このトピックでは、診断手順や一般的な問題の解決策など、Pod の問題のトラブルシューティング方法について説明します。
コンソールで Pod のステータス、基本情報、設定、イベント、ログの表示、ターミナルを使用したコンテナへのアクセス、Pod 診断の有効化など、一般的な Pod のトラブルシューティングタスクを実行するには、「一般的なトラブルシューティング手順」をご参照ください。
クイック診断手順
異常なワークロード Pod を診断するには、対象の ポッド の詳細ページに移動します。イベント タブをクリックして、異常なイベントの説明を確認します。次に、ログ タブをクリックして、最近の異常なログを確認します。
Pending 状態の Pod
Pod の ステータスの詳細 に Unschedulable ステータスが表示されるか、イベント に FailedScheduling イベントが表示される場合、 に移動して、対象ノードの正常性ステータスおよびリソース使用量(CPU およびメモリ)を確認します。また、Pod のアフィニティポリシーが厳しすぎるかどうかを確認し、nodeSelector、nodeAffinity、および Taint および Toleration の構成を含めます。問題のさらに詳しいトラブルシューティングについては、「スケジューリングの問題」をご参照ください。
イメージのプル失敗 (ImagePullBackOff/ErrImagePull)
ポッド 詳細ページで、コンテナー タブに移動し、イメージ アドレスを確認します。 Pod のノードにログオンし、crictl pull <image-address> または curl -v https://<image-address> を実行して、イメージリポジトリへのネットワーク接続を確認します。 右上隅で YAML の編集 をクリックし、ワークロードの spec.imagePullSecrets フィールドで指定されている Secret が存在し、有効であることを確認します。 詳細については、「イメージのプルに関する問題」をご参照ください。
Pod の起動失敗 (CrashLoopBackOff)
このエラーは、アプリケーションがクラッシュと再起動を繰り返す場合に発生します。ポッド 詳細ページで ログ タブをクリックし、最後のコンテナーが終了した時のログを表示する を選択すると、障害の原因を確認できます。詳細については、「Pod の起動失敗のトラブルシューティング」をご参照ください。
Pod は Running だが Ready ではない
このステータスは、Pod の readiness プローブが失敗した場合に発生します。 ターゲットの 編集 ページの ワークロード で、ヘルスチェックのリクエストパス (例: /healthz) とポートが アプリケーションで提供されているものと一致することを確認してください。 詳細については、「Pod は実行中ですが、準備ができていません (Ready: False)」をご参照ください。
一時的にヘルスチェックを無効にすることができます。その後、Pod ターミナルまたはそのホストノードにアクセスし、curl などのコマンドを使用してヘルスチェックが成功することを確認します。
Pod が OOMKilled される
ポッド 詳細ページで、ログ タブをクリックし、最後のコンテナーが終了した時のログを表示する を選択して OOM ログを表示します。アプリケーションにメモリリークまたはメモリ不足 (OOM) エラーがあるかどうかを確認します。Java アプリケーションの場合は、-Xmx パラメーターを最適化できます。必要に応じて、アプリケーションのメモリリソース制限 (resources.limits.memory) を調整します。詳細については、「OOMKilled」をご参照ください。
liveness プローブが設定されている場合、Pod は OOMKilled 状態に短時間留まった後、自動的に再起動します。
診断ワークフロー
異常な Pod を診断するには、そのイベント、ログ、設定を検査します。
フェーズ 1:スケジューリングの問題
Pod がノードにスケジュールされない
Pod が長期間 Pending 状態のままである場合、ノードにスケジュールされていません。このセクションでは、一般的な原因と解決策について説明します。
|
エラーメッセージ |
説明 |
ソリューション |
|
|
クラスターには Pod スケジューリングに利用できるノードがありません。 |
|
|
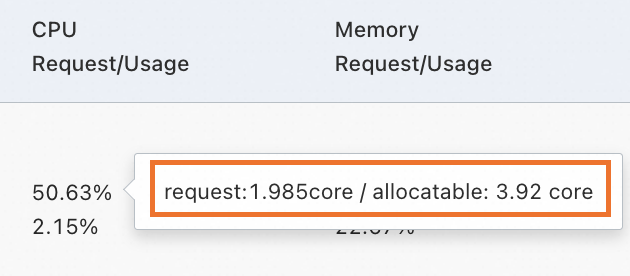
クラスター内に、Pod の CPU またはメモリリソースリクエストを満たすことができる利用可能なノードがありません。 実際の CPU またはメモリ使用率が低くても、割り当てられたリソースの
|
対象クラスターの詳細ページで、 に移動し、対象ノードの CPU またはメモリのリクエスト割り当て率を確認します。割り当て率にマウスを上に置くと、具体的なリソース割り当て値を表示できます。
ノードリソース使用量の詳細を表示するには、「kubectl を使用してノードのリソース使用量を確認する」をご参照ください。
|
|
|
クラスター内の既存のノードが、Pod に宣言されたノードアフィニティポリシー ( |
|
|
|
|
|
|
ボリュームのノードアフィニティの競合によりスケジューリングが失敗します。これは通常、クラウドディスクが異なるゾーン間でマウントできないために発生します。 |
|
|
|
ECS インスタンスは指定されたクラウドディスクタイプをサポートしていません。 |
ご利用の ECS インスタンスでサポートされているクラウドディスクタイプを確認するには、「インスタンスファミリー」をご参照ください。マウント時に、クラウドディスクタイプを ECS インスタンスでサポートされているものに更新します。 |
|
|
Pod は、ノードの Taint のいずれかに対する Toleration がないため、ノードにスケジュールできません。 |
|
|
|
ノードのエフェメラルストレージが不足しています。 |
|
|
|
Pod が永続ボリューム要求 (PVC) にバインドできませんでした。 |
Pod によって指定された PVC または PV が作成されているか確認します。 |
Pod はスケジュールされたが Pending のまま
Pod がノードにスケジュールされたが Pending 状態のままである場合は、次の手順に従って問題を解決します。
-
Pod が
hostPortで設定されているかどうかを判断します:Pod がhostPortで設定されている場合、そのhostPortを使用する Pod インスタンスは各ノードで 1 つしか実行できません。したがって、Deployment またはレプリケーションコントローラーのReplicasの値は、クラスター内のノード数を超えることはできません。このポートが別のアプリケーションで使用されている場合、Pod のスケジューリングは失敗します。hostPortは、いくつかの管理およびスケジューリングの複雑さを伴います。Pod にアクセスするには Service を使用することを推奨します。詳細については、「Service」をご参照ください。 -
Pod が
hostPortで設定されていない場合は、以下の手順でトラブルシューティングを行います。-
kubectl describe pod <pod-name>を実行して Pod のイベントを表示し、見つかった問題を解決します。イベントは、イメージのプル失敗、リソース不足、セキュリティポリシーの制限、設定エラーなど、Pod が起動に失敗した理由を説明できます。 -
イベントオブジェクトに有用な情報がない場合は、ノードの kubelet ログを確認して、Pod の起動プロセス中の問題をトラブルシューティングします。
grep -i <pod name> /var/log/messages* | lessコマンドを使用して、システムログファイル (/var/log/messages*) で指定された Pod 名を含むログエントリを検索できます。
-
フェーズ 2:イメージのプルの問題
ImagePullBackOff または ErrImagePull
Pod のステータスが ImagePullBackOff または ErrImagePull の場合、イメージのプルが失敗したことを示します。この場合、Pod のイベントを調べて、以下の情報を使用して問題をトラブルシューティングします。
|
エラーメッセージ |
説明 |
推奨されるソリューション |
||||||
|
|
Pod の作成時に |
ワークロードの YAML ファイルの Container Registry (ACR) を使用する場合、認証情報ヘルパーを使用してパスワードなしでイメージをプルできます。詳細については、「同じアカウントからイメージをプルする」をご参照ください。 |
||||||
|
|
HTTPS 経由でイメージをプルする際に、イメージリポジトリのアドレスを解決できませんでした。 |
|
||||||
|
|
ノードのディスク領域が不足しています。 |
Pod が実行されているノードにログインし (詳細については、「ECS リモート接続方法の選択」をご参照ください)、 |
||||||
|
|
サードパーティのイメージリポジトリが、不明または安全でない認証局 (CA) によって署名された証明書を使用しています。 |
コンソールコンソールを使用して containerd パラメーターを設定する重要
この変更は既存のコンテナには影響しません。クラスターの安定性を保つため、この操作はオフピーク時に実行してください。
設定例
CLI
|
||||||
|
|
操作はキャンセルされました。おそらくイメージファイルが大きすぎるためです。Kubernetes にはイメージをプルするためのデフォルトのタイムアウトがあります。プルが特定の期間進行しない場合、Kubernetes は操作が失敗したか応答がないと判断し、タスクをキャンセルします。 |
|
||||||
|
|
ネットワークの問題により、イメージリポジトリに接続できません。 |
|
||||||
|
|
海外のリポジトリからイメージをプルする際に、ネットワークの問題により接続がタイムアウトしました。 |
Docker Hub などの海外リポジトリからのイメージプルは、キャリアネットワークが不安定なため、ACK クラスターで失敗することがあります。これを解決するには、以下のソリューションを検討してください:
|
||||||
|
|
Docker Hub は、イメージのプルリクエストにレート制限を課しています。 |
イメージを Container Registry (ACR) にアップロードし、ACR イメージリポジトリからプルします。 |
||||||
|
ステータス |
kubelet のイメージプルレート制限メカニズムがトリガーされた可能性があります。 |
ノードプールの kubelet 設定をカスタマイズする機能を使用して、 |



フェーズ 3:起動の問題
Pod が Init 状態にある
|
エラーメッセージ |
説明 |
ソリューション |
|
|
Pod には M 個の init コンテナが含まれています。そのうち N 個は完了しましたが、残りの M-N 個の init コンテナは起動に失敗しました。 |
init コンテナの詳細については、「init コンテナのデバッグ」をご参照ください。 |
|
|
Pod 内の init コンテナが起動に失敗しました。 |
|
|
|
Pod 内の init コンテナが起動に失敗し、再起動ループに陥っています。 |
Pod が Creating 状態にある
|
エラーメッセージ |
説明 |
ソリューション |
|
|
これは Flannel ネットワークプラグインの設計による期待される動作です。 |
Flannel コンポーネントを v0.15.1.11-7e95fe23-aliyun 以降にアップグレードします。詳細については、「Flannel」をご参照ください。 |
|
Kubernetes バージョン 1.20 より前のクラスターでは、Pod が繰り返し再起動したり、CronJob の Pod がタスクを完了してすぐに終了したりすると、IP アドレスのリークが発生する可能性があります。 |
クラスターを Kubernetes 1.20 以降にアップグレードします。最新のクラスターバージョンを使用することを推奨します。詳細については、「クラスターを手動でアップグレードする」をご参照ください。 |
|
|
containerd と runC の欠陥がこの問題を引き起こします。 |
緊急の修正については、「Pod が「範囲内で利用可能な IP アドレスがありません」というエラーで起動に失敗するのはなぜですか?」をご参照ください。 |
|
|
|
Terway ネットワークプラグインは、ノード上に内部データベースを維持して Elastic Network Interface (ENI) を追跡および管理します。このエラーは、データベースの状態が実際のネットワークデバイス設定と一致しない場合に発生し、ENI の割り当てが失敗します。 |
|
|
Terway ネットワークプラグインが vSwitch から IP アドレスを要求できなかった可能性があります。 |
|
Pod の起動失敗 (CrashLoopBackOff)
|
エラーメッセージ |
説明 |
ソリューション |
|
ログに |
|
|
|
Pod のイベントに |
liveness プローブが失敗し、アプリケーションが再起動しました。 |
|
|
Pod のイベントに |
startup プローブが失敗し、アプリケーションが再起動しました。 |
|
|
Pod のログに |
クラウドディスクの領域が不足しています。 |
|
|
イベント情報なしで起動が失敗します。 |
この問題は、コンテナが宣言された制限を超えるリソースを必要とし、その結果失敗する場合に発生します。 |
Pod のリソース設定が正しいか確認します。リソースプロファイリングを有効にして、コンテナの推奨されるリクエストと制限の設定を取得できます。 |
|
Pod のログに |
同じ Pod 内のコンテナ間でポートの競合が存在します。 |
|
|
Pod のログに |
ワークロードが Secret をマウントしていますが、Secret 内の値が Base64 エンコードされていません。 |
|
|
アプリケーション固有の問題。 |
Pod のログを調べて問題をトラブルシューティングします。 |
|
Pod は Running だが Ready ではない (Ready: False)
|
エラーメッセージ |
説明 |
ソリューション |
|
|
readiness プローブが失敗し、対象の Pod がトラフィックを受信できなくなりました。 |
|
|
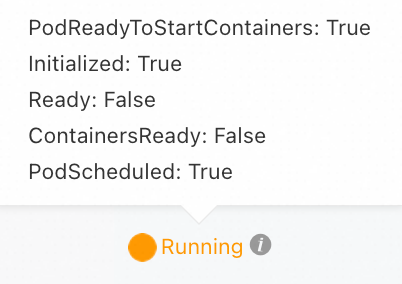
Pod のステータスは上記と同じです。Pod のイベントに |
startup プローブの失敗により、コンテナが再起動します。このエラーは、永続的な Running/NotReady 状態ではなく、「CrashLoopBackOff」状態になるはずです。 |
この問題のトラブルシューティングは、「Pod が起動しない (CrashLoopBackOff)」セクションに記載されている手順に従って、起動 について行います。 |
 Pod のイベントに
Pod のイベントに フェーズ 4:Pod ランタイムの問題
OOMKilled
クラスター内のコンテナが指定された制限を超えるメモリを使用すると、メモリ不足 (OOM) イベントにより終了させられる可能性があり、コンテナが予期せず終了します。OOM イベントの詳細については、「コンテナと Pod にメモリリソースを割り当てる」をご参照ください。
-
終了したプロセスがコンテナのメインプロセスである場合、コンテナは予期せず再起動する可能性があります。
-
OOM イベントが発生すると、コンソールの Pod 詳細ページの イベント タブに表示されます。たとえば、
pod was OOM killed. node:XXX pod:XXX namespace:XXXのように表示されます。 -
クラスターのコンテナレプリカ例外のアラートを設定している場合、OOM イベントが発生すると通知が届きます。詳細については、「コンテナレプリカ例外アラートルールセット」をご参照ください。
|
OOM レベル |
説明 |
推奨されるソリューション |
|
OS レベル |
Pod のノードのカーネルログ |
|
|
cgroup レベル |
Pod のノードのカーネルログ |
|
OOM イベントの原因と解決策の詳細については、「OOM Killer の原因と解決策」をご参照ください。
Terminating
|
考えられる原因 |
説明 |
推奨されるソリューション |
|
ノードが NotReady 状態です。 |
ノードが NotReady 状態から回復した後、Pod は自動的に削除されます。 |
|
|
Pod に finalizer が設定されています。 |
Pod に finalizer が設定されている場合、Kubernetes は Pod を削除する前に finalizer で指定されたクリーンアップ操作を実行します。クリーンアップ操作が応答に失敗した場合、Pod は Terminating 状態のままになります。 |
|
|
Pod の preStop フックが無効またはスタックしています。 |
Pod に preStop フックが設定されている場合、Kubernetes はコンテナを終了する前にフックを実行します。フックの実行中、Pod は Terminating 状態のままになります。 |
|
|
Pod にグレースフルシャットダウン期間が設定されています。 |
Pod にグレースフルシャットダウン期間 ( |
コンテナがグレースフルシャットダウンを完了した後、Kubernetes は自動的に Pod を削除します。 |
|
コンテナが応答しません。 |
Pod の停止または削除を要求すると、Kubernetes は Pod 内のコンテナに |
|
Evicted
|
考えられる原因 |
説明 |
推奨されるソリューション |
|
ノードは、メモリやディスク使用量などの要因によるリソースプレッシャー下にあります。 |
ノードは、メモリプレッシャー、ディスクプレッシャー、または PID プレッシャーを経験している可能性があります。
|
|
|
予期しないエビクションが発生します。 |
Pod のノードに手動で追加された NoExecute Taint が予期しないエビクションを引き起こしました。 |
|
|
エビクションが期待どおりに進みません。 |
|
小規模クラスター (50 ノード以下) では、ノードの 55% 以上が障害を起こすと、Pod のエビクションは停止します。詳細については、「エビクションのレート制限」をご参照ください。 |
|
大規模クラスター (50 ノード超) では、異常なノードの割合が |
||
|
Pod がエビクションされた後、頻繁に元のノードに再スケジュールされます。 |
kubelet は実際のリソース使用量に基づいて Pod をエビクションしますが、スケジューラはリソースリクエストに基づいて Pod を配置します。エビクションによってリソースが解放されるため、リクエストがまだ収まる場合、スケジューラは Pod を同じノードに再スケジュールする可能性があります。 |
Pod のリソースリクエストがノードの割り当て可能なリソースに対して適切であることを確認し、必要に応じて調整します。詳細については、「コンテナの CPU およびメモリリソースの設定」をご参照ください。また、リソースプロファイリングを有効にして、コンテナの推奨リクエストと制限の設定を取得することもできます。 |
Completed
Pod が Completed 状態にある場合、そのすべてのコンテナはコマンドを終了し、正常に終了しています。この状態は、ジョブや init コンテナなどのワークロードで一般的です。
よくある質問
Pod は実行中だが機能しない
アプリケーションの YAML ファイルのエラーにより、Pod が Running 状態に入っても正しく機能しないことがあります。
-
Pod の設定でコンテナの設定を確認します。
-
以下の方法で YAML 設定のスペルミスを確認します。
Pod を作成する際に、YAML ファイルのキーにスペルミスがある場合 (例えば、
commandをcommndとスペルミスした場合)、クラスターはそのエラーを無視してリソースを正常に作成します。しかし、システムはコンテナの実行中に YAML ファイルで指定されたコマンドを実行できません。以下の例では、
commandがcommndとスペルミスされている場合のトラブルシューティング方法を説明します。-
--validateフラグをkubectl apply -fコマンドに追加し、kubectl apply --validate -f XXX.yamlコマンドを実行します。単語をスペルミスした場合、エラーが報告されます:
XXX] unknown field: commnd XXX] this may be a false alarm, see https://gXXXb.XXX/6842pods/test。 -
以下のコマンドを実行し、出力された
pod.yamlを Pod の作成に使用した元の YAML ファイルと比較します。説明[$Pod]は異常な Pod の名前で、kubectl get podsコマンドを実行して取得できます。kubectl get pods [$Pod] -o yaml > pod.yaml-
pod.yamlファイルが元のファイルよりも行数が多い場合、Pod は期待どおりに作成され、クラスターがデフォルト値を追加したことを意味します。 -
元の YAML ファイルの行が
pod.yamlにない場合、これは元のファイルにスペルミスがあることを示します。
-
-
-
Pod のログを確認して問題をトラブルシューティングします。
-
ターミナルを介してコンテナにアクセスし、コンテナ内のローカルファイルが期待どおりであることを確認します。
kubectl を使用してノードのリソース使用量を確認する
-
クラスター内のすべてのノードの CPU とメモリの使用量を確認します。
kubectl describe nodes | awk '/^Name:/{print "\n"$2} /Resource +Requests +Limits/{print $0} /^[ \t]+cpu.*%/{print $0} /^[ \t]+memory.*%/{print $0}'期待される出力:
cn-hangzhou.192.168.0.xxx Resource Requests Limits cpu 1725m (44%) 10320m (263%) memory 1750Mi (11%) 16044Mi (109%) cn-hangzhou.192.168.16.xxx Resource Requests Limits cpu 1885m (48%) 16820m (429%) memory 2536Mi (17%) 25760Mi (179%)リクエスト使用率が高いノードは、新しい Pod の
requestsを満たすことができず、Pod のスケジューリングが妨げられる可能性があります。 -
YOUR_NODE_NAMEを実際のノード名に置き換えて、ノード上のすべての Pod のリソース使用量を確認します。kubectl describe node YOUR_NODE_NAME | awk '/Non-terminated Pods/,/Allocated resources/{ if ($0 !~ /Allocated resources/) print }'期待される出力:
Non-terminated Pods: (11 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age --------- ---- ------------ ---------- --------------- ------------- --- arms-prom node-exporter-gp95p 20m (0%) 1020m (26%) 160Mi (1%) 1152Mi (7%) 6d21h csdr csdr-velero-77c8bbc9c7-w46lq 500m (12%) 1 (25%) 128Mi (0%) 2Gi (13%) 6d19h kube-system ack-cost-exporter-5b647ffc65-zdrsl 100m (2%) 1 (25%) 200Mi (1%) 1Gi (6%) 6d21h kube-system ack-node-local-dns-admission-controller-5dfd74f5f4-9rl6n 100m (2%) 1 (25%) 100Mi (0%) 1Gi (6%) 6d21h kube-system ack-node-problem-detector-daemonset-6wql2 200m (5%) 1200m (30%) 300Mi (2%) 1324Mi (9%) 6d21h kube-system coredns-7784559f6-dr9sn 100m (2%) 0 (0%) 100Mi (0%) 2Gi (13%) 6d21h kube-system csi-plugin-knz7j 130m (3%) 2 (51%) 176Mi (1%) 4Gi (27%) 6d21h kube-system kube-proxy-worker-rkbzv 100m (2%) 0 (0%) 100Mi (0%) 0 (0%) 6d21h kube-system loongcollector-ds-kw7cj 100m (2%) 2 (51%) 256Mi (1%) 2Gi (13%) 6d21h kube-system node-local-dns-pgzcn 25m (0%) 0 (0%) 30Mi (0%) 1Gi (6%) 6d21h kube-system terway-eniip-lnn8n 350m (8%) 1100m (28%) 200Mi (1%) 256Mi (1%) 6d21h実際のリソース消費量に基づいて
requests設定を調整できます。
Pod からデータベースへの断続的なネットワーク切断
ACK クラスター内の Pod がデータベースから断続的に切断される場合は、次の手順に従って問題をトラブルシューティングします。
1. Pod の確認
-
Pod のイベントを確認し、ネットワークの問題、再起動、リソース不足など、接続の不安定さの兆候がないか調べます。
-
Pod のログを確認し、タイムアウト、認証の失敗、再接続のトリガーなど、データベース接続に関連するエラーメッセージがないか調べます。
-
Pod の CPU とメモリの使用量を監視し、リソースの枯渇がアプリケーションやデータベースドライバのクラッシュを引き起こしていないことを確認します。
-
Pod のリソースの
requestsとlimitsを確認し、十分な CPU とメモリがあることを確認します。
2. ノードの確認
-
ノードのリソース使用量を確認し、メモリ、ディスク領域、その他のリソースの不足がないか調べます。詳細については、「ノードの監視」をご参照ください。
-
ノードと対象データベース間の断続的なネットワーク中断をテストします。
3. データベースの確認
-
データベースのステータスとパフォーマンスメトリクスを確認し、再起動やパフォーマンスボトルネックがないか調べます。
-
異常な接続数と接続タイムアウト設定を確認し、アプリケーションの要件に基づいて調整します。
-
データベースのログを検査し、切断に関連するレコードがないか調べます。
4. クラスターコンポーネントのステータスの確認
クラスターコンポーネントの障害は、Pod のネットワーク通信を妨げる可能性があります。
kubectl get pod -n kube-system # コンポーネント Pod のステータスを確認します。また、以下のネットワークコンポーネントも確認してください:
-
CoreDNS:コンポーネントのステータスとログを確認し、Pod がデータベースサービスアドレスを正しく解決できることを確認します。
-
Flannel:kube-flannel コンポーネントのステータスとログを確認します。
-
Terway:terway-eniip コンポーネントのステータスとログを確認します。
5. ネットワークトラフィックの分析
tcpdump を使用してパケットをキャプチャし、ネットワークトラフィックを分析することで、問題の原因を特定するのに役立ちます。
-
Pod とノードの情報を取得します:
以下のコマンドを実行して、特定の名前空間内の Pod とそれらが実行されているノードに関する情報を取得します:
kubectl get pod -n [namespace] -o wide -
対象のノードにログインし、以下のコマンドを実行してコンテナ PID を見つけます。
Containerd
-
以下のコマンドを実行して、コンテナ
CONTAINERを表示します。crictl ps |grep <Pod name keyword>期待される出力:
CONTAINER IMAGE CREATED STATE a1a214d2***** 35d28df4***** 2 days ago Running -
CONTAINER IDパラメーターを使用して以下のコマンドを実行し、コンテナ PID を表示します。crictl inspect a1a214d2***** |grep -i PID期待される出力:
"pid": 2309838, # 対象コンテナの PID。 "pid": 1 "type": "pid"
Docker
-
以下のコマンドを実行して、コンテナの
CONTAINER IDを表示します。docker ps |grep <pod name keyword>期待される出力:
CONTAINER ID IMAGE COMMAND a1a214d2***** 35d28df4***** "/nginx -
CONTAINER IDパラメーターを使用して以下のコマンドを実行し、コンテナ PID を表示します。docker inspect a1a214d2***** |grep -i PID期待される出力:
"Pid": 2309838, # 対象コンテナの PID。 "PidMode": "", "PidsLimit": null,
-
-
パケットキャプチャコマンドを実行します。
コンテナ PID を使用して以下のコマンドを実行し、Pod と対象データベース間のネットワークパケットをキャプチャします。
nsenter -t <container PID> tcpdump -i any -n -s 0 tcp and host <database IP address>コンテナ PID を使用して以下のコマンドを実行し、Pod とホスト間のネットワークパケットをキャプチャします。
nsenter -t <container PID> tcpdump -i any -n -s 0 tcp and host <node IP address>以下のコマンドを実行して、ホストとデータベース間のネットワークパケットをキャプチャします。
tcpdump -i any -n -s 0 tcp and host <database IP address>
6. アプリケーションの最適化
-
アプリケーションに自動再接続メカニズムを実装し、データベースのスイッチオーバーや移行中に接続を自動的に復元できるようにします。
-
データベースとの通信には、短時間接続ではなく接続保持を使用します。接続保持は、パフォーマンスのオーバーヘッドとリソース消費を大幅に削減し、システム全体の効率を向上させることができます。
コンソールでのトラブルシューティング
ACK コンソールにログインし、クラスターの詳細ページに移動して Pod の問題をトラブルシューティングします。
|
操作 |
コンソール |
|
Pod のステータスを確認する |
|
|
Pod の基本情報を確認する |
|
|
Pod の設定を確認する |
|
|
Pod のイベントを確認する |
|
|
Pod のログを表示する |
説明
ACK クラスターは Simple Log Service (SLS) と統合されています。クラスターで SLS を有効にすると、コンテナログを迅速に収集できます。詳細については、「ACK クラスターからコンテナログを収集する」をご参照ください。 |
|
Pod のモニタリングデータを確認する |
説明
ACK クラスターは Managed Service for Prometheus と統合されています。クラスターで Managed Service for Prometheus を迅速に有効にして、クラスターとコンテナのヘルスをリアルタイムで監視し、Grafana ダッシュボードを表示できます。詳細については、「Managed Service for Prometheus への接続と設定」をご参照ください。 |
|
ターミナルを使用してコンテナにアクセスし、ローカルファイルを表示する |
|
|
Pod 診断を実行する |
説明
Container Intelligent Service は、クラスターの問題を特定するのに役立つワンクリック診断機能を提供します。詳細については、「クラスター診断の使用」をご参照ください。 |
予期しない Pod の削除
クラスターに Completed ステータスの Pod が多数含まれている場合、kube-controller-manager (KCM) はコントローラーのパフォーマンス低下を防ぐためにそれらをガベージコレクションします。このクリーンアップは、完了した Pod の数がデフォルトのしきい値である 12,500 を超えたときに発生します。--terminated-pod-gc-threshold パラメーターがこのしきい値を設定します。詳細については、コミュニティのKCM パラメータードキュメントをご参照ください。
推奨:クラスター内の Completed ステータスの Pod を定期的にクリーンアップして、コントローラーの効率に影響を与えないようにします。