DeepSeek-R1 is a model developed by DeepSeek that excels in math, coding, and reasoning tasks. This topic uses the DeepSeek-R1-Distill-Qwen-7B distill model as an example to explain how to fine-tune models in this series.
Supported models
Model Gallery supports LoRA supervised fine-tuning (SFT) for six distill models. The following table lists the recommended minimum computing resource configurations when you use the default hyperparameters and the provided dataset.
Distill Model | Base Model | Supported Training Method | Minimum Configuration |
DeepSeek-R1-Distill-Qwen-1.5B | LoRA supervised fine-tuning | 1 × A10 (24 GB video memory) | |
DeepSeek-R1-Distill-Qwen-7B | 1 × A10 (24 GB video memory) | ||
DeepSeek-R1-Distill-Llama-8B | 1 × A10 (24 GB video memory) | ||
DeepSeek-R1-Distill-Qwen-14B | 1 × GU8IS (48 GB video memory) | ||
DeepSeek-R1-Distill-Qwen-32B | 2 × GU8IS (48 GB video memory) | ||
DeepSeek-R1-Distill-Llama-70B | 8 × GU100 (80 GB video memory) |
Quick start
Go to the Model Gallery page.
Log on to the PAI console. In the left-side navigation pane, select your target Workspace.
In the left-side navigation pane, choose QuickStart > Model Gallery.
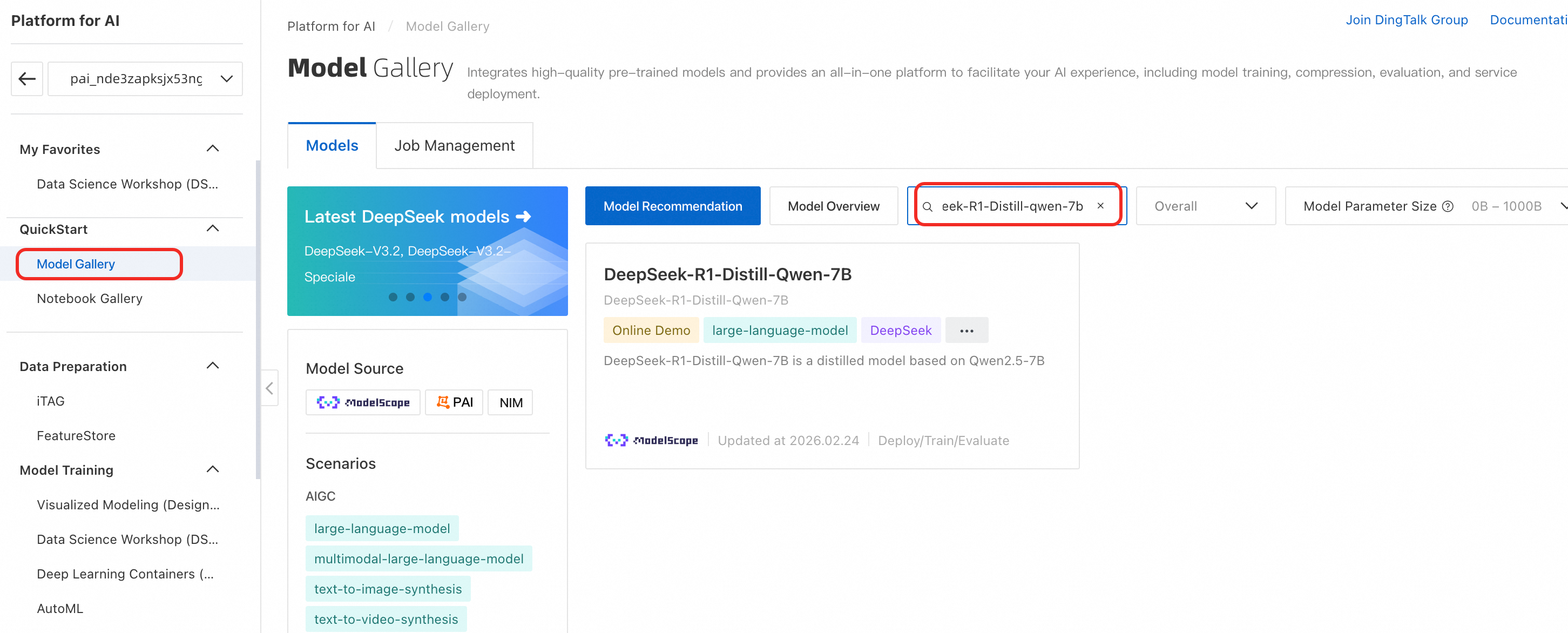
On the Model Gallery page, search for and click the DeepSeek-R1-Distill-Qwen-7B model card to open the model details page. This page provides details about model training and deployment, including the required data format for SFT and model invocation methods.
Click Train in the upper-right corner. Configure the following key parameters:
Dataset configuration: This example uses the default dataset. You can also prepare a custom dataset according to the format requirements on the model details page and upload it to an Object Storage Service (OSS) bucket.
Model output path: Select an OSS path to store the fine-tuned model.
Computing Resources: For Source, select public resource. For Instance type, select
ecs.gn7i-c16g1.4xlarge.Hyperparameters: The following table describes the hyperparameters supported for LoRA supervised fine-tuning. You can adjust them as needed. For more information, see Fine-tuning guide for large language models.
Click Train. PAI automatically redirects you to the training job page where you can monitor the job status and view logs.
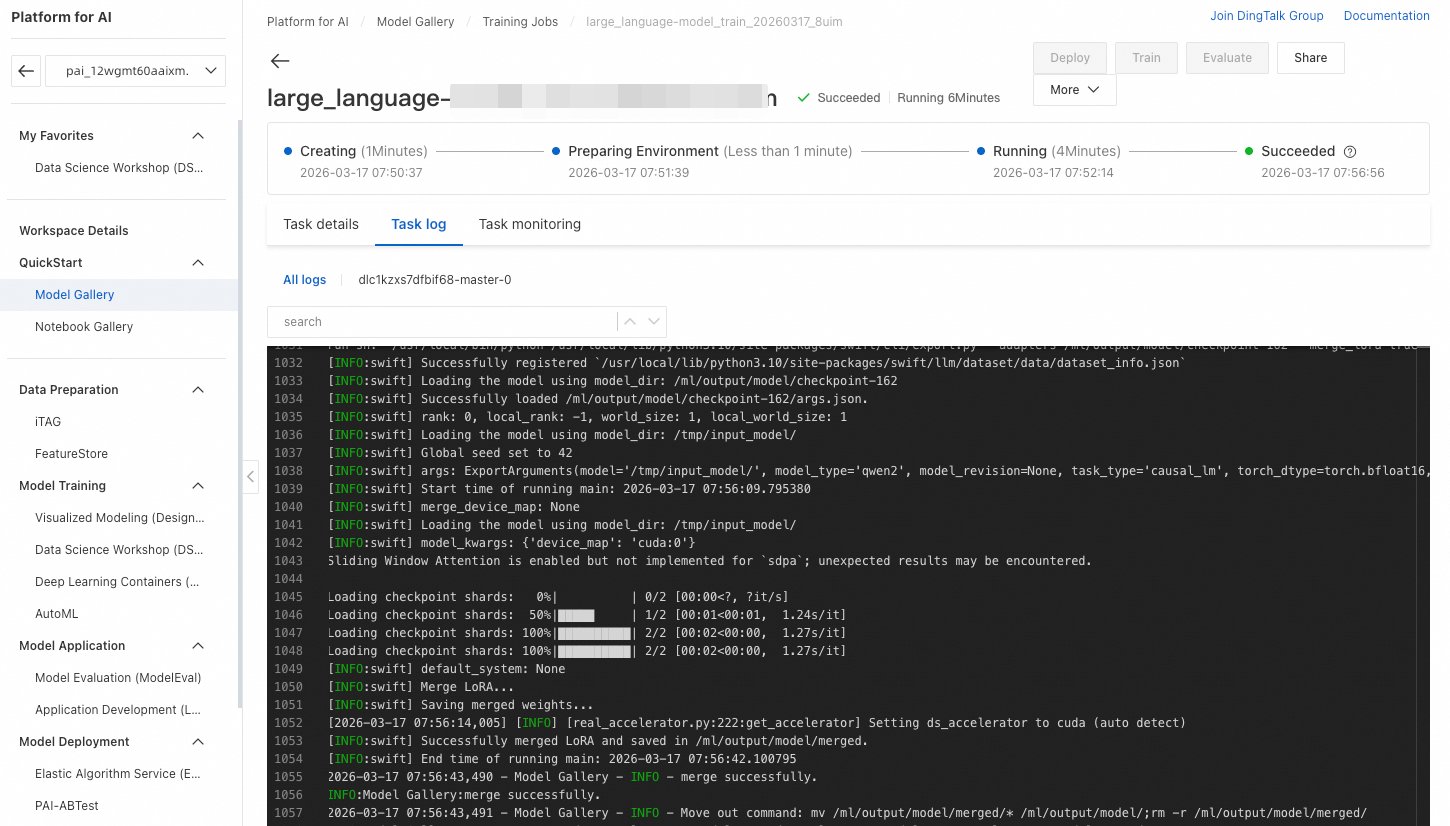
When the training job succeeds, the system automatically registers the fine-tuned model in AI Asset Management - Models. You can then view or deploy the model. For details, see Register and manage models.
After the training is complete, click Deploy in the upper-right corner to deploy the fine-tuned model as an EAS service. The invocation method is the same as that for the original distill model. For more information, see the model details page or Deploy DeepSeek-V3 and DeepSeek-R1 models.

Billing
Model training in Model Gallery uses DLC. DLC is billed based on the duration of the training job. For more information, see Billing for DLC.
FAQ
Q: How do I troubleshoot a failed training job?
Set an appropriate
max_lengthin the training configuration. The training algorithm discards data that exceedsmax_lengthand logs the action in the task log: If too much data is discarded, the training or validation dataset might become empty, causing the training job to fail:
If too much data is discarded, the training or validation dataset might become empty, causing the training job to fail:
The error log
failed to compose dlc job specs, resource limiting triggered, you are trying to use more GPU resources than the thresholdindicates that the job has triggered a resource limit. By default, a maximum of 2 GPUs can run simultaneously for training jobs. Wait for the running jobs to complete before starting a new one, or submit a ticket to request a quota increase.The error log
the specified vswitch vsw-**** cannot create the required resource ecs.gn7i-c32g1.8xlarge, zone not matchindicates that the specified instance type is out of stock in the availability zone where the VSwitch is located. You can try the following solutions: 1. Do not specify a VSwitch. DLC automatically selects a VSwitch in an availability zone with sufficient inventory. 2. Switch to a different instance type.
Q: Can I download the model after training?
Yes. When you create a training job, you can set the model output path to an OSS directory. After the job completes, you can download the model from the specified OSS path.

Q: What should I do if the model performance is poor?
Consider the following solutions:
Use a model with better baseline performance, such as a model from the DeepSeek or Qwen3 series with a higher parameter count.
Refine your prompts.
Increase the
max_tokensvalue.Break down complex tasks into smaller subtasks for the model to handle separately.