Jika bisnis Anda memerlukan kemampuan database seperti performa baca dan tulis konkuren tinggi, skalabilitas tinggi, ketersediaan tinggi, pengambilan data kompleks, dan analisis big data, tetapi arsitektur database yang ada tidak dapat memenuhi kebutuhan tersebut atau biaya transformasi database terlalu tinggi, Anda dapat menggunakan DataWorks Data Integration untuk memigrasikan data dari database yang ada ke tabel Tablestore. Anda juga dapat menggunakan DataWorks Data Integration untuk memigrasikan data di antara instans atau akun Alibaba Cloud, serta memigrasikan data Tablestore ke Object Storage Service (OSS) atau MaxCompute. Dengan cara ini, Anda dapat mencadangkan data Tablestore dan menggunakannya di layanan lain.
Skenario
DataWorks Data Integration adalah platform sinkronisasi data yang stabil, efisien, dan skalabel. Platform ini cocok untuk migrasi dan sinkronisasi data antara berbagai sumber data seperti MySQL, Oracle, MaxCompute, dan Tablestore.
Tablestore memungkinkan Anda menggunakan DataWorks Data Integration untuk memigrasikan data database ke Tablestore, memigrasikan data Tablestore antar instans atau akun Alibaba Cloud, serta memigrasikan data Tablestore ke OSS atau MaxCompute.
Migrasikan data database ke Tablestore
DataWorks menyediakan fitur sinkronisasi data yang stabil dan efisien di antara berbagai sumber data. Anda dapat memigrasikan data dari berbagai database ke Tablestore.
Untuk informasi tentang sumber data serta plug-in Reader dan Writer yang didukung oleh DataWorks, lihat Tipe sumber data yang didukung, plug-in Reader, dan plug-in Writer.
Migrasikan atau sinkronkan data Tablestore antar instans atau akun Alibaba Cloud
Anda dapat mengonfigurasi plug-in Reader dan Writer terkait Tablestore di DataWorks untuk menyinkronkan data di tabel data Tablestore atau tabel deret waktu. Tabel berikut menjelaskan plug-in Reader dan Writer terkait Tablestore.
Plug-in | Deskripsi |
OTSReader | Plug-in ini digunakan untuk membaca data dari tabel Tablestore. Anda dapat menentukan rentang data yang ingin diekstraksi untuk melakukan ekstraksi inkremental. |
OTSStreamReader | Plug-in ini digunakan untuk mengekspor data di tabel Tablestore dalam mode inkremental. |
OTSWriter | Plug-in ini digunakan untuk menulis data ke Tablestore. |
Migrasikan data Tablestore ke OSS atau MaxCompute
Anda dapat memigrasikan data Tablestore ke OSS atau MaxCompute sesuai dengan skenario bisnis Anda.
MaxCompute adalah layanan gudang data yang dikelola sepenuhnya yang dapat memproses terabyte hingga petabyte data dengan kecepatan tinggi. Anda dapat menggunakan MaxCompute untuk mencadangkan data Tablestore atau memigrasikan data Tablestore ke MaxCompute dan menggunakannya di MaxCompute.
OSS adalah layanan penyimpanan yang aman, hemat biaya, dan sangat andal untuk sejumlah besar data. Anda dapat menggunakan OSS untuk mencadangkan data Tablestore atau menyinkronkan data Tablestore ke OSS dan mengunduh objek dari OSS ke perangkat lokal Anda.
Solusi Migrasi
Anda dapat menggunakan DataWorks Data Integration untuk memigrasikan data antara Tablestore dan berbagai sumber data.
Anda dapat menggunakan solusi impor data untuk menyinkronkan jenis data berikut ke Tablestore: MySQL, Oracle, Kafka, HBase, dan MaxCompute. Anda juga dapat menyinkronkan data di antara tabel data Tablestore atau tabel deret waktu.
Anda dapat menggunakan solusi ekspor data untuk menyinkronkan data dari Tablestore ke MaxCompute atau OSS.
Impor data
Tabel berikut menjelaskan solusi impor data.
Solusi | Deskripsi |
Sinkronkan data MySQL ke Tablestore | Anda hanya dapat memigrasikan data di database MySQL ke tabel data Tablestore. Selama migrasi, konfigurasi skrip Reader MySQL dan konfigurasi skrip Writer Tablestore digunakan. Item berikut menjelaskan konfigurasi sumber dan tujuan:
|
Sinkronkan data Oracle ke Tablestore | Anda hanya dapat memigrasikan data di database Oracle ke tabel data Tablestore. Selama migrasi, konfigurasi skrip Reader Oracle dan konfigurasi skrip Writer Tablestore digunakan. Item berikut menjelaskan konfigurasi sumber dan tujuan:
|
Sinkronkan data Kafka ke Tablestore | Anda dapat memigrasikan data Kafka ke tabel data Tablestore atau tabel deret waktu. Penting
Selama migrasi, konfigurasi skrip Reader Kafka dan konfigurasi skrip Writer Tablestore digunakan. Item berikut menjelaskan konfigurasi sumber dan tujuan:
|
Sinkronkan data HBase ke Tablestore | Anda hanya dapat memigrasikan data di database HBase ke tabel data Tablestore. Selama migrasi, konfigurasi skrip Reader HBase dan konfigurasi skrip Writer Tablestore digunakan. Item berikut menjelaskan konfigurasi sumber dan tujuan:
|
Sinkronkan data MaxCompute ke Tablestore | Anda hanya dapat memigrasikan data MaxCompute ke tabel data Tablestore. Selama migrasi, konfigurasi skrip Reader MaxCompute dan konfigurasi skrip Writer Tablestore digunakan. Item berikut menjelaskan konfigurasi sumber dan tujuan:
|
Sinkronkan data PolarDB-X 2.0 ke Tablestore | Anda hanya dapat memigrasikan data dari PolarDB-X 2.0 ke tabel data Tablestore. Selama migrasi, konfigurasi skrip Reader PolarDB-X 2.0 dan konfigurasi skrip Writer Tablestore digunakan.
|
Sinkronkan data antara tabel data Tablestore | Anda hanya dapat memigrasikan data dari tabel data Tablestore ke tabel data Tablestore lainnya. Selama migrasi, konfigurasi skrip Reader dan konfigurasi skrip Writer Tablestore digunakan. Untuk informasi tentang konfigurasi sumber dan tujuan, lihat Sumber data Tablestore. Saat menentukan konfigurasi skrip Reader dan Writer Tablestore, merujuk pada konfigurasi yang digunakan untuk membaca dan menulis data dalam model Kolom Lebar. |
Sinkronkan data antara tabel deret waktu Tablestore | Anda hanya dapat memigrasikan data dari tabel deret waktu Tablestore ke tabel deret waktu Tablestore lainnya. Selama migrasi, konfigurasi skrip Reader dan konfigurasi skrip Writer Tablestore digunakan. Untuk informasi tentang konfigurasi sumber dan tujuan, lihat Sumber data Tablestore. Saat menentukan konfigurasi skrip Reader dan Writer Tablestore, merujuk pada konfigurasi yang digunakan untuk membaca dan menulis data dalam model TimeSeries. |
Ekspor data
Tabel berikut menjelaskan solusi ekspor data.
Solusi | Deskripsi |
Sinkronkan data Tablestore ke MaxCompute | Anda dapat menggunakan MaxCompute untuk mencadangkan data Tablestore atau memigrasikan data Tablestore ke MaxCompute dan menggunakan data Tablestore di MaxCompute. Selama migrasi, konfigurasi skrip Reader Tablestore dan konfigurasi skrip Writer MaxCompute digunakan. Item berikut menjelaskan konfigurasi sumber dan tujuan:
|
Sinkronkan data Tablestore ke OSS | Anda dapat mengunduh objek yang disinkronkan dari Tablestore ke OSS dan menyimpan objek tersebut di OSS sebagai cadangan data di Tablestore. Selama migrasi, konfigurasi skrip Reader Tablestore dan konfigurasi skrip Writer OSS digunakan. Item berikut menjelaskan konfigurasi sumber dan tujuan:
|
Prasyarat
Setelah menentukan solusi migrasi, pastikan persiapan berikut telah dilakukan:
Koneksi jaringan antara sumber dan DataWorks serta antara tujuan dan DataWorks telah dibuat.
Operasi berikut dilakukan pada layanan sumber: konfirmasi versi, persiapan akun, konfigurasi izin yang diperlukan, dan konfigurasi spesifik layanan. Untuk informasi lebih lanjut, lihat persyaratan konfigurasi dalam dokumentasi sumber.
Layanan tujuan diaktifkan, dan sumber daya yang diperlukan dibuat. Untuk informasi lebih lanjut, lihat persyaratan konfigurasi dalam dokumentasi tujuan.
Catatan Penggunaan
Jika mengalami masalah apa pun, ajukan tiket.
Pastikan DataWorks Data Integration mendukung migrasi data versi produk tertentu.
Tipe data tujuan harus sesuai dengan tipe data sumber. Jika tidak, data kotor mungkin dihasilkan selama migrasi.
Setelah menentukan solusi migrasi, pastikan untuk membaca batasan dan catatan penggunaan dalam dokumentasi sumber dan tujuan.
Sebelum memigrasikan data Kafka, Anda harus memilih model data Tablestore untuk menyimpan data berdasarkan skenario bisnis Anda.
Proses Konfigurasi
Anda dapat menentukan solusi migrasi Anda dan mempelajari cara mengonfigurasi migrasi data menggunakan DataWorks Data Integration untuk solusi migrasi Anda.
Tabel berikut menjelaskan langkah-langkah konfigurasi.
No. | Langkah | Deskripsi |
1 | Buat sumber data yang diperlukan berdasarkan solusi migrasi.
| |
2 | Konfigurasikan tugas sinkronisasi batch menggunakan UI tanpa kode | DataWorks Data Integration menyediakan UI tanpa kode dan instruksi langkah demi langkah untuk membantu Anda mengonfigurasi tugas sinkronisasi batch. UI tanpa kode mudah digunakan tetapi hanya menyediakan fitur terbatas. |
3 | Verifikasi hasil migrasi | Lihat data yang diimpor di tujuan berdasarkan solusi migrasi.
|
Contoh
Impor data
Menggunakan DataWorks Data Integration, Anda dapat menyinkronkan data dari database seperti MySQL, Oracle, dan MaxCompute ke tabel data Tablestore. Anda juga dapat menyinkronkan data Tablestore antar akun atau instans. Contohnya termasuk menyinkronkan data dari satu tabel data ke tabel lainnya.
Bagian ini menggunakan sinkronisasi data MaxCompute ke tabel data Tablestore di UI tanpa kode sebagai contoh untuk menjelaskan prosedurnya.
Persiapan
Sebelum melanjutkan, selesaikan persiapan berikut.
Dapatkan informasi tentang proyek MaxCompute dan tabel sumber.
Aktifkan Tablestore, buat instans, dan buat tabel data tujuan. Dapatkan informasi seperti nama instans, titik akhir instans, dan ID wilayah.
CatatanStruktur kunci utama tabel data Tablestore, termasuk tipe data dan urutan, harus sesuai dengan kunci utama tabel sumber MaxCompute. Anda tidak perlu mendefinisikan kolom atribut tabel data terlebih dahulu. Kolom tersebut ditentukan secara dinamis saat data ditulis.
Buat AccessKey untuk akun Alibaba Cloud Anda atau pengguna RAM yang memiliki izin pada layanan Tablestore dan MaxCompute.
Aktifkan DataWorks dan buat ruang kerja di wilayah tempat instans MaxCompute atau Tablestore berada.
Buat kelompok sumber daya tanpa server dan sambungkan ke ruang kerja.
Jika instans MaxCompute dan instans Tablestore berada di wilayah yang berbeda, buat koneksi peering VPC untuk menetapkan konektivitas jaringan lintas wilayah sebagai berikut.
Bagian ini menggunakan contoh di mana ruang kerja DataWorks dan instans MaxCompute berada di wilayah China (Hangzhou), dan instans Tablestore berada di wilayah China (Shanghai).
Sambungkan VPC ke instans Tablestore.
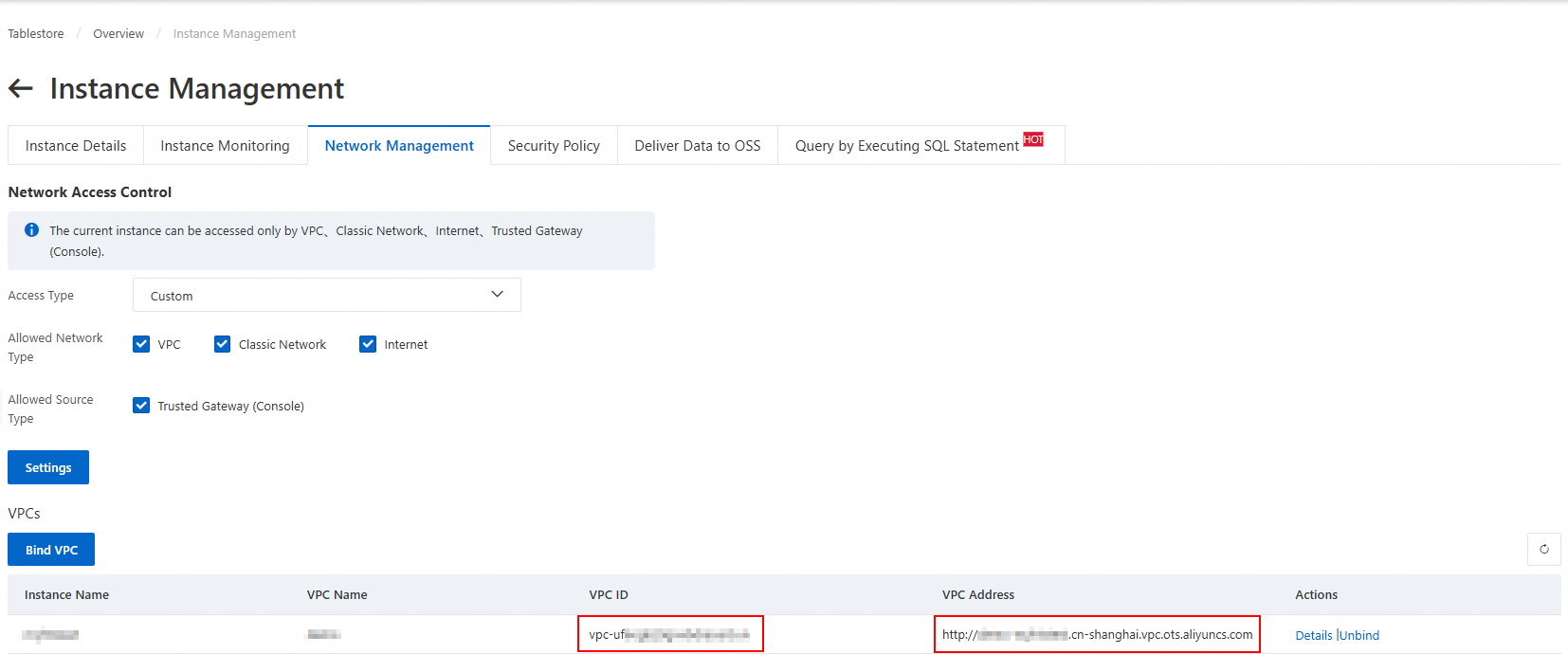
Masuk ke konsol Tablestore dan pilih wilayah di bilah navigasi atas.
Klik alias instans untuk membuka halaman Instance Management.
Di tab Network Management, klik Attach VPC. Pilih VPC dan vSwitch, masukkan nama untuk VPC, lalu klik OK.
Tunggu hingga VPC disambungkan. Halaman kemudian akan diperbarui secara otomatis. Anda dapat melihat ID VPC dan Titik Akhir VPC yang tersambung di daftar VPC.
CatatanAnda akan menggunakan titik akhir VPC ini saat menambahkan sumber data Tablestore di konsol DataWorks nanti.
Dapatkan informasi VPC dari kelompok sumber daya ruang kerja DataWorks.
Masuk ke konsol DataWorks, pilih wilayah ruang kerja dari bilah navigasi atas, lalu klik menu Workspaces di panel navigasi kiri untuk pergi ke halaman Workspace List.
Klik nama ruang kerja untuk pergi ke halaman Workspace Details. Di panel navigasi kiri, klik Resource Groups untuk melihat daftar kelompok sumber daya yang tersambung ke ruang kerja.
Klik Network Settings di sebelah kanan kelompok sumber daya target, dan lihat ID VPC dari virtual private cloud yang tersambung di area Resource Scheduling & Data Integration.
Buat koneksi peering VPC dan konfigurasikan rute.
Masuk ke konsol VPC. Di panel navigasi kiri, klik menu Virtual Private Cloud. Pilih wilayah instans Tablestore dan ruang kerja DataWorks, dan catat blok CIDR untuk setiap VPC yang sesuai.

Di panel navigasi kiri, klik VPC Peering Connection. Di halaman VPC Peering Connection, klik Create Peering Connection.
Di halaman Create Peering Connection, beri nama koneksi peering, pilih VPC peminta, tipe akun penerima, wilayah penerima, dan VPC penerima, lalu klik OK.
Di halaman VPC Peering Connection, temukan koneksi peering VPC yang Anda buat. Di kolom Requester VPC dan Accepter VPC, klik Configure Route Entry.
Blok CIDR tujuan harus menjadi blok CIDR dari VPC peer. Artinya, saat mengonfigurasi rute untuk VPC peminta, masukkan blok CIDR dari VPC penerima. Saat mengonfigurasi rute untuk VPC penerima, masukkan blok CIDR dari VPC peminta.
Langkah 1: Tambahkan sumber data Tablestore dan sumber data MaxCompute
Langkah 2: Konfigurasikan tugas sinkronisasi batch menggunakan UI tanpa kode
DataStudio (Versi Sebelumnya)
1. Buat node tugas
Pergi ke halaman Data Development.
Masuk ke konsol DataWorks.
Di bilah navigasi atas, pilih kelompok sumber daya dan wilayah.
Di panel navigasi kiri, klik .
Di halaman Data Development, pilih ruang kerja target dari daftar drop-down dan klik tombol Go To Data Development.
Di halaman Data Development di konsol DataStudio, di bawah node Business Flow, klik alur bisnis target.
Untuk informasi lebih lanjut, lihat Buat alur bisnis.
Klik kanan node Data Integration dan pilih New Node > Offline Sync.
Di kotak dialog New Node, pilih jalur, masukkan nama, dan klik Confirm.
Node sinkronisasi offline baru ditampilkan di bawah node Data Integration.
2. Konfigurasikan tugas sinkronisasi
Di bawah node Data Integration, klik dua kali pada node tugas sinkronisasi offline baru.
Konfigurasikan jaringan dan sumber daya.
Pilih sumber, tujuan, dan kelompok sumber daya untuk menjalankan tugas sinkronisasi, lalu uji konektivitas.
Di langkah Configure Network and Resource, atur Data Source ke MaxCompute(ODPS). Untuk Data Source Name, pilih sumber data MaxCompute baru.
Pilih kelompok sumber daya.
Setelah Anda memilih kelompok sumber daya, sistem akan menampilkan informasi seperti wilayah dan spesifikasi kelompok sumber daya dan secara otomatis menguji konektivitas antara kelompok sumber daya dan sumber data yang dipilih.
CatatanKelompok sumber daya tanpa server mendukung penentuan batas atas penggunaan CU untuk tugas sinkronisasi. Jika tugas sinkronisasi Anda mengalami kesalahan OOM karena sumber daya tidak mencukupi, sesuaikan nilai penggunaan CU untuk kelompok sumber daya sesuai kebutuhan.
Atur Data Destination ke Tablestore, dan untuk Data Source Name, pilih sumber data Tablestore baru.
Sistem secara otomatis menguji konektivitas antara kelompok sumber daya dan sumber data yang dipilih.
Jika uji konektivitas berhasil, klik Next.
Konfigurasikan tugas dan simpan.
Di langkah Configure Task, Anda dapat mengonfigurasi sumber data dan tujuan di area Configure Data Source And Destination.
Sumber
Parameter
Deskripsi
Sumber data
Sumber data MaxCompute yang dipilih pada langkah sebelumnya ditampilkan secara default.
Kelompok sumber daya Tunnel
Ini adalah Kuota Tunnel. Secara default, "Sumber transmisi publik" dipilih, yaitu kuota gratis MaxCompute.
Untuk informasi tentang memilih sumber daya transmisi data MaxCompute, lihat Beli dan gunakan kelompok sumber daya eksklusif untuk integrasi data.
CatatanJika kuota tunnel eksklusif tidak tersedia karena pembayaran tertunda atau kedaluwarsa, tugas akan secara otomatis beralih ke "Sumber transmisi publik" selama runtime.
Tabel
Tabel sumber.
Metode filter
Logika penyaringan untuk sinkronisasi data. Dua metode berikut didukung:
Partition Filter: Menyaring rentang sinkronisasi data sumber menggunakan ekspresi filter partisi. Saat metode ini dipilih, Anda juga perlu mengonfigurasi parameter Partition Information dan When Partition Does Not Exist.
Data Filter: Menentukan rentang sinkronisasi data sumber menggunakan klausa SQL WHERE (jangan masukkan kata kunci WHERE).
Informasi partisi
CatatanPerlu dikonfigurasi saat Filter Method diatur ke Partition Filter.
Tentukan nilai kolom kunci partisi.
Nilainya bisa berupa bidang statis, seperti
ds=20220101.Nilainya bisa berupa parameter sistem penjadwalan, seperti
ds=${bizdate}. Saat tugas berjalan, parameter sistem penjadwalan secara otomatis diganti.
Ketika partisi tidak ada
CatatanPerlu dikonfigurasi saat Filter Method diatur ke Partition Filter.
Kebijakan pemrosesan untuk tugas sinkronisasi saat partisi tidak ada.
Error.
Ignore Non-existent Partition, Task Executes Normally.
Tujuan
Parameter
Deskripsi
Sumber data
Sumber data Tablestore yang dipilih pada langkah sebelumnya ditampilkan secara default.
Tabel
Tabel data tujuan.
Informasi kunci utama
Informasi kunci utama tabel data tujuan.
Mode penulisan
Mode untuk menulis data ke Tablestore. Dua mode berikut didukung:
PutRow: Sesuai dengan API PutRow Tablestore. Ini memasukkan data ke baris tertentu. Jika baris tersebut tidak ada, baris baru akan ditambahkan. Jika baris tersebut ada, baris yang ada akan ditimpa.
UpdateRow: Sesuai dengan API UpdateRow Tablestore. Ini memperbarui data di baris tertentu. Jika baris tersebut tidak ada, baris baru akan ditambahkan. Jika baris tersebut ada, itu menambah, memodifikasi, atau menghapus nilai kolom tertentu dalam baris tersebut berdasarkan konten permintaan.
Konfigurasikan pemetaan bidang.
Setelah Anda mengonfigurasi sumber data dan tujuan, Anda perlu menentukan pemetaan antara Source Field dan Destination Field. Tugas menggunakan pemetaan ini untuk menulis data dari bidang tabel sumber ke bidang yang sesuai di tabel tujuan. Untuk informasi lebih lanjut, lihat Langkah 4: Konfigurasikan pemetaan bidang.
PentingUntuk membaca data kunci utama, Anda harus menentukan informasi kunci utama di Source Field.
Karena Primary Key Information untuk tabel tujuan telah dikonfigurasi di bawah Data Destination pada langkah sebelumnya, Anda tidak dapat mengonfigurasinya lagi di Destination Field.
Jika tipe data suatu bidang adalah INTEGER, Anda harus mengonfigurasinya sebagai INT. DataWorks secara otomatis mengonversinya ke tipe INTEGER. Jika Anda mengonfigurasi tipe sebagai INTEGER, kesalahan dilaporkan dalam log dan tugas gagal.
Konfigurasikan kontrol saluran.
Anda dapat mengonfigurasi saluran untuk mengontrol properti terkait proses sinkronisasi data. Untuk informasi lebih lanjut tentang parameter, lihat Hubungan antara konkurensi dan pembatasan laju untuk sinkronisasi offline.
Klik ikon
 untuk menyimpan konfigurasi.
untuk menyimpan konfigurasi.
3. Jalankan tugas sinkronisasi
Klik ikon
 .
.Di kotak dialog Parameters, pilih kelompok sumber daya untuk menjalankan tugas.
Klik Run.
DataStudio (Versi Baru)
1. Buat node tugas
Pergi ke halaman Data Development.
Masuk ke konsol DataWorks.
Di bilah navigasi atas, pilih kelompok sumber daya dan wilayah.
Di panel navigasi kiri, klik .
Di halaman Data Development, pilih ruang kerja target Anda dari daftar drop-down dan klik Go To DataStudio.
Di konsol DataStudio pada halaman Data Development, klik ikon
 di sebelah kanan Project Directory, dan pilih .Catatan
di sebelah kanan Project Directory, dan pilih .CatatanJika ini pertama kali Anda menggunakan Project Folder, Anda juga dapat mengklik tombol New Node.
Di kotak dialog New Node, pilih jalur, masukkan nama, dan klik Confirm.
Node sinkronisasi offline baru muncul di Project Folder.
2. Konfigurasikan tugas sinkronisasi
Di bawah Project Directory, klik node tugas sinkronisasi offline baru.
Konfigurasikan jaringan dan sumber daya.
Pilih sumber, tujuan, dan kelompok sumber daya untuk menjalankan tugas sinkronisasi, lalu uji konektivitas.
Di langkah Configure Network and Resource, atur Data Source ke MaxCompute(ODPS). Untuk Data Source Name, pilih sumber data MaxCompute baru.
Pilih kelompok sumber daya.
Setelah Anda memilih kelompok sumber daya, sistem menampilkan informasi seperti wilayah dan spesifikasi kelompok sumber daya dan secara otomatis menguji konektivitas antara kelompok sumber daya dan sumber data yang dipilih.
CatatanKelompok sumber daya tanpa server mendukung penentuan batas atas penggunaan CU untuk tugas sinkronisasi. Jika tugas sinkronisasi Anda mengalami kesalahan OOM karena sumber daya tidak mencukupi, sesuaikan nilai penggunaan CU untuk kelompok sumber daya sesuai kebutuhan.
Atur Data Destination ke Tablestore, dan untuk Data Source Name, pilih sumber data Tablestore baru.
Sistem secara otomatis menguji konektivitas antara kelompok sumber daya dan sumber data yang dipilih.
Jika uji konektivitas berhasil, klik Next.
Konfigurasikan tugas dan simpan.
Di langkah Configure Task, Anda dapat mengonfigurasi sumber data dan tujuan di area Configure Data Source And Destination.
Sumber
Parameter
Deskripsi
Sumber data
Sumber data MaxCompute yang dipilih pada langkah sebelumnya ditampilkan secara default.
Kelompok sumber daya Tunnel
Ini adalah Kuota Tunnel. Secara default, "Sumber transmisi publik" dipilih, yaitu kuota gratis MaxCompute.
Untuk informasi tentang memilih sumber daya transmisi data MaxCompute, lihat Beli dan gunakan kelompok sumber daya eksklusif untuk integrasi data.
CatatanJika kuota tunnel eksklusif tidak tersedia karena pembayaran tertunda atau kedaluwarsa, tugas akan secara otomatis beralih ke "Sumber transmisi publik" selama runtime.
Tabel
Tabel sumber.
Metode filter
Logika penyaringan untuk sinkronisasi data. Dua metode berikut didukung:
Partition Filter: Menyaring rentang sinkronisasi data sumber menggunakan ekspresi filter partisi. Saat metode ini dipilih, Anda juga perlu mengonfigurasi parameter Partition Information dan When Partition Does Not Exist.
Data Filter: Menentukan rentang sinkronisasi data sumber menggunakan klausa SQL WHERE (jangan masukkan kata kunci WHERE).
Informasi partisi
CatatanPerlu dikonfigurasi saat Filter Method diatur ke Partition Filter.
Tentukan nilai kolom kunci partisi.
Nilainya bisa berupa bidang statis, seperti
ds=20220101.Nilainya bisa berupa parameter sistem penjadwalan, seperti
ds=${bizdate}. Saat tugas berjalan, parameter sistem penjadwalan secara otomatis diganti.
Ketika partisi tidak ada
CatatanPerlu dikonfigurasi saat Filter Method diatur ke Partition Filter.
Kebijakan pemrosesan untuk tugas sinkronisasi saat partisi tidak ada.
Error.
Ignore Non-existent Partition, Task Executes Normally.
Tujuan
Parameter
Deskripsi
Sumber data
Sumber data Tablestore yang dipilih pada langkah sebelumnya ditampilkan secara default.
Tabel
Tabel data tujuan.
Informasi kunci utama
Informasi kunci utama tabel data tujuan.
Mode penulisan
Mode untuk menulis data ke Tablestore. Dua mode berikut didukung:
PutRow: Sesuai dengan API PutRow Tablestore. Ini memasukkan data ke baris tertentu. Jika baris tersebut tidak ada, baris baru akan ditambahkan. Jika baris tersebut ada, baris yang ada akan ditimpa.
UpdateRow: Sesuai dengan API UpdateRow Tablestore. Ini memperbarui data di baris tertentu. Jika baris tersebut tidak ada, baris baru akan ditambahkan. Jika baris tersebut ada, itu menambah, memodifikasi, atau menghapus nilai kolom tertentu dalam baris tersebut berdasarkan konten permintaan.
Konfigurasikan pemetaan bidang.
Setelah Anda mengonfigurasi sumber data dan tujuan, Anda perlu menentukan pemetaan antara Source Field dan Destination Field. Tugas menggunakan pemetaan ini untuk menulis data dari bidang tabel sumber ke bidang yang sesuai di tabel tujuan. Untuk informasi lebih lanjut, lihat Langkah 4: Konfigurasikan pemetaan bidang.
PentingUntuk membaca data kunci utama, Anda harus menentukan informasi kunci utama di Source Field.
Karena Primary Key Information untuk tabel tujuan telah dikonfigurasi di bawah Data Destination pada langkah sebelumnya, Anda tidak dapat mengonfigurasinya lagi di Destination Field.
Jika tipe data suatu bidang adalah INTEGER, Anda harus mengonfigurasinya sebagai INT. DataWorks secara otomatis mengonversinya ke tipe INTEGER. Jika Anda mengonfigurasi tipe sebagai INTEGER, kesalahan dilaporkan dalam log dan tugas gagal.
Konfigurasikan kontrol saluran.
Anda dapat mengonfigurasi saluran untuk mengontrol properti terkait proses sinkronisasi data. Untuk informasi lebih lanjut tentang parameter, lihat Hubungan antara konkurensi dan pembatasan laju untuk sinkronisasi offline.
Klik Save.
3. Jalankan tugas sinkronisasi
Di sebelah kanan tugas, klik Debug Configuration dan pilih kelompok sumber daya untuk menjalankan tugas.
Klik tombol Run.
Langkah 3: Lihat hasil sinkronisasi
Ekspor data
Anda dapat menggunakan DataWorks Data Integration untuk mengekspor data Tablestore ke MaxCompute atau OSS.
Sinkronkan data Tablestore ke OSS
Penagihan
Saat menggunakan alat migrasi untuk mengakses Tablestore, Anda akan dikenakan biaya untuk pembacaan dan penulisan data. Setelah data ditulis, Tablestore mengenakan biaya penyimpanan berdasarkan volume data. Untuk informasi lebih lanjut tentang penagihan, lihat Ikhtisar Penagihan.
Penagihan DataWorks terdiri dari biaya perangkat lunak dan sumber daya. Untuk informasi lebih lanjut, lihat Penagihan.
Solusi Lainnya
Anda dapat mengunduh data Tablestore ke file lokal sesuai kebutuhan.
Anda juga dapat menggunakan alat migrasi seperti DataX dan layanan tunnel untuk mengimpor data.
Alat migrasi | Deskripsi |
DataX mengabstraksi sinkronisasi antara sumber data yang berbeda menjadi plugin Reader yang membaca data dari sumber dan plugin Writer yang menulis data ke tujuan. | |
Tunnel Service adalah layanan terpadu untuk mengonsumsi data penuh dan inkremental berdasarkan API data Tablestore. Dengan membuat saluran data untuk tabel data, Anda dapat dengan mudah mengonsumsi data historis dan baru dari tabel tersebut. Layanan ini cocok untuk migrasi dan sinkronisasi data ketika tabel sumber adalah tabel data Tablestore. Untuk informasi lebih lanjut, lihat Sinkronkan data dari satu tabel data ke tabel lainnya. | |
Data Transmission Service (DTS) adalah layanan streaming data real-time yang disediakan oleh Alibaba Cloud. Ini mendukung interaksi data antara sumber data seperti database relasional (RDBMS), database NoSQL, dan sistem pemrosesan analitik online (OLAP). Ini mengintegrasikan sinkronisasi data, migrasi, langganan, integrasi, dan pemrosesan untuk membantu Anda membangun arsitektur data yang aman, skalabel, dan sangat tersedia. Untuk informasi lebih lanjut, lihat Sinkronkan data PolarDB-X 2.0 ke Tablestore dan Migrasikan data PolarDB-X 2.0 ke Tablestore. |
Lampiran: Pemetaan Tipe Bidang
Bagian ini menjelaskan pemetaan tipe bidang antara layanan umum dan Tablestore. Dalam skenario aktual, konfigurasikan pemetaan bidang berdasarkan pemetaan tipe bidang.
Pemetaan tipe bidang antara MaxCompute dan Tablestore
Tipe bidang di MaxCompute | Tipe bidang di Tablestore |
STRING | STRING |
BIGINT | INTEGER |
DOUBLE | DOUBLE |
BOOLEAN | BOOLEAN |
BINARY | BINARY |
Pemetaan tipe bidang antara MySQL dan Tablestore
Tipe bidang di MySQL | Tipe bidang di Tablestore |
STRING | STRING |
INT atau INTEGER | INTEGER |
DOUBLE, FLOAT, atau DECIMAL | DOUBLE |
BOOL atau BOOLEAN | BOOLEAN |
BINARY | BINARY |
Pemetaan tipe bidang antara Kafka dan Tablestore
Skema Kafka | Tipe bidang di Tablestore |
STRING | STRING |
INT8, INT16, INT32, atau INT64 | INTEGER |
FLOAT32 atau FLOAT64 | DOUBLE |
BOOLEAN | BOOLEAN |
BYTES | BINARY |