンシ
データ遅延を有効にすると、システムは [最大遅延日数] の期間内に、この論理テーブルのすべてのデータを自動的に再実行します。 詳細については、「論理テーブルのデータ遅延を設定する」をご参照ください。
スケジューリングプロパティ
本番環境でのファクト論理テーブルのスケジューリング方法を設定します。スケジューリングタイプ、サイクル、ロジック、実行を設定できます。詳細については、「論理テーブルのスケジューリングプロパティの設定」をご参照ください。
アップストリーム依存関係
Dataphin は、設定されたスケジューリング依存関係に従って、ビジネスプロセス内のノードを実行します。これにより、ビジネスデータが効率的かつタイムリーに生成されるようになります。詳細については、「論理テーブルのアップストリーム依存関係の設定」をご参照ください。
パラメータ設定
コードで使用される変数に値を割り当てることで、ノードスケジューリング中にパラメーター変数が対応する値に自動的に置き換えられるようになります。 パラメーター設定ページでは、パラメーターを [無視] するか、[グローバル変数に変換] することができます。 詳細については、「論理テーブルのパラメーターを設定する」をご参照ください。
ランタイム設定
タスクレベルのランタイムタイムアウトと、タスクが失敗した場合の再試行ポリシーを設定できます。これにより、長時間実行されるタスクによるリソースの浪費を防ぎ、コンピュートタスクの信頼性を向上させます。詳細については、「論理テーブルのランタイム設定」をご参照ください。
論理テーブルタスクのスケジューリングリソースグループを設定できます。タスクがスケジュールされると、このグループのリソースクォータを消費します。設定の詳細については、「論理テーブルリソース設定」をご参照ください。
ステップ 6: 論理テーブルの保存と送信
ファクト論理テーブルの設定後、**[保存して送信]** をクリックします。システムは、[テーブル構造]、[計算ロジック]、[スケジューリング依存関係]、および [ランタイムパラメータ] の設定を検証します。設定が検証に失敗した場合は、[チェック結果] を使用してエラーを見つけて修正してください。
すべてのチェックに合格したら、送信メモを入力し、**[OK して送信]** をクリックします。
タスクを送信すると、Dataphin はそのデータリネージを分析し、送信チェックを実行します。詳細については、「標準化モデリングタスク送信手順」をご参照ください。
シングルテナント向けのマルチエンジン
テーブルからインポートメソッドを使用してフィールドリストを設定する場合、同じエンジンタイプのプロジェクトからのみテーブルをインポートできます。
ソーステーブルでは、現在のプロジェクトと同じクラスターにあるプロジェクトからのみテーブルを選択できます。
次のステップ
プロジェクトモードが開発-本番の場合、論理テーブルを本番環境に公開します。詳細については、「リリース タスクの管理」 をご参照ください。
論理テーブルを本番環境に公開した後、O&M センターでそのタスクを表示および管理します。詳細については、「O&M センター」 をご参照ください。