Alibaba Cloud Model Studio applies rate limiting to model calls at the Alibaba Cloud account level, aggregating usage across all RAM users, workspaces, and API keys under the account. Requests are rejected when the limit is exceeded and typically recover automatically within one minute.
Rate limiting rules
Account-level rate limiting: Rate limits are applied at the root account level. The usage of all RAM users, workspaces, and API keys under the account is combined.
Model-specific rate limiting: Each model has its own rate limit. For more information, see the tables below.
FAQ
Why is rate limiting triggered?
You can identify the type of rate limit triggered based on the error message:
Requests rate limit exceededorYou exceeded your current requests list: This indicates that the requests per minute (RPM) limit was triggered.Allocated quota exceededorYou exceeded your current quota: This indicates that the tokens per minute (TPM) limit was triggered.Request rate increased too quickly: The request frequency surged in a short period, triggering system stability protection. This can occur even if the total number of calls has not reached the RPM or TPM limits.For other errors, see Error codes to confirm the cause.
In addition to RPM and TPM, rate limiting may be enforced at the per-second level for requests per second (RPS), which is RPM/60, and tokens per second (TPS), which is TPM/60. Even if the total number of calls per minute does not exceed the limit, a burst of requests in a short time can still trigger rate limiting.
How to view model usage
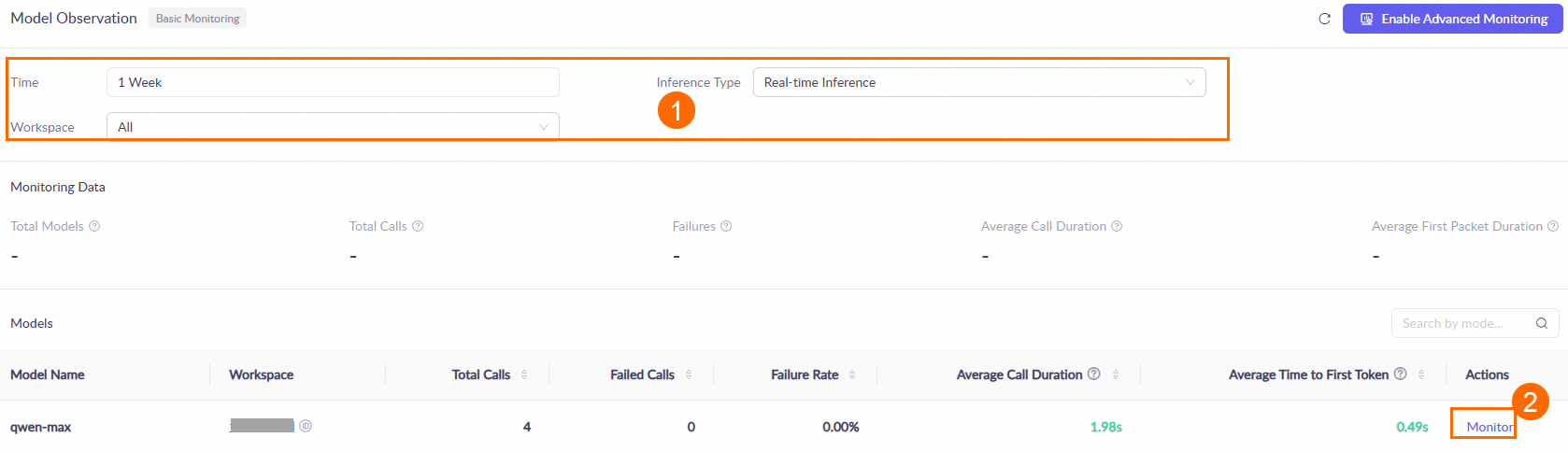
One hour after you call a model, go to the Monitoring (Singapore or Beijing) page. Set the query conditions, such as the time range and workspace. Then, in the Models area, find the target model and click Monitor in the Actions column to view the model's call statistics. For more information, see the Monitoring document.
Data is updated hourly. During peak periods, there may be an hour-level latency.
How long does it take to recover from rate limiting?
Recovery usually occurs within one minute. If other errors occur, see Error codes for troubleshooting.
How to avoid rate limiting
Choose models with higher rate limits: Stable or latest versions have higher rate limits than dated snapshot versions.
Optimize your call strategy
Reduce call frequency: If you receive a
Requests rate limit exceededorYou exceeded your current requests listerror, lower the API call frequency.Reduce token consumption: If you receive an
Allocated quota exceededorYou exceeded your current quotaerror, shorten the input or limit the output length.Smooth the request rate: If you receive a
Request rate increased too quicklyerror, use uniform scheduling, exponential backoff, or a request queue to distribute requests evenly and avoid sudden peaks.
Add a backup model
If rate limiting is triggered, you can switch to a backup model to continue generation. This can reduce the probability of failure and increase throughput. The following code automatically retries with
qwen-plus-2025-07-14after a rate limit is triggered forqwen-plus-2025-07-28.Split tasks: Long conversations or large documents can consume many tokens quickly. You can split large batch tasks into smaller batches and submit them at different times.
Use batch inference: For tasks that do not require real-time responses, you can use the Batch API. Batch requests are not subject to real-time rate limits, but you must consider queuing and processing time.
Increase rate limits: If the default rate limits are insufficient, you can increase the temporary TPM quota for a model on the Increase Rate Limits page in the Model Studio console. The increase takes effect immediately. For more information, see Increase temporary rate limits.
How to control token usage or costs
Rate limiting only restricts the request rate per unit of time; it does not cap cumulative usage. To control token usage or costs, use the following methods:
Set a spending limit and cost alerts: On the Billing card, configure Cost alerts to enable a monthly spending limit and threshold notifications. You are notified when the threshold is reached, which helps you avoid overspending. For more information, see Query bills and manage costs.
Enable stop when the free quota is used up: For models that offer a free quota, you can enable stop when the free quota is used up so that calls stop automatically once the free quota is exhausted, which prevents additional charges. For more information, see Free quota.
Monitor model usage: Regularly check the token usage of each model to detect abnormal growth in time. See How to view model usage above.
Increase temporary rate limits
If the default rate limits are insufficient, you can increase a model's temporary TPM quota in the Model Studio console. The increase takes effect immediately and is valid for 30 days. After it expires, the quota automatically reverts to the system default.
This feature is currently available in the China (Beijing) and Singapore regions.
Log on to the Model Studio console and go to the Increase Rate Limits page.
Click Increase Temporary Model Rate Limit in the upper-right corner.
In the dialog box that appears, select a Model and enter the desired value for Token Account Limit (Tokens/60s). The dialog box displays the current quota and the maximum configurable limit.
Click OK. The increased quota takes effect immediately.
After the quota increase takes effect, you can confirm it in the following ways:
On the Increase Rate Limits page, view the models with increased quotas and their corresponding rate limit data in the list.
In the Model List, go to the details page of the corresponding model to view the updated rate limit data.
The models for which you can temporarily increase quotas are listed in the dialog box on the Increase Rate Limits page.
Submitting another request for a model that already has an increased quota is considered a new application, and the validity period is reset to 30 days.
Request a quota based on your actual needs. If the provisioned capacity significantly exceeds actual usage for a long time, the system may restore it to the default value after prior notification.
Text generation - Qwen
Qwen language model
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.7-max | International | 600 | 1,000,000 |
qwen3.7-max-2026-06-08 | International | 60 | 1,000,000 |
qwen3.7-max-2026-05-20 | International | 60 | 1,000,000 |
qwen3.7-max-preview | International | 600 | 1,000,000 |
qwen3.7-max-2026-05-17 | International | 600 | 1,000,000 |
qwen3.6-max-preview | International | 600 | 1,000,000 |
qwen3-max | International | 600 | 1,000,000 |
qwen3-max-2026-01-23 | International | 600 | 1,000,000 |
qwen3-max-2025-09-23 | International | 60 | 100,000 |
qwen3-max-preview | International | 600 | 1,000,000 |
qwen-max Rate limiting does not apply to service calls made using the Batch API. | International | 600 | 1,000,000 |
qwen3.7-plus | International | 15,000 | 5,000,000 |
qwen3.7-plus-2026-05-26 | International | 60 | 1,000,000 |
qwen3.6-plus | International | 15,000 | 5,000,000 |
qwen3.6-plus-2026-04-02 | International | 60 | 1,000,000 |
qwen3.6-flash | International | 15,000 | 5,000,000 |
qwen3.6-flash-2026-04-16 | International | 60 | 1,000,000 |
qwen3.5-plus | International | 15,000 | 6,000,000 |
qwen3.5-plus-2026-04-20 | International | 600 | 1,000,000 |
qwen3.5-plus-2026-02-15 | International | 60 | 1,000,000 |
qwen-plus Rate limiting does not apply to service calls made using the Batch API. | International | 600 | 1,500,000 |
qwen-plus-latest | International | 600 | 1,000,000 |
qwen-plus-2025-12-01 | International | 120 | 1,000,000 |
qwen-plus-2025-09-11 | International | 120 | 1,000,000 |
qwen-plus-2025-07-28 | International | 60 | 100,000 |
qwen-plus-2025-07-14 (qwen-plus-0714) | International | 60 | 100,000 |
qwen-plus-2025-04-28 (qwen-plus-0428) | International | 60 | 1,000,000 |
qwen-plus-2025-01-25 (qwen-plus-0125) | International | 60 | 100,000 |
qwen3.5-flash | International | 15,000 | 5,000,000 |
qwen3.5-flash-2026-02-23 | International | 60 | 1,000,000 |
qwen-flash Rate limiting does not apply to service calls made using the Batch API. | International | 600 | 5,000,000 |
qwen-flash-2025-07-28 | International | 600 | 5,000,000 |
qwq-plus | International | 60 | 100,000 |
qwen-turbo Rate limiting does not apply to service calls made using the Batch API. | International | 600 | 5,000,000 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.7-max | Global | 30,000 | 5,000,000 |
qwen3.7-max-2026-06-08 | Global | 600 | 1,000,000 |
qwen3.7-max-2026-05-20 | Global | 600 | 1,000,000 |
qwen3-max | Global | 600 | 1,000,000 |
qwen3-max-preview | Global | 600 | 1,000,000 |
qwen3-max-2025-09-23 | Global | 60 | 100,000 |
qwen3.7-plus | Global | 30,000 | 5,000,000 |
qwen3.7-plus-2026-05-26 | Global | 600 | 1,000,000 |
qwen3.6-plus | Global | 30,000 | 5,000,000 |
qwen3.6-plus-2026-04-02 | Global | 600 | 1,000,000 |
qwen3.6-flash | Global | 15,000 | 5,000,000 |
qwen3.6-flash-2026-04-16 | Global | 60 | 1,000,000 |
qwen3.5-plus | Global | 30,000 | 5,000,000 |
qwen3.5-plus-2026-02-15 | Global | 600 | 1,000,000 |
qwen-plus | Global | 15,000 | 5,000,000 |
qwen-plus-us | US | 600 | 1,000,000 |
qwen-plus-2025-12-01 | Global | 60 | 1,000,000 |
qwen-plus-2025-09-11 | Global | 60 | 1,000,000 |
qwen-plus-2025-07-28 | Global | 60 | 1,000,000 |
qwen-plus-2025-12-01-us | US | 60 | 1,000,000 |
qwen3.5-flash | Global | 30,000 | 10,000,000 |
qwen3.5-flash-2026-02-23 | Global | 600 | 1,000,000 |
qwen-flash | Global | 15,000 | 10,000,000 |
qwen-flash-us | US | 600 | 5,000,000 |
qwen-flash-2025-07-28 | Global | 60 | 1,000,000 |
qwen-flash-2025-07-28-us | US | 600 | 5,000,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.7-max Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 30,000 | 5,000,000 |
qwen3.7-max-2026-06-08 | The Chinese mainland | 600 | 1,000,000 |
qwen3.7-max-2026-05-20 | The Chinese mainland | 600 | 1,000,000 |
qwen3.6-max-preview | The Chinese mainland | 600 | 1,000,000 |
qwen3-max Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 30,000 | 5,000,000 |
qwen3-max-2026-01-23 | The Chinese mainland | 600 | 1,000,000 |
qwen3-max-2025-09-23 | The Chinese mainland | 60 | 100,000 |
qwen3-max-preview | The Chinese mainland | 600 | 1,000,000 |
qwen-max Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 1,200 | 1,000,000 |
qwen3.7-plus | The Chinese mainland | 30,000 | 5,000,000 |
qwen3.7-plus-2026-05-26 | The Chinese mainland | 600 | 1,000,000 |
qwen3.6-plus Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 30,000 | 5,000,000 |
qwen3.6-plus-2026-04-02 | The Chinese mainland | 600 | 1,000,000 |
qwen3.6-flash Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 30,000 | 10,000,000 |
qwen3.6-flash-2026-04-16 | The Chinese mainland | 600 | 1,000,000 |
qwen3.5-plus Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 30,000 | 5,000,000 |
qwen3.5-plus-2026-04-20 | The Chinese mainland | 600 | 1,000,000 |
qwen3.5-plus-2026-02-15 | The Chinese mainland | 600 | 1,000,000 |
qwen-plus Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 30,000 | 5,000,000 |
qwen-plus-latest Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 15,000 | 1,200,000 |
qwen-plus-2025-12-01 | The Chinese mainland | 120 | 1,000,000 |
qwen-plus-2025-09-11 | The Chinese mainland | 60 | 1,000,000 |
qwen-plus-2025-07-28 (qwen-plus-0728) | The Chinese mainland | 60 | 1,000,000 |
qwen-plus-2025-07-14 (qwen-plus-0714) | The Chinese mainland | 60 | 100,000 |
qwen-plus-2025-04-28 (qwen-plus-0428) | The Chinese mainland | 60 | 1,000,000 |
qwen-plus-2025-01-25 (qwen-plus-0125) | The Chinese mainland | 60 | 150,000 |
qwen-plus-2025-01-12 (qwen-plus-0112) | The Chinese mainland | 60 | 150,000 |
qwen-plus-2024-12-20 (qwen-plus-1220) | The Chinese mainland | 60 | 150,000 |
qwen3.5-flash Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 30,000 | 10,000,000 |
qwen3.5-flash-2026-02-23 | The Chinese mainland | 600 | 1,000,000 |
qwen-flash Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 30,000 | 10,000,000 |
qwen-flash-2025-07-28 | The Chinese mainland | 60 | 1,000,000 |
qwq-plus Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 600 | 1,000,000 |
qwen-turbo | The Chinese mainland | 1,200 | 5,000,000 |
qwen-long-latest Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 1,200 | 60,000 |
qwen-long-2025-01-25 (qwen-long-0125) | The Chinese mainland | 3 | 7,500 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.7-max | Global | 30,000 | 5,000,000 |
qwen3.7-max-2026-06-08 | Global | 600 | 1,000,000 |
qwen3.7-max-2026-05-20 | Global | 600 | 1,000,000 |
qwen3-max | Global | 600 | 1,000,000 |
qwen3-max | EU | 600 | 1,000,000 |
qwen3-max-preview | Global | 600 | 1,000,000 |
qwen3-max-2026-01-23 | EU | 600 | 1,000,000 |
qwen3-max-2025-09-23 | Global | 60 | 100,000 |
qwen3.7-plus | Global | 30,000 | 5,000,000 |
qwen3.7-plus-2026-05-26 | Global | 600 | 1,000,000 |
qwen3.6-plus | Global | 30,000 | 5,000,000 |
qwen3.6-plus-2026-04-02 | Global | 600 | 1,000,000 |
qwen3.6-flash | Global | 15,000 | 5,000,000 |
qwen3.6-flash-2026-04-16 | Global | 60 | 1,000,000 |
qwen3.5-plus | Global | 30,000 | 5,000,000 |
qwen3.5-plus-2026-02-15 | Global | 600 | 1,000,000 |
qwen-plus | Global | 15,000 | 5,000,000 |
qwen-plus | EU | 600 | 1,000,000 |
qwen-plus-2025-12-01 | Global | 60 | 1,000,000 |
qwen-plus-2025-12-01 | EU | 120 | 1,000,000 |
qwen-plus-2025-09-11 | Global | 60 | 1,000,000 |
qwen-plus-2025-07-28 | Global | 60 | 1,000,000 |
qwen3.5-flash | Global | 30,000 | 10,000,000 |
qwen3.5-flash | EU | 30,000 | 10,000,000 |
qwen3.5-flash-2026-02-23 | Global | 600 | 1,000,000 |
qwen3.5-flash-2026-02-23 | EU | 600 | 1,000,000 |
qwen-flash | Global | 15,000 | 10,000,000 |
qwen-flash-2025-07-28 | Global | 60 | 1,000,000 |
Hong Kong (China)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-max | Hong Kong (China) | 600 | 1,000,000 |
qwen3-max-2026-01-23 | Hong Kong (China) | 600 | 1,000,000 |
qwen3.6-plus | Global | 30,000 | 5,000,000 |
qwen3.6-flash | Global | 15,000 | 5,000,000 |
qwen-plus | Hong Kong (China) | 600 | 1,000,000 |
qwen-plus-2025-12-01 | Hong Kong (China) | 120 | 1,000,000 |
qwen3.5-flash | Hong Kong (China) | 15,000 | 5,000,000 |
qwen3.5-flash-2026-02-23 | Hong Kong (China) | 60 | 1,000,000 |
Qwen-VL (visual understanding/image-to-text)
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-vl-plus | International | 1,200 | 1,000,000 |
qwen3-vl-plus-2025-12-19 | International | 60 | 100,000 |
qwen3-vl-plus-2025-09-23 | International | 120 | 1,000,000 |
qwen3-vl-flash | International | 1,200 | 1,000,000 |
qwen3-vl-flash-2026-01-22 | International | 60 | 100,000 |
qwen3-vl-flash-2025-10-15 | International | 120 | 1,000,000 |
qwen-vl-max | International | 1,200 | 1,000,000 |
qwen-vl-plus | International | 1,200 | 1,000,000 |
qvq-max | International | 60 | 100,000 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-vl-plus | Global | 1,200 | 1,000,000 |
qwen3-vl-plus-2025-09-23 | Global | 60 | 100,000 |
qwen3-vl-flash | Global | 1,200 | 1,000,000 |
qwen3-vl-flash-us | US | 1,200 | 1,000,000 |
qwen3-vl-flash-2025-10-15 | Global | 60 | 100,000 |
qwen3-vl-flash-2026-01-22-us | US | 120 | 1,000,000 |
qwen3-vl-flash-2025-10-15-us | US | 120 | 1,000,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-vl-plus Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 3,000 | 5,000,000 |
qwen3-vl-plus-2025-12-19 | The Chinese mainland | 60 | 100,000 |
qwen3-vl-plus-2025-09-23 | The Chinese mainland | 60 | 100,000 |
qwen3-vl-flash Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 3,000 | 5,000,000 |
qwen3-vl-flash-2026-01-22 | The Chinese mainland | 60 | 100,000 |
qwen3-vl-flash-2025-10-15 | The Chinese mainland | 60 | 100,000 |
qwen-vl-max Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 1,200 | 1,000,000 |
qwen-vl-plus Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 1,200 | 1,000,000 |
qvq-max | The Chinese mainland | 60 | 100,000 |
qvq-plus | The Chinese mainland | 60 | 100,000 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-vl-plus | Global | 1,200 | 1,000,000 |
qwen3-vl-plus | EU | 1,200 | 1,000,000 |
qwen3-vl-plus-2025-09-23 | Global | 60 | 100,000 |
qwen3-vl-flash | Global | 1,200 | 1,000,000 |
qwen3-vl-flash | EU | 1,200 | 1,000,000 |
qwen3-vl-flash-2026-01-22 | EU | 60 | 100,000 |
qwen3-vl-flash-2025-10-15 | Global | 60 | 100,000 |
qwen3-vl-flash-2025-10-15 | EU | 60 | 100,000 |
Hong Kong (China)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-vl-plus | Hong Kong (China) | 1,200 | 1,000,000 |
qwen3-vl-plus-2025-12-19 | Hong Kong (China) | 60 | 100,000 |
Qwen-Omni (omni-modal)
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.5-omni-flash | International | 60 | 100,000 |
qwen3.5-omni-flash-2026-03-15 | International | 60 | 100,000 |
qwen3.5-omni-plus | International | 60 | 100,000 |
qwen3.5-omni-plus-2026-03-15 | International | 60 | 100,000 |
qwen3-omni-flash | International | 60 | 100,000 |
qwen3-omni-flash-2025-12-01 | International | 60 | 100,000 |
qwen3-omni-flash-2025-09-15 | International | 60 | 100,000 |
qwen-omni-turbo | International | 60 | 100,000 |
qwen-omni-turbo-latest | International | 60 | 100,000 |
qwen-omni-turbo-2025-03-26 | International | 60 | 100,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.5-omni-flash | The Chinese mainland | 60 | 100,000 |
qwen3.5-omni-flash-2026-03-15 | The Chinese mainland | 60 | 100,000 |
qwen3.5-omni-plus | The Chinese mainland | 60 | 100,000 |
qwen3.5-omni-plus-2026-03-15 | The Chinese mainland | 60 | 100,000 |
qwen3-omni-flash | The Chinese mainland | 60 | 100,000 |
qwen3-omni-flash-2025-12-01 | The Chinese mainland | 60 | 100,000 |
qwen3-omni-flash-2025-09-15 | The Chinese mainland | 60 | 100,000 |
qwen-omni-turbo | The Chinese mainland | 60 | 100,000 |
qwen-omni-turbo-latest | The Chinese mainland | 60 | 100,000 |
qwen-omni-turbo-2025-03-26 (qwen-omni-turbo-0326) | The Chinese mainland | 60 | 100,000 |
qwen-omni-turbo-2025-01-19 (qwen-omni-turbo-0119) | The Chinese mainland | 60 | 100,000 |
Qwen-Omni-Realtime (real-time multimodal)
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.5-omni-plus-realtime | International | 60 | 100,000 |
qwen3.5-omni-plus-realtime-2026-03-15 | International | 60 | 100,000 |
qwen3.5-omni-flash-realtime | International | 60 | 100,000 |
qwen3.5-omni-flash-realtime-2026-03-15 | International | 60 | 100,000 |
qwen3-omni-flash-realtime | International | 60 | 100,000 |
qwen3-omni-flash-realtime-2025-12-01 | International | 60 | 100,000 |
qwen3-omni-flash-realtime-2025-09-15 | International | 60 | 100,000 |
qwen-omni-turbo-realtime | International | 60 | 10,000 |
qwen-omni-turbo-realtime-latest | International | 60 | 10,000 |
qwen-omni-turbo-realtime-2025-05-08 | International | 60 | 10,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.5-omni-plus-realtime | The Chinese mainland | 60 | 100,000 |
qwen3.5-omni-plus-realtime-2026-03-15 | The Chinese mainland | 60 | 100,000 |
qwen3.5-omni-flash-realtime | The Chinese mainland | 60 | 100,000 |
qwen3.5-omni-flash-realtime-2026-03-15 | The Chinese mainland | 60 | 100,000 |
qwen3-omni-flash-realtime | The Chinese mainland | 60 | 100,000 |
qwen3-omni-flash-realtime-2025-12-01 | The Chinese mainland | 60 | 100,000 |
qwen3-omni-flash-realtime-2025-09-15 | The Chinese mainland | 60 | 100,000 |
qwen-omni-turbo-realtime | The Chinese mainland | 60 | 100,000 |
qwen-omni-turbo-realtime-latest | The Chinese mainland | 60 | 100,000 |
qwen-omni-turbo-realtime-2025-05-08 | The Chinese mainland | 60 | 100,000 |
Qwen-OCR (text extraction)
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-vl-ocr | International | 600 | 6,000,000 |
qwen-vl-ocr-2025-11-20 | International | 1,200 | 6,000,000 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-vl-ocr | Global | 600 | 6,000,000 |
qwen-vl-ocr-2025-11-20 | Global | 1,200 | 6,000,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.5-ocr | The Chinese mainland | 6,000 | 30,000,000 |
qwen-vl-ocr Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 600 | 6,000,000 |
qwen-vl-ocr-latest | The Chinese mainland | 1,200 | 6,000,000 |
qwen-vl-ocr-2025-11-20 | The Chinese mainland | 1,200 | 6,000,000 |
qwen-vl-ocr-2025-04-13 | The Chinese mainland | 600 | 6,000,000 |
qwen-vl-ocr-2024-10-28 | The Chinese mainland | 600 | 6,000,000 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-vl-ocr | Global | 600 | 6,000,000 |
qwen-vl-ocr-2025-11-20 | Global | 1,200 | 6,000,000 |
Qwen math model
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-math-plus | The Chinese mainland | 1,200 | 1,000,000 |
qwen-math-plus-latest | The Chinese mainland | 1,200 | 1,000,000 |
qwen-math-plus-2024-09-19 (qwen-math-plus-0919) | The Chinese mainland | 60 | 100,000 |
qwen-math-plus-2024-08-16 (qwen-math-plus-0816) | The Chinese mainland | 10 | 20,000 |
qwen-math-turbo | The Chinese mainland | 1200 | 1,000,000 |
Qwen-Coder
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-coder-plus | International | 2,400 | 2,000,000 |
qwen3-coder-plus-2025-09-23 | International | 600 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | International | 60 | 1,000,000 |
qwen3-coder-flash | International | 600 | 5,000,000 |
qwen3-coder-flash-2025-07-28 | International | 600 | 5,000,000 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-coder-plus | Global | 2,400 | 2,000,000 |
qwen3-coder-plus-2025-09-23 | Global | 60 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | Global | 60 | 1,000,000 |
qwen3-coder-flash | Global | 1,200 | 1,000,000 |
qwen3-coder-flash-2025-07-28 | Global | 60 | 1,000,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-coder-plus | The Chinese mainland | 5,000 | 5,000,000 |
qwen3-coder-plus-2025-09-23 | The Chinese mainland | 60 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | The Chinese mainland | 60 | 1,000,000 |
qwen3-coder-flash | The Chinese mainland | 5,000 | 5,000,000 |
qwen3-coder-flash-2025-07-28 | The Chinese mainland | 60 | 1,000,000 |
qwen-coder-plus | The Chinese mainland | 1,200 | 1,000,000 |
qwen-coder-turbo | The Chinese mainland | 1,200 | 1,000,000 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-coder-plus | Global | 2,400 | 2,000,000 |
qwen3-coder-plus-2025-09-23 | Global | 60 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | Global | 60 | 1,000,000 |
qwen3-coder-flash | Global | 1,200 | 1,000,000 |
qwen3-coder-flash-2025-07-28 | Global | 60 | 1,000,000 |
Qwen translation model
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-mt-plus | International | 60 | 100,000 |
qwen-mt-flash | International | 60 | 100,000 |
qwen-mt-lite | International | 60 | 100,000 |
qwen-mt-turbo | International | 60 | 100,000 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-mt-plus | Global | 60 | 25,000 |
qwen-mt-flash | Global | 60 | 35,000 |
qwen-mt-lite | Global | 60 | 100,000 |
qwen-mt-lite-us | US | 60 | 100,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-mt-plus | The Chinese mainland | 60 | 25,000 |
qwen-mt-flash | The Chinese mainland | 60 | 35,000 |
qwen-mt-lite | The Chinese mainland | 60 | 100,000 |
qwen-mt-turbo | The Chinese mainland | 60 | 35,000 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-mt-plus | Global | 60 | 25,000 |
qwen-mt-flash | Global | 60 | 35,000 |
qwen-mt-lite | Global | 60 | 100,000 |
Qwen data mining model
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-doc-turbo | The Chinese mainland | 600 | 3,000,000 |
Qwen deep research model
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-deep-research | The Chinese mainland | 120 | 1,200,000 |
Text generation - Qwen - Open source
Qwen language model open source
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.6-35b-a3b | International | 600 | 1,000,000 |
qwen3.6-27b | International | 600 | 1,000,000 |
qwen3.5-397b-a17b | International | 600 | 1,000,000 |
qwen3.5-122b-a10b | International | 600 | 1,000,000 |
qwen3.5-27b | International | 600 | 1,000,000 |
qwen3.5-35b-a3b | International | 600 | 5,000,000 |
qwen3-next-80b-a3b-thinking | International | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | International | 600 | 1,000,000 |
qwen3-235b-a22b-thinking-2507 | International | 600 | 1,000,000 |
qwen3-235b-a22b-instruct-2507 | International | 600 | 1,000,000 |
qwen3-30b-a3b-thinking-2507 | International | 600 | 5,000,000 |
qwen3-30b-a3b-instruct-2507 | International | 600 | 5,000,000 |
qwen3-235b-a22b | International | 600 | 1,000,000 |
qwen3-32b | International | 600 | 1,000,000 |
qwen3-30b-a3b | International | 600 | 1,000,000 |
qwen3-14b | International | 600 | 1,000,000 |
qwen3-8b | International | 600 | 1,000,000 |
qwen3-4b | International | 600 | 1,000,000 |
qwen3-1.7b | International | 600 | 1,000,000 |
qwen3-0.6b | International | 600 | 1,000,000 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.5-397b-a17b | Global | 600 | 1,000,000 |
qwen3.5-122b-a10b | Global | 600 | 1,000,000 |
qwen3.5-27b | Global | 600 | 1,000,000 |
qwen3.6-35b-a3b | Global | 600 | 1,000,000 |
qwen3.5-35b-a3b | Global | 600 | 1,000,000 |
qwen3-next-80b-a3b-thinking | Global | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | Global | 600 | 1,000,000 |
qwen3-235b-a22b-thinking-2507 | Global | 600 | 1,000,000 |
qwen3-235b-a22b-instruct-2507 | Global | 600 | 1,000,000 |
qwen3-30b-a3b-thinking-2507 | Global | 600 | 1,000,000 |
qwen3-30b-a3b-instruct-2507 | Global | 600 | 1,000,000 |
qwen3-235b-a22b | Global | 600 | 1,000,000 |
qwen3-30b-a3b | Global | 600 | 1,000,000 |
qwen3-32b | Global | 600 | 1,000,000 |
qwen3-14b | Global | 600 | 1,000,000 |
qwen3-8b | Global | 600 | 1,000,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.6-35b-a3b | The Chinese mainland | 600 | 1,000,000 |
qwen3.6-27b | The Chinese mainland | 600 | 1,000,000 |
qwen3.5-397b-a17b | The Chinese mainland | 600 | 1,000,000 |
qwen3.5-122b-a10b | The Chinese mainland | 600 | 1,000,000 |
qwen3.5-27b | The Chinese mainland | 600 | 1,000,000 |
qwen3.5-35b-a3b | The Chinese mainland | 600 | 1,000,000 |
qwen3-next-80b-a3b-thinking | The Chinese mainland | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | The Chinese mainland | 600 | 1,000,000 |
qwen3-235b-a22b-thinking-2507 | The Chinese mainland | 600 | 1,000,000 |
qwen3-235b-a22b-instruct-2507 | The Chinese mainland | 600 | 1,000,000 |
qwen3-30b-a3b-thinking-2507 | The Chinese mainland | 600 | 1,000,000 |
qwen3-30b-a3b-instruct-2507 | The Chinese mainland | 600 | 1,000,000 |
qwen3-235b-a22b | The Chinese mainland | 600 | 1,000,000 |
qwen3-30b-a3b | The Chinese mainland | 600 | 1,000,000 |
qwen3-32b | The Chinese mainland | 2400 | 1,000,000 |
qwen3-14b | The Chinese mainland | 600 | 1,000,000 |
qwen3-8b | The Chinese mainland | 600 | 1,000,000 |
qwen3-4b | The Chinese mainland | 600 | 1,000,000 |
qwen3-1.7b | The Chinese mainland | 600 | 1,000,000 |
qwen3-0.6b | The Chinese mainland | 600 | 1,000,000 |
qwen2.5-3b-instruct | The Chinese mainland | 1,200 | 2,000,000 |
qwen2.5-1.5b-instruct | The Chinese mainland | 1,200 | 2,000,000 |
qwen2.5-0.5b-instruct | The Chinese mainland | 1,200 | 2,000,000 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3.5-397b-a17b | Global | 600 | 1,000,000 |
qwen3.5-122b-a10b | Global | 600 | 1,000,000 |
qwen3.5-27b | Global | 600 | 1,000,000 |
qwen3.6-35b-a3b | Global | 600 | 1,000,000 |
qwen3.5-35b-a3b | Global | 600 | 1,000,000 |
qwen3-next-80b-a3b-thinking | Global | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | Global | 600 | 1,000,000 |
qwen3-235b-a22b-thinking-2507 | Global | 600 | 1,000,000 |
qwen3-235b-a22b-instruct-2507 | Global | 600 | 1,000,000 |
qwen3-30b-a3b-thinking-2507 | Global | 600 | 1,000,000 |
qwen3-30b-a3b-instruct-2507 | Global | 600 | 1,000,000 |
qwen3-235b-a22b | Global | 600 | 1,000,000 |
qwen3-30b-a3b | Global | 600 | 1,000,000 |
qwen3-32b | Global | 600 | 1,000,000 |
qwen3-14b | Global | 600 | 1,000,000 |
qwen3-8b | Global | 600 | 1,000,000 |
Qwen-VL (visual understanding/image-to-text)
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-vl-32b-thinking | International | 60 | 100,000 |
qwen3-vl-32b-instruct | International | 60 | 100,000 |
qwen3-vl-30b-a3b-thinking | International | 60 | 100,000 |
qwen3-vl-30b-a3b-instruct | International | 60 | 100,000 |
qwen3-vl-8b-thinking | International | 60 | 100,000 |
qwen3-vl-8b-instruct | International | 60 | 100,000 |
qwen3-vl-235b-a22b-thinking | International | 60 | 100,000 |
qwen3-vl-235b-a22b-instruct | International | 60 | 100,000 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-vl-235b-a22b-thinking | Global | 60 | 100,000 |
qwen3-vl-235b-a22b-instruct | Global | 60 | 100,000 |
qwen3-vl-32b-thinking | Global | 600 | 1,000,000 |
qwen3-vl-32b-instruct | Global | 600 | 1,000,000 |
qwen3-vl-30b-a3b-thinking | Global | 600 | 1,000,000 |
qwen3-vl-30b-a3b-instruct | Global | 600 | 1,000,000 |
qwen3-vl-8b-thinking | Global | 600 | 1,000,000 |
qwen3-vl-8b-instruct | Global | 600 | 1,000,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-vl-32b-thinking | The Chinese mainland | 600 | 1,000,000 |
qwen3-vl-32b-instruct | The Chinese mainland | 600 | 1,000,000 |
qwen3-vl-30b-a3b-thinking | The Chinese mainland | 600 | 1,000,000 |
qwen3-vl-30b-a3b-instruct | The Chinese mainland | 600 | 1,000,000 |
qwen3-vl-8b-thinking | The Chinese mainland | 600 | 1,000,000 |
qwen3-vl-8b-instruct | The Chinese mainland | 600 | 1,000,000 |
qwen3-vl-235b-a22b-thinking | The Chinese mainland | 60 | 100,000 |
qwen3-vl-235b-a22b-instruct | The Chinese mainland | 60 | 100,000 |
qwen2-vl-72b-instruct | The Chinese mainland | 1,200 | 1,000,000 |
qwen2-vl-7b-instruct | The Chinese mainland | 1,200 | 1,000,000 |
qwen2-vl-2b-instruct | The Chinese mainland | 1,200 | 1,000,000 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-vl-235b-a22b-thinking | Global | 60 | 100,000 |
qwen3-vl-235b-a22b-instruct | Global | 60 | 100,000 |
qwen3-vl-32b-thinking | Global | 600 | 1,000,000 |
qwen3-vl-32b-instruct | Global | 600 | 1,000,000 |
qwen3-vl-30b-a3b-thinking | Global | 600 | 1,000,000 |
qwen3-vl-30b-a3b-instruct | Global | 600 | 1,000,000 |
qwen3-vl-8b-thinking | Global | 600 | 1,000,000 |
qwen3-vl-8b-instruct | Global | 600 | 1,000,000 |
Qwen3-Omni
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen2.5-omni-7b | International | 60 | 100,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen2.5-omni-7b | The Chinese mainland | 60 | 100,000 |
Qwen3-Omni-Captioner
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-omni-30b-a3b-captioner | International | 60 | 100,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-omni-30b-a3b-captioner | The Chinese mainland | 60 | 100,000 |
Qwen-Math
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
Qwen-Coder
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-coder-next | International | 600 | 1,000,000 |
qwen3-coder-480b-a35b-instruct | International | 600 | 1,000,000 |
qwen3-coder-30b-a3b-instruct | International | 600 | 1,000,000 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-coder-480b-a35b-instruct | Global | 600 | 1,000,000 |
qwen3-coder-30b-a3b-instruct | Global | 600 | 1,000,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-coder-next | The Chinese mainland | 600 | 1,000,000 |
qwen3-coder-480b-a35b-instruct | The Chinese mainland | 600 | 1,000,000 |
qwen3-coder-30b-a3b-instruct | The Chinese mainland | 600 | 1,000,000 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen3-coder-480b-a35b-instruct | Global | 600 | 1,000,000 |
qwen3-coder-30b-a3b-instruct | Global | 600 | 1,000,000 |
qwen3-coder-next | EU | 600 | 1,000,000 |
Text generation - Third-party models
DeepSeek
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
deepseek-v4-pro | International | 10,000 | 1,200,000 |
deepseek-v4-flash | International | 10,000 | 1,200,000 |
deepseek-v3.2 | International | 10,000 | 1,200,000 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
deepseek-v4-pro | Global | 15,000 | 1,200,000 |
deepseek-v4-flash | Global | 15,000 | 1,200,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
deepseek-v4-pro | The Chinese mainland | 15,000 | 1,200,000 |
deepseek-v4-flash | The Chinese mainland | 15,000 | 1,200,000 |
deepseek-v3.2 Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 15,000 | 1,200,000 |
deepseek-v3.2-exp | The Chinese mainland | 15,000 | 1,200,000 |
deepseek-v3.1 | The Chinese mainland | 15,000 | 1,200,000 |
deepseek-r1-0528 | The Chinese mainland | 60 | 100,000 |
deepseek-r1 Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 15,000 | 1,200,000 |
deepseek-v3 Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 15,000 | 1,200,000 |
deepseek-r1-distill-qwen-7b | The Chinese mainland | 15,000 | 1,200,000 |
deepseek-r1-distill-qwen-14b | The Chinese mainland | 15,000 | 1,200,000 |
deepseek-r1-distill-qwen-32b | The Chinese mainland | 15,000 | 1,200,000 |
deepseek-r1-distill-qwen-1.5b | The Chinese mainland | 60 | 100,000 |
deepseek-r1-distill-llama-8b | The Chinese mainland | 60 | 100,000 |
deepseek-r1-distill-llama-70b | The Chinese mainland | 60 | 100,000 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
deepseek-v4-pro | Global | 15,000 | 1,200,000 |
deepseek-v4-flash | Global | 15,000 | 1,200,000 |
Kimi
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
kimi-k2.7-code | The Chinese mainland | 500 | 1,000,000 |
kimi-k2.6 | The Chinese mainland | 500 | 1,000,000 |
kimi-k2.5 | The Chinese mainland | 500 | 1,000,000 |
kimi-k2-thinking | The Chinese mainland | 500 | 1,000,000 |
Moonshot-Kimi-K2-Instruct | The Chinese mainland | 500 | 1,000,000 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
kimi-k2.7-code | Global | 500 | 1,000,000 |
kimi-k2.5 | Global | 500 | 1,000,000 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
kimi-k2.7-code | Global | 500 | 1,000,000 |
kimi-k2.5 | Global | 500 | 1,000,000 |
Hong Kong (China)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
kimi-k2.7-code | Global | 500 | 1,000,000 |
MiniMax
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
MiniMax-M2.5 | The Chinese mainland | 500 | 1,000,000 |
GLM
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
glm-5.2 | Global | 500 | 1,000,000 |
glm-5.1 | Global | 500 | 1,000,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
glm-5.2 | The Chinese mainland | 500 | 1,000,000 |
glm-5.1 | The Chinese mainland | 500 | 1,000,000 |
glm-5 | The Chinese mainland | 500 | 1,000,000 |
glm-4.7 | The Chinese mainland | 500 | 1,000,000 |
glm-4.6 | The Chinese mainland | 60 | 1,000,000 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
glm-5.2 | Global | 500 | 1,000,000 |
glm-5.1 | Global | 500 | 1,000,000 |
Singapore
Model name | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | |
glm-5.1 | 500 | 1,000,000 |
Hong Kong (China)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
glm-5.2 | Global | 500 | 1,000,000 |
Image generation
Qwen-Image
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
Task submission API call limit | Number of concurrent tasks (concurrency) | ||
qwen-image-2.0-pro | International | 2 times/minute | No limit for synchronous APIs |
qwen-image-2.0-pro-2026-04-22 | International | 2 times/minute | No limit for synchronous APIs |
qwen-image-2.0-pro-2026-03-03 | International | 2 times/minute | No limit for synchronous APIs |
qwen-image-2.0 | International | 2 times/second | No limit for synchronous APIs |
qwen-image-2.0-2026-03-03 | International | 2 times/second | No limit for synchronous APIs |
qwen-image-max | International | 2 times/minute | No limit for synchronous APIs |
qwen-image-max-2025-12-30 | International | 2 times/minute | No limit for synchronous APIs |
qwen-image-plus | International | 2 times/second | No limit for synchronous APIs / 2 for asynchronous APIs |
qwen-image-plus-2026-01-09 | International | 2 times/second | No limit for synchronous APIs |
qwen-image | International | 2 times/second | No limit for synchronous APIs / 2 for asynchronous APIs |
qwen-image-edit-max | International | 2 times/minute | No limit for synchronous APIs |
qwen-image-edit-max-2026-01-16 | International | 2 times/minute | No limit for synchronous APIs |
qwen-image-edit-plus | International | 2 times/second | No limit for synchronous APIs |
qwen-image-edit-plus-2025-12-15 | International | 2 times/second | No limit for synchronous APIs |
qwen-image-edit-plus-2025-10-30 | International | 2 times/second | No limit for synchronous APIs |
qwen-image-edit | International | 2 times/second | No limit for synchronous APIs |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
Task submission API call limit | Number of concurrent tasks (concurrency) | ||
qwen-image-2.0-pro | The Chinese mainland | 2 times/minute | No limit for synchronous APIs |
qwen-image-2.0-pro-2026-04-22 | The Chinese mainland | 2 times/minute | No limit for synchronous APIs |
qwen-image-2.0-pro-2026-03-03 | The Chinese mainland | 2 times/minute | No limit for synchronous APIs |
qwen-image-2.0 | The Chinese mainland | 2 times/second | No limit for synchronous APIs |
qwen-image-2.0-2026-03-03 | The Chinese mainland | 2 times/second | No limit for synchronous APIs |
qwen-image-max | The Chinese mainland | 2 times/minute | No limit for synchronous APIs |
qwen-image-max-2025-12-30 | The Chinese mainland | 2 times/minute | No limit for synchronous APIs |
qwen-image-plus | The Chinese mainland | 2 times/second | No limit for synchronous APIs / 2 for asynchronous APIs |
qwen-image-plus-2026-01-09 | The Chinese mainland | 2 times/second | No limit for synchronous APIs |
qwen-image | The Chinese mainland | 2 times/second | No limit for synchronous APIs / 2 for asynchronous APIs |
qwen-image-edit-max | The Chinese mainland | 2 times/minute | No limit for synchronous APIs |
qwen-image-edit-max-2026-01-16 | The Chinese mainland | 2 times/minute | No limit for synchronous APIs |
qwen-image-edit-plus | The Chinese mainland | 2 times/second | No limit for synchronous APIs |
qwen-image-edit-plus-2025-12-15 | The Chinese mainland | 2 times/second | No limit for synchronous APIs |
qwen-image-edit-plus-2025-10-30 | The Chinese mainland | 2 times/second | No limit for synchronous APIs |
qwen-image-edit | The Chinese mainland | 2 times/second | No limit for synchronous APIs |
qwen-mt-image | The Chinese mainland | 1 time/second | 2 |
Text-to-image - Z-Image
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
z-image-turbo | International | 2 | No limit for synchronous APIs |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
z-image-turbo | The Chinese mainland | 2 | No limit for synchronous APIs |
Wanxiang
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
wan2.7-image-pro | International | 5 | 5 |
wan2.7-image | International | 5 | 5 |
wan2.6-image | International | 5 | 5 |
wan2.6-t2i | International | 5 | 5 |
wan2.5-t2i-preview | International | 5 | 5 |
wan2.2-t2i-flash | International | 2 | 2 |
wan2.2-t2i-plus | International | 2 | 2 |
wan2.1-t2i-turbo | International | 2 | 2 |
wan2.1-t2i-plus | International | 2 | 2 |
wan2.5-i2i-preview | International | 5 | 5 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
wan2.6-t2i | Global | 5 | 5 |
wan2.6-image | Global | 5 | 5 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
wan2.7-image-pro | The Chinese mainland | 5 | 5 |
wan2.7-image | The Chinese mainland | 5 | 5 |
wan2.6-image | The Chinese mainland | 5 | 5 |
wan2.6-t2i | The Chinese mainland | 1 | 5 |
wan2.5-t2i-preview | The Chinese mainland | 5 | 5 |
wanx2.0-t2i-turbo | The Chinese mainland | 2 | 2 |
wanx2.1-t2i-turbo | The Chinese mainland | 2 | 2 |
wanx2.1-t2i-plus | The Chinese mainland | 2 | 2 |
wan2.2-t2i-flash | The Chinese mainland | 2 | 2 |
wan2.2-t2i-plus | The Chinese mainland | 2 | 2 |
wan2.5-i2i-preview | The Chinese mainland | 5 | 5 |
wanx2.1-imageedit | The Chinese mainland | 2 | 2 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
wan2.6-t2i | Global | 5 | 5 |
wan2.6-image | Global | 5 | 5 |
OutfitAnyone
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for job submission API | Number of concurrent tasks | ||
aitryon-plus | The Chinese mainland | 10 | 5 |
aitryon-parsing-v1 | The Chinese mainland | 10 | No limit for synchronous APIs |
Video generation
HappyHorse series
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
happyhorse-1.1-t2v | International | 10 | 5 |
happyhorse-1.1-i2v | International | 10 | 5 |
happyhorse-1.1-r2v | International | 10 | 5 |
happyhorse-1.0-t2v | International | 10 | 5 |
happyhorse-1.0-i2v | International | 10 | 5 |
happyhorse-1.0-r2v | International | 10 | 5 |
happyhorse-1.0-video-edit | International | 10 | 5 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
happyhorse-1.0-t2v | Global | 10 | 5 |
happyhorse-1.0-i2v | Global | 10 | 5 |
happyhorse-1.0-r2v | Global | 10 | 5 |
happyhorse-1.0-video-edit | Global | 10 | 5 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
happyhorse-1.1-t2v | The Chinese mainland | 10 | 5 |
happyhorse-1.1-i2v | The Chinese mainland | 10 | 5 |
happyhorse-1.1-r2v | The Chinese mainland | 10 | 5 |
happyhorse-1.0-t2v | The Chinese mainland | 10 | 5 |
happyhorse-1.0-i2v | The Chinese mainland | 10 | 5 |
happyhorse-1.0-r2v | The Chinese mainland | 10 | 5 |
happyhorse-1.0-video-edit | The Chinese mainland | 10 | 5 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
happyhorse-1.0-t2v | Global | 10 | 5 |
happyhorse-1.0-i2v | Global | 10 | 5 |
happyhorse-1.0-r2v | Global | 10 | 5 |
happyhorse-1.0-video-edit | Global | 10 | 5 |
Wanxiang series
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
wan2.7-t2v-2026-04-25 | International | 5 | 5 |
wan2.7-t2v | International | 5 | 5 |
wan2.6-t2v | International | 5 | 5 |
wan2.5-t2v-preview | International | 5 | 5 |
wan2.2-t2v-plus | International | 2 | 2 |
wan2.1-t2v-turbo | International | 2 | 2 |
wan2.1-t2v-plus | International | 2 | 2 |
wan2.7-i2v-2026-04-25 | International | 5 | 5 |
wan2.7-i2v | International | 5 | 5 |
wan2.6-i2v-flash | International | 5 | 5 |
wan2.6-i2v | International | 5 | 5 |
wan2.5-i2v-preview | International | 5 | 5 |
wan2.2-i2v-flash | International | 2 | 2 |
wan2.1-i2v-plus | International | 2 | 2 |
wan2.1-i2v-turbo | International | 2 | 2 |
wan2.2-i2v-plus | International | 2 | 2 |
wan2.2-kf2v-flash | International | 2 | 2 |
wan2.1-kf2v-plus | International | 1 | 2 |
wan2.1-vace-plus | International | 2 | 2 |
wan2.7-videoedit | International | 5 | 5 |
wan2.7-r2v | International | 5 | 5 |
wan2.6-r2v-flash | International | 5 | 5 |
wan2.6-r2v | International | 5 | 5 |
wan2.2-animate-move | International | 5 | 1 |
wan2.2-animate-mix | International | 5 | 1 |
US (Virginia)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
wan2.6-t2v | Global | 5 | 5 |
wan2.6-i2v | Global | 5 | 5 |
wan2.6-r2v | Global | 5 | 5 |
wan2.6-t2v-us | US | 5 | 5 |
wan2.6-i2v-us | US | 5 | 5 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
wan2.7-t2v-2026-04-25 | The Chinese mainland | 5 | 5 |
wan2.7-t2v | The Chinese mainland | 5 | 5 |
wan2.6-t2v | The Chinese mainland | 5 | 5 |
wan2.5-t2v-preview | The Chinese mainland | 5 | 5 |
wan2.2-t2v-plus | The Chinese mainland | 2 | 2 |
wanx2.1-t2v-turbo | The Chinese mainland | 2 | 2 |
wanx2.1-t2v-plus | The Chinese mainland | 2 | 2 |
wan2.7-i2v-2026-04-25 | The Chinese mainland | 5 | 5 |
wan2.7-i2v | The Chinese mainland | 5 | 5 |
wan2.6-i2v-flash | The Chinese mainland | 5 | 5 |
wan2.6-i2v | The Chinese mainland | 5 | 5 |
wan2.5-i2v-preview | The Chinese mainland | 5 | 5 |
wan2.2-i2v-plus | The Chinese mainland | 2 | 2 |
wanx2.1-i2v-turbo | The Chinese mainland | 2 | 2 |
wanx2.1-i2v-plus | The Chinese mainland | 2 | 2 |
wan2.2-kf2v-flash | The Chinese mainland | 2 | 2 |
wanx2.1-kf2v-plus | The Chinese mainland | 2 | 2 |
wanx2.1-vace-plus | The Chinese mainland | 2 | 2 |
wan2.7-videoedit | The Chinese mainland | 5 | 5 |
wan2.7-r2v | The Chinese mainland | 5 | 5 |
wan2.6-r2v-flash | The Chinese mainland | 5 | 5 |
wan2.6-r2v | The Chinese mainland | 5 | 5 |
wan2.2-s2v-detect | The Chinese mainland | 5 | No limit for synchronous APIs |
wan2.2-s2v | The Chinese mainland | 5 | 1 |
wan2.2-animate-move | The Chinese mainland | 5 | 1 |
wan2.2-animate-mix | The Chinese mainland | 5 | 1 |
Germany (Frankfurt)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
RPS limit for task submission API | Number of concurrent tasks (concurrency) | ||
wan2.6-t2v | Global | 5 | 5 |
wan2.6-i2v | Global | 5 | 5 |
wan2.6-r2v | Global | 5 | 5 |
AnimateAnyone
China (Beijing)
Model name | Service deployment scope | RPS limit for task submission API | Number of concurrent tasks |
animate-anyone-detect-gen2 | The Chinese mainland | 5 | No limit for synchronous APIs |
animate-anyone-template-gen2 | The Chinese mainland | 5 | 1 Only one job runs at a time. Other jobs in the queue are in a waiting state. |
animate-anyone-gen2 | The Chinese mainland | 5 | 1 Only one job runs at a time. Other jobs in the queue are in a waiting state. |
EMO
China (Beijing)
Model name | Service deployment scope | RPS limit for task submission API | Number of concurrent tasks |
emo-detect-v1 | The Chinese mainland | 5 | No limit for synchronous APIs |
emo-v1 | The Chinese mainland | 5 | 1 Only one job runs at a time. Other jobs in the queue are in a waiting state. |
LivePortrait
China (Beijing)
Model name | Service deployment scope | RPS limit for task submission API | Number of concurrent tasks |
liveportrait-detect | The Chinese mainland | 5 | No limit for synchronous APIs |
liveportrait | The Chinese mainland | 5 | 1 Only one job runs at a time. Other jobs in the queue are in a waiting state. |
VideoRetalk
China (Beijing)
Model name | Service deployment scope | RPS limit for task submission API | Number of concurrent tasks |
videoretalk | The Chinese mainland | 1 | 1 Only one job runs at a time. Other jobs in the queue are in a waiting state. |
Emoji
China (Beijing)
Model name | Service deployment scope | RPS limit for task submission API | Number of concurrent tasks |
emoji-detect-v1 | The Chinese mainland | 1 | No limit for synchronous APIs |
emoji-v1 | The Chinese mainland | 1 | 1 Only one job runs at a time. Other jobs in the queue are in a waiting state. |
Video style transform
China (Beijing)
Model name | Service deployment scope | RPS limit for task submission API | Number of concurrent tasks |
video-style-transform | The Chinese mainland | 20 | 2 Only one job runs at a time. Other jobs in the queue are in a waiting state. |
Music generation
China (Beijing)
Model name | Service deployment scope | Requests per minute (RPM) |
fun-music-preview | The Chinese mainland | 180 |
fun-music-v1 | The Chinese mainland | 180 |
Speech synthesis (text-to-speech)
Qwen speech synthesis
Singapore
Qwen3-TTS-Instruct-Flash
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-instruct-flash |
International |
180 |
|
qwen3-tts-instruct-flash-2026-01-26 |
International |
180 |
Qwen3-TTS-VD
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-vd-2026-01-26 |
International |
180 |
Qwen3-TTS-VC
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-vc-2026-01-22 |
International |
180 |
Qwen3-TTS-Flash
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-flash |
International |
180 |
|
qwen3-tts-flash-2025-11-27 |
International |
180 |
|
qwen3-tts-flash-2025-09-18 |
International |
10 |
China (Beijing)
Qwen3-TTS-Instruct-Flash
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-instruct-flash |
Mainland China |
180 |
|
qwen3-tts-instruct-flash-2026-01-26 |
Mainland China |
180 |
Qwen3-TTS-VD
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-vd-2026-01-26 |
Mainland China |
180 |
Qwen3-TTS-VC
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-vc-2026-01-22 |
Mainland China |
180 |
Qwen3-TTS-Flash
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-flash |
Mainland China |
180 |
|
qwen3-tts-flash-2025-11-27 |
Mainland China |
180 |
|
qwen3-tts-flash-2025-09-18 |
Mainland China |
10 |
Qwen-TTS
|
Model name |
Service deployment scope |
Rate limiting conditions (rate limiting is triggered when any value is exceeded) The following are per-minute rate limiting conditions. The service may also enforce RPS (RPM/60) and TPS (TPM/60) limits |
|
|
Requests per minute (RPM) |
Tokens consumed per minute (TPM) Including input and output tokens |
||
|
qwen-tts |
Mainland China |
10 |
100,000 |
|
qwen-tts-latest |
Mainland China |
||
|
qwen-tts-2025-05-22 |
Mainland China |
||
|
qwen-tts-2025-04-10 |
Mainland China |
||
Qwen real-time speech synthesis
Singapore
Qwen3-TTS-Instruct-Flash-Realtime
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-instruct-flash-realtime |
International |
180 |
|
qwen3-tts-instruct-flash-realtime-2026-01-22 |
International |
180 |
Qwen3-TTS-VD-Realtime
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-vd-realtime-2026-01-15 |
International |
180 |
|
qwen3-tts-vd-realtime-2025-12-16 |
International |
Qwen3-TTS-VC-Realtime
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-vc-realtime-2026-01-15 |
International |
180 |
|
qwen3-tts-vc-realtime-2025-11-27 |
International |
Qwen3-TTS-Flash-Realtime
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-flash-realtime |
International |
180 |
|
qwen3-tts-flash-realtime-2025-11-27 |
International |
180 |
|
qwen3-tts-flash-realtime-2025-09-18 |
International |
10 |
China (Beijing)
Qwen3-TTS-Instruct-Flash-Realtime
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-instruct-flash-realtime |
Mainland China |
180 |
|
qwen3-tts-instruct-flash-realtime-2026-01-22 |
Mainland China |
180 |
Qwen3-TTS-VD-Realtime
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-vd-realtime-2026-01-15 |
Mainland China |
180 |
|
qwen3-tts-vd-realtime-2025-12-16 |
Mainland China |
Qwen3-TTS-VC-Realtime
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-vc-realtime-2026-01-15 |
Mainland China |
180 |
|
qwen3-tts-vc-realtime-2025-11-27 |
Mainland China |
Qwen3-TTS-Flash-Realtime
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-tts-flash-realtime |
Mainland China |
180 |
|
qwen3-tts-flash-realtime-2025-11-27 |
Mainland China |
180 |
|
qwen3-tts-flash-realtime-2025-09-18 |
Mainland China |
10 |
Qwen-TTS-Realtime
|
Model name |
Service deployment scope |
Rate limiting conditions (rate limiting is triggered when any value is exceeded) The following are per-minute rate limiting conditions. The service may also enforce RPS (RPM/60) and TPS (TPM/60) limits |
|
|
Requests per minute (RPM) |
Tokens consumed per minute (TPM) Including input and output tokens |
||
|
qwen-tts-realtime |
Mainland China |
10 |
100,000 |
|
qwen-tts-realtime-latest |
Mainland China |
||
|
qwen-tts-realtime-2025-07-15 |
Mainland China |
||
Qwen voice cloning
Singapore
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen-voice-enrollment |
International |
180 |
China (Beijing)
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen-voice-enrollment |
Mainland China |
180 |
Qwen voice design
Singapore
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen-voice-design |
International |
180 |
China (Beijing)
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen-voice-design |
Mainland China |
180 |
CosyVoice speech synthesis
Singapore
|
Model name |
Service deployment scope |
Job submission API RPS limit |
|
cosyvoice-v3-plus |
International |
3 |
|
cosyvoice-v3-flash |
International |
China (Beijing)
|
Model name |
Service deployment scope |
Job submission API RPS limit |
|
cosyvoice-v3.5-plus |
Mainland China |
3 |
|
cosyvoice-v3.5-flash |
Mainland China |
|
|
cosyvoice-v3-plus |
Mainland China |
|
|
cosyvoice-v3-flash |
Mainland China |
|
|
cosyvoice-v2 |
Mainland China |
CosyVoice voice cloning/design
CosyVoice voice cloning models share a single model and a shared rate limit quota.
Singapore
|
Model name |
Service deployment scope |
Job submission API RPS limit |
|
voice-enrollment |
International |
10 |
China (Beijing)
|
Model name |
Service deployment scope |
Job submission API RPS limit |
|
voice-enrollment |
Mainland China |
10 |
Speech recognition (speech-to-text) and translation (speech to text in a specified language)
Qwen3-LiveTranslate-Flash
Singapore
|
Model name |
Service deployment scope |
Rate limiting conditions (rate limiting is triggered when any value is exceeded) The following are per-minute rate limiting conditions. The service may also enforce RPS (RPM/60) and TPS (TPM/60) limits |
|
|
Requests per minute (RPM) |
Tokens consumed per minute (TPM) Including input and output tokens |
||
|
qwen3-livetranslate-flash |
International |
100 |
100,000 |
|
qwen3-livetranslate-flash-2025-12-01 |
International |
6,000 |
1,000,000 |
China (Beijing)
|
Model name |
Service deployment scope |
Rate limiting conditions (rate limiting is triggered when any value is exceeded) The following are per-minute rate limiting conditions. The service may also enforce RPS (RPM/60) and TPS (TPM/60) limits |
|
|
Requests per minute (RPM) |
Tokens consumed per minute (TPM) Including input and output tokens |
||
|
qwen3-livetranslate-flash |
Mainland China |
100 |
100,000 |
|
qwen3-livetranslate-flash-2025-12-01 |
Mainland China |
||
Qwen-LiveTranslate-Flash-Realtime
Singapore
|
Model name |
Service deployment scope |
Rate limiting conditions (rate limiting is triggered when any value is exceeded) The following are per-minute rate limiting conditions. The service may also enforce RPS (RPM/60) and TPS (TPM/60) limits |
|
|
Requests per minute (RPM) |
Tokens consumed per minute (TPM) Including input and output tokens |
||
|
qwen3.5-livetranslate-flash-realtime |
International |
10 |
100,000 |
|
qwen3.5-livetranslate-flash-realtime-2026-05-19 |
International |
||
|
qwen3-livetranslate-flash-realtime |
International |
||
|
qwen3-livetranslate-flash-realtime-2025-09-22 |
International |
||
China (Beijing)
|
Model name |
Service deployment scope |
Rate limiting conditions (rate limiting is triggered when any value is exceeded) The following are per-minute rate limiting conditions. The service may also enforce RPS (RPM/60) and TPS (TPM/60) limits |
|
|
Requests per minute (RPM) |
Tokens consumed per minute (TPM) Including input and output tokens |
||
|
qwen3.5-livetranslate-flash-realtime |
Mainland China |
10 |
100,000 |
|
qwen3.5-livetranslate-flash-realtime-2026-05-19 |
Mainland China |
||
|
qwen3-livetranslate-flash-realtime |
Mainland China |
||
|
qwen3-livetranslate-flash-realtime-2025-09-22 |
Mainland China |
||
Qwen audio file recognition
Singapore
Qwen3-ASR-Flash-Filetrans
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-asr-flash-filetrans |
International |
100 |
|
qwen3-asr-flash-filetrans-2025-11-17 |
International |
Qwen3-ASR-Flash
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-asr-flash |
International |
100 |
|
qwen3-asr-flash-2026-02-10 |
International |
|
|
qwen3-asr-flash-2025-09-08 |
International |
US (Virginia)
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-asr-flash-us |
US |
100 |
|
qwen3-asr-flash-2025-09-08-us |
US |
China (Beijing)
Qwen3-ASR-Flash-Filetrans
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-asr-flash-filetrans |
Mainland China |
100 |
|
qwen3-asr-flash-filetrans-2025-11-17 |
Mainland China |
Qwen3-ASR-Flash
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
qwen3-asr-flash |
Mainland China |
100 |
|
qwen3-asr-flash-2026-02-10 |
Mainland China |
|
|
qwen3-asr-flash-2025-09-08 |
Mainland China |
Qwen real-time speech recognition
Singapore
|
Model name |
Service deployment scope |
Requests per second (RPS) |
|
qwen3-asr-flash-realtime |
International |
20 |
|
qwen3-asr-flash-realtime-2026-02-10 |
International |
|
|
qwen3-asr-flash-realtime-2025-10-27 |
International |
China (Beijing)
|
Model name |
Service deployment scope |
Requests per second (RPS) |
|
qwen3-asr-flash-realtime |
Mainland China |
20 |
|
qwen3-asr-flash-realtime-2026-02-10 |
Mainland China |
|
|
qwen3-asr-flash-realtime-2025-10-27 |
Mainland China |
ParaformerSpeech recognition
China (Beijing)
|
Model name |
Service deployment scope |
Job submission API RPS limit |
|
paraformer-realtime-v2 |
Mainland China |
20 |
|
paraformer-realtime-8k-v2 |
Mainland China |
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
paraformer-v2 |
Mainland China |
1,200 |
|
Model name |
Service deployment scope |
Job submission API RPS limit |
Number of tasks being processed simultaneously (concurrency) |
|
paraformer-8k-v2 |
Mainland China |
20 |
100 |
Fun-ASR Audio file recognition
Singapore
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
fun-asr |
International |
600 |
|
fun-asr-2025-11-07 |
International |
600 |
|
fun-asr-2025-08-25 |
International |
600 |
|
fun-asr-mtl |
International |
100 |
|
fun-asr-mtl-2025-08-25 |
International |
100 |
|
fun-asr-flash-2026-06-15 |
International |
600 |
China (Beijing)
|
Model name |
Service deployment scope |
Requests per minute (RPM) |
|
fun-asr |
Mainland China |
600 |
|
fun-asr-2025-11-07 |
Mainland China |
|
|
fun-asr-2025-08-25 |
Mainland China |
|
|
fun-asr-mtl |
Mainland China |
|
|
fun-asr-mtl-2025-08-25 |
Mainland China |
|
|
fun-asr-flash-2026-06-15 |
Mainland China |
Fun-ASR Real-time speech recognition
Singapore
|
Model name |
Service deployment scope |
Job submission API RPS limit |
|
fun-asr-realtime |
International |
20 |
|
fun-asr-realtime-2025-11-07 |
International |
China (Beijing)
|
Model name |
Service deployment scope |
Job submission API RPS limit |
|
fun-asr-realtime |
Mainland China |
20 |
|
fun-asr-realtime-2026-02-28 |
Mainland China |
|
|
fun-asr-realtime-2025-11-07 |
Mainland China |
|
|
fun-asr-realtime-2025-09-15 |
Mainland China |
|
|
fun-asr-flash-8k-realtime |
Mainland China |
|
|
fun-asr-flash-8k-realtime-2026-01-28 |
Mainland China |
Text embedding
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM)/Number of jobs Includes input and output tokens. | ||
text-embedding-v4 | International | 1,800 | 1,000,000 |
text-embedding-v3 | International | 6,000 | 24,000,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) | |
Requests per second (RPS) | Tokens per minute (TPM)/Number of jobs Includes input and output tokens. | ||
text-embedding-v4 Rate limiting does not apply to service calls made using the Batch API. | The Chinese mainland | 30 | 1,200,000 |
Hong Kong (China)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM)/Number of jobs Includes input and output tokens. | ||
text-embedding-v4 | Hong Kong (China) | 1,800 | 1,000,000 |
Multimodal embedding
Singapore
Model name | Service deployment scope | Rate limiting conditions The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Input tokens only. | ||
tongyi-embedding-vision-plus | International | 600 | 200,000 |
tongyi-embedding-vision-flash | International | 600 | 200,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Input tokens only. | ||
qwen3-vl-embedding | The Chinese mainland | 2,400 | 1,200,000 |
multimodal-embedding-v1 | The Chinese mainland | 120 | 100,000 |
Sorting model
Singapore
Model name | Service deployment scope | Rate limiting conditions The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Input tokens only. | ||
qwen3-rerank | International | 5,400 | 5,000,000,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Input tokens only. | ||
qwen3-vl-rerank | The Chinese mainland | 600 | 9,000,000 |
gte-rerank-v2 | The Chinese mainland | 5,040 | 4,980,000,000 |
Industry
Intention recognition
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
tongyi-intent-detect-v3 | The Chinese mainland | 1,200 | 1,000,000 |
Role assumption
Singapore
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-plus-character | International | 120 | 500,000 |
qwen-flash-character | International | 120 | 500,000 |
qwen-plus-character-ja | International | 120 | 500,000 |
China (Beijing)
Model name | Service deployment scope | Rate limiting conditions (triggered if any value is exceeded) The following limits are per minute. The service may also enforce limits based on requests per second (RPS = RPM/60) and tokens per second (TPS = TPM/60). | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
qwen-plus-character | The Chinese mainland | 120 | 500,000 |
qwen-flash-character | The Chinese mainland | 120 | 500,000 |
Offline models
For more information, see Model unpublishing policy.
Offline on January 30, 2026
Category | Model name | Rate limiting conditions (triggered if any value is exceeded) | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
Qwen-Plus | qwen-plus-2024-11-27 | 0 | 0 |
qwen-plus-2024-11-25 | |||
qwen-plus-2024-09-19 | |||
qwen-plus-2024-08-06 | |||
Qwen-Turbo | qwen-turbo-2024-09-19 | ||
Qwen-VL | qwen-vl-max-2024-10-30 | ||
qwen-vl-max-2024-08-09 | |||
qwen-vl-plus-2024-08-09 | |||
Offline on August 20, 2025
Category | Model name | Rate limiting conditions (triggered if any value is exceeded) | |
Requests per minute (RPM) | Tokens per minute (TPM) Includes input and output tokens. | ||
Text generation - Qwen | qwen2-72b-instruct | 0 | 0 |
qwen2-57b-a14b-instruct | |||
qwen2-7b-instruct | |||
qwen1.5-110b-chat | |||
qwen1.5-72b-chat | |||
qwen1.5-32b-chat | |||
qwen1.5-14b-chat | |||
qwen1.5-7b-chat | |||