The cloud-native data warehouse AnalyticDB for PostgreSQL provides a simple, fast, and cost-effective petabyte-scale cloud data warehouse solution. Using Data Transmission Service (DTS), you can synchronize data from PolarDB for MySQL to the cloud-native data warehouse AnalyticDB for PostgreSQL. This lets you quickly perform ad-hoc query analysis, extract, transform, and load (ETL) processing, and visual exploration of massive datasets.
Prerequisites
- Binary logging (binlog) is enabled for the PolarDB for MySQL cluster. For more information, see Enable binary logging.
- PolarDB for MySQL cluster must have primary keys.
- You have created a destination cloud-native data warehouse AnalyticDB for PostgreSQL instance. For more information, see Create a cloud-native data warehouse AnalyticDB for PostgreSQL instance.
Notes
- DTS consumes read and write resources from the source and destination databases during the initial full data synchronization, which can increase the database load. If your database has poor performance, low specifications, or a high workload, the pressure on your database may increase. For example, if the source database contains many slow SQL statements or tables without primary keys, or if deadlocks occur in the destination database, the database service may become unavailable. Before you synchronize data, evaluate the performance of the source and destination databases. We recommend that you synchronize data during off-peak hours, such as when the CPU load of both the source and destination databases is below 30%.
- During the initial full data synchronization, concurrent INSERT operations cause table fragmentation in the destination instance. As a result, the tablespace of the destination instance is larger than that of the source cluster after the synchronization is complete.
Billing
Synchronization type | Pricing |
Schema synchronization and full data synchronization | Free of charge. |
Incremental data synchronization | Charged. For more information, see Billing overview. |
Synchronization limitations
-
Only data tables can be synchronized.
-
Data synchronization is not supported for the following data types: BIT, VARBIT, GEOMETRY, ARRAY, UUID, TSQUERY, TSVECTOR, TXID_SNAPSHOT, and POINT.
-
Prefix indexes are not supported. If prefix indexes exist in the source database, the data synchronization task may fail.
-
During data synchronization, do not perform online DDL changes on the synchronization objects in the source database using tools such as gh-ost or pt-online-schema-change. Otherwise, the synchronization task will fail.
Supported SQL operations
-
DML operations: INSERT, UPDATE, and DELETE.
-
DDL operations: ADD COLUMN.
NoteThe CREATE TABLE operation is not supported. If you need to add a new table as a synchronization object, you must add a synchronization object.
Supported synchronization topologies
-
One-to-one one-way synchronization.
-
One-to-many one-way synchronization.
-
Many-to-one one-way synchronization.
Glossary
| PolarDB for MySQL | Cloud-native data warehouse AnalyticDB for PostgreSQL |
| Database | Schema |
| Table | Table |
Procedure
- Purchase a data synchronization job. For more information, see Purchase procedure.
Note When you purchase the job, set Source Instance to Apsara PolarDB, Destination Instance to AnalyticDB for PostgreSQL, and Synchronization Topology to one-way synchronization.
-
Log on to the Data Transmission Service console.
-
In the navigation pane on the left, click Data Synchronization.
-
At the top of the Synchronization Tasks page, select the region where the destination instance is located.
-
Find the purchased data synchronization instance and click Configure Synchronization Channel.
- Configure the source and destination instances for the synchronization channel.
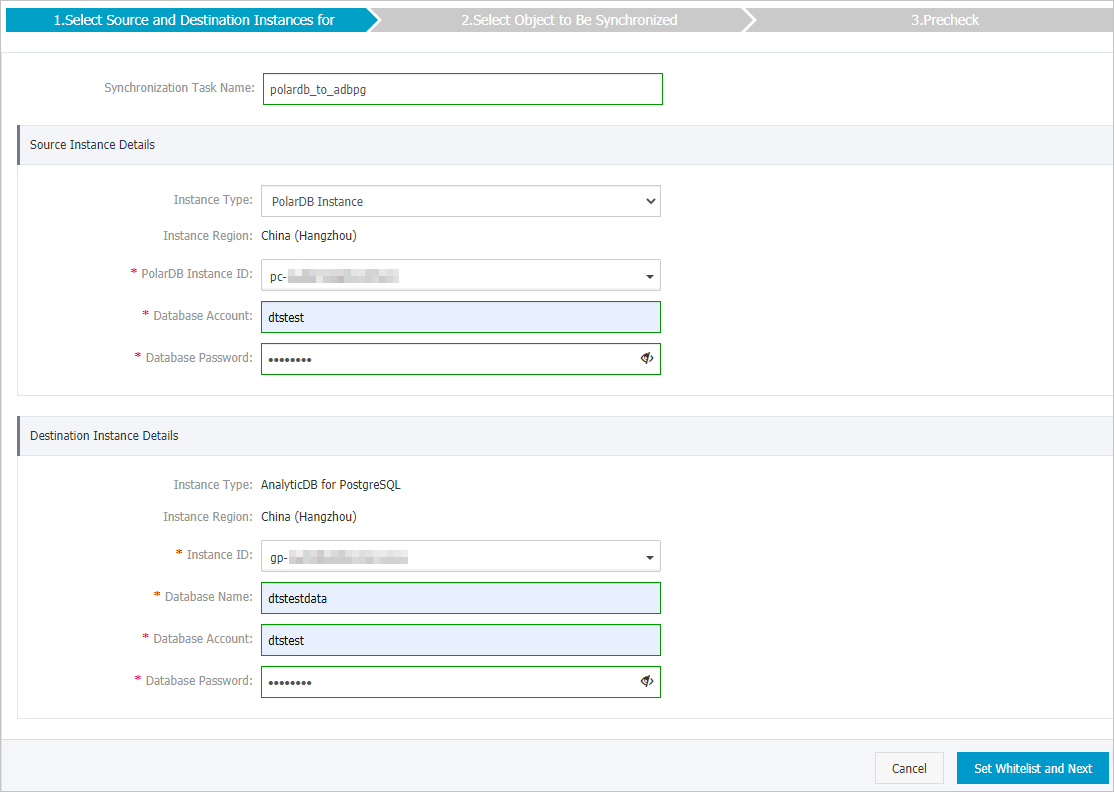
Category Configuration Description N/A Sync Job Name DTS automatically generates a name for the sync job. Specify a descriptive name for easy identification. The name does not need to be unique. Source Instance Information Instance Type This is fixed to PolarDB Instance. Instance Region The region of the source PolarDB for MySQL cluster that you selected when you purchased the data synchronization instance. This cannot be changed. PolarDB Instance ID Select the ID of the PolarDB for MySQL cluster. Database Account Enter the database account of the PolarDB for MySQL cluster. Note This account must have the read permission on the objects to be synchronized.Database Password Enter the password for the database account. Target instance information Instance Type AnalyticDB for PostgreSQLFixed as . You do not need to set this parameter. Instance Region The region of the destination instance that you selected when you purchased the data synchronization instance. This cannot be changed. Instance ID Select the instance ID of the cloud-native data warehouse AnalyticDB for PostgreSQL. Database Name Enter the name of the database in the cloud-native data warehouse AnalyticDB for PostgreSQL instance that contains the destination tables. Database Account Enter the Initial Account of the cloud-native data warehouse AnalyticDB for PostgreSQLCreate and manage users. Note You can also enter an account that has the RDS_SUPERUSER permission. For information about how to create such an account, see User permission management.Database Password Enter the password for the database account. -
In the lower-right corner of the page, click Set Whitelist and Next.
If the source or destination database is an Alibaba Cloud database instance, such as an ApsaraDB RDS for MySQL or ApsaraDB for MongoDB instance, DTS automatically adds the CIDR blocks of DTS servers to the IP address whitelist of the instance. If the source or destination database is a self-managed database hosted on an Elastic Compute Service (ECS) instance, DTS automatically adds the CIDR blocks of DTS servers to the security group rules of the ECS instance, and you must make sure that the ECS instance can access the database. If the self-managed database is hosted on multiple ECS instances, you must manually add the CIDR blocks of DTS servers to the security group rules of each ECS instance. If the source or destination database is a self-managed database that is deployed in a data center or provided by a third-party cloud service provider, you must manually add the CIDR blocks of DTS servers to the IP address whitelist of the database to allow DTS to access the database. For more information, see DTS server IP whitelist.
WarningAdding the public IP address blocks of the DTS service, either automatically or manually, may pose security risks. Using this product, you acknowledge that you understand and accept the potential security risks and that you must implement basic security measures. These measures include, but are not limited to, strengthening password security, limiting the ports open to each CIDR block, using authentication for internal API calls, and regularly checking and restricting unnecessary CIDR blocks. Alternatively, you can connect through a private network using a leased line, VPN Gateway, or Smart Access Gateway.
-
Configure the synchronization policy and synchronization objects.
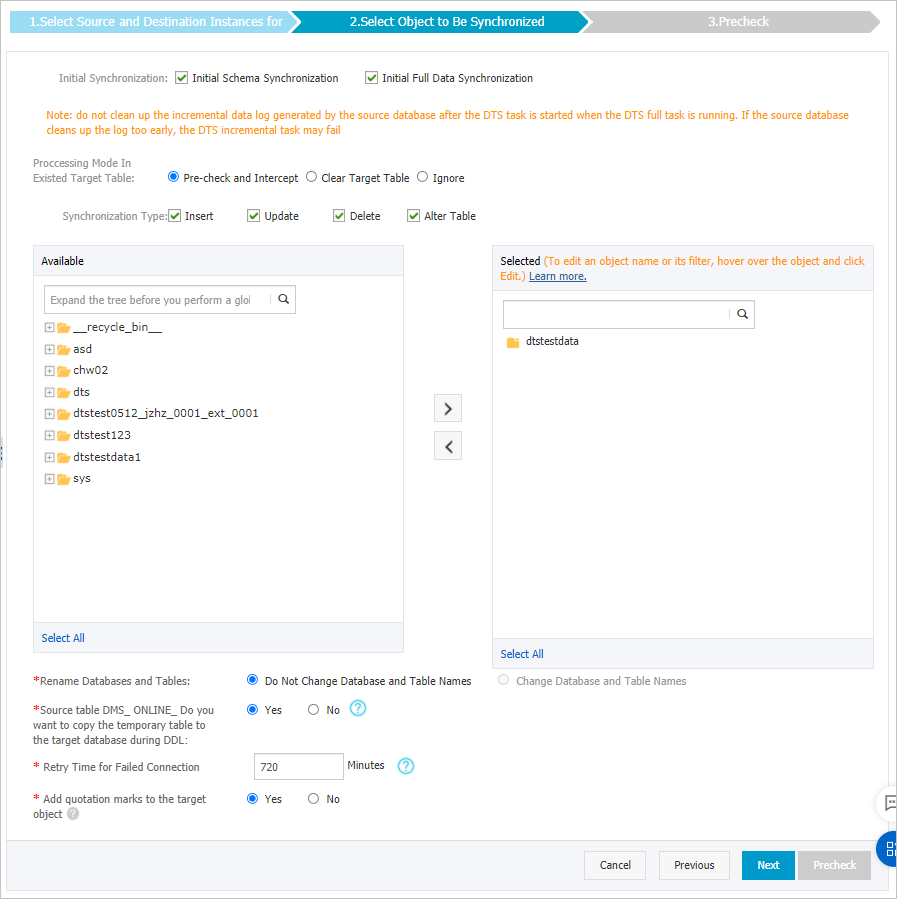
Category
Parameter
Description
Synchronization Policy Configuration
Synchronization Initialization
By default, you must select both Schema Initialization and Full Data Initialization. After the precheck is complete, DTS initializes the schema and data of the objects to be synchronized in the destination instance. This serves as the baseline data for subsequent incremental synchronization.
Processing Mode of Conflicting Tables
-
Clear Data in Destination Table
Skips the Schema Name Conflict precheck item. Before full initialization, the data in the destination table is cleared. This mode is suitable for formal synchronization after a synchronization task test is complete.
-
Ignore Errors and Proceed
Skips the Schema Name Conflict precheck item. During full initialization, data is directly appended. This mode is suitable for scenarios where data from multiple tables is synchronized to a single summary table.
Synchronization Operation Type
Select the operation types to be synchronized based on your business needs:
-
Insert
-
Update
-
Delete
-
AlterTable
Select Synchronization Objects
N/A
In the Source Objects box, click the tables to be synchronized and click the
 icon to move them to the Selected Objects box.Note
icon to move them to the Selected Objects box.Note-
The synchronization objects are selected at the table level.
-
If you need the column names in the destination table to be different from those in the source table, use the field mapping feature of DTS. For more information, see Specify the names of synchronization objects in the destination instance.
Change Mapped Name
N/A
To rename synchronized objects in the destination instance, use the object name mapping feature. For more information, see database, table, and column mapping.
Replicate Temporary Tables to Destination Database During DMS_ONLINE_DDL on Source Table
N/A
If you use Data Management Service (DMS) to perform online DDL changes on the source database, you can specify whether to synchronize the temporary tables generated by these changes.
-
Yes: Synchronize data from temporary tables generated by online DDL changes.
NoteIf online DDL changes generate a large volume of data in temporary tables, data synchronization may be delayed.
-
No: Do not synchronize data from temporary tables. Only the original DDL data from the source database is synchronized.
NoteThis option causes table locking in the destination database.
Retry Duration for Unreachable Source or Destination Database
N/A
By default, if DTS fails to connect to the source or destination database, it retries for 720 minutes (12 hours). You can also specify a custom retry duration. The synchronization task automatically resumes if DTS reconnects within the specified duration; otherwise, the task fails.
NoteBecause DTS instances are charged during the connection retry period, set a custom retry duration based on your business requirements, or release the DTS instance promptly after the source and destination instances are released.
-
-
Set the primary key column and distribution column for the tables to be synchronized in the cloud-native data warehouse AnalyticDB for PostgreSQL instance.
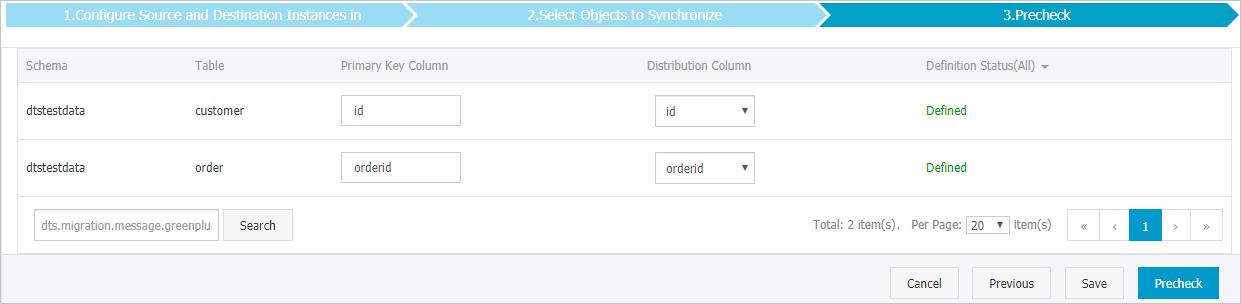 Note
NoteThis page appears only if you selected Schema Initialization in the previous step. For more information about primary key columns and distribution columns, see Table constraint definitions and Table distribution definitions.
In the lower-right corner of the page, click Precheck.
NoteBefore the task starts, DTS runs a precheck. The task starts only after it passes the precheck.
If the precheck fails, click the
 icon next to the failed item to view the details.
icon next to the failed item to view the details.You can fix the issues based on the details and then run the precheck again.
If you do not need to fix a warning item, you can click Acknowledge and Ignore or Ignore and Precheck Again to skip the item and run the precheck again.
-
After the Precheck dialog box shows that the task Precheck Passed, close the Precheck dialog box. The synchronization task starts.
-
Wait for the synchronization channel to be initialized until the task enters the Synchronizing state.
You can view the status of the data synchronization task on the Data Synchronization page.
