This topic describes how to build a complete pipeline in AI Search Open Platform that parses documents and images, chunks text, and generates dense and sparse vector embeddings.
Prerequisites
Before you begin, ensure the following requirements are met:
AI Search Open Platform is activated. For more information, see Activate AI Search Open Platform.
The service endpoint and authentication credentials are obtained. For more information, see Query service endpoint and Manage API key.
AI Search Open Platform supports service calls over the Internet or a virtual private cloud (VPC), including cross-region calls through VPC. Users in the Germany (Frankfurt) region can access services in the AI Search Open Platform console by using VPC endpoints.
Pipeline overview
Multimodal data processing follows a sequential pipeline that transforms raw documents and images into vector representations for search and retrieval:
Raw Document / Image
|
v
+---------------------+
| 1. Document Parsing | Extract structured content from unstructured documents
| Image Parsing | Extract text from images (VLM or OCR)
+---------------------+
|
v
+---------------------+
| 2. Document Chunking | Segment parsed content into smaller pieces by paragraph,
| | semantics, or custom rules
+---------------------+
|
v
+---------------------+
| 3. Text Embedding | Convert chunks into dense vectors (text embedding)
| Sparse Embedding | Convert chunks into sparse vectors (text sparse embedding)
+---------------------+
|
v
Vector Store / Search EngineEach stage is powered by a dedicated API service. All services require AI Search Open Platform API access and are billed based on actual usage.
Available services
Each pipeline stage uses one or more services identified by a unique service ID that you specify in API calls.
Document parsing
| Service name | Service ID | Description |
|---|---|---|
| Document Content Parsing Service | ops-document-analyze-001 | General-purpose document parsing service. Extracts logical structures such as titles and paragraphs from unstructured documents -- including text, tables, and images -- to generate structured data. |
Image parsing
Choose between VLM-based and OCR-based parsing depending on your accuracy and cost requirements.
| Service name | Service ID | Description |
|---|---|---|
| Image Content Recognition Service 001 | ops-image-analyze-vlm-001 | Parses and understands image content and identifies text based on multimodal LLMs. The parsed text can be used for image retrieval and conversational search scenarios. |
| Image Text Recognition Service 001 | ops-image-analyze-ocr-001 | Uses optical character recognition (OCR) capabilities for image text recognition. The parsed text can be used for image retrieval and conversational search scenarios. |
Document chunking
| Service name | Service ID | Description |
|---|---|---|
| Common Document Slicing Service | ops-document-split-001 | General-purpose text chunking service. Segments structured data in HTML, Markdown, and TXT formats based on paragraphs, semantics, and specific rules. Can also extract code, images, and tables from rich text. |
Text embedding
Choose an embedding model based on your language support needs, maximum input length, and desired vector dimensions.
| Service name | Service ID | Languages | Max tokens | Dimensions |
|---|---|---|---|---|
| OpenSearch text embedding service -001 | ops-text-embedding-001 | 40+ languages | 300 | 1,536 |
| OpenSearch Universal Text Vectorization Service -002 | ops-text-embedding-002 | 100+ languages | 8,192 | 1,024 |
| OpenSearch text vectorization service-Chinese -001 | ops-text-embedding-zh-001 | Chinese | 1,024 | 768 |
| OpenSearch text vectorization service-English -001 | ops-text-embedding-en-001 | English | 512 | 768 |
Text sparse embedding
Text sparse embedding converts text into sparse vectors that occupy less storage space. Sparse vectors express keywords and frequently used term information. Combine sparse and dense vectors in a hybrid search to improve retrieval performance.
| Service name | Service ID | Languages | Max tokens |
|---|---|---|---|
| OpenSearch text sparse vectorization service-generic | ops-text-sparse-embedding-001 | 100+ languages | 8,192 |
Development frameworks
For ease of use, AI Search Open Platform provides four types of development frameworks:
-
Java SDK.
-
Python SDK.
-
If your business already uses the LangChain development framework, select LangChain.
-
If your business already uses the LlamaIndex development framework, select LlamaIndex.
Step 1: Select services and download the code
This example uses SDK for Python as the development framework to build a multimodal data processing solution.
Log on to the AI Search Open Platform console.
In the top navigation bar, select the Germany (Frankfurt) region.
In the left-side navigation pane, select Scene Center. On the Scene Center page, click Enter in the Multimodal Data Processing Scenario - Data Parsing and Vectorization section.
On the Basic configuration tab of the Scene Development tab, select the services that you want to use from the drop-down lists in the Service Name column. On the Service Details tab, you can view the service details.
If you want to use an algorithm service in the RAG-based solution by calling an API operation, you must specify the service ID by using the
service_idparameter. For example, the ID of the document content parsing service isops-document-analyze-001.After you select a service, the
service_idparameter in the generated code is modified accordingly. After you download the code to your local environment, you can modify theservice_idparameter in the code to call other services.
After you select the services, click After the configuration is completed, enter the code query to view and download the code based on the execution flow.
Pipeline execution flow
The pipeline code executes the following stages in sequence. Call the main function document_pipeline_execute to run the entire pipeline. You can specify the document to process by using a document URL or Base64-encoded file.
Parse the document or image. For more information, see Document content parsing and Image content extraction.
Call the asynchronous operation for document parsing to extract content from a document URL or Base64-encoded file.
Call the asynchronous operation for image parsing to extract content from an image URL or Base64-encoded file.
Chunk the document. For more information, see Document chunking.
Call the document chunking operation to segment the parsed document based on a specific policy.
Call the
document_splitfunction to segment the document. This process includes text segmentation and rich text parsing.
Generate text embeddings. For more information, see Text embedding and Sparse text embedding.
Call the text embedding operation to convert the chunked data into dense vectors.
Call the text sparse embedding operation to convert the chunked data into sparse vectors. If you need to perform content retrieval later, you can write the vectors to a search engine.
On the Code Query tab, click Text Parsing and Vectorization. In the code editor, click Copy Code or Download File to download the code to your device.
Step 2: Test the code in your local environment
After you download the code files, configure the required parameters described in the following table.
| Section | Parameter | Description |
|---|---|---|
| AI Search Open Platform | api_key | The API key. For more information about how to obtain the API key, see Manage API keys. |
aisearch_endpoint | The API endpoint. For more information about how to obtain the API endpoint, see Query service endpoint. Note You must remove the | |
workspace_name | The AI Search Open Platform workspace name. | |
service_id | The service ID. To facilitate code development, you can configure services and specify service IDs separately in the offline.py and online.py files by using the service_id_config parameter.  |
After you configure the parameters, run the code in Python 3.8.1 or later to verify the results.
If you preprocess AI Search Open Platform data in the code, the running results are as follows.
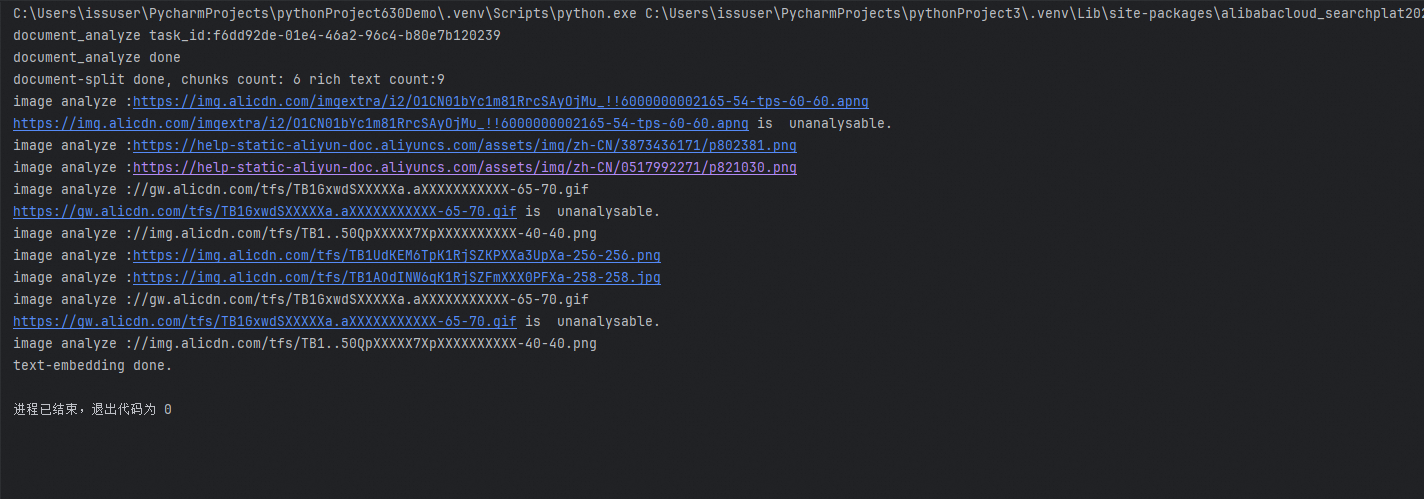
Sample code: Document parsing and embedding
# Multimodal data processing solution
# Requirements:
# Python 3.8.1 or later
# pip install alibabacloud_searchplat20240529
# AI Search Open Platform configuration
aisearch_endpoint = "xxx.platform-cn-shanghai.opensearch.aliyuncs.com"
api_key = "OS-xxx"
workspace_name = "default"
service_id_config = {
"document_analyze": "ops-document-analyze-001",
"split": "ops-document-split-001",
"text_embedding": "ops-text-embedding-001",
"text_sparse_embedding": "ops-text-sparse-embedding-001",
"image_analyze": "ops-image-analyze-ocr-001"
}
# Specify the document URL.
# In this example, the OpenSearch product description document is used.
document_url = "https://www.alibabacloud.com/help/zh/open-search/search-platform/product-overview/introduction-to-search-platform?spm=a2c4g.11186623.0.0.7ab93526WDzQ8z"
import asyncio
from operator import attrgetter
from typing import List
from Tea.exceptions import TeaException, RetryError
from alibabacloud_tea_openapi.models import Config
from alibabacloud_searchplat20240529.client import Client
from alibabacloud_searchplat20240529.models import (
GetDocumentSplitRequest,
CreateDocumentAnalyzeTaskRequest,
CreateDocumentAnalyzeTaskRequestDocument,
GetDocumentAnalyzeTaskStatusRequest,
GetDocumentSplitRequestDocument,
GetTextEmbeddingRequest,
GetTextEmbeddingResponseBodyResultEmbeddings,
GetTextSparseEmbeddingRequest,
GetTextSparseEmbeddingResponseBodyResultSparseEmbeddings,
GetImageAnalyzeTaskStatusResponse,
CreateImageAnalyzeTaskRequest,
GetImageAnalyzeTaskStatusRequest,
CreateImageAnalyzeTaskRequestDocument,
CreateImageAnalyzeTaskResponse,
)
async def poll_doc_analyze_task_result(ops_client, task_id, service_id, interval=5):
"""Poll until the document analysis task completes or fails."""
while True:
request = GetDocumentAnalyzeTaskStatusRequest(task_id=task_id)
response = await ops_client.get_document_analyze_task_status_async(
workspace_name, service_id, request
)
status = response.body.result.status
if status == "PENDING":
await asyncio.sleep(interval)
elif status == "SUCCESS":
return response
else:
print("error: " + response.body.result.error)
raise Exception("document analyze task failed")
def is_analyzable_url(url: str):
"""Check whether the URL points to a supported image format."""
if not url:
return False
image_extensions = {'.jpg', '.jpeg', '.png', '.bmp', '.tiff'}
return url.lower().endswith(tuple(image_extensions))
async def image_analyze(ops_client, url):
"""Parse an image URL and return the extracted text content."""
try:
print("image analyze: " + url)
if url.startswith("//"):
url = "https:" + url
if not is_analyzable_url(url):
print(url + " is unanalyzable.")
return url
image_analyze_service_id = service_id_config["image_analyze"]
document = CreateImageAnalyzeTaskRequestDocument(url=url)
request = CreateImageAnalyzeTaskRequest(document=document)
response: CreateImageAnalyzeTaskResponse = (
ops_client.create_image_analyze_task(
workspace_name, image_analyze_service_id, request
)
)
task_id = response.body.result.task_id
while True:
request = GetImageAnalyzeTaskStatusRequest(task_id=task_id)
response: GetImageAnalyzeTaskStatusResponse = (
ops_client.get_image_analyze_task_status(
workspace_name, image_analyze_service_id, request
)
)
status = response.body.result.status
if status == "PENDING":
await asyncio.sleep(5)
elif status == "SUCCESS":
return url + response.body.result.data.content
else:
print("image analyze error: " + response.body.result.error)
return url
except Exception as e:
print(f"image analyze Exception: {e}")
def chunk_list(lst, chunk_size):
"""Split a list into batches of the specified size."""
for i in range(0, len(lst), chunk_size):
yield lst[i:i + chunk_size]
async def document_pipeline_execute(
document_url: str = None,
document_base64: str = None,
file_name: str = None
):
# Initialize the AI Search Open Platform client.
config = Config(
bearer_token=api_key,
endpoint=aisearch_endpoint,
protocol="http"
)
ops_client = Client(config=config)
# Stage 1: Parse the document or image.
document_analyze_request = CreateDocumentAnalyzeTaskRequest(
document=CreateDocumentAnalyzeTaskRequestDocument(
url=document_url,
content=document_base64,
file_name=file_name,
file_type='html'
)
)
document_analyze_response = await ops_client.create_document_analyze_task_async(
workspace_name=workspace_name,
service_id=service_id_config["document_analyze"],
request=document_analyze_request
)
print("document_analyze task_id: " + document_analyze_response.body.result.task_id)
extraction_result = await poll_doc_analyze_task_result(
ops_client,
document_analyze_response.body.result.task_id,
service_id_config["document_analyze"]
)
print("document_analyze done")
document_content = extraction_result.body.result.data.content
content_type = extraction_result.body.result.data.content_type
# Stage 2: Chunk the document.
document_split_request = GetDocumentSplitRequest(
GetDocumentSplitRequestDocument(
content=document_content,
content_type=content_type
)
)
document_split_result = await ops_client.get_document_split_async(
workspace_name,
service_id_config["split"],
document_split_request
)
print(
"document-split done, chunks count: "
+ str(len(document_split_result.body.result.chunks))
+ " rich text count: "
+ str(len(document_split_result.body.result.rich_texts))
)
# Stage 3: Generate text embeddings.
# Extract the chunking results. For image chunks, use the image parsing
# service to extract text before embedding.
doc_list = (
[
{"id": chunk.meta.get("id"), "content": chunk.content}
for chunk in document_split_result.body.result.chunks
]
+ [
{"id": chunk.meta.get("id"), "content": chunk.content}
for chunk in document_split_result.body.result.rich_texts
if chunk.meta.get("type") != "image"
]
+ [
{
"id": chunk.meta.get("id"),
"content": await image_analyze(ops_client, chunk.content),
}
for chunk in document_split_result.body.result.rich_texts
if chunk.meta.get("type") == "image"
]
)
# A maximum of 32 vectors can be generated per request.
chunk_size = 32
all_text_embeddings: List[GetTextEmbeddingResponseBodyResultEmbeddings] = []
for chunk in chunk_list([text["content"] for text in doc_list], chunk_size):
response = await ops_client.get_text_embedding_async(
workspace_name,
service_id_config["text_embedding"],
GetTextEmbeddingRequest(chunk)
)
all_text_embeddings.extend(response.body.result.embeddings)
all_text_sparse_embeddings: List[
GetTextSparseEmbeddingResponseBodyResultSparseEmbeddings
] = []
for chunk in chunk_list([text["content"] for text in doc_list], chunk_size):
response = await ops_client.get_text_sparse_embedding_async(
workspace_name,
service_id_config["text_sparse_embedding"],
GetTextSparseEmbeddingRequest(
chunk, input_type="document", return_token=True
),
)
all_text_sparse_embeddings.extend(response.body.result.sparse_embeddings)
for i in range(len(doc_list)):
doc_list[i]["embedding"] = all_text_embeddings[i].embedding
doc_list[i]["sparse_embedding"] = all_text_sparse_embeddings[i].embedding
print("text-embedding done.")
if __name__ == "__main__":
# Run the asynchronous pipeline.
# import nest_asyncio # Uncomment if running in Jupyter Notebook.
# nest_asyncio.apply() # Uncomment if running in Jupyter Notebook.
asyncio.run(document_pipeline_execute(document_url))
# You can also use a Base64-encoded file to specify the document:
# asyncio.run(document_pipeline_execute(
# document_base64="eHh4eHh4eHg...", file_name="attention.pdf"
# ))