Konfigurasikan tugas sinkronisasi batch di DataWorks untuk menyinkronkan data baru dan yang berubah dari Tablestore ke OSS secara berkala. Hal ini memungkinkan pencadangan data serta pemrosesan lanjutan.
Persiapan
Peroleh nama instans, titik akhir (endpoint), dan ID wilayah dari tabel Tablestore sumber. Anda juga harus mengaktifkan fitur Stream untuk tabel sumber.
Untuk tabel data, aktifkan fitur Stream saat membuat atau mengubah tabel. Untuk tabel deret waktu, fitur ini diaktifkan secara default.
Buat AccessKey untuk Akun Alibaba Cloud Anda atau pengguna RAM yang memiliki izin untuk Tablestore dan OSS.
Aktifkan DataWorks dan buat ruang kerja di wilayah yang sama dengan bucket OSS atau instans Tablestore Anda.
Buat kelompok sumber daya Serverless dan sambungkan ke ruang kerja. Untuk informasi lebih lanjut tentang penagihan, lihat Penagihan kelompok sumber daya Serverless.
Jika instans DataWorks dan Tablestore Anda berada di wilayah yang berbeda, Anda harus membuat koneksi peering VPC untuk menetapkan konektivitas jaringan cross-region.
Contoh berikut menunjukkan kasus penggunaan di mana instans tabel sumber berada di wilayah China (Shanghai) dan ruang kerja DataWorks berada di wilayah China (Hangzhou).
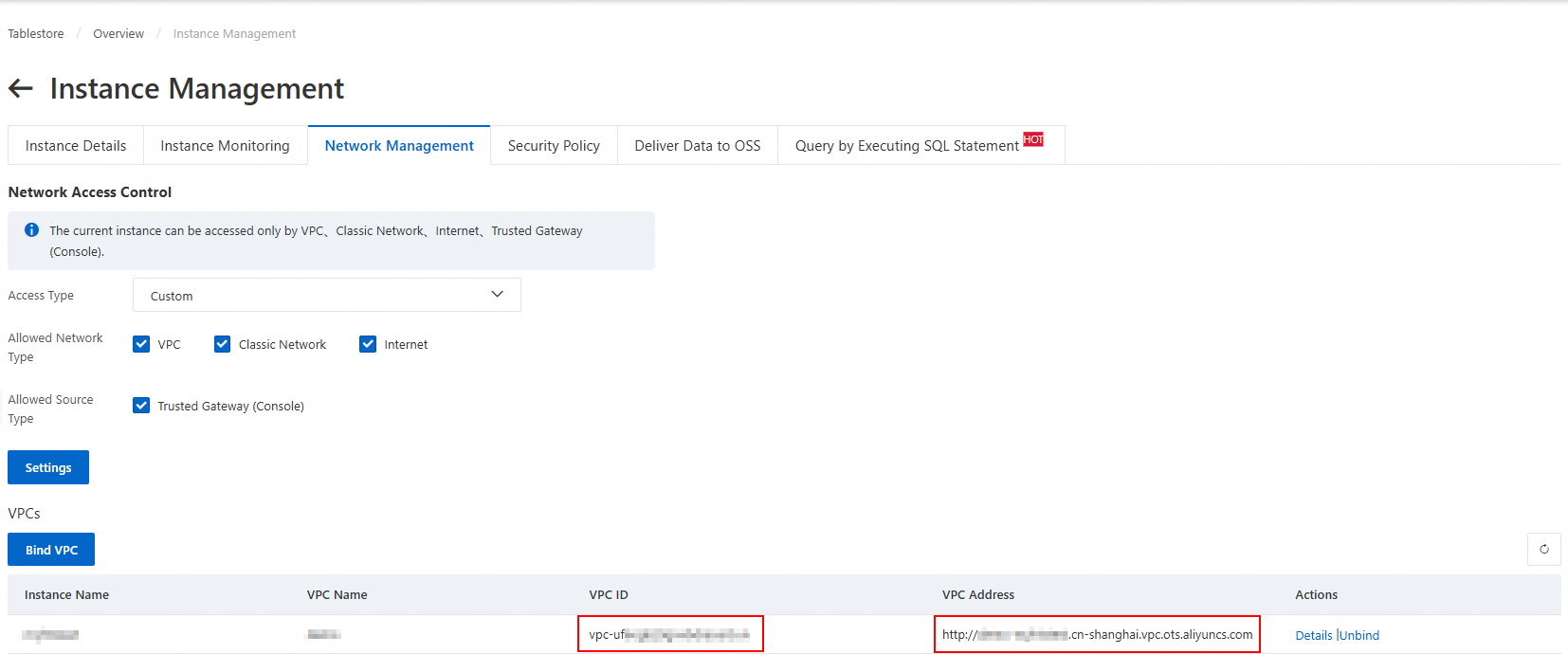
Sambungkan VPC ke instans Tablestore.
Login ke Konsol Tablestore. Di bilah navigasi atas, pilih wilayah tempat tabel target berada.
Klik alias instans untuk menuju halaman Instance Management.
Di tab Network Management, klik Bind VPC. Pilih VPC dan vSwitch, masukkan nama VPC, lalu klik OK.
Tunggu hingga VPC tersambung. Halaman akan otomatis dimuat ulang untuk menampilkan VPC ID dan VPC Address dalam daftar VPC.
CatatanSaat Anda menambahkan sumber data Tablestore di Konsol DataWorks, Anda harus menggunakan alamat VPC ini.
Peroleh informasi VPC untuk kelompok sumber daya ruang kerja DataWorks.
Login ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah tempat ruang kerja Anda berada. Di panel navigasi kiri, klik Workspace untuk menuju halaman Workspaces.
Klik nama ruang kerja untuk menuju halaman Workspace Details. Di panel navigasi kiri, klik Resource Group untuk melihat kelompok sumber daya yang terhubung ke ruang kerja.
Di sebelah kanan kelompok sumber daya target, klik Network Settings. Di bagian Data Scheduling & Data Integration, lihat VPC ID dari virtual private cloud yang terhubung.
Buat koneksi peering VPC dan konfigurasi entri rute.
Login ke Konsol VPC. Di panel navigasi kiri, klik VPC Peering Connection, lalu klik Create VPC Peering Connection.
Di halaman Create VPC Peering Connection, masukkan nama untuk koneksi peering dan pilih instans VPC peminta, tipe akun penerima, wilayah penerima, dan instans VPC penerima. Lalu, klik OK.
Di halaman VPC Peering Connection, temukan koneksi peering VPC tersebut dan klik Configure route di kolom Requester VPC dan Accepter.
Untuk blok CIDR tujuan, masukkan blok CIDR dari VPC peer. Misalnya, saat Anda mengonfigurasi entri rute untuk VPC peminta, masukkan blok CIDR dari VPC penerima. Saat Anda mengonfigurasi entri rute untuk VPC penerima, masukkan blok CIDR dari VPC peminta.
Prosedur
Langkah 1: Tambahkan sumber data Tablestore
Konfigurasikan sumber data Tablestore di DataWorks untuk menghubungkan ke data sumber.
Login ke Konsol DataWorks. Alihkan ke wilayah tujuan. Di panel navigasi kiri, pilih . Dari daftar drop-down, pilih ruang kerja dan klik Go To Data Integration.
Di panel navigasi kiri, klik Data source.
Di halaman Data Sources, klik Add Data Source.
Di kotak dialog Add Data Source, cari dan pilih Tablestore sebagai tipe sumber data.
Di kotak dialog Add OTS Data Source, konfigurasikan parameter sumber data seperti dijelaskan dalam tabel berikut.
Parameter
Deskripsi
Data Source Name
Nama sumber data harus merupakan kombinasi huruf, angka, dan garis bawah (_). Nama tidak boleh diawali dengan angka atau garis bawah (_).
Data Source Description
Deskripsi singkat mengenai sumber data. Panjang deskripsi tidak boleh melebihi 80 karakter.
Region
Pilih wilayah tempat instans Tablestore berada.
Tablestore Instance Name
Nama instans Tablestore.
Endpoint
Titik akhir (endpoint) instans Tablestore. Gunakan alamat VPC.
AccessKey ID
ID AccessKey dan Rahasia AccessKey dari Akun Alibaba Cloud atau pengguna RAM.
AccessKey Secret
Uji konektivitas kelompok sumber daya.
Saat membuat sumber data, Anda harus menguji konektivitas kelompok sumber daya untuk memastikan bahwa kelompok sumber daya untuk tugas sinkronisasi dapat terhubung ke sumber data. Jika tidak, tugas sinkronisasi data tidak dapat dijalankan.
Di bagian Connection Configuration, klik Test Network Connectivity di kolom Connection Status untuk kelompok sumber daya.
Setelah uji konektivitas berhasil, klik Complete. Sumber data baru akan muncul dalam daftar sumber data.
Jika uji konektivitas gagal, gunakan Network Connectivity Diagnostic Tool untuk memecahkan masalah.
Langkah 2: Tambahkan sumber data OSS
Konfigurasikan sumber data OSS sebagai tujuan ekspor data.
Klik Add Data Source lagi. Di kotak dialog, cari dan pilih OSS sebagai tipe sumber data, lalu konfigurasikan parameter sumber data.
Parameter
Deskripsi
Data Source Name
Nama sumber data harus terdiri dari huruf, angka, dan garis bawah (_). Nama tidak boleh diawali dengan angka atau garis bawah (_).
Data Source Description
Deskripsi singkat mengenai sumber data. Panjang deskripsi tidak boleh melebihi 80 karakter.
Access Mode
RAM Role Authorization Mode: Akun layanan DataWorks mengakses sumber data dengan mengasumsikan peran RAM. Jika ini pertama kalinya Anda memilih mode ini, ikuti petunjuk di layar untuk memberikan izin yang diperlukan.
AccessKey Mode: Akses sumber data menggunakan ID AccessKey dan Rahasia AccessKey dari Akun Alibaba Cloud atau pengguna RAM.
Role
Parameter ini hanya diperlukan jika Anda mengatur Access Mode ke RAM Role Authorization Mode.
AccessKey ID
Parameter ini hanya diperlukan jika Anda mengatur Access Mode ke AccessKey Mode. ID AccessKey dan Rahasia AccessKey dari Akun Alibaba Cloud atau pengguna RAM.
AccessKey Secret
Region
Wilayah tempat bucket berada.
Endpoint
Nama domain OSS. Untuk informasi lebih lanjut, lihat Regions and endpoints.
Bucket
Nama bucket.
Setelah Anda mengonfigurasi parameter dan uji konektivitas berhasil, klik Complete untuk menambahkan sumber data.
Langkah 3: Konfigurasikan tugas sinkronisasi batch
Buat dan konfigurasikan tugas sinkronisasi data untuk menentukan aturan transfer data dari Tablestore ke OSS.
Buat node tugas
Navigasi ke halaman Data Development.
Login ke Konsol DataWorks.
Di bilah navigasi atas, pilih kelompok sumber daya dan wilayah.
Di panel navigasi kiri, klik .
Pilih ruang kerja yang sesuai dan klik Go To Data Studio.
Di Konsol Data Studio, klik ikon
 di sebelah Workspace Directories, lalu pilih .
di sebelah Workspace Directories, lalu pilih .Di kotak dialog Create Node, pilih Path. Atur sumber ke Tablestore Stream dan tujuan ke OSS. Masukkan Name dan klik OK.
Konfigurasikan tugas sinkronisasi
Di Direktori Proyek, klik node tugas sinkronisasi batch baru dan konfigurasikan menggunakan antarmuka tanpa kode (codeless UI) atau editor kode.
Saat Anda menyinkronkan tabel deret waktu, hanya gunakan editor kode untuk mengonfigurasi tugas sinkronisasi.
Antarmuka tanpa kode (default)
Konfigurasikan item berikut:
Data Source: Pilih sumber data untuk sumber dan tujuan.
Runtime Resource: Pilih kelompok sumber daya. Sistem secara otomatis menguji konektivitas sumber data.
Data Source: Pilih tabel data sumber. Pertahankan pengaturan default untuk parameter lain atau ubah sesuai kebutuhan.
Destination: Pilih Text Type dan konfigurasikan parameter yang sesuai.
Text Type: Jenis teks yang didukung adalah csv, text, orc, dan parquet.
Object Name (Path Included): Jalur dan nama file di bucket OSS. Contoh:
tablestore/resource_table.csv.Column Delimiter: Default-nya adalah
,. Untuk pembatas non-visibel, masukkan encoding Unicode, seperti\u001batau\u007c.Object Path: Jalur file di bucket OSS. Parameter ini hanya diperlukan untuk file parquet.
File Name: Nama file di bucket OSS. Parameter ini hanya diperlukan ketika jenis file adalah parquet.
Destination Field Mapping: Pemetaan dikonfigurasi secara otomatis berdasarkan kunci primer tabel sumber dan data perubahan inkremental. Ubah pemetaan sesuai kebutuhan.
Klik Save di bagian atas halaman setelah Anda menyelesaikan konfigurasi.
Editor kode
Klik Code Editor di bagian atas halaman untuk mengedit skrip.
Tabel data
Contoh berikut menunjukkan cara mengonfigurasi tugas dengan jenis file tujuan CSV. Tabel data sumber memiliki kunci primer yang mencakup satu kolom kunci primer int bernama id dan satu kolom kunci primer string bernama name. Saat mengonfigurasi tugas, ganti datasource, table, dan nama file tujuan (object) dalam skrip contoh.
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "otsstream",
"parameter": {
"statusTable": "TableStoreStreamReaderStatusTable",
"maxRetries": 31,
"isExportSequenceInfo": false,
"datasource": "source_data",
"column": [
"id",
"name",
"colName",
"version",
"colValue",
"opType",
"sequenceInfo"
],
"startTimeString": "${startTime}",
"table": "source_table",
"endTimeString": "${endTime}"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "oss",
"parameter": {
"dateFormat": "yyyy-MM-dd HH:mm:ss",
"datasource": "target_data",
"writeSingleObject": false,
"column": [
"0",
"1",
"2",
"3",
"4",
"5",
"6"
],
"writeMode": "truncate",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileFormat": "csv",
"object": "tablestore/source_table.csv"
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 2,
"throttle": false
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Tabel deret waktu
Contoh berikut menunjukkan cara mengonfigurasi tugas dengan jenis file tujuan CSV. Data timeline tabel deret waktu sumber mencakup satu kolom atribut int bernama value. Saat mengonfigurasi tugas, ganti datasource, table, dan nama file tujuan (object) dalam skrip contoh.
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "otsstream",
"parameter": {
"statusTable": "TableStoreStreamReaderStatusTable",
"maxRetries": 31,
"isExportSequenceInfo": false,
"datasource": "source_data",
"column": [
{
"name": "_m_name"
},
{
"name": "_data_source"
},
{
"name": "_tags"
},
{
"name": "_time"
},
{
"name": "value",
"type": "int"
}
],
"startTimeString": "${startTime}",
"table": "source_series",
"isTimeseriesTable":"true",
"mode": "single_version_and_update_only",
"endTimeString": "${endTime}"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "oss",
"parameter": {
"dateFormat": "yyyy-MM-dd HH:mm:ss",
"datasource": "target_data",
"writeSingleObject": false,
"writeMode": "truncate",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileFormat": "csv",
"object": "tablestore/source_series.csv"
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 2,
"throttle": false
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Setelah selesai mengedit skrip, klik Save di bagian atas halaman.
Debug tugas sinkronisasi
Di sisi kanan halaman, klik Debugging Configurations. Pilih kelompok sumber daya untuk tugas dan tentukan Script Parameters.
startTime: Waktu mulai inklusif untuk sinkronisasi data inkremental. Contoh:
20251119200000.endTime: Waktu akhir untuk sinkronisasi data inkremental (eksklusif). Contoh:
20251119205000.Sinkronisasi inkremental menggunakan jadwal berulang yang berjalan setiap 5 menit. Plugin memperkenalkan latensi 5 menit. Hal ini menghasilkan latensi sinkronisasi total 5 hingga 10 menit. Saat mengonfigurasi waktu akhir, hindari menetapkan waktu yang berada dalam rentang 10 menit dari waktu saat ini.
Klik Run di bagian atas halaman untuk memulai tugas sinkronisasi.
Nilai contoh di atas menunjukkan bahwa data inkremental disinkronkan dari pukul
20:00 pada tanggal11/19/2025hingga pukul20:50(eksklusif).
Langkah 4: Lihat hasil sinkronisasi
Setelah tugas sinkronisasi selesai, Anda dapat melihat status eksekusi di log dan memeriksa file hasil di bucket OSS.
Lihat status dan hasil eksekusi tugas di bagian bawah halaman. Informasi log berikut menunjukkan bahwa tugas sinkronisasi berhasil dijalankan.
2025-11-18 11:16:23 INFO Shell run successfully! 2025-11-18 11:16:23 INFO Current task status: FINISH 2025-11-18 11:16:23 INFO Cost time is: 77.208sLihat file di bucket tujuan.
Buka Daftar Bucket. Klik bucket tujuan untuk melihat atau mengunduh file hasil.
Tayang
Setelah debugging selesai, konfigurasikan parameter penjadwalan startTime dan endTime serta kebijakan penjadwalan berulang di panel Scheduling Settings di sisi kanan halaman. Kemudian, publikasikan tugas ke lingkungan produksi. Untuk informasi lebih lanjut tentang aturan konfigurasi, lihat Configure and use scheduling parameters, Scheduling policy, dan Scheduling time.