Prometheus モニタリングを統合して、ACK クラスターのコントロールプレーン、ノード、アプリケーションのメトリックを収集し、視覚的なダッシュボードとリアルタイムアラートでクラスターのパフォーマンス管理を向上させます。
バージョンの選択
Managed Service for Prometheus は、オープンソースの Prometheus エコシステムと完全に統合され、フルマネージドのモニタリングサービスを提供します。このサービスは、データストレージ、データの可視化、システムの O&M などの基盤となる問題を管理します。
Pro Edition (推奨): メトリックを 90 日間保存し、フルマネージドのコレクターを提供します。このエディションは、本番環境グレードのサービスレベルアグリーメント (SLA) 99.95% を提供します。また、カスタマイズ可能な Grafana ダッシュボードと、さまざまな Container Service コンポーネント用に事前設定されたアラートルールも含まれています。
Basic Edition: メトリックを 7 日間保存し、基本的なモニタリングダッシュボードのみを提供します。コレクターはご自身でメンテナンスする必要があります。
Prometheus モニタリングの有効化
既存のクラスターでモニタリングを有効にする
(オプション) ACK 専用クラスターの場合、まずクラスターにモニタリングポリシーの権限付与を行う必要があります。
クラスターページで、対象クラスターの名前をクリックします。クラスター詳細ページの左側のナビゲーションウィンドウで、 を選択します。
[Prometheus モニタリング] ページで、コンテナ監視バージョンを選択し、[インストール] をクリックします。
モニタリングを有効にすると、デフォルトの基本メトリックが自動的に収集されます。カスタムメトリックの収集の詳細については、「カスタムメトリックの収集」をご参照ください。このページでは、[クラスターモニタリングの概要]、[ノードモニタリング]、[アプリケーションモニタリング]、[ネットワークモニタリング]、[ストレージモニタリング] など、いくつかの事前設定されたモニタリングダッシュボードも表示できます。
クラスター作成時にモニタリングを有効にする
ACK マネージドクラスター Pro Edition:
[コンポーネント設定] ページの [コンテナ監視] セクションで、コンテナクラスターモニタリング Pro Edition または コンテナクラスターモニタリング Basic Edition を選択します。詳細については、「ACK マネージドクラスターの作成」をご参照ください。
スマートホスティングの自動モードでは、コンテナ監視 Basic Edition がデフォルトで有効になります。
ACK マネージドクラスター Basic Edition、ACS クラスター、および Serverless Kubernetes クラスター:
クラスター作成ウィザードの [コンポーネント設定] ページの [コンテナ監視] セクションで、[Managed Service For Prometheus を使用] を選択してコンテナ監視 Basic Edition をインストールします。
モニタリングを有効にすると、デフォルトの基本メトリックが自動的に収集されます。カスタムメトリックを収集するには、「カスタムメトリックの収集」をご参照ください。対象クラスターの詳細ページの左側のナビゲーションウィンドウで、 を選択します。その後、[クラスターモニタリングの概要]、[ノードモニタリング]、[アプリケーションモニタリング]、[ネットワークモニタリング]、[ストレージモニタリング] などの事前設定されたモニタリングダッシュボードを表示できます。
アラート通知の設定
主要なメトリックに対してアラートルールを設定できます。異常が発生した場合、メール、ショートメッセージ、DingTalk などのチャンネルを通じて通知が自動的に送信されます。
ARMS コンソールにログインします。左側のナビゲーションウィンドウで、 を選択します。
[通知受信者] ページで、通知方法を選択し、アラート通知受信者を作成します。
ARMS コンソールの左側のナビゲーションウィンドウで、 を選択します。
[Prometheus アラートルール] ページで、[Prometheus アラートルールの作成] をクリックします。
詳細については、「Prometheus アラートルールの設定」をご参照ください。
カスタムモニタリングメトリックの収集
Prometheus モニタリングは、リクエスト QPS や処理レイテンシなど、カスタムメトリックを収集するいくつかの方法をサポートしています。詳細については、「コンテナ環境のカスタム収集ルールの管理」をご参照ください。
Prometheus モニタリングの無効化
対象クラスターの詳細ページの左側のナビゲーションウィンドウで、[コンポーネント管理] をクリックします。
[コンポーネント管理] ページで、[ログとモニタリング] タブをクリックします。[ack-arms-prometheus] コンポーネントを見つけて、[アンインストール] をクリックします。表示されるダイアログボックスで、[OK] をクリックします。
課金
クラスターサイズに基づくモニタリング料金: Basic Edition は無料です。Pro Edition は、クラスター内のノード数に基づいて従量課金で請求されます。
Prometheus インスタンス料金: 基本メトリックの収集は無料です。カスタムメトリックの収集は、データ書き込み、データレポート、ストレージボリューム、保持期間などの要因に基づいて従量課金で請求されます。
詳細な課金ルールと価格については、「コンテナ監視の課金」をご参照ください。
デフォルトの基本メトリック
Prometheus モニタリング機能が有効になると、コンテナ監視の基本メトリックが自動的に収集されます。基本メトリックの詳細については、「メトリックの説明」をご参照ください。
コンテナーの基本的なリソース監視 (kubelet)。
クラスターのアプリケーション状態監視 (kube-state-metrics)。
クラスターノードの基本的なリソース監視 (node-exporter)。
クラスターノードの GPU 監視 (ack-gpu-exporter)。
マネージドクラスターのコントロールプレーンコンポーネントモニタリング機能は、API Server、etcd、kube-scheduler、kube-controller-manager、および cloud-controller-manager のメトリックを監視します。
クラスター CoreDNS の基本的なモニタリングメトリック。
クラスター Ingress-Controller の基本的なモニタリングメトリック。
特定の機能を有効にした後に自動的にレポートされる基本メトリック:
コンテナストレージモニタリングの概要を有効にすると、csi-plugin コンポーネントのメトリックがレポートされます。
コストインサイト機能を有効にすると、ack-cost-exporter コンポーネントのメトリックがレポートされます。
複数タイプのワークロードのコロケーションモニタリングとリソースプロファイルを有効にすると、ack-koordinator コンポーネントのメトリックがレポートされます。
よくある質問
Prometheus モニタリングページに「関連するモニタリングダッシュボードが見つかりません」と表示される
Prometheus モニタリングを有効化し、対象クラスターの ページに [関連するモニタリングダッシュボードが見つかりません] というメッセージが表示された場合は、以下の手順に従って問題を解決してください。
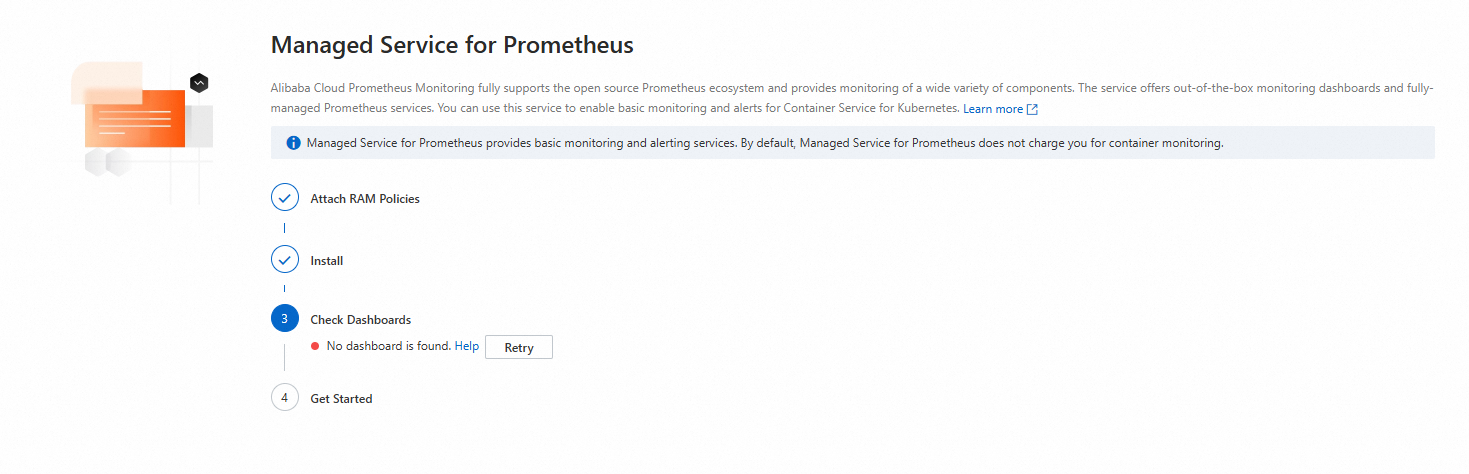
Prometheus モニタリングコンポーネントを再インストールします。
コンポーネントを再インストールします:
アンインストールが完了したことを確認した後、[インストール] をクリックし、ダイアログボックスで [OK] をクリックします。
インストールが完了したら、Prometheus モニタリングページに戻り、問題が解決したかどうかを確認します。
問題が解決しない場合は、次のステップに進みます。
Prometheus インスタンスの接続を確認します。
ARMS コンソールの左側のナビゲーションウィンドウで、[プロビジョニング] をクリックします。
[接続された環境] タブで、[コンテナ環境] リストでクラスターと同じ名前のコンテナ環境を確認します。
対応するコンテナ環境が存在しない場合: 「ARMS または Prometheus コンソールを使用して接続する」をご参照ください。
コンテナ環境がある場合は、対象環境の [アクション] 列の [プローブ設定] をクリックして [プローブ設定] ページを開きます。
インストールされているエージェントが期待どおりに実行されているかどうかを確認します。
メトリックの保存期間を調整するにはどうすればよいですか?
詳細については、「メトリックの保存期間の調整」をご参照ください。
ack-arms-prometheus コンポーネントのバージョンを表示するにはどうすればよいですか?
クラスターページで、対象クラスターの名前をクリックします。左側のナビゲーションウィンドウで、[コンポーネント管理] をクリックします。
[コンポーネント管理] ページで、[ログとモニタリング] タブをクリックし、[ack-arms-prometheus] コンポーネントを見つけます。
現在のバージョンがコンポーネントの下に表示されます。新しいバージョンが利用可能な場合は、バージョン番号の横にある [アップグレード] をクリックします。
説明[アップグレード] オプションは、インストールされているコンポーネントが最新バージョンでない場合にのみ使用できます。
GPU モニタリングをデプロイできないのはなぜですか?
GPU ノードに Taint がある場合、GPU モニタリングのデプロイメントが失敗することがあります。以下の手順を実行して、GPU ノードの Taint を表示できます。
次のコマンドを実行して、対象の GPU ノードの Taint を表示します。
GPU ノードにカスタム Taint がある場合、Taint 関連のエントリを見つけることができます。このトピックでは、
キーがtest-key、値がtest-value、効果がNoScheduleの Taint を例として使用します。kubectl describe node cn-beijing.47.100.***.***想定される出力:
Taints:test-key=test-value:NoSchedule次のいずれかの方法で GPU ノードの Taint を処理します。
次のコマンドを実行して、GPU ノードから Taint を削除します。
kubectl taint node cn-beijing.47.100.***.*** test-key=test-value:NoSchedule-GPU ノードの Taint に対して Toleration を宣言し、Taint のあるノードに Pod をスケジュールできるようにします。
# 1. 次のコマンドを実行して ack-prometheus-gpu-exporter を編集します。 kubectl edit daemonset -n arms-prom ack-prometheus-gpu-exporter # 2. YAML ファイルに次のフィールドを追加して、Taint に対する Toleration を宣言します。 # 他のフィールドは省略されています。 # tolerations フィールドは containers フィールドの上に追加され、containers フィールドと同じレベルにあります。 tolerations: - key: "test-key" operator: "Equal" value: "test-value" effect: "NoSchedule" containers: # 他のフィールドは省略されています。
ARMS-Prometheus を手動で完全に削除するにはどうすればよいですか?
Managed Service for Prometheus の名前空間のみを削除すると、残りの設定が保持され、再インストールが失敗する可能性があります。以下の操作を実行して、残りの ARMS-Prometheus 設定を完全に削除できます。
arms-prom 名前空間を削除します。
kubectl delete namespace arms-promClusterRoles を削除します。
kubectl delete ClusterRole arms-kube-state-metrics kubectl delete ClusterRole arms-node-exporter kubectl delete ClusterRole arms-prom-ack-arms-prometheus-role kubectl delete ClusterRole arms-prometheus-oper3 kubectl delete ClusterRole arms-prometheus-ack-arms-prometheus-role kubectl delete ClusterRole arms-pilot-prom-k8s kubectl delete ClusterRole gpu-prometheus-exporter kubectl delete ClusterRole o11y:addon-controller:role kubectl delete ClusterRole arms-aliyunserviceroleforarms-clusterroleClusterRoleBinding を削除します。
kubectl delete ClusterRoleBinding arms-node-exporter kubectl delete ClusterRoleBinding arms-prom-ack-arms-prometheus-role-binding kubectl delete ClusterRoleBinding arms-prometheus-oper-bind2 kubectl delete ClusterRoleBinding arms-kube-state-metrics kubectl delete ClusterRoleBinding arms-pilot-prom-k8s kubectl delete ClusterRoleBinding arms-prometheus-ack-arms-prometheus-role-binding kubectl delete ClusterRoleBinding gpu-prometheus-exporter kubectl delete ClusterRoleBinding o11y:addon-controller:rolebinding kubectl delete ClusterRoleBinding arms-kube-state-metrics-agent kubectl delete ClusterRoleBinding arms-node-exporter-agent kubectl delete ClusterRoleBinding arms-aliyunserviceroleforarms-clusterrolebindingRole と RoleBinding を削除します。
kubectl delete Role arms-pilot-prom-spec-ns-k8s kubectl delete Role arms-pilot-prom-spec-ns-k8s -n kube-system kubectl delete RoleBinding arms-pilot-prom-spec-ns-k8s kubectl delete RoleBinding arms-pilot-prom-spec-ns-k8s -n kube-system
Helm を使用して Managed Service for Prometheus をアンインストールするにはどうすればよいですか?
Helm を使用してサービスを手動でデプロイした場合、または環境や Helm のバージョンの問題で残存リソースが残っている場合は、この方法でサービスをアンインストールする必要があります。
クラスターページで、対象クラスターの名前をクリックします。クラスター詳細ページの左側のナビゲーションウィンドウで、 を選択します。
[Helm] ページで、arms-prometheus コンポーネントを見つけ、[アクション] 列の [削除] をクリックします。次に、[リリースレコードのパージ] を選択し、プロンプトに従ってアプリケーションを削除します。
ack-arms-prometheus コンポーネントのインストール時に「xxx in use」エラーが発生する
クラスターページで、対象クラスターの名前をクリックします。クラスター詳細ページの左側のナビゲーションウィンドウで、 を選択します。
[Helm] ページで、ack-arms-prometheus が存在することを確認します。
[Helm] ページから ack-arms-prometheus を削除し、[コンポーネント管理] ページで再インストールします。詳細については、「コンポーネントの管理」をご参照ください。
見つからない場合:
ack-arms-prometheusが見つからない場合は、ack-arms-prometheusHelm Release の削除によって残存リソースが残っていることを示します。その場合は、ARMS-Prometheus を手動で完全に削除する必要があります。
「コンポーネントがインストールされていません」というメッセージが表示された後、ack-arms-prometheus コンポーネントのインストールに失敗する
ack-arms-prometheus コンポーネントがすでにインストールされているかどうかを確認します。
クラスターページで、対象クラスターの名前をクリックします。クラスター詳細ページの左側のナビゲーションウィンドウで、 を選択します。
[Helm] ページで、ack-arms-prometheus が存在することを確認します。
[Helm] ページから ack-arms-prometheus を削除し、[コンポーネント管理] ページで再インストールします。詳細については、「コンポーネントの管理」をご参照ください。
見つからない場合:
ack-arms-prometheusが見つからない場合は、ack-arms-prometheusHelm Release の削除によって残存リソースが残っていることを示します。その場合は、ARMS-Prometheus を手動で完全に削除する必要があります。
ack-arms-prometheus のログにエラーがないか確認します。
クラスター詳細ページの左側のナビゲーションウィンドウで、 を選択します。
[ステートレス] ページの上部で、[名前空間] を [arms-prom] に設定し、arms-prometheus-ack-arms-prometheus をクリックします。
[ログ] タブをクリックし、ログにエラーがないか確認します。
エージェントのインストール中にエラーが発生したかどうかを確認します。
ARMS コンソールにログインします。左側のナビゲーションウィンドウで、[プロビジョニング] をクリックします。
[接続された環境] タブで、[コンテナ環境] リストから対象のコンテナ環境を見つけます。[アクション] 列で、[プローブ設定] をクリックして [プローブ設定] ページを開きます。
ACK 専用クラスターにモニタリング権限を付与するにはどうすればよいですか?
クラスターページで、対象クラスターの名前をクリックします。左側のナビゲーションウィンドウで、[クラスター情報] をクリックします。
[基本情報] タブで、[ワーカー RAM ロール] の右側にある [KubernetesWorkerRole-***] リンクをクリックします。RAM ロールページで、[権限管理] タブをクリックします。[アクセスポリシー] 列で、[k8sWorkerRole****] をクリックします。
アクセスポリシー詳細ページで、[ポリシードキュメント] タブをクリックし、[ポリシードキュメントの編集] をクリックします。
スクリプトエディターで、[Statement] フィールドに次の権限付与ルールを追加し、[OK] をクリックします。
{ "Version": "1", "Statement": [ { "Action": [ "arms:Describe*", "arms:List*", "arms:Get*", "arms:Search*", "arms:Check*", "arms:Query*", "arms:ListEnvironments", "arms:DescribeAddonRelease", "arms:InstallAddon", "arms:DeleteAddonRelease", "arms:ListEnvironmentDashboards", "arms:ListAddonReleases", "arms:CreateEnvironment", "arms:UpdateEnvironment", "arms:InitEnvironment", "arms:DescribeEnvironment", "arms:InstallEnvironmentFeature", "arms:ListEnvironmentFeatures", "cms:CreateIntegrationPolicy", "cms:ListAddonReleases", "cms:UpdateAddonRelease", "cms:CreateAddonRelease", "cms:GetPrometheusInstance", "cms:ListIntegrationPolicyStorageRequirements" ], "Resource": "*", "Effect": "Allow" } ] }
関連ドキュメント
Alibaba Cloud Prometheus Monitoring を Basic Edition から Pro Edition にアップグレードする。