Container Service for Kubernetes (ACK) は、Kubernetes ネイティブのワークロード向けにリソースプロファイリングを提供します。この機能は、過去のリソース使用量データを分析し、コンテナレベルのリソース仕様に関する推奨事項を提示することで、コンテナの requests と limits の設定プロセスを簡素化します。このトピックでは、コンソールおよびコマンドラインでリソースプロファイリング機能を使用する方法について説明します。
前提条件と使用上の注意
-
この機能は、以下の要件を満たす ACK Pro クラスター でのみ使用できます。
-
ack-koordinator コンポーネント (旧 ack-slo-manager) v0.7.1 以降がインストールされていること。詳細については、「ack-koordinator」をご参照ください。
-
metrics-server コンポーネント v0.3.8 以降がインストールされていること。
-
ノードがコンテナランタイムとして containerd を使用しており、かつ 2022 年 1 月 19 日 14:00 より前にクラスターに追加された場合は、ノードを再追加するか、クラスターを最新バージョンにアップグレードする必要があります。詳細については、「既存ノードの追加」および「クラスターの手動アップグレード」をご参照ください。
-
-
リソースプロファイリング機能は、コストスイートでパブリックプレビュー版として提供されており、直接使用できます。
-
正確なプロファイリング結果を得るために、ワークロードに対してリソースプロファイリングを有効にした後、少なくとも 24 時間待機することを推奨します。これにより、システムが十分なデータを収集できるようになります。
課金
ack-koordinator コンポーネントのインストールおよび使用は無料です。ただし、以下のシナリオでは追加料金が発生する場合があります。
-
ack-koordinator は自己管理コンポーネントです。インストール後、ワーカーノードのリソースを消費します。コンポーネントのインストール時に、各モジュールのリソースリクエストを設定できます。
-
デフォルトでは、ack-koordinator は、リソースプロファイリングやきめ細かいスケジューリングなどの機能のモニタリングメトリクスを Prometheus 形式で公開します。 [ACK-Koordinator の Prometheus モニタリングを有効化] オプションを有効にし、Managed Service for Prometheus を使用する場合、これらのメトリクスは 基本メトリクスとして Managed Service for Prometheus に送信されます。デフォルトの保持期間などのデフォルト設定を変更すると、追加料金が発生する場合があります。詳細については、「Managed Service for Prometheus の課金」をご参照ください。
リソースプロファイリング
Kubernetes では、リソースリクエストを使用してコンテナのリソース要件を記述します。コンテナにリソースリクエストを設定すると、スケジューラーはそのリクエストとノードの割り当て可能なリソースをマッチングし、Pod をノードにスケジュールします。ほとんどの場合、リソースリクエストは経験に基づいて設定されます。管理者は過去の使用率、負荷テスト結果、本番環境のフィードバックを確認し、時間をかけて値を調整します。
しかし、このアプローチには以下の制限があります。
-
本番アプリケーションを安定させるため、管理者は上流および下流の依存関係におけるトラフィック変動に対処するために、大きなリソースバッファーを確保することがよくあります。その結果、コンテナのリソースリクエストは実際の使用量よりもはるかに高く設定されます。これにより、クラスターのリソース使用率が低下し、大幅なリソースの浪費につながります。
-
クラスターの割り当て率が高い場合、管理者はクラスターの使用率を向上させ、より多くの容量を確保するために、リソースリクエストを削減することがあります。これにより、コンテナ密度が増加し、アプリケーションのトラフィックが増加した際にクラスターの安定性に影響を与える可能性があります。
これらの問題に対処するため、ack-koordinator はリソースプロファイリング機能を提供します。この機能は、コンテナレベルのリソース仕様を推奨することで、コンテナ設定の複雑さを軽減します。ACK はこの機能をコンソールで提供しており、アプリケーション管理者は現在のリソース仕様が適切かどうかを迅速に評価し、必要に応じて調整できます。また、コマンドラインを使用して、CRD を通じてアプリケーションのリソースプロファイルを直接管理することもできます。
コンソールでのリソースプロファイリング
ステップ 1: リソースプロファイリングのインストールと有効化
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
-
コスト最適化モード ページで、リソースプロファイル タブをクリックします。リソースプロファイル セクションで、画面の指示に従って機能を有効にします。
-
コンポーネントのインストールまたはアップグレード: 画面の指示に従って、ack-koordinator コンポーネントをインストールまたはアップグレードします。この機能を初めて使用する場合は、ack-koordinator コンポーネントをインストールする必要があります。
説明ack-koordinator コンポーネントのバージョンが v0.7.0 より前の場合は、移行とアップグレードを実行する必要があります。詳細については、「ack-koordinator をアプリケーションマーケットプレイスからコンポーネントセンターへ移行する」をご参照ください。
-
プロファイリング設定: インストールまたはアップグレード後、デフォルトの設定 を選択してプロファイリング範囲を制御できます (推奨)。また、後からコンソールでプロファイリング設定をクリックして設定を調整することもできます。
-
-
プロファイリングを有効化する をクリックして リソースプロファイル ページに移動します。
ステップ 2: プロファイリングポリシーの管理
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
-
コスト最適化モード ページで、リソースプロファイル タブをクリックし、次に プロファイルの設定 をクリックします。
設定モードは フル設定 と [自動 O&M モード] の 2 種類から選択できます。コンポーネントのインストール時に推奨されるデフォルトのモードは、グローバル設定モードです。ここでモードとパラメーターを変更し、OK をクリックして変更を適用できます。
グローバル設定 (推奨)
グローバル設定モードでは、すべてのワークロードに対してリソースプロファイリングが有効になります。デフォルトでは、arms-prom および kube-system 名前空間が除外されます。
パラメータ
説明
設定可能な値
[除外された名前空間]
リソースプロファイリングが無効になっている名前空間。通常、システムコンポーネント用の名前空間が該当します。最終的なプロファイリング範囲は、指定された名前空間とワークロードタイプの積集合となります。
現在のクラスター内の既存の名前空間。複数の名前空間を選択できます。デフォルト値: kube-system および arms-prom。
[有効化するロードタイプ]
リソースプロファイリングが有効になっているワークロードタイプ。最終的なプロファイリング範囲は、指定された名前空間とワークロードタイプの積集合となります。
サポートされている Kubernetes ネイティブワークロードは、Deployment、StatefulSet、および DaemonSet です。複数のワークロードタイプを選択できます。
[CPU 消費の冗長性]
リソースプロファイリング結果を生成するための安全バッファー。詳細については、以下の説明をご参照ください。
非負の数値。一般的なオプションは 70%、50%、30% です。
[メモリ消費の冗長性]
リソースプロファイリング結果を生成するための安全バッファー。詳細については、以下の説明をご参照ください。
非負の数値。一般的なオプションは 70%、50%、30% です。
自動 O&M 設定
自動 O&M モードでは、選択した名前空間内のワークロードに対してのみリソースプロファイリングが有効になります。クラスターが大規模 (例: 1,000 ノード以上) な場合、または一部のワークロードでのみこの機能を試したい場合は、このモードを使用して必要に応じて範囲を指定してください。
パラメータ
説明
設定可能な値
[名前空間を有効化する]
リソースプロファイリングが有効になっている名前空間。最終的なプロファイリング範囲は、指定された名前空間とワークロードタイプの積集合となります。
現在のクラスター内の既存の名前空間。複数の名前空間を選択できます。
[有効化するロードタイプ]
リソースプロファイリングが有効になっているワークロードタイプ。最終的なプロファイリング範囲は、指定された名前空間とワークロードタイプの積集合となります。
サポートされている Kubernetes ネイティブワークロードは、Deployment、StatefulSet、および DaemonSet です。複数のワークロードタイプを選択できます。
[CPU 消費の冗長性]
リソースプロファイリング結果を生成するための安全バッファー。詳細については、以下の説明をご参照ください。
非負の数値。一般的なオプションは 70%、50%、30% です。
[メモリ消費の冗長性]
リソースプロファイリング結果を生成するための安全バッファー。詳細については、以下の説明をご参照ください。
非負の数値。一般的なオプションは 70%、50%、30% です。
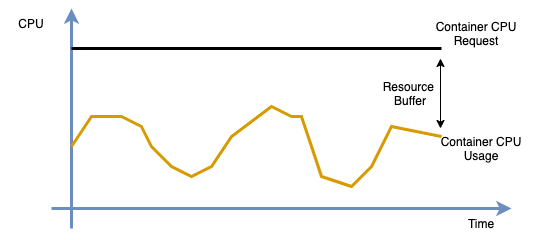
リソース消費バッファーとは、管理者がアプリケーションの容量 (Queries Per Second (QPS) など) を評価する際に、物理リソースを 100% は使用しないという慣例のことです。これは、ハイパースレッディングなどの物理リソースの制限と、ピーク期間中の負荷リクエストを処理するためにアプリケーションがリソースを予約する必要があるためです。プロファイル値と元のリソースリクエストの差が安全バッファーを超える場合、ダウングレードが推奨されます。アルゴリズムの詳細については、「アプリケーションプロファイリングの概要」トピックのプロファイリング推奨事項の説明をご参照ください。
ステップ 3: プロファイリング概要の表示
リソースプロファイリングポリシーを設定すると、リソースプロファイル ページで、各ワークロードのリソースプロファイリングの結果を表示できます。
精度を向上させるため、この機能を初めて使用する際は、少なくとも 24 時間のデータを収集するよう、システムからプロンプトが表示されます。
以下の表は、プロファイリング概要の列について説明しています。
以下の表では、ハイフン (-) はそのフィールドが該当しないことを示します。
|
列 |
説明 |
値 |
フィルタリング可能 |
|
ワークロード名 |
ワークロードの名前。 |
- |
はい。ページ上部で名前による完全一致検索を実行できます。 |
|
名前空間 |
ワークロードの名前空間。 |
- |
はい。デフォルトでは、kube-system 名前空間はフィルター条件から除外されます。 |
|
ワークロードタイプ |
ワークロードのタイプ。 |
Deployment、DaemonSet、StatefulSet。 |
はい。デフォルトのフィルターは「すべて」です。 |
|
CPU リクエスト |
ワークロード Pod の CPU リソースリクエスト。 |
- |
いいえ。 |
|
メモリリクエスト |
ワークロード Pod のメモリリソースリクエスト。 |
- |
いいえ。 |
|
プロファイルデータステータス |
ワークロードのリソースプロファイリングステータス。 |
|
いいえ。 |
|
CPU プロファイル、メモリプロファイル |
プロファイル値、元のリソースリクエスト、および設定されたリソース消費バッファーに基づく推奨事項。 |
アップグレード、ダウングレード、維持が含まれます。パーセンテージは偏差の大きさを示し、次の式を使用して計算されます: |
はい。デフォルトのフィルター条件は「アップグレード」と「ダウングレード」です。 |
|
作成時刻 |
プロファイリング結果が作成された時刻。 |
- |
いいえ。 |
|
リソース設定の変更 |
プロファイリング結果と推奨事項を評価した後、リソースの変更設定 をクリックしてリソースをアップグレードまたはダウングレードします。 詳細については、「ステップ 5: 推奨されるリソース仕様を適用する」をご参照ください。 |
- |
いいえ。 |
ACK リソースプロファイリングは、ワークロード内の各コンテナのリソース仕様に対してプロファイル値を生成します。プロファイル値 (Recommend)、元のリソースリクエスト (Request)、およびプロファイリングポリシーで設定されたリソース消費バッファー (Buffer) を比較することで、コンソールはリソースリクエストに対するアップグレードまたはダウングレードの推奨事項を提供します。ワークロードに複数のコンテナがある場合、コンソールは最も大きな偏差を持つコンテナを強調表示します。計算ロジックは以下のとおりです。
-
プロファイル値 (Recommend) が元のリソースリクエスト (Request) より大きい場合、コンテナは長期間にわたってリソースを過剰に使用しています (使用量がリクエストを超えています)。これは安定性に関するリスクが生じます。リソース仕様を速やかに増やす必要があります。コンソールには「アップグレード」の推奨事項が表示されます。
-
プロファイル値 (Recommend) が元のリソースリクエスト (Request) より小さい場合、コンテナはリソースを浪費している可能性があり、リソース仕様を削減できます。この判断の際には、設定されたリソース消費バッファーを考慮する必要があります。
-
プロファイル値と設定されたリソース消費バッファー (Buffer) に基づいて、ターゲットリソース仕様 (Target) を計算します:
Target = Recommend * (1 + Buffer)。 -
元のリソースリクエスト (Request) とターゲットリソース仕様 (Target) の偏差 (Degree) を計算します:
Degree = 1 - (Request / Target)。 -
プロファイル値と偏差レベル (Degree) に基づいて、コンソールは CPU とメモリに関する推奨事項を生成します。偏差 (Degree) の絶対値が 0.1 より大きい場合、コンソールには「ダウングレード」の推奨事項が表示されます。
-
-
それ以外の場合、推奨事項は現在のリソース仕様を [現状維持] することであり、調整は不要であることを示します。
ステップ 4: アプリケーションプロファイルの詳細表示
リソースプロファイル ページでワークロード名をクリックすると、そのプロファイル詳細ページが開きます。
詳細ページは、基本的なワークロード情報、各コンテナのリソースプロファイル曲線、およびアプリケーションのリソース仕様を変更するためのウィンドウの3つの部分で構成されています。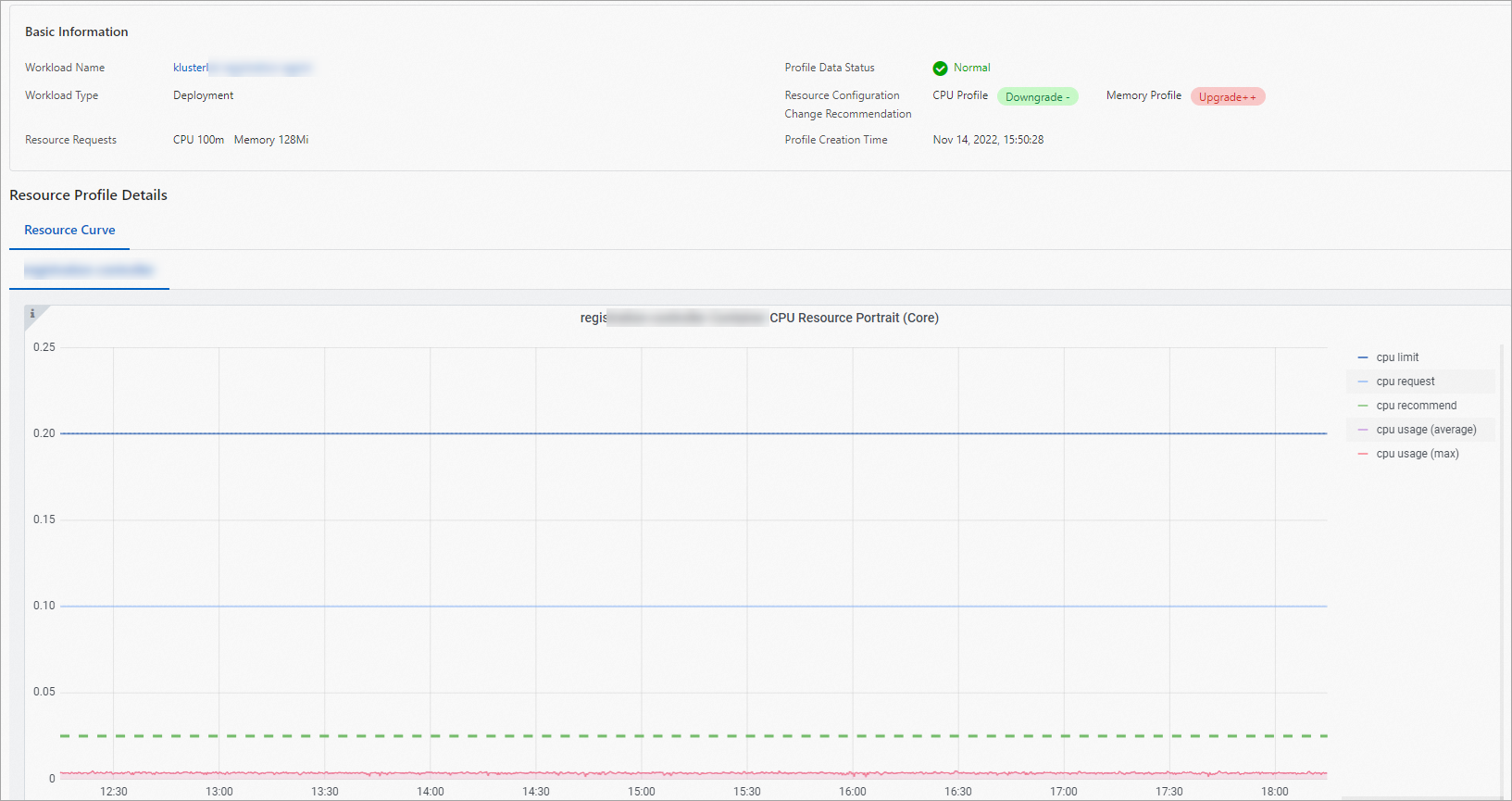
上図に示すように、次の表は、CPU を例として、リソース曲線のメトリクスについて説明しています。
|
曲線名 |
説明 |
|
CPU limit |
コンテナの CPU リソース制限。 |
|
CPU request |
コンテナの CPU リソースリクエスト。 |
|
CPU recommend |
コンテナのプロファイル CPU 値。 |
|
CPU usage (average) |
ワークロード内のすべてのコンテナレプリカにわたる平均 CPU 使用量。 |
|
CPU usage (max) |
ワークロード内のすべてのコンテナレプリカの中での最大 CPU 使用量。 |
ステップ 5: 推奨されるリソース仕様の適用
設定された安全バッファーをターゲットリソース要件の参考として使用できます。たとえば、プロファイル値にバッファー係数を追加できます (例: 4.742 * 1.3 ≈ 6.2)。
次の表は、パラメータについて説明しています。
|
パラメータ |
説明 |
|
現在のリソースリクエスト |
コンテナの現在のリソースリクエスト。 |
|
現在のリソース制限 |
コンテナの現在のリソース制限。 |
|
プロファイル値 |
コンテナに対して生成されたプロファイル値。リソースリクエストの参考として使用できます。 |
|
安全バッファー |
プロファイリングポリシーで設定された安全バッファー。ターゲットリソース要件の参考として使用できます。たとえば、プロファイル値にバッファー係数を追加できます (例: 4.742 * 1.3 ≈ 6.2)。 |
|
新しいリソースリクエスト |
コンテナリソースリクエストのターゲット値。 |
|
新しいリソース制限 |
コンテナリソース制限のターゲット値。注: ワークロードが CPU トポロジ対応スケジューリングを使用する場合、CPU リソース制限は整数である必要があります。 |
設定が完了したら、送信 をクリックします。システムによってリソース仕様が更新され、ワークロード詳細ページに自動的にリダイレクトされます。
リソース仕様が更新されると、コントローラーはワークロードのローリングアップデートを実行し、その Pod を再作成します。
コマンドラインからのリソースプロファイリング
手順1:リソースプロファイリングの有効化
-
ワークロードのリソースプロファイリングを有効にするには、次の内容で
recommendation-profile.yamlという名前のファイルを作成します。RecommendationProfile CRD は、ワークロードのリソースプロファイリングを有効にし、そのコンテナのリソース仕様データを提供します。名前空間とワークロードタイプを指定することで、プロファイリング範囲を制御できます。最終的な範囲は、この2つの積集合となります。
apiVersion: autoscaling.alibabacloud.com/v1alpha1 kind: RecommendationProfile metadata: # オブジェクト名。クラスター スコープのため名前空間は不要です。 name: profile-demo spec: # リソースプロファイリングを有効にするワークロードタイプ。 controllerKind: - Deployment # リソースプロファイリングを有効にする名前空間。 enabledNamespaces: - default次の表で、各設定フィールドについて説明します。
パラメーター
タイプ
説明
metadata.nameString
オブジェクトの名前。RecommendationProfile はクラスター スコープ (非名前空間) オブジェクトであるため、名前空間は不要です。
spec.controllerKindString
リソースプロファイリングを有効にするワークロードのタイプ。サポートされているワークロードタイプには、Deployment、StatefulSet、DaemonSet があります。
spec.enabledNamespacesString
リソースプロファイリングを有効にする名前空間。
-
プロファイルの設定を適用します。
kubectl apply -f recommendation-profile.yaml -
次の内容で
cpu-load-gen.yamlという名前のファイルを作成します。apiVersion: apps/v1 kind: Deployment metadata: name: cpu-load-gen labels: app: cpu-load-gen spec: replicas: 2 selector: matchLabels: app: cpu-load-gen-selector template: metadata: labels: app: cpu-load-gen-selector spec: containers: - name: cpu-load-gen image: registry.cn-zhangjiakou.aliyuncs.com/acs/slo-test-cpu-load-gen:v0.1 command: ["cpu_load_gen.sh"] imagePullPolicy: Always resources: requests: cpu: 8 # このアプリケーションの CPU リクエストは 8 コアです。 memory: "1Gi" limits: cpu: 12 memory: "2Gi" -
cpu-load-gen アプリケーションをデプロイします。
kubectl apply -f cpu-load-gen.yaml -
リソースプロファイリングの結果を取得します。
kubectl get recommendations -n default -l \ "alpha.alibabacloud.com/recommendation-workload-apiVersion=apps-v1, \ alpha.alibabacloud.com/recommendation-workload-kind=Deployment, \ alpha.alibabacloud.com/recommendation-workload-name=cpu-load-gen" -o yamlack-koordinator は、プロファイリング対象の各ワークロードのリソースプロファイルを生成し、結果を Recommendation CRD に保存します。以下は、
cpu-load-genワークロードのリソースプロファイルのサンプルです。apiVersion: autoscaling.alibabacloud.com/v1alpha1 kind: Recommendation metadata: labels: alpha.alibabacloud.com/recommendation-workload-apiVersion: apps-v1 alpha.alibabacloud.com/recommendation-workload-kind: Deployment alpha.alibabacloud.com/recommendation-workload-name: cpu-load-gen name: f20ac0b3-dc7f-4f47-b3d9-bd91f906**** namespace: default spec: workloadRef: apiVersion: apps/v1 kind: Deployment name: cpu-load-gen status: recommendResources: containerRecommendations: - containerName: cpu-load-gen target: cpu: 4742m memory: 262144k originalTarget: # リソースプロファイリングアルゴリズムの中間結果。直接使用しないでください。 # ...取得を簡素化するため、Recommendation オブジェクトはワークロードと同じ名前空間に作成されます。また、次の表に示すように、ワークロードの API バージョン、タイプ、名前を指定するラベルも含まれます。
ラベルキー
説明
例
alpha.alibabacloud.com/recommendation-workload-apiVersionワークロードの API バージョン。Kubernetes ラベル構文に準拠するため、スラッシュ (/) はハイフン (-) に置き換えられます。
apps-v1 (apps/v1 から)
alpha.alibabacloud.com/recommendation-workload-kindDeployment や StatefulSet など、ワークロードのタイプ。
Deployment
alpha.alibabacloud.com/recommendation-workload-nameワークロードの名前。Kubernetes ラベル構文に準拠するため、63 文字以下である必要があります。
cpu-load-gen
各コンテナのリソースプロファイリング結果は、
status.recommendResources.containerRecommendationsに保存されます。次の表で、各フィールドについて説明します。フィールド
説明
形式
例
containerNameコンテナの名前。
String
cpu-load-gen
targetプロファイリングによる推奨リソース仕様 (CPU とメモリを含む)。
map[ResourceName]resource.Quantity
cpu: 4742m
memory: 262144k
originalTargetリソースプロファイリングアルゴリズムの中間結果。このフィールドは直接使用しないでください。
-
-
説明Pod あたりにプロファイリングで推奨される最小 CPU 値は 0.025 コア、最小メモリ値は 250 MB です。
cpu-load-genアプリケーションで定義されているリソース仕様とプロファイリング結果を比較すると、CPU リクエストが過剰にプロビジョニングされていることがわかります。リクエストを削減して、クラスターのリソースを節約できます。カテゴリー
元の仕様
プロファイリングによる推奨仕様
CPU
8 コア
4.742 コア
手順2: (オプション) Prometheus による結果の表示
ack-koordinator コンポーネントは、リソースプロファイリング結果を取得するための Prometheus クエリインターフェイスを提供します。ACK の Prometheus モニタリング機能を使用して、これらの結果を直接表示できます。
-
このダッシュボードを初めて使用する場合は、リソースプロファイル ダッシュボードが最新バージョンに更新されていることを確認してください。アップグレード手順については、「関連操作」をご参照ください。
Prometheus モニタリングを使用して ACK コンソールでリソースプロファイリング結果を表示するには、次の手順に従ってください。
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
-
Prometheus 監視 ページで、 を選択します。
リソースプロファイル タブで、コンテナ仕様 (Request)、実際のコンテナリソース使用量 (Usage)、プロファイルされたコンテナリソース仕様 (Recommend) などの詳細なデータを表示できます。詳細については、「Managed Service for Prometheus への接続と設定」をご参照ください。
-
セルフマネージド Prometheus インスタンスをお持ちの場合は、次のメトリックに基づいてダッシュボードを設定してください。
# ワークロード内コンテナの、プロファイリングによる推奨CPUリソース仕様。 koord_manager_recommender_recommendation_workload_target{exported_namespace="$namespace", workload_name="$workload", container_name="$container", resource="cpu"} # ワークロード内コンテナの、プロファイリングによる推奨メモリリソース仕様。 koord_manager_recommender_recommendation_workload_target{exported_namespace="$namespace", workload_name="$workload", container_name="$container", resource="memory"}重要ack-koordinator コンポーネントが提供するリソースプロファイリングのメトリックは、v1.5.0-ack1.14 で
koord_manager_recommender_recommendation_workload_targetに名前が変更されました。ただし、以前のバージョンのメトリックslo_manager_recommender_recommendation_workload_targetは引き続き互換性があります。セルフマネージド Prometheus インスタンスをお持ちの場合は、ack-koordinator コンポーネントを v1.5.0-ack1.14 以降にアップグレードした後、koord_manager_recommender_recommendation_workload_targetに切り替えてください。
よくある質問
リソースプロファイリングアルゴリズム
リソースプロファイリングアルゴリズムは、多次元データモデルを使用しており、次のように機能します。
-
コンテナのリソース使用量データを継続的に収集し、ピーク値、加重平均、CPU およびメモリ使用率のパーセンタイルなどの集計統計を計算します。
-
最終的な推奨では、CPU の推奨値を P95 パーセンタイルに、メモリの推奨値を P99 パーセンタイルに設定します。 アルゴリズムは、ワークロードの信頼性を確保するために、両方にセーフティマージンを追加します。
-
アルゴリズムは適時性を重視して最適化されており、直近 14 日間のデータのみを考慮します。 集計には半減期スライディングウィンドウモデルを使用し、古いデータポイントの重みが徐々に減少する仕組みです。
-
アルゴリズムは、プロファイル値の精度を向上させるために、メモリ不足 (OOM) によるキルなどのコンテナランタイムイベントを考慮します。
適切なアプリケーションタイプ
リソースプロファイリングは、オンラインサービスアプリケーションに最適です。
現在、プロファイリング結果では、コンテナが使用サンプルの大部分をカバーできる十分なリソースを確保することを優先しています。 しかし、このアプローチは、特定のアプリケーションタイプにとっては過度に保守的となる場合があります。 全体的なスループットを優先し、クラスター使用率を向上させるためにある程度のリソース競合を許容できるバッチ処理タスクなどのオフラインアプリケーションでは、プロファイリング結果が過度に保守的に見えることがあります。 さらに、アクティブ/パッシブ構成でデプロイされた重要なシステムコンポーネントの場合、パッシブレプリカは長期間アイドル状態であり、その低いリソース使用量がプロファイリングアルゴリズムに影響を与える可能性があります。 これらのシナリオでは、適用する前に必要に応じてプロファイリング結果を確認し、調整してください。 リソースプロファイリングの製品アップデートに関する最新情報を常に確認することを推奨します。
requests と limits へのプロファイル値の使用
これは、特定のワークロードによって異なります。 プロファイル値は、アプリケーションの現在のリソース需要の概要を示すものです。 これらをベースラインとして使用し、アプリケーションの特性とビジネス要件に基づいて調整する必要があります。
たとえば、トラフィックスパイクへの対応や、アクティブ/アクティブアーキテクチャでのシームレスなフェイルオーバーが必要なアプリケーションでは、リソースバッファーを追加する必要があります。 また、高負荷のホストでは正常に動作しない、リソースの影響を受けやすいアプリケーションの場合も、プロファイル値を超えてリソース割り当てを増やす必要があります。
セルフマネージド Prometheus でのメトリックの表示
ack-koordinator コンポーネントの ack-koord-manager モジュールは、リソースプロファイリングのメトリックを Prometheus 形式の HTTP エンドポイントとして公開します。 Pod の IP アドレスを取得し、メトリックデータにアクセスできます。
-
Pod の IP アドレスを取得します。
kubectl get pod -A -o wide | grep koord-manager出力例:
kube-system ack-koord-manager-b86bd47d9-92f6m 1/1 Running 0 16h 10.10.0.xxx cn-hangzhou.10.10.0.xxx <none> <none> kube-system ack-koord-manager-b86bd47d9-vg5z7 1/1 Running 0 16h 10.10.0.xxx cn-hangzhou.10.10.0.xxx <none> <none> -
次のコマンドを実行してメトリクスデータを表示します (なお、ack-koord-manager はデュアルレプリカのアクティブ/パッシブモードで実行され、データはプライマリレプリカの Pod でのみ利用可能です)。ポート
port(デフォルト: 9326) については、ack-koord-manager の Deployment 設定をご参照ください。コマンドを実行するサーバーが、クラスターのコンテナネットワークと通信できることを確認してください。
curl -s http://10.10.0.xxx:9326/all-metrics | grep slo_manager_recommender_recommendation_workload_target # ack-koordinator v1.5.0-ack1.12 より前のバージョンを使用している場合は、次のコマンドを実行してメトリックデータを表示します。 curl -s http://10.10.0.xxx:9326/metrics | grep slo_manager_recommender_recommendation_workload_target出力例:
# HELP slo_manager_recommender_recommendation_workload_target ワークロードのリソースリクエストの推奨値 # TYPE slo_manager_recommender_recommendation_workload_target gauge slo_manager_recommender_recommendation_workload_target{container_name="xxx",namespace="xxx",recommendation_name="d2169dbf-fb36-4bf4-99d1-673577fb85c1",resource="cpu",workload_api_version="apps/v1",workload_kind="Deployment",workload_name="xxx"} 0.025 slo_manager_recommender_recommendation_workload_target{container_name="xxx",namespace="xxx",recommendation_name="d2169dbf-fb36-4bf4-99d1-673577fb85c1",resource="memory",workload_api_version="apps/v1",workload_kind="Deployment",workload_name="xxx"} 2.62144e+08
ack-koordinator コンポーネントがインストールされると、対応する Pod に関連付けられた Service および ServiceMonitor オブジェクトが自動的に作成されます。 Managed Service for Prometheus を使用する場合、サービスはこれらのメトリックを自動的に収集し、対応する Grafana ダッシュボードに表示します。
Prometheus は複数の収集方法をサポートしています。 セルフマネージド Prometheus インスタンスを使用している場合は、設定について公式の Prometheus ドキュメントを参照し、デバッグには上記の手順を使用してください。 デバッグ後、「手順 2: (オプション) Prometheus で結果を表示する」を参照して、お使いの環境で Grafana ダッシュボードを設定できます。
プロファイリング結果とルールの削除
Recommendation CRD はプロファイリング結果を保存し、RecommendationProfile CRD はプロファイリングルールを保存します。 次のコマンドを実行して、すべての結果とルールを削除します。
# すべてのプロファイリング結果を削除します。
kubectl delete recommendation -A --all
# すべてのプロファイリングルールを削除します。
kubectl delete recommendationprofile -A --allRAM ユーザーへの権限付与
ACK の認可には、基本的なリソースアクセス用の RAM 認可と、クラスター内の権限用の RBAC (ロールベースのアクセス制御) の 2 つの層があります。 概要については、「認可のベストプラクティス」をご参照ください。 RAM ユーザーにリソースプロファイリングを使用する権限を付与するには、両方のレベルで権限を設定する必要があります。
-
RAM 認可
Alibaba Cloud アカウントで RAM コンソールにログインし、AliyunCSFullAccess 組み込みシステムポリシーを RAM ユーザーに付与してください。 詳細な手順については、「権限の付与」をご参照ください。
-
RBAC 認可
RAM 認可が完了したら、ターゲットクラスターで RAM ユーザーに
developerロール以上を付与してください。 手順については、「RBAC を使用してクラスターリソースに対する操作を認可する」をご参照ください。
事前定義された developer ロールは、クラスター内のすべての Kubernetes リソースへの読み取りおよび書き込みアクセスを許可します。 よりきめ細かな制御を行うには、「カスタム RBAC ロールを使用してクラスター内のリソース操作を制限する」に記載の手順に従って、カスタム ClusterRole を作成または編集できます。 リソースプロファイリング機能では、ClusterRole に次のルールを追加する必要があります。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: recommendation-clusterrole
rules:
- apiGroups:
- "autoscaling.alibabacloud.com"
resources:
- "*"
verbs:
- "*"