ChatBI uses natural language to SQL (NL2SQL) technology to translate plain-language questions into SQL queries and generate reports automatically. This tutorial walks through the complete ChatBI setup using a fictional restaurant chain, "Ali Xiang", so you can follow along end-to-end.
What you'll learn
-
Enable the PolarDB for AI feature and connect to the AI node
-
Prepare a schema that the large language model (LLM) can understand
-
Build a schema index and run NL2SQL queries
-
Improve model accuracy with question templates and configuration hints
-
Retrain the model with your own data
Prerequisites
Before you begin, make sure you have:
-
A PolarDB for MySQL cluster with an AI node added. For setup instructions, see Enable the PolarDB for AI feature.
-
A database account for the AI node with read and write permissions on the target tables.
If you added an AI node when you purchased the cluster, you can set the database account directly. For more information, see Create a standard account.
Connect to the cluster using the Cluster Endpoint. For connection instructions, see Log on to PolarDB for AI.
When connecting from the command line, add the -c option. Data Management Service (DMS) defaults to the Primary Endpoint — manually switch to the Cluster Endpoint, then close the current SQL window and open a new one.
Prepare your data
"Ali Xiang" is a fictional restaurant chain. Its billing system contains three tables.
Why table comments matter
The LLM infers your schema's business meaning from table and column comments. Without comments, it relies on column names alone, which reduces accuracy — especially for ambiguous names like items or actual_amount. Adding descriptive comments is the single most effective step to improve NL2SQL precision.
Create the three tables with comments as shown below:
CREATE TABLE restaurant_info (
id INT COMMENT 'Outlet ID',
position VARCHAR(128) COMMENT 'Outlet location',
PRIMARY KEY (id)
) COMMENT='Outlet table';
CREATE TABLE menu_info (
id INT COMMENT 'Dish ID',
name VARCHAR(64) COMMENT 'Dish name',
type INT COMMENT 'Dish type',
unit_price INT COMMENT 'Unit price of the dish',
PRIMARY KEY (id)
) COMMENT='Menu table';
CREATE TABLE bill_info (
id INT COMMENT 'Bill ID',
items VARCHAR(512) COMMENT 'Ordered dishes',
actual_amount INT COMMENT 'Actual amount paid',
restaurant_id INT COMMENT 'Dining outlet',
waiter VARCHAR(16) COMMENT 'Waiter',
diner_count INT COMMENT 'Number of diners',
pay_time DATE COMMENT 'Payment time',
PRIMARY KEY (id)
) COMMENT='Bill table';Build a schema index
ChatBI needs a searchable index of your table schemas so it can identify relevant tables when answering each question. Run the following statement to create the index table schema_index:
/*polar4ai*/CREATE TABLE schema_index(id integer, table_name varchar, table_comment text_ik_max_word, table_ddl text_ik_max_word, column_names text_ik_max_word, column_comments text_ik_max_word, sample_values text_ik_max_word, vecs vector_768,ext text_ik_max_word, PRIMARY key (id));This table is not directly visible in the database. To list all PolarDB for AI tables, run:
/*polar4ai*/SHOW TABLES;Next, import your table schemas into the index. PolarDB for AI vectorizes all tables in the current database and samples column values automatically.
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema') INTO schema_index;This runs as a background task. A task_id is returned (for example, bce632ea-97e9-11ee-bdd2-492f4dfe0918). Poll the task status until taskStatus is finish:
/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;Run NL2SQL queries
With the schema index ready, submit natural language questions to the NL2SQL model. All queries use the /*polar4ai*/ prefix and the PREDICT function.
The following example asks for the week's total income:
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select 'What is the total income for this week') WITH (basic_index_name='schema_index');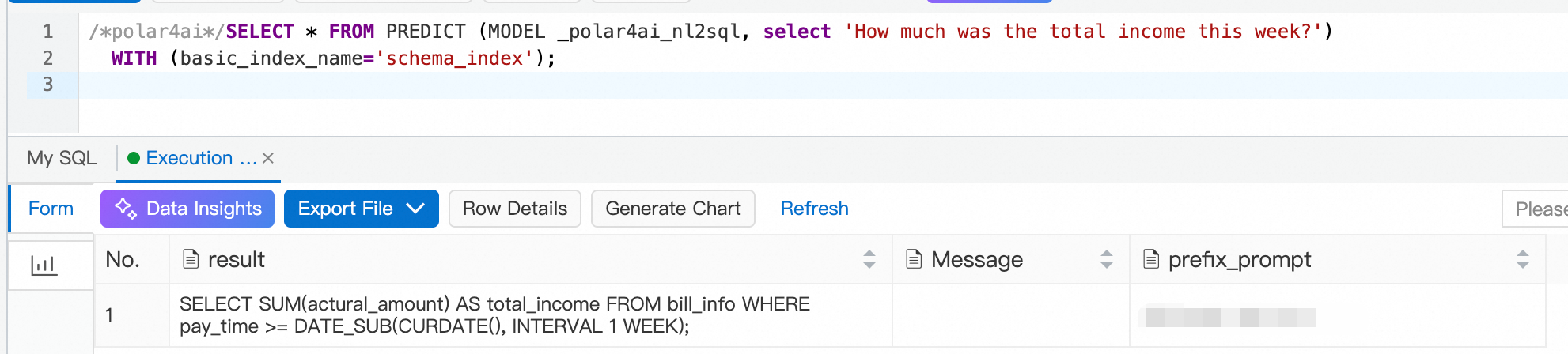
The table below shows typical questions and the SQL statements the model generates. The examples cover GROUP BY, multi-table JOIN, ORDER BY, and computed formulas.
| No. | Question | Generated SQL |
|---|---|---|
| 1 | Sort outlets by income | SELECT restaurant_id, SUM(actual_amount) AS total_income FROM bill_info GROUP BY restaurant_id ORDER BY total_income DESC; |
| 2 | Which outlet in Shanghai has the highest income? | SELECT b.restaurant_id FROM restaurant_info r JOIN bill_info b ON r.id = b.restaurant_id WHERE r.position LIKE '%Shanghai%' GROUP BY r.position ORDER BY SUM(b.actual_amount) DESC LIMIT 1; |
| 3 | What is the average spending per person in Shanghai? | SELECT AVG(bill_info.actual_amount / bill_info.diner_count) AS average_consumption_per_person FROM bill_info WHERE bill_info.restaurant_id IN (SELECT id FROM restaurant_info WHERE position = 'Shanghai'); |
| 4 | What are the top ten most ordered dishes this month? | SELECT mi.name, SUM(bi.items) as total_orders FROM bill_info bi JOIN menu_info mi ON bi.items = mi.id WHERE bi.pay_time >= '2024-10-01' AND bi.pay_time < '2024-11-01' GROUP BY mi.name ORDER BY total_orders DESC LIMIT 10; |
| 5 | What is the month-over-month income growth percentage for this month compared to last month? | SELECT (SUM(CASE WHEN MONTH(pay_time) = 10 AND YEAR(pay_time) = 2024 THEN actual_amount ELSE 0 END) - SUM(CASE WHEN MONTH(pay_time) = 9 AND YEAR(pay_time) = 2024 THEN actual_amount ELSE 0 END)) / SUM(CASE WHEN MONTH(pay_time) = 9 AND YEAR(pay_time) = 2024 THEN actual_amount ELSE 0 END) * 100 AS growth_percentage FROM bill_info; |
| 6 | Which outlet in Shanghai has the highest customer traffic? | SELECT r.position, COUNT(b.id) AS customer_flow FROM restaurant_info r JOIN bill_info b ON r.id = b.restaurant_id WHERE r.position LIKE '%Shanghai%' GROUP BY r.id ORDER BY customer_flow DESC LIMIT 1; |
The model handles most questions well, but some responses may not match your intent. For example, question 2 returns restaurant_id rather than the outlet name. You can address this by rephrasing — "Which outlet in Shanghai has the highest income? Please return the outlet name." — or by using the accuracy improvement techniques below.
Improve model accuracy
Two mechanisms let you guide the model without retraining: question templates and LLM configuration hints.
Add question templates
Question templates provide verified question-to-SQL mappings. When a user's question matches a template, the model uses the pre-defined SQL as a reference, which significantly improves accuracy for known query patterns.
Step 1: Create the template table.
The table name must start with polar4ai_nl2sql_pattern and include these five columns:
CREATE TABLE `polar4ai_nl2sql_pattern` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key',
`pattern_question` text COMMENT 'Template question',
`pattern_description` text COMMENT 'Template description',
`pattern_sql` text COMMENT 'Template SQL',
`pattern_params` text COMMENT 'Template parameters',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;Step 2: Create the pattern index table.
/*polar4ai*/CREATE TABLE pattern_index(id integer, pattern_question
text_ik_max_word, pattern_description text_ik_max_word, pattern_sql
text_ik_max_word, pattern_params text_ik_max_word, pattern_tables
text_ik_max_word, vecs vector_768, PRIMARY key (id));Step 3: Add a template.
The following template fixes question 2 so it returns the outlet name. Use #{} slots to match variable parts of the question — here, #{position} matches any location name.
INSERT INTO polar4ai_nl2sql_pattern (id, pattern_question, pattern_description, pattern_sql, pattern_params) VALUES (
1,
"Which outlet in #{position} has the highest income?",
"Which outlet in [location] has the highest income?",
"SELECT r.position FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position LIKE '%#{position}%' ORDER BY b.actual_amount DESC LIMIT 1;",
'[{"table_name":"bill_info","param_info":[{"param_name":"#{position}","value":["Shanghai"]}], "explanation": "Consumption location"}]'
);Step 4: Import the templates into the index.
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern') INTO pattern_index;A task ID is returned. Check the status with /*polar4ai*/SHOW TASK 'xxx-xxx-xxx'.
If you updatepolar4ai_nl2sql_pattern, recreatepattern_indexfrom scratch. Delete the old index first: Then re-run the import statement.
/*polar4ai*/DROP TABLE pattern_index;Step 5: Run the query with the pattern index.
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select 'Which outlet in Shanghai has the highest income?') WITH
(basic_index_name='schema_index',pattern_index_name='pattern_index');
Configure LLM hints
The polar4ai_nl2sql_llm_config table lets you define preprocessing rules that are injected into the LLM prompt. Use it when the model misinterprets domain-specific terms or applies the wrong matching logic.
Create the configuration table:
CREATE TABLE `polar4ai_nl2sql_llm_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key',
`is_functional` int(11) NOT NULL DEFAULT '1' COMMENT 'Whether it is effective',
`text_condition` text COMMENT 'Text condition',
`query_function` text COMMENT 'Query processing',
`formula_function` text COMMENT 'Formula information',
`sql_condition` text COMMENT 'SQL condition',
`sql_function` text COMMENT 'SQL processing',
PRIMARY KEY (`id`)
);Vocabulary hints
Question 6 uses "customer traffic", but the LLM doesn't reliably map this to the diner_count column. Add a hint to define the term:
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
1,
1,
"customer traffic||customer flow",
"",
"Customer traffic or customer flow is counted as the sum of the number of diners",
"",
""
);-
is_functional=1activates the rule. -
text_conditionuses||as a separator — the rule applies when the question contains "customer traffic" or "customer flow". -
formula_functionuses text or a formula to explain the meaning of a technical term to the LLM.
No index rebuild is required for configuration table changes. The model reads the rules directly at query time.

Fuzzy matching hints
Question 3 may fail if the model uses = for location matching instead of a LIKE clause. Add a global hint to enforce fuzzy matching on the position column:
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
2,
1,
"",
"",
"Matching for the outlet location 'position' requires a fuzzy search",
"",
""
);An empty text_condition means the rule applies to all queries. Use global rules carefully to avoid unintended side effects.
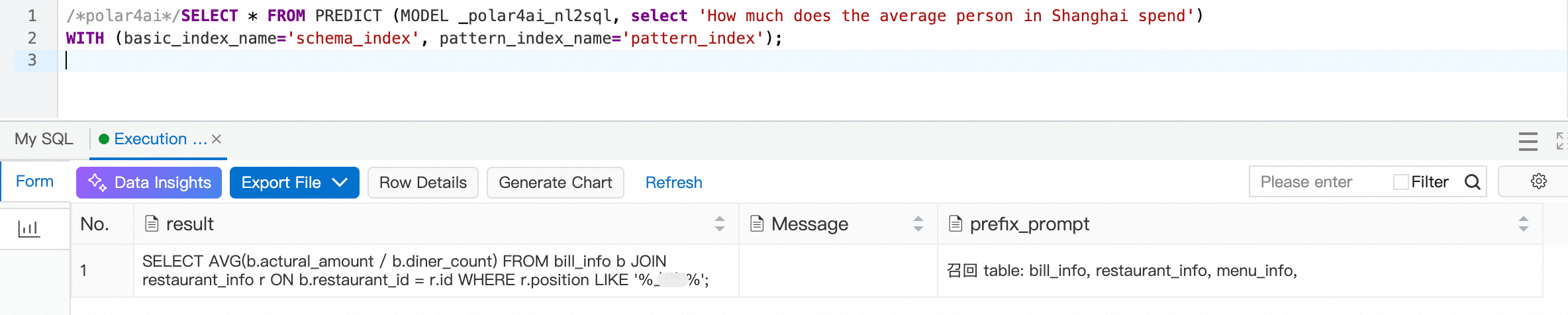
For question 5, try adding month-over-month and year-over-year calculation formulas to the configuration table yourself as a practice exercise.
Retrain and fine-tune the model
If question templates and LLM hints don't meet your accuracy requirements, retrain the model on your own data with supervised fine-tuning (SFT).
Prerequisites
-
AI node specification: polar.mysql.x8.2xlarge.gpu (16-core, 125 GB, one GU100)
-
Only one model can be trained at a time
-
Only one model can be deployed at a time
Train a model
/*polar4ai*/CREATE MODEL udf_qwen14b WITH (model_class='qwen-turbo', model_parameter=(basic_index_name='schema_index', pattern_index_name='pattern_index',training_type='efficient_sft')) as (SELECT '')Training parameters
| Parameter | Description | Default | Valid values |
|---|---|---|---|
model_class |
Model type. Supported values: qwen-14b-chat and qwen-turbo. |
— | qwen-14b-chat, qwen-turbo |
model_parameter |
Container for required and optional model parameters. | — | — |
basic_index_name |
Name of the schema index table used to sample database information for training data. | — | — |
pattern_index_name |
Name of the pattern index table used to sample question template data for training. | — | — |
training_type |
Training method. efficient_sft uses LoRA for parameter-efficient fine-tuning. sft performs full-parameter fine-tuning. |
— | efficient_sft, sft |
n_epochs |
Number of training epochs. Values in the range 1–3 are recommended for most use cases. | 3 |
1–200 |
learning_rate |
Weight update step size. Larger values cause bigger parameter changes per update. | 3e-4 |
— |
batch_size |
Number of samples per parameter update step. Values of 16 or 32 are recommended. | 16 |
8, 16, 32 |
lr_scheduler_type |
Learning rate scheduler. Controls how the learning rate changes during training. | linear |
linear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmup, inverse_sqrt, reduce_lr_on_plateau |
eval_steps |
Interval (in steps) between validation evaluations. | 50 |
1–2,147,483,647 |
sequence_length |
Maximum token length per training sample. Samples exceeding this length are truncated. | 2048 |
500–2,048 |
lr_warmup_ratio |
Fraction of total training steps used for learning rate warm-up. | 0.05 |
(0, 1) |
weight_decay |
L2 regularization coefficient. Reduces overfitting. | 0.01 |
(0, 0.2) |
gradient_checkpointing |
Saves GPU memory by recomputing activations during backpropagation instead of storing them. | True |
True, False |
use_flash_attn |
Enables Flash Attention for faster and more memory-efficient attention computation. | True |
True, False |
lora_rank |
LoRA rank. Controls how much the training data influences the model. Higher values allow more capacity but increase compute. | 8 |
2, 4, 8, 16, 32, 64 |
lora_alpha |
LoRA scaling factor. Adjusts the magnitude of the LoRA updates relative to the base model. | 32 |
8, 16, 32, 64 |
lora_dropout |
Fraction of neurons randomly dropped during LoRA training. Helps prevent overfitting. | 0.1 |
(0, 0.2) |
lora_target_modules |
Selects which model modules to apply LoRA to. | ALL |
ALL, AUTO |
View the model
/*polar4ai*/SHOW model udf_qwen14bDelete the model
/*polar4ai*/DROP model udf_qwen14bView all models
/*polar4ai*/SHOW modelsModel deployment
A trained model must be deployed before it can serve NL2SQL requests.
/*polar4ai*/deploy model udf_qwen14bView the deployment
/*polar4ai*/SHOW deployment udf_qwen14bDelete the deployment
/*polar4ai*/DROP deployment udf_qwen14bView all deployments
/*polar4ai*/SHOW deploymentsUse a deployed model for NL2SQL
Pass the deployment name via the llm_model parameter:
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT 'What is the content for id 1?') WITH (basic_index_name='schema_index', llm_model='udf_qwen14b')| Parameter | Description |
|---|---|
basic_index_name |
Required. The schema index table for the current question. |
llm_model |
Optional. If you leave this empty, the system calls the model without fine-tuning for NL2SQL. If you specify a value, make sure it is the name of a deployment that is in the serving state. Models that are not fully deployed cannot be used. |