Managed Service for Prometheus は、Prometheus マネージドサービスとコンテナ監視サービスを提供します。コンテナ監視サービスには、監視クラスター規模料金と Prometheus インスタンス料金を含むコンテナ監視料金が発生します。コンテナ監視サービスには、Basic 版と Pro 版の 2 つのバージョンがあります。このトピックでは、コンテナ監視 Pro 版の操作、課金の詳細、特徴、サポートされるダッシュボード、およびデフォルトのアラートルールについて説明します。
Pro 版をサポートするクラスタータイプ
ACK マネージド Pro クラスター
ACK Lingjun クラスター
ACK 専用クラスター
前提条件
コンテナ監視 Pro 版には Managed Service for Prometheus が必要です。まず Managed Service for Prometheus (書き込みボリュームによる従量課金 有効化リンク、レポートボリュームによる従量課金 有効化リンク) を有効化し、次に コンテナ監視 Pro 版を有効化する必要があります。
コンテナ監視 Pro 版の課金の詳細
課金項目 | 課金の説明 | 課金方法 | 課金サイクル |
監視クラスター規模料金 | OCU 使用量はコンテナクラスターのノード規模に基づいて計算され、10 クラスターノードごとに 1 OCU に変換されます。 説明 OCU: Observability Capacity Unit は、Alibaba Cloud Native Observability によって導入された新しい課金単位です。時間単位のリソース使用量に基づいて OCU 使用量を自動的に計算します。OCU の価格は 0.023 USD/ユニット です。 | 従量課金: 1 日あたりのコンテナクラスター規模料金 = 1 時間あたりの OCU ユニットの合計 × OCU 単価 説明 1 時間あたりの OCU ユニット = 現在の課金サイクルにおける最大ノード数 ÷ 10 (切り上げ) | 課金サイクルは 1 時間単位です。Managed Service for Prometheus は、00:00 以降、前日の各時間におけるクラスターノードの最大数を計算し、課金ルールに従って 1 時間あたりの OCU ユニットを計算し、1 時間あたりの OCU ユニットを累積して前日の合計 OCU 量を計算し、OCU 単価を乗じて、コンテナクラスター規模の監視料金を日次で生成します。 |
Prometheus インスタンス料金 | 詳細については、「Prometheus インスタンスの課金」をご参照ください。 | ||
コンテナ監視 Pro 版の使用方法
方法 1: 統合時にコンテナ監視 Pro 版を選択する
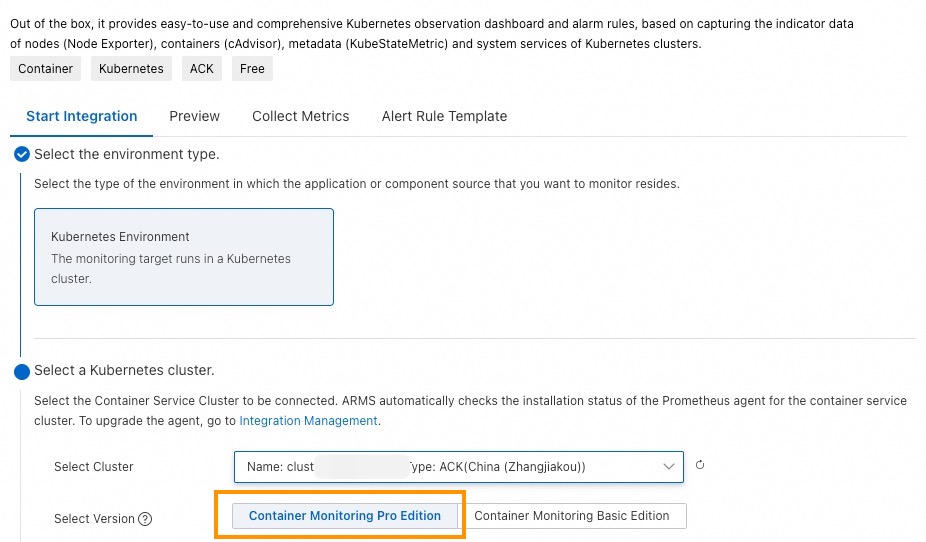
[インテグレーションセンター] ページで、[コンテナクラスターモニタリング] を選択します。
[コンテナクラスターモニタリング] パネルで、統合するコンテナサービスクラスターを選択し、バージョンとして [コンテナ監視 Pro 版] を選択して、[OK] をクリックします。
方法 2: Basic 版からコンテナ監視 Pro 版へのスペックアップ
コンテナ監視 Pro 版にスペックアップした後は、Basic 版にスペックダウンすることはできません。
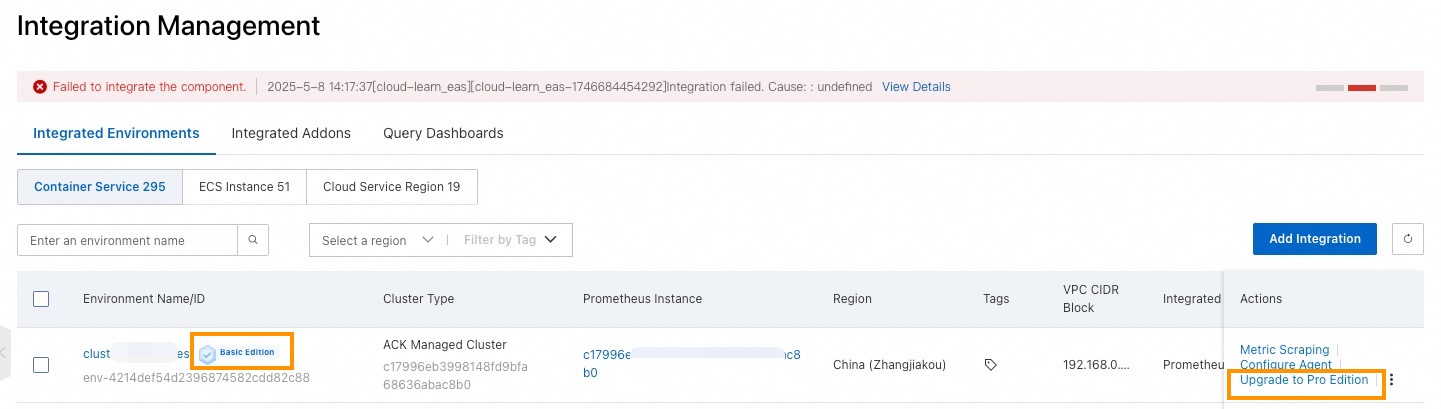
[プロビジョニング] ページで、[統合環境] > [コンテナ環境] を選択します。
スペックアップするコンテナ監視の [操作] 列にある [スペックアップ] をクリックします。ダイアログボックスで、[確認] をクリックします。
Basic 版と Pro 版の違い
カテゴリ | Basic 版 | Pro 版 |
コンテナクラスターの基本メトリック の保存期間 | 7 日間 | 90 日間 |
Prometheus コレクター | ユーザーのクラスターにデプロイされた Agent (デフォルトの単一レプリカは 3 コア、4 GB のクラスターリソースを占有) で、自己管理が必要です。 | マネージドコレクション Agent を提供し、ユーザーは Agent のリソースコストを負担する必要がなくなり、99.95% の本番レベルの SLA を提供します。 |
監視ダッシュボード | 基本的な監視ダッシュボードが組み込まれています。 | 包括的な監視ダッシュボードが組み込まれています。 |
コンテナ監視 Pro 版でサポートされるダッシュボード
タイプ | ダッシュボード名 |
監視の概要 | クラスター監視の概要 |
クラスター名前空間ダッシュボード | |
クラスターコアコンポーネント | ACK Pro APIサーバー |
ACK Pro ETCD | |
ACK Proスケジューラー | |
ACK Pro Cloud Controller Manager | |
ACK Pro Kube Controller Manager | |
ノード監視 | ノードプールの概要 |
クラスターノード監視の詳細 | |
アプリケーション監視 | ステートレスアプリケーション監視 |
ステートフルアプリケーション監視 | |
デーモンプロセスセットアプリケーション監視 | |
クラスター Pod 監視 | |
ネットワーク監視 | CoreDNS コンポーネント監視 |
クラスター Ingress トラフィック監視 | |
ストレージ監視 | CSI ストレージコンポーネント監視 - クラスターディメンション |
CSI ストレージコンポーネント監視 - ノードディメンション | |
Pod IOモニタリング(Podレベル) | |
フロントエンドストレージIOモニタリング(クラスターレベル) | |
GPU 監視 | クラスター GPU 監視 - クラスターディメンション |
クラスター GPU 監視 - ノードディメンション | |
クラスター GPU 監視 - アプリケーション Pod ディメンション | |
コスト分析/リソース最適化 | リソースプロファイル |
その他 | バックエンドストレージIOモニタリング(クラスターレベル) |
k8s-reclaimed-resource | |
クラスター Prometheus 自己監視 | |
仮想ノード(ECI)概要 |
デフォルトアラートルール
アラートルール名/ID | アラートグループ | テンプレート |
ノードの CPU 使用率が 75% を超える | ノード | ノード {{ $labels.instance }} の CPU 使用率が 75% を超えました。現在の CPU 使用率は {{ printf "%.2f" $value }}% です |
ノードの CPU 使用率が 85% を超える | ノード | ノード {{ $labels.instance }} の CPU 使用率が 85% を超えました。現在の CPU 使用率は {{ printf "%.2f" $value }}% です |
ノードのメモリ使用量が 75% を超える | ノード | ノード {{ $labels.instance }} のメモリ使用量が 75% を超えました。現在のメモリ使用量は {{ printf "%.2f" $value }}% です |
ノードのメモリ使用量が 85% を超える | ノード | ノード {{ $labels.instance }} のメモリ使用量が 85% を超えました。現在のメモリ使用量は {{ printf "%.2f" $value }}% です |
ノードの異常 | ノード | ノード {{$labels.node}} が 10 分以上利用不可の状態です |
ディスク使用率が 95% を超える | ノード | ノード {{ $labels.instance }} のディスク {{ $labels.device }} の使用率が 95% を超えました。現在のディスク使用率は {{ printf "%.2f" $value }}% です |
Deployment の Pod 可用性が 50% 未満 | ワークロード | 名前空間: {{$labels.namespace}} / Deployment: {{$labels.deployment}} の Pod 可用性が 50% 未満です。現在の利用不可 Pod 数は {{ $value }} です |
ジョブの実行に失敗しました | ワークロード | 名前空間: {{$labels.namespace}}/ジョブ: {{$labels.job_name}} の実行に失敗しました |
Pod の起動タイムアウト失敗 | ワークロード | 名前空間: {{$labels.namespace}}/Pod: {{$labels.pod_name}} が 15 分以上正常に起動していません。待機理由 {{$labels.reason}} |
Pod のステータス異常 | ワークロード | 名前空間: {{$labels.namespace}}/Pod: {{$labels.pod_name}} が 10 分以上 {{$labels.phase}} ステータスのままです |
Pod の頻繁な再起動 | ワークロード | 名前空間: {{$labels.namespace}}/Pod: {{$labels.pod_name}} が {{$labels.metrics_params_time}} 分以内に {{ $labels.metrics_params_value}} 回以上再起動しました。現在の再起動回数は {{ $value }} です |
コンテナの CPU 使用率が 85% を超える | ワークロード | 名前空間: {{$labels.namespace}} / Pod: {{$labels.pod_name}} / コンテナ: {{$labels.container}} の CPU 使用率が 85% を超えました。現在の値は {{ printf "%.2f" $value }}% です |
コンテナの CPU 使用率が 75% を超える | ワークロード | 名前空間: {{$labels.namespace}} / Pod: {{$labels.pod_name}} / コンテナ: {{$labels.container}} の CPU 使用率が 75% を超えました。現在の値は {{ printf "%.2f" $value }}% です |
コンテナのメモリ使用量が 75% を超える | ワークロード | 名前空間: {{$labels.namespace}} / Pod: {{$labels.pod_name}} / コンテナ: {{$labels.container}} のメモリ使用量が 75% を超えました。現在の値は {{ printf "%.2f" $value }}% です |
コンテナのメモリ使用量が 85% を超える | ワークロード | 名前空間: {{$labels.namespace}} / Pod: {{$labels.pod_name}} / コンテナ: {{$labels.container}} のメモリ使用量が 85% を超えました。現在の値は {{ printf "%.2f" $value }}% です |