Gunakan fitur integrasi data di DataWorks untuk mengekspor data lengkap dari Tablestore ke MaxCompute guna analisis dan pemrosesan offline. DataWorks adalah platform untuk pengembangan dan tata kelola data besar.
Prasyarat
Sebelum mengekspor data, selesaikan persiapan berikut:
Dapatkan informasi mengenai tabel sumber Tablestore, termasuk nama instans, titik akhir instans, dan ID wilayah.
Buat proyek MaxCompute sebagai tujuan penyimpanan data.
Buat AccessKey untuk Akun Alibaba Cloud atau Pengguna RAM Anda. Akun atau pengguna tersebut harus memiliki izin akses ke Tablestore dan MaxCompute.
Aktifkan DataWorks dan buat ruang kerja di wilayah tempat instans MaxCompute atau Tablestore Anda berada.
Buat kelompok sumber daya arsitektur tanpa server dan sambungkan ke ruang kerja. Untuk informasi lebih lanjut mengenai penagihan, lihat Penagihan kelompok sumber daya arsitektur tanpa server.
Jika ruang kerja DataWorks dan instans Tablestore Anda berada di wilayah yang berbeda, Anda harus membuat koneksi peering VPC untuk mengaktifkan konektivitas jaringan cross-region.
Contoh berikut menunjukkan kasus penggunaan di mana instans tabel sumber berada di wilayah Tiongkok (Shanghai) dan ruang kerja DataWorks berada di wilayah Tiongkok (Hangzhou).
Sambungkan VPC ke instans Tablestore.
Login ke Konsol Tablestore. Di bilah navigasi atas, pilih wilayah tempat tabel target berada.
Klik alias instans untuk menuju halaman Instance Management.
Di tab Network Management, klik Bind VPC. Pilih VPC dan vSwitch, masukkan nama VPC, lalu klik OK.
Tunggu hingga VPC tersambung. Halaman akan otomatis dimuat ulang dan menampilkan VPC ID dan VPC Address di daftar VPC.
CatatanSaat menambahkan sumber data Tablestore di Konsol DataWorks, Anda harus menggunakan alamat VPC ini.
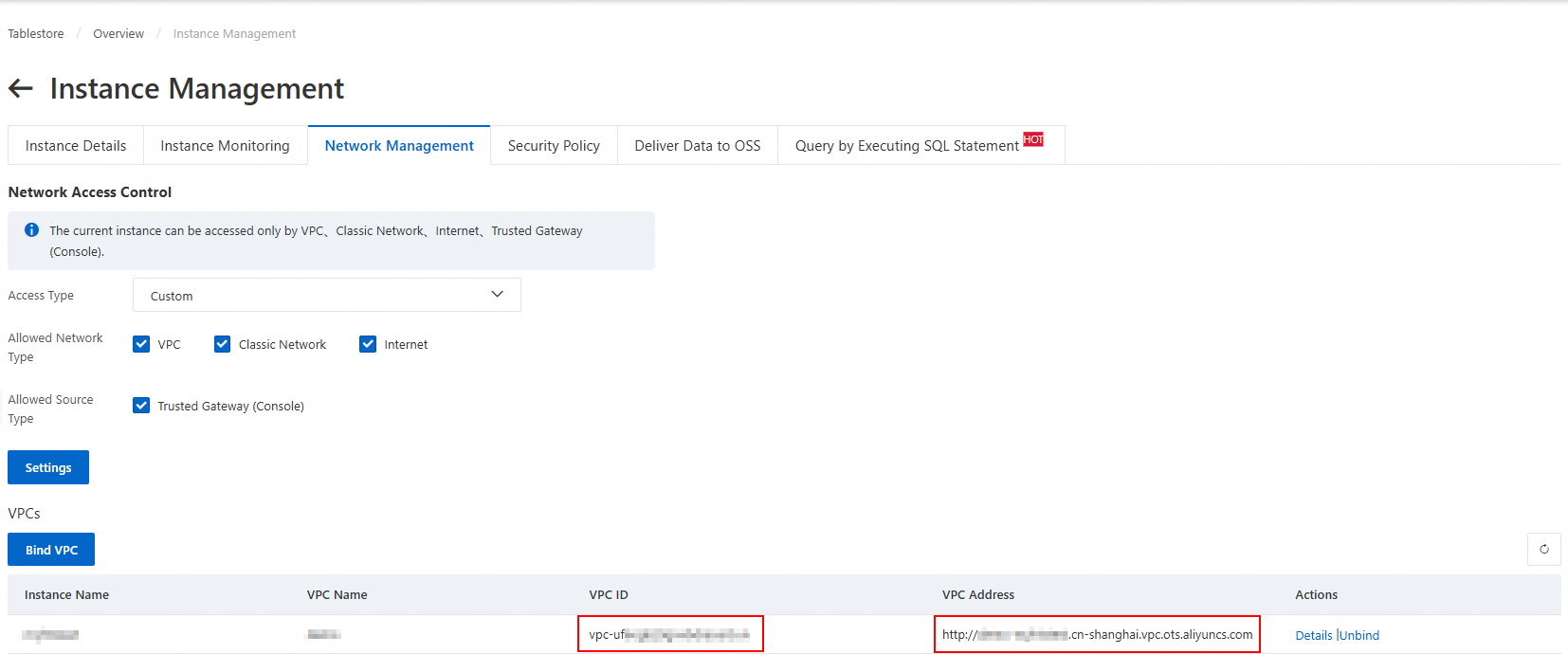
Dapatkan informasi VPC untuk kelompok sumber daya ruang kerja DataWorks.
Login ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah tempat ruang kerja Anda berada. Di panel navigasi kiri, klik Workspace untuk menuju halaman Workspaces.
Klik nama ruang kerja untuk menuju halaman Workspace Details. Di panel navigasi kiri, klik Resource Group untuk melihat kelompok sumber daya yang terhubung ke ruang kerja.
Di sebelah kanan kelompok sumber daya target, klik Network Settings. Di bagian Data Scheduling & Data Integration, lihat VPC ID dari virtual private cloud yang terhubung.
Buat koneksi peering VPC dan konfigurasikan entri rute.
Login ke Konsol VPC. Di panel navigasi kiri, klik VPC Peering Connection, lalu klik Create VPC Peering Connection.
Di halaman Create VPC Peering Connection, masukkan nama untuk koneksi peering dan pilih instans VPC peminta, jenis akun penerima, wilayah penerima, serta instans VPC penerima. Lalu, klik OK.
Di halaman VPC Peering Connection, temukan koneksi peering VPC tersebut dan klik Configure route di kolom Requester VPC dan Accepter.
Untuk blok CIDR tujuan, masukkan blok CIDR dari VPC peer. Misalnya, saat mengonfigurasi entri rute untuk VPC peminta, masukkan blok CIDR VPC penerima. Saat mengonfigurasi entri rute untuk VPC penerima, masukkan blok CIDR VPC peminta.
Prosedur
Ikuti langkah-langkah berikut untuk mengonfigurasi ekspor data lengkap dari Tablestore ke MaxCompute.
Langkah 1: Tambahkan sumber data Tablestore
Konfigurasikan sumber data Tablestore di DataWorks untuk menghubungkan ke tabel data sumber.
Login ke Konsol DataWorks. Alihkan ke wilayah tujuan. Di panel navigasi kiri, pilih . Dari daftar drop-down, pilih ruang kerja dan klik Go to Data Integration.
Di panel navigasi kiri, klik Data source.
Di halaman Data Sources, klik Add Data Source.
Di kotak dialog Add Data Source, cari dan pilih Tablestore sebagai jenis sumber data.
Di kotak dialog Add OTS Data Source, konfigurasikan parameter sumber data seperti dijelaskan dalam tabel berikut.
Parameter
Deskripsi
Data Source Name
Nama sumber data harus merupakan kombinasi huruf, angka, dan garis bawah (_). Nama tidak boleh diawali dengan angka atau garis bawah (_).
Data Source Description
Deskripsi singkat mengenai sumber data. Panjang deskripsi tidak boleh melebihi 80 karakter.
Region
Pilih wilayah tempat instans Tablestore berada.
Tablestore Instance Name
Nama instans Tablestore.
Endpoint
Titik akhir instans Tablestore. Gunakan alamat VPC.
AccessKey ID
ID AccessKey dan Rahasia AccessKey dari Akun Alibaba Cloud atau Pengguna RAM.
AccessKey Secret
Uji konektivitas kelompok sumber daya.
Saat membuat sumber data, Anda harus menguji konektivitas kelompok sumber daya untuk memastikan bahwa kelompok sumber daya untuk tugas sinkronisasi dapat terhubung ke sumber data. Jika tidak, tugas sinkronisasi data tidak dapat dijalankan.
Di bagian Connection Configuration, klik Test Network Connectivity di kolom Connection Status untuk kelompok sumber daya.
Setelah uji konektivitas berhasil, klik Complete. Sumber data baru akan muncul di daftar sumber data.
Jika uji konektivitas gagal, gunakan Network Connectivity Diagnostic Tool untuk memecahkan masalah.
Langkah 2: Tambahkan sumber data MaxCompute
Konfigurasikan sumber data MaxCompute sebagai tujuan ekspor data.
Klik Add Data Source lagi. Pilih MaxCompute sebagai jenis sumber data dan konfigurasikan parameter-parameter berikut.
Parameter
Deskripsi
Data Source Name
Nama harus terdiri dari huruf, angka, dan garis bawah (_). Nama tidak boleh diawali dengan angka atau garis bawah (_).
Data Source Description
Deskripsi singkat mengenai sumber data. Panjang deskripsi tidak boleh melebihi 80 karakter.
Authentication Method
Nilai default adalah Alibaba Cloud Account And Alibaba Cloud RAM Role. Anda tidak dapat mengubah nilai ini.
Alibaba Cloud Account
Current Alibaba Cloud Account: Pilih MaxCompute Project Name dan Default Access Identity untuk akun saat ini di wilayah yang ditentukan.
Other Alibaba Cloud Account: Masukkan UID of Alibaba Cloud Account, MaxCompute Project Name, dan RAM Role untuk akun lain di wilayah yang ditentukan.
Region
Wilayah tempat proyek MaxCompute berada.
Endpoint
Nilai default adalah Auto Fit. Anda juga dapat memilih Custom Configuration sesuai kebutuhan.
Setelah mengonfigurasi parameter dan uji konektivitas berhasil, klik Complete untuk menambahkan sumber data.
Langkah 3: Konfigurasikan tugas sinkronisasi batch
Buat tugas sinkronisasi data untuk menentukan aturan transfer data dan pemetaan bidang dari Tablestore ke MaxCompute.
Buat node tugas
Buka halaman Data Development.
Login ke Konsol DataWorks.
Di bilah navigasi atas, pilih kelompok sumber daya dan wilayah.
Di panel navigasi kiri, klik .
Pilih ruang kerja target dan klik Go to Data Studio.
Di Konsol Data Studio, klik ikon
 di sebelah kanan Workspace Directories, lalu pilih .
di sebelah kanan Workspace Directories, lalu pilih .Di kotak dialog Create Node, pilih Path. Atur sumber data ke Tablestore dan tujuan ke MaxCompute(ODPS). Masukkan Name dan klik OK.
Konfigurasikan tugas sinkronisasi
Di Workspace Directories, klik node tugas sinkronisasi batch baru untuk membukanya. Anda dapat mengonfigurasi tugas sinkronisasi di antarmuka tanpa kode atau menggunakan editor kode.
Antarmuka tanpa kode (default)
Konfigurasikan item-item berikut di antarmuka tanpa kode:
Data Source: Pilih sumber dan tujuan sumber data.
Runtime Resource: Pilih kelompok sumber daya. Sistem secara otomatis menguji konektivitas sumber data setelah Anda melakukan pemilihan.
Data Source:
Table: Pilih tabel data sumber dari daftar drop-down.
Primary Key Range (Start): Tentukan awal rentang kunci primer dari mana data dibaca. Nilainya harus dalam format array JSON.
inf_minmerepresentasikan nilai tak hingga kecil.Sebagai contoh, jika kunci primer terdiri dari kolom
intbernamaiddan kolomstringbernamaname, konfigurasi contohnya sebagai berikut:Rentang kunci primer tertentu
Data lengkap
[ { "type": "int", "value": "000" }, { "type": "string", "value": "aaa" } ][ { "type": "inf_min" }, { "type": "inf_min" } ]Primary Key Range (End): Tentukan akhir rentang kunci primer dari mana data dibaca. Nilainya harus dalam format array JSON.
inf_maxmerepresentasikan nilai tak hingga besar.Sebagai contoh, jika kunci primer terdiri dari kolom
intbernamaiddan kolomstringbernamaname, konfigurasi contohnya sebagai berikut:Rentang kunci primer tertentu
Data lengkap
[ { "type": "int", "value": "999" }, { "type": "string", "value": "zzz" } ][ { "type": "inf_max" }, { "type": "inf_max" } ]Splitting Configuration: Tentukan informasi konfigurasi pemisahan kustom dalam format array JSON. Dalam kebanyakan kasus, kami menyarankan agar Anda tidak mengonfigurasi parameter ini. Jika tidak dikonfigurasi, atur nilainya menjadi
[].Jika terjadi hot spot pada penyimpanan data Tablestore dan kebijakan pemisahan otomatis Tablestore Reader tidak efektif, gunakan aturan pemisahan kustom. Aturan ini menentukan titik pemisahan dalam rentang kunci primer awal dan akhir. Anda hanya perlu mengonfigurasi kunci shard dan tidak perlu menentukan semua kunci primer.
Destination: Konfigurasikan item-item berikut. Biarkan nilai default untuk parameter lain atau ubah sesuai kebutuhan.
Production Project Name: Nama proyek MaxCompute yang terkait dengan sumber data tujuan. Parameter ini diisi otomatis.
Tunnel Resource Group: Nilai default adalah Common transmission resources. Kelompok sumber daya ini menggunakan kuota gratis MaxCompute. Pilih kelompok sumber daya Tunnel khusus sesuai kebutuhan.
Table: Pilih tabel tujuan. Klik Generate Target Table Schema untuk membuat tabel tujuan secara otomatis.
Partition: Tentukan partisi tempat data yang disinkronkan disimpan. Parameter ini dapat digunakan untuk sinkronisasi inkremental harian.
Write Mode: Pilih apakah akan menghapus data yang ada sebelum menulis atau menambahkan data ke tabel.
Destination Field Mapping: Konfigurasikan pemetaan bidang dari tabel sumber ke tabel tujuan. Sistem secara otomatis memetakan bidang berdasarkan tabel sumber. Ubah pemetaan sesuai kebutuhan.
Setelah menyelesaikan konfigurasi, klik Save di bagian atas halaman.
Editor kode
Klik Code Editor di bagian atas halaman untuk mengedit skrip di editor.
Skrip contoh berikut digunakan untuk tabel data sumber yang kunci primernya terdiri dari kolomintbernamaiddan kolomstringbernamaname. Kolom atributnya adalah bidangintbernamaage. Dalam skrip Anda, ganti nilai parameterdatasourcedantabledengan nilai aktual Anda.
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "ots",
"parameter": {
"datasource": "source_data",
"column": [
{
"name": "id",
"type": "INTEGER"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "age",
"type": "INTEGER"
}
],
"range": {
"begin": [
{
"type": "inf_min"
},
{
"type": "inf_min"
}
],
"end": [
{
"type": "inf_max"
},
{
"type": "inf_max"
}
],
"split": []
},
"table": "source_table",
"newVersion": "true"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "odps",
"parameter": {
"partition": "pt=${bizdate}",
"truncate": true,
"datasource": "target_data",
"tunnelQuota": "default",
"column": [
"id",
"name",
"age"
],
"emptyAsNull": false,
"guid": null,
"table": "source_table",
"consistencyCommit": false
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 2,
"throttle": false
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Setelah selesai mengedit skrip, klik Save di bagian atas halaman.
Jalankan tugas sinkronisasi
Klik Debug Configuration di sisi kanan halaman. Pilih kelompok sumber daya untuk menjalankan tugas dan tambahkan Script Parameters.
bizdate: Partisi data tabel tujuan MaxCompute. Contohnya,
20251120.
Klik Run di bagian atas halaman untuk memulai tugas sinkronisasi.
Langkah 4: Lihat hasil sinkronisasi
Setelah tugas sinkronisasi selesai, lihat status eksekusinya di log dan periksa data yang telah disinkronkan di Konsol DataWorks.
Lihat status dan hasil eksekusi tugas di bagian bawah halaman. Informasi log berikut menunjukkan bahwa tugas sinkronisasi berhasil dijalankan.
2025-11-18 11:16:23 INFO Shell run successfully! 2025-11-18 11:16:23 INFO Current task status: FINISH 2025-11-18 11:16:23 INFO Cost time is: 77.208sLihat data yang telah disinkronkan di tabel tujuan.
Buka Konsol DataWorks. Di panel navigasi kiri, klik . Lalu, klik Go to Data Map untuk melihat tabel tujuan beserta datanya.