To ensure fair use, Alibaba Cloud Model Studio applies basic rate limits. These limits are model-specific and linked to your Alibaba Cloud account. The limit is calculated based on the total calls to a model from all RAM users, workspaces, and API keys under your account. If you exceed the limit, API requests will fail. You must wait for the limit to reset before making another call.
Rules
Account-level limits: Rate limits apply at the Alibaba Cloud account level. They are calculated based on the total calls from all RAM users, workspaces, and API keys under the account.
Model-specific limits: Each model has an independent rate limit. See the tables below for details.
FAQ
Why is rate limiting triggered?
Check the error message:
Requests rate limit exceeded or You exceeded your current requests list: This error indicates that the call frequency limit was triggered.
Allocated quota exceeded or You exceeded your current quota: This error indicates that the token consumption limit was triggered.
Request rate increased too quickly: This error indicates that a sudden surge in call frequency triggered the system's stability protection, even if the Requests Per Minute (RPM) or Tokens Per Minute (TPM) limits were not reached.
For other errors, see Error messages to identify the cause.
Note: In addition to RPM and TPM, rate limits may also be enforced at the per-second level. These limits are Requests per Second (RPS), calculated as RPM/60, and Requests per Second (RPS), calculated as TPM/60. A burst of requests in a short period can trigger rate limiting, even if the total number of calls is below the per-minute limit.
How to view model call usage?
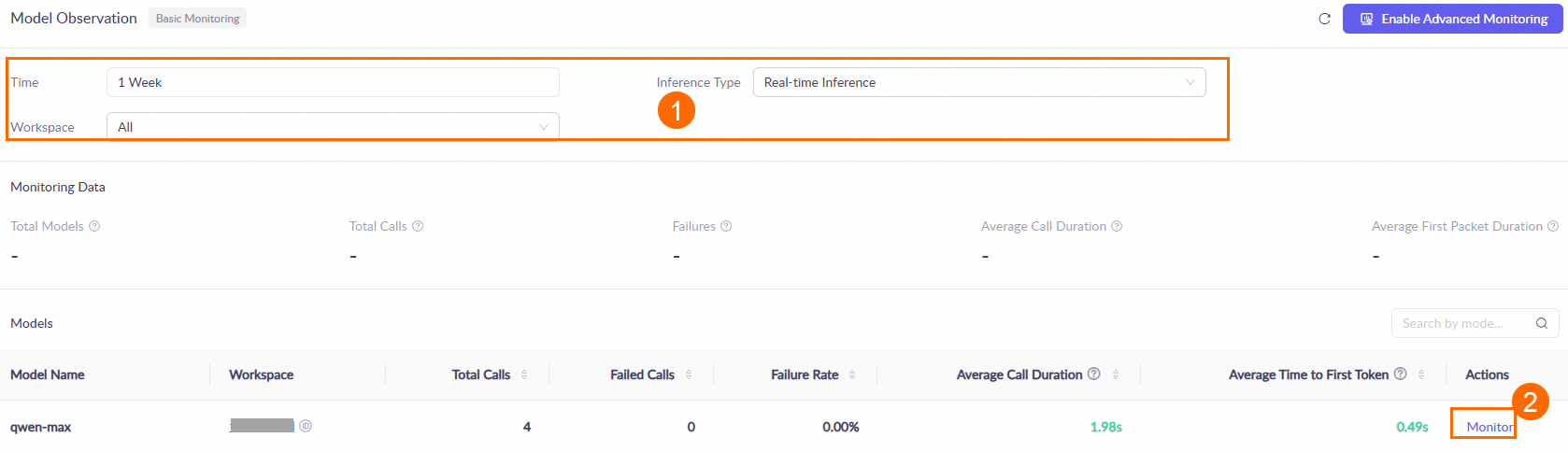
One hour after you call a model, go to the Monitoring (Singapore or Beijing) page. Set the query conditions, such as the time range and workspace. Then, in the Models area, find the target model and click Monitor in the Actions column to view the model's call statistics. For more information, see the Monitoring document.
Data is updated hourly. During peak periods, there may be an hour-level latency.
How long does it take to recover after a rate limit is triggered?
The limit typically resets within one minute. If other errors occur, see Error messages for solutions.
How to avoid rate limiting?
Choose a model with a higher rate limit: Stable or latest versions have higher rate limits than older snapshot versions.
Optimize your calling strategy
Adjust the call frequency: If you receive a "Requests rate limit exceeded" or "You exceeded your current requests list" error, reduce the call frequency.
Reduce token consumption: If you receive an "Allocated quota exceeded" or "You exceeded your current quota" error, shorten the input or output length.
Smooth the request rate: If a sudden increase in call frequency triggers system stability protection, you may receive a "Request rate increased too quickly" error. In this case, optimize your client-side calling logic. You can adopt a request smoothing strategy, such as uniform scheduling, exponential backoff, or a request queue buffer. This strategy distributes requests evenly over the time window and avoids instantaneous peaks.
Add a backup model
If you encounter a rate limit error, switch to a backup model to continue generation. This improves concurrency and reduces the failure rate. The following code shows an example of retrying a request with
qwen-plus-2025-07-14after a rate limit is triggered forqwen-plus-2025-07-28.Split tasks: Processing long conversations or large documents can consume many tokens quickly. Split large batch tasks into smaller batches and submit them at different times.
Use batch inference: If you do not need real-time results, use batch inference (Batch API). It is not subject to real-time rate limits, but you must consider queuing and processing time.
Text generation - Qwen
Qwen language models
Global
In the Global deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are dynamically scheduled worldwide.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-max | 600 | 1,000,000 |
qwen3-max-2025-09-23 | 60 | 100,000 |
qwen3-max-preview | 600 | 1,000,000 |
qwen-plus | 15,000 | 5,000,000 |
qwen-plus-2025-12-01 | 60 | 1,000,000 |
qwen-plus-2025-09-11 | ||
qwen-plus-2025-07-28 | ||
qwen-flash | 15,000 | 10,000,000 |
qwen-flash-2025-07-28 | 60 | 1,000,000 |
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-max | 600 | 1,000,000 |
qwen3-max-2026-01-23 | ||
qwen3-max-2025-09-23 | 60 | 100,000 |
qwen3-max-preview | 600 | 1,000,000 |
qwen-max | 600 | 1,000,000 |
qwen-max-latest | 60 | 100,000 |
qwen-max-2025-01-25 (qwen-max-0125) | ||
qwen-plus | 600 | 1,000,000 |
qwen-plus-latest | 60 | 100,000 |
qwen-plus-2025-12-01 | 1,000,000 | |
qwen-plus-2025-09-11 | 120 | |
qwen-plus-2025-07-28 | 60 | 100,000 |
qwen-plus-2025-07-14 (qwen-plus-0714) | ||
qwen-plus-2025-04-28 (qwen-plus-0428) | ||
qwen-plus-2025-01-25 (qwen-plus-0125) | ||
qwen-flash | 600 | 5,000,000 |
qwen-flash-2025-07-28 | 600 | 5,000,000 |
qwq-plus | 60 | 100,000 |
qwen-turbo | 600 | 5,000,000 |
qwen-turbo-latest | 60 | |
qwen-turbo-2025-04-28 (qwen-turbo-0428) | ||
qwen-turbo-2024-11-01 (qwen-turbo-1101) | ||
US
In the US deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are limited to the United States.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-plus-us | 600 | 1,000,000 |
qwen-plus-2025-12-01-us | 60 | |
qwen-flash-us | 600 | 5,000,000 |
qwen-flash-2025-07-28-us | ||
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-max | 30,000 | 5,000,000 |
qwen3-max-2026-01-23 | 600 | 1,000,000 |
qwen3-max-2025-09-23 | 60 | 100,000 |
qwen3-max-preview | 600 | 1,000,000 |
qwen-max | 1,200 | 1,000,000 |
qwen-max-latest | ||
qwen-max-2025-01-25 (qwen-max-0125) | 60 | 100,000 |
qwen-max-2024-09-19 (qwen-max-0919) | ||
qwen-plus | 30,000 | 5,000,000 |
qwen-plus-latest | 15,000 | 1,200,000 |
qwen-plus-2025-12-01 | 60 | 1,000,000 |
qwen-plus-2025-09-11 | ||
qwen-plus-2025-07-28 (qwen-plus-0728) | ||
qwen-plus-2025-07-14 (qwen-plus-0714) | 100,000 | |
qwen-plus-2025-04-28 (qwen-plus-0428) | 1,000,000 | |
qwen-plus-2025-01-25 (qwen-plus-0125) | 150,000 | |
qwen-plus-2025-01-12 (qwen-plus-0112) | ||
qwen-plus-2024-12-20 (qwen-plus-1220) | ||
qwen-flash | 30,000 | 10,000,000 |
qwen-flash-2025-07-28 | 60 | 1,000,000 |
qwq-plus | 600 | 1,000,000 |
qwq-plus-latest | ||
qwq-plus-2025-03-05 | 60 | 100,000 |
qwen-turbo | 1,200 | 5,000,000 |
qwen-turbo-latest | ||
qwen-turbo-2025-04-28 (qwen-turbo-0428) | 60 | 1,000,000 |
qwen-turbo-2025-02-11 (qwen-turbo-0211) | 5,000,000 | |
qwen-turbo-2024-11-01 (qwen-turbo-1101) | ||
qwen-long-latest | 1,200 | 60,000 |
qwen-long-2025-01-25 (qwen-long-0125) | 3 | 7,500 |
Qwen-VL (visual understanding/image-to-text)
Global
In the Global deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are dynamically scheduled worldwide.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-vl-plus | 1,200 | 1,000,000 |
qwen3-vl-plus-2025-09-23 | 60 | 100,000 |
qwen3-vl-flash | 1,200 | 1,000,000 |
qwen3-vl-flash-2025-10-15 | 60 | 100,000 |
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-vl-plus | 1,200 | 1,000,000 |
qwen3-vl-plus-2025-12-19 | 60 | 100,000 |
qwen3-vl-plus-2025-09-23 | ||
qwen3-vl-flash | 1,200 | 1,000,000 |
qwen3-vl-flash-2026-01-22 | 60 | 100,000 |
qwen3-vl-flash-2025-10-15 | 120 | 1,000,000 |
qwen-vl-max | 1,200 | 1,000,000 |
qwen-vl-max-latest | ||
qwen-vl-max-2025-08-13 (qwen-vl-max-0813) | 60 | 100,000 |
qwen-vl-max-2025-04-08 (qwen-vl-max-0408) | 1,200 | 1,000,000 |
qwen-vl-plus | ||
qwen-vl-plus-latest | ||
qwen-vl-plus-2025-08-15 (qwen-vl-plus-0815) | 120 | 1,000,000 |
qwen-vl-plus-2025-05-07 (qwen-vl-plus-0507) | ||
qwen-vl-plus-2025-01-25 (qwen-vl-plus-0125) | 1,200 | |
qvq-max | 60 | 100,000 |
qvq-max-latest | ||
qvq-max-2025-03-25 (qvq-max-0325) | ||
US
In the US deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are limited to the United States.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-vl-flash-us | 1,200 | 1,000,000 |
qwen3-vl-flash-2025-10-15-us | 120 | 1,000,000 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-vl-plus | 3,000 | 5,000,000 |
qwen3-vl-plus-2025-12-19 | 60 | 100,000 |
qwen3-vl-plus-2025-09-23 | ||
qwen3-vl-flash | 3,000 | 5,000,000 |
qwen3-vl-flash-2026-01-22 | 60 | 100,000 |
qwen3-vl-flash-2025-10-15 | ||
qwen-vl-max | 1,200 | 1,000,000 |
qwen-vl-max-latest | ||
qwen-vl-max-2025-08-13 (qwen-vl-max-0813) | 60 | 100,000 |
qwen-vl-max-2025-04-08 (qwen-vl-max-0408) | ||
qwen-vl-max-2025-04-02 (qwen-vl-max-0402) | ||
qwen-vl-max-2025-01-25 (qwen-vl-max-0125) | ||
qwen-vl-max-2024-12-30 (qwen-vl-max-1230) | ||
qwen-vl-max-2024-11-19 (qwen-vl-max-1119) | ||
qwen-vl-plus | 1,200 | 1,000,000 |
qwen-vl-plus-latest | ||
qwen-vl-plus-2025-08-15 (qwen-vl-plus-0815) | 60 | 100,000 |
qwen-vl-plus-2025-07-10 (qwen-vl-plus-0710) | ||
qwen-vl-plus-2025-05-07 (qwen-vl-plus-0507) | ||
qwen-vl-plus-2025-01-25 (qwen-vl-plus-0125) | ||
qwen-vl-plus-2025-01-02 (qwen-vl-plus-0102) | ||
qvq-max | ||
qvq-max-latest | ||
qvq-max-2025-05-15 (qvq-max-0515) | ||
qvq-max-2025-03-25 (qvq-max-0325) | ||
qvq-plus | ||
qvq-plus-latest | ||
qvq-plus-2025-05-15 (qvq-plus-0515) | ||
Qwen-Omni (omni-modal)
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-omni-flash | 60 | 100,000 |
qwen3-omni-flash-2025-12-01 | ||
qwen3-omni-flash-2025-09-15 | ||
qwen-omni-turbo | ||
qwen-omni-turbo-latest | ||
qwen-omni-turbo-2025-03-26 | ||
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-omni-flash | 60 | 100,000 |
qwen3-omni-flash-2025-12-01 | ||
qwen3-omni-flash-2025-09-15 | ||
qwen-omni-turbo | ||
qwen-omni-turbo-latest | ||
qwen-omni-turbo-2025-03-26 (qwen-omni-turbo-0326) | ||
qwen-omni-turbo-2025-01-19 (qwen-omni-turbo-0119) | ||
Qwen-Omni-Realtime (real-time multimodal)
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-omni-flash-realtime | 60 | 100,000 |
qwen3-omni-flash-realtime-2025-12-01 | ||
qwen3-omni-flash-realtime-2025-09-15 | ||
qwen-omni-turbo-realtime | ||
qwen-omni-turbo-realtime-latest | ||
qwen-omni-turbo-realtime-2025-05-08 | ||
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-omni-flash-realtime | 60 | 100,000 |
qwen3-omni-flash-realtime-2025-12-01 | ||
qwen3-omni-flash-realtime-2025-09-15 | ||
qwen-omni-turbo-realtime | ||
qwen-omni-turbo-realtime-latest | ||
qwen-omni-turbo-realtime-2025-05-08 | ||
Qwen-OCR (text extraction)
Global
In the Global deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are dynamically scheduled worldwide.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-vl-ocr | 600 | 6,000,000 |
qwen-vl-ocr-2025-11-20 | 1,200 | |
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-vl-ocr | 600 | 6,000,000 |
qwen-vl-ocr-2025-11-20 | 1,200 | |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-vl-ocr | 600 | 6,000,000 |
qwen-vl-ocr-latest | 1,200 | |
qwen-vl-ocr-2025-11-20 | ||
qwen-vl-ocr-2025-04-13 | 600 | |
qwen-vl-ocr-2024-10-28 | ||
Qwen-Math
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-math-plus | 1,200 | 1,000,000 |
qwen-math-plus-latest | ||
qwen-math-plus-2024-09-19 (qwen-math-plus-0919) | 60 | 100,000 |
qwen-math-plus-2024-08-16 (qwen-math-plus-0816) | 10 | 20,000 |
qwen-math-turbo | 1200 | 1,000,000 |
qwen-math-turbo-latest | ||
qwen-math-turbo-2024-09-19 (qwen-math-turbo-0919) | 60 | 100,000 |
Qwen-Coder
Global
In the Global deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are dynamically scheduled worldwide.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-coder-plus | 2,400 | 2,000,000 |
qwen3-coder-plus-2025-09-23 | 60 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | ||
qwen3-coder-flash | 1,200 | |
qwen3-coder-flash-2025-07-28 | 60 | |
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-coder-plus | 2,400 | 2,000,000 |
qwen3-coder-plus-2025-09-23 | 60 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | 60 | 1,000,000 |
qwen3-coder-flash | 600 | 5,000,000 |
qwen3-coder-flash-2025-07-28 | 600 | 5,000,000 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-coder-plus | 5,000 | 5,000,000 |
qwen3-coder-plus-2025-09-23 | 60 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | ||
qwen3-coder-flash | 5,000 | 5,000,000 |
qwen3-coder-flash-2025-07-28 | 60 | 1,000,000 |
qwen-coder-plus | 1,200 | |
qwen-coder-plus-latest | ||
qwen-coder-plus-2024-11-06 (qwen-coder-plus-1106) | 60 | 100,000 |
qwen-coder-turbo | 1,200 | 1,000,000 |
qwen-coder-turbo-latest | ||
qwen-coder-turbo-2024-09-19 (qwen-coder-turbo-0919) | 60 | 100,000 |
Qwen translation
Global
In the Global deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are dynamically scheduled worldwide.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-mt-plus | 60 | 25,000 |
qwen-mt-flash | 35,000 | |
qwen-mt-lite | 100,000 | |
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-mt-plus | 60 | 100,000 |
qwen-mt-flash | ||
qwen-mt-lite | ||
qwen-mt-turbo | ||
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-mt-plus | 60 | 25,000 |
qwen-mt-flash | 35,000 | |
qwen-mt-lite | 100,000 | |
qwen-mt-turbo | 35,000 | |
Qwen data mining
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-doc-turbo | 600 | 3,000,000 |
Qwen deep research
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-deep-research | 120 | 1,200,000 |
Text generation - Qwen - Open source
Open-source Qwen language models
Global
In the Global deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are dynamically scheduled worldwide.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-next-80b-a3b-thinking | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | ||
qwen3-235b-a22b-thinking-2507 | ||
qwen3-235b-a22b-instruct-2507 | ||
qwen3-30b-a3b-thinking-2507 | ||
qwen3-30b-a3b-instruct-2507 | ||
qwen3-235b-a22b | ||
qwen3-30b-a3b | ||
qwen3-32b | ||
qwen3-14b | ||
qwen3-8b | ||
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-next-80b-a3b-thinking | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | ||
qwen3-235b-a22b-thinking-2507 | ||
qwen3-235b-a22b-instruct-2507 | ||
qwen3-30b-a3b-thinking-2507 | ||
qwen3-30b-a3b-instruct-2507 | ||
qwen3-235b-a22b | ||
qwen3-32b | ||
qwen3-30b-a3b | ||
qwen3-14b | ||
qwen3-8b | ||
qwen3-4b | ||
qwen3-1.7b | ||
qwen3-0.6b | ||
qwen2.5-14b-instruct-1m | 60 | 1,000,000 |
qwen2.5-7b-instruct-1m | ||
qwen2.5-72b-instruct | 100,000 | |
qwen2.5-32b-instruct | ||
qwen2.5-14b-instruct | ||
qwen2.5-7b-instruct | ||
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-next-80b-a3b-thinking | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | ||
qwen3-235b-a22b-thinking-2507 | ||
qwen3-235b-a22b-instruct-2507 | ||
qwen3-30b-a3b-thinking-2507 | ||
qwen3-30b-a3b-instruct-2507 | ||
qwen3-235b-a22b | ||
qwen3-30b-a3b | ||
qwen3-32b | ||
qwen3-14b | ||
qwen3-8b | ||
qwen3-4b | ||
qwen3-1.7b | ||
qwen3-0.6b | ||
qwq-32b | ||
qwq-32b-preview | 1,200 | |
qwen2.5-72b-instruct | ||
qwen2.5-32b-instruct | ||
qwen2.5-14b-instruct | ||
qwen2.5-14b-instruct-1m | ||
qwen2.5-7b-instruct | ||
qwen2.5-7b-instruct-1m | ||
qwen2.5-3b-instruct | 2,000,000 | |
qwen2.5-1.5b-instruct | ||
qwen2.5-0.5b-instruct | ||
Qwen-VL (visual understanding/image-to-text)
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-vl-32b-thinking | 60 | 100,000 |
qwen3-vl-32b-instruct | ||
qwen3-vl-30b-a3b-thinking | ||
qwen3-vl-30b-a3b-instruct | ||
qwen3-vl-8b-thinking | ||
qwen3-vl-8b-instruct | ||
qwen3-vl-235b-a22b-thinking | ||
qwen3-vl-235b-a22b-instruct | ||
qwen2.5-vl-72b-instruct | ||
qwen2.5-vl-32b-instruct | ||
qwen2.5-vl-7b-instruct | ||
qwen2.5-vl-3b-instruct | ||
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-vl-32b-thinking | 600 | 1,000,000 |
qwen3-vl-32b-instruct | ||
qwen3-vl-30b-a3b-thinking | ||
qwen3-vl-30b-a3b-instruct | ||
qwen3-vl-8b-thinking | ||
qwen3-vl-8b-instruct | ||
qwen3-vl-235b-a22b-thinking | 60 | 100,000 |
qwen3-vl-235b-a22b-instruct | ||
qwen2.5-vl-72b-instruct | ||
qwen2.5-vl-32b-instruct | ||
qwen2.5-vl-7b-instruct | 1,200 | 1,000,000 |
qwen2.5-vl-3b-instruct | ||
qwen2-vl-72b-instruct | 60 | 100,000 |
qwen2-vl-7b-instruct | 1,200 | 1,000,000 |
qwen2-vl-2b-instruct | ||
qvq-72b-preview | 60 | 100,000 |
Qwen-Omni
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen2.5-omni-7b | 60 | 100,000 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen2.5-omni-7b | 60 | 100,000 |
Qwen3-Omni-Captioner
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-omni-30b-a3b-captioner | 60 | 100,000 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-omni-30b-a3b-captioner | 60 | 100,000 |
Qwen-Math
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen2.5-math-72b-instruct | 1,200 | 1,000,000 |
qwen2.5-math-7b-instruct | ||
qwen2.5-math-1.5b-instruct | ||
Qwen-Coder
Global
In the Global deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are dynamically scheduled worldwide.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-coder-480b-a35b-instruct | 600 | 1,000,000 |
qwen3-coder-30b-a3b-instruct | ||
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-coder-480b-a35b-instruct | 1,000,000 | 600 |
qwen3-coder-30b-a3b-instruct | ||
Mainland China
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-coder-480b-a35b-instruct | 600 | 1,000,000 |
qwen3-coder-30b-a3b-instruct | ||
qwen2.5-coder-32b-instruct | 1,200 | |
qwen2.5-coder-14b-instruct | ||
qwen2.5-coder-7b-instruct | ||
qwen2.5-coder-3b-instruct | 2,000,000 | |
qwen2.5-coder-1.5b-instruct | ||
qwen2.5-coder-0.5b-instruct | ||
Text generation - Third-party
DeepSeek
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
deepseek-v3.2 | 15,000 | 1,200,000 |
deepseek-v3.2-exp | 15,000 | 1,200,000 |
deepseek-v3.1 | 15,000 | 1,200,000 |
deepseek-r1-0528 | 60 | 100,000 |
deepseek-r1 | 15,000 | 1,200,000 |
deepseek-v3 | ||
deepseek-r1-distill-qwen-7b | ||
deepseek-r1-distill-qwen-14b | ||
deepseek-r1-distill-qwen-32b | ||
deepseek-r1-distill-qwen-1.5b | 60 | 100,000 |
deepseek-r1-distill-llama-8b | ||
deepseek-r1-distill-llama-70b | ||
Kimi
Supported only in Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
kimi-k2.5 | 60 | 100,000 |
kimi-k2-thinking | 60 | 100,000 |
Moonshot-Kimi-K2-Instruct | 60 | 100,000 |
GLM
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
glm-4.7 | 60 | 1,000,000 |
glm-4.6 | ||
Image generation
Qwen (Qwen-Image)
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Service | Model | Rate limit (triggered if any value is exceeded) | |
Task submission limit | Concurrent tasks | ||
Text-to-image | qwen-image-max | 2 per minute | No limit for sync API |
qwen-image-max-2025-12-30 | 2 per minute | No limit for sync API | |
qwen-image-plus | 2 per second | No limit for sync API / 2 for async API | |
qwen-image-plus-2026-01-09 | 2 per second | No limit for sync API | |
qwen-image | 2 per second | No limit for sync API / 2 for async API | |
Image editing | qwen-image-edit-max | 2 per minute | No limit for sync API |
qwen-image-edit-max-2026-01-16 | 2 per minute | No limit for sync API | |
qwen-image-edit-plus | 2 per second | No limit for sync API | |
qwen-image-edit-plus-2025-12-15 | 2 per second | No limit for sync API | |
qwen-image-edit-plus-2025-10-30 | 2 per second | No limit for sync API | |
qwen-image-edit | 2 per second | No limit for sync API | |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Service | Model | Rate limit (triggered if any value is exceeded) | |
Task submission limit | Concurrent tasks | ||
Text-to-image | qwen-image-max | 2 per minute | No limit for sync API |
qwen-image-max-2025-12-30 | 2 per minute | No limit for sync API | |
qwen-image-plus | 2 per second | No limit for sync API / 2 for async API | |
qwen-image-plus-2026-01-09 | 2 per second | No limit for sync API | |
qwen-image | 2 per second | No limit for sync API / 2 for async API | |
Image editing | qwen-image-edit-max | 2 per minute | No limit for sync API |
qwen-image-edit-max-2026-01-16 | 2 per minute | No limit for sync API | |
qwen-image-edit-plus | 2 per second | No limit for sync API | |
qwen-image-edit-plus-2025-12-15 | 2 per second | No limit for sync API | |
qwen-image-edit-plus-2025-10-30 | 2 per second | No limit for sync API | |
qwen-image-edit | 2 per second | No limit for sync API | |
Image translation | qwen-mt-image | 1 per second | 2 |
Tongyi - text-to-image - Z-Image
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) | |
Task submission RPS limit | Concurrent tasks | |
z-image-turbo | 2 | No limit for sync API |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) | |
Task submission RPS limit | Concurrent tasks | |
z-image-turbo | 2 | No limit for sync API |
Wan
Global
In the Global deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are dynamically scheduled worldwide.
Service | Model | Rate limit (triggered if any value is exceeded) | |
Task submission RPS limit | Concurrent tasks | ||
Text-to-image | wan2.6-t2i | 5 | 5 |
Image generation | wan2.6-image | 5 | 5 |
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Service | Model | Rate limit (triggered if any value is exceeded) | |
Task submission RPS limit | Concurrent tasks | ||
Text-to-image | wan2.6-t2i | 5 | 5 |
wan2.5-t2i-preview | |||
wan2.2-t2i-flash | 2 | 2 | |
wan2.2-t2i-plus | |||
wan2.1-t2i-turbo | |||
wan2.1-t2i-plus | |||
Image editing | wan2.5-i2i-preview | 5 | 5 |
Image generation | wan2.6-image | 5 | 5 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Service | Model | Rate limit (triggered if any value is exceeded) | |
Task submission RPS limit | Concurrent tasks | ||
Text-to-image | wan2.6-t2i | 1 | 5 |
wan2.5-t2i-preview | 5 | ||
wanx2.0-t2i-turbo | 2 | 2 | |
wanx2.1-t2i-turbo | |||
wanx2.1-t2i-plus | |||
wan2.2-t2i-flash | |||
wan2.2-t2i-plus | |||
General image editing | wan2.5-i2i-preview | 5 | 5 |
wanx2.1-imageedit | 2 | 2 | |
Image generation | wan2.6-image | 5 | 5 |
OutfitAnyone
Supported only in Mainland China.
Model | Rate limit (triggered if any value is exceeded) | |
Task submission RPS limit | Concurrent tasks | |
aitryon-plus | 10 | 5 |
aitryon-parsing-v1 | 10 | No limit for sync API |
Video generation
Wan series
Global
In the Global deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are dynamically scheduled worldwide.
Service | Model | Rate limit (triggered if any value is exceeded) | |
Task submission RPS limit | Concurrent tasks | ||
Text-to-image | wan2.6-t2v | 5 | 5 |
Image-to-video - first frame | wan2.6-i2v | ||
Referece-to-video | wan2.6-r2v | ||
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Service | Model | Rate limit (triggered if any value is exceeded) | |
Task submission RPS limit | Concurrent tasks | ||
Text-to-image | wan2.6-t2v | 5 | 5 |
wan2.5-t2v-preview | |||
wan2.2-t2v-plus | 2 | 2 | |
wan2.1-t2v-turbo | |||
wan2.1-t2v-plus | |||
Image-to-video - first frame | wan2.6-i2v-flash | 5 | 5 |
wan2.6-i2v | |||
wan2.5-i2v-preview | |||
wan2.2-i2v-flash | 2 | 2 | |
wan2.1-i2v-plus | |||
wan2.1-i2v-turbo | |||
wan2.2-i2v-plus | |||
Image-to-video - first and last frames | wan2.2-kf2v-flash | ||
wan2.1-kf2v-plus | |||
General video editing | wan2.1-vace-plus | ||
Referece-to-video | wan2.6-r2v-flash | 5 | 5 |
wan2.6-r2v | 5 | 5 | |
Animate image | wan2.2-animate-move | 5 | 1 |
Video character swap | wan2.2-animate-mix | 5 | 1 |
US
In the US deployment mode, the endpoint and data storage are located in the US (Virginia) region. Inference computing resources are limited to the United States.
Service | Model | Rate limit (triggered if any value is exceeded) | |
Task submission RPS limit | Concurrent tasks | ||
Text-to-image | wan2.6-t2v-us | 5 | 5 |
Image-to-video - first frame | wan2.6-i2v-us | ||
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Service | Model | Rate limit (triggered if any value is exceeded) | |
Task submission RPS limit | Concurrent tasks | ||
Text-to-image | wan2.6-t2v | 5 | 5 |
wan2.5-t2v-preview | |||
wan2.2-t2v-plus | 2 | 2 | |
wanx2.1-t2v-turbo | |||
wanx2.1-t2v-plus | |||
Image-to-video - first frame | wan2.6-i2v-flash | 5 | 5 |
wan2.6-i2v | |||
wan2.5-i2v-preview | |||
wan2.2-i2v-plus | 2 | 2 | |
wanx2.1-i2v-turbo | |||
wanx2.1-i2v-plus | |||
Image-to-video - first and last frames | wan2.2-kf2v-flash | ||
wanx2.1-kf2v-plus | |||
General video editing | wanx2.1-vace-plus | ||
Referece-to-video | wan2.6-r2v-flash | 5 | 5 |
wan2.6-r2v | 5 | 5 | |
Digital human | wan2.2-s2v-detect | 5 | No limit for sync API |
wan2.2-s2v | 1 | ||
Animate image | wan2.2-animate-move | 5 | 1 |
Video character swap | wan2.2-animate-mix | 5 | 1 |
AnimateAnyone
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Task submission RPS limit | Concurrent tasks |
animate-anyone-detect-gen2 | 5 | No limit for sync API |
animate-anyone-template-gen2 | 1 At any given time, only one task is running. Other tasks in the queue are in a pending state. | |
animate-anyone-gen2 |
EMO
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Task submission RPS limit | Concurrent tasks |
emo-detect-v1 | 5 | No limit for sync API |
emo-v1 | 1 At any given time, only one task is running. Other tasks in the queue are in a pending state. |
LivePortrait
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Task submission RPS limit | Concurrent tasks |
liveportrait-detect | 5 | No limit for sync API |
liveportrait | 1 At any given time, only one task is running. Other tasks in the queue are in a pending state. |
VideoRetalk
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Task submission RPS limit | Concurrent tasks |
videoretalk | 1 | 1 At any given time, only one task is running. Other tasks in the queue are in a pending state. |
Emoji
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Task submission RPS limit | Concurrent tasks |
emoji-detect-v1 | 1 | No limit for sync API |
emoji-v1 | 1 At any given time, only one task is running. Other tasks in the queue are in a pending state. |
Video style transform
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Task submission RPS limit | Concurrent tasks |
video-style-transform | 2 | 1 At any given time, only one task is running. Other tasks in the queue are in a pending state. |
Speech synthesis (text-to-speech)
Qwen speech synthesis
International
In the international deployment mode, the endpoint and data storage are both located in the Singapore region. The inference compute resources are dynamically scheduled worldwide (excluding Mainland China).
Model | RPM |
qwen3-tts-flash | 180 |
qwen3-tts-flash-2025-11-27 | 180 |
qwen3-tts-flash-2025-09-18 | 10 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are both located in the Beijing region. The inference compute resources are limited to Mainland China.
Qwen3-TTS-Flash
Model | RPM |
qwen3-tts-flash | 180 |
qwen3-tts-flash-2025-11-27 | 180 |
qwen3-tts-flash-2025-09-18 | 10 |
Qwen-TTS
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-tts | 10 | 100,000 |
qwen-tts-latest | ||
qwen-tts-2025-05-22 | ||
qwen-tts-2025-04-10 | ||
Qwen real-time speech synthesis
International
In the international deployment mode, the endpoint and data storage are both located in the Singapore region. The inference compute resources are dynamically scheduled worldwide (excluding Mainland China).
Qwen3-TTS-VD-Realtime
Model | RPM |
qwen3-tts-vd-realtime-2025-12-16 | 180 |
Qwen3-TTS-VC-Realtime
Model | RPM |
qwen3-tts-vc-realtime-2025-11-27 | 180 |
Qwen3-TTS-Flash-Realtime
Model | RPM |
qwen3-tts-flash-realtime | 180 |
qwen3-tts-flash-realtime-2025-11-27 | 180 |
qwen3-tts-flash-realtime-2025-09-18 | 10 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are both located in the Beijing region. The inference compute resources are limited to Mainland China.
Qwen3-TTS-VD-Realtime
Model | RPM |
qwen3-tts-vd-realtime-2025-12-16 | 180 |
Qwen3-TTS-VC-Realtime
Model | RPM |
qwen3-tts-vc-realtime-2025-11-27 | 180 |
Qwen3-TTS-Flash-Realtime
Model | RPM |
qwen3-tts-flash-realtime | 180 |
qwen3-tts-flash-realtime-2025-11-27 | 180 |
qwen3-tts-flash-realtime-2025-09-18 | 10 |
Qwen-TTS-Realtime
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-tts-realtime | 10 | 100,000 |
qwen-tts-realtime-latest | ||
qwen-tts-realtime-2025-07-15 | ||
Qwen voice cloning
International
In the international deployment mode, the endpoint and data storage are both located in the Singapore region. The inference compute resources are dynamically scheduled worldwide (excluding Mainland China).
Model | RPM |
qwen-voice-enrollment | 180 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are both located in the Beijing region. The inference compute resources are limited to Mainland China.
Model | RPM |
qwen-voice-enrollment | 180 |
Qwen voice design
International
In the international deployment mode, the endpoint and data storage are both located in the Singapore region. The inference compute resources are dynamically scheduled worldwide (excluding Mainland China).
Model | RPM |
qwen-voice-design | 180 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are both located in the Beijing region. The inference compute resources are limited to Mainland China.
Model | RPM |
qwen-voice-design | 180 |
CosyVoice speech synthesis
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Speech synthesis
Model | Task submission RPS limit |
cosyvoice-v3-plus | 3 |
cosyvoice-v3-flash | |
cosyvoice-v2 |
Voice cloning
Model | Task submission RPS limit |
cosyvoice-v3-plus | 10 The total concurrent request limit for the voice cloning feature is 10 RPS. This limit applies whether you call a single model version or multiple model versions at the same time. This means:
|
cosyvoice-v3-flash | |
cosyvoice-v2 |
Speech recognition (speech-to-text) and translation (speech-to-translation)
Qwen3-LiveTranslate-Flash
International
In the international deployment mode, the endpoint and data storage are both located in the Singapore region. The inference compute resources are dynamically scheduled worldwide (excluding Mainland China).
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-livetranslate-flash | 100 | 100,000 |
qwen3-livetranslate-flash-2025-12-01 | ||
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are both located in the Beijing region. The inference compute resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-livetranslate-flash | 100 | 100,000 |
qwen3-livetranslate-flash-2025-12-01 | ||
Qwen3-LiveTranslate-Flash-Realtime
International
In the international deployment mode, the endpoint and data storage are both located in the Singapore region. The inference compute resources are dynamically scheduled worldwide (excluding Mainland China).
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-livetranslate-flash-realtime | 10 | 100,000 |
qwen3-livetranslate-flash-realtime-2025-09-22 | ||
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are both located in the Beijing region. The inference compute resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen3-livetranslate-flash-realtime | 10 | 100,000 |
qwen3-livetranslate-flash-realtime-2025-09-22 | ||
Qwen audio file recognition
International
In the international deployment mode, the endpoint and data storage are both located in the Singapore region. The inference compute resources are dynamically scheduled worldwide (excluding Mainland China).
Qwen3-ASR-Flash-Filetrans
Model | RPM |
qwen3-asr-flash-filetrans | 100 |
qwen3-asr-flash-filetrans-2025-11-17 |
Qwen3-ASR-Flash
Model | RPM |
qwen3-asr-flash | 100 |
qwen3-asr-flash-2025-09-08 |
US
In the US deployment mode, the endpoint and data storage are both located in the US (Virginia) region. The inference compute resources are limited to the United States.
Model | RPM |
qwen3-asr-flash-us | 100 |
qwen3-asr-flash-2025-09-08-us |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are both located in the Beijing region. The inference compute resources are limited to Mainland China.
Qwen3-ASR-Flash-Filetrans
Model | RPM |
qwen3-asr-flash-filetrans | 100 |
qwen3-asr-flash-filetrans-2025-11-17 |
Qwen3-ASR-Flash
Model | Calls per Minute (RPM) |
qwen3-asr-flash | 100 |
qwen3-asr-flash-2025-09-08 |
Qwen real-time speech recognition
International
In the international deployment mode, the endpoint and data storage are both located in the Singapore region. The inference compute resources are dynamically scheduled worldwide (excluding Mainland China).
Model | RPS |
qwen3-asr-flash-realtime | 20 |
qwen3-asr-flash-realtime-2025-10-27 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are both located in the Beijing region. The inference compute resources are limited to Mainland China.
Model | RPS |
qwen3-asr-flash-realtime | 20 |
qwen3-asr-flash-realtime-2025-10-27 |
Paraformer speech recognition
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Task submission RPS limit |
paraformer-realtime-v2 | 20 |
paraformer-realtime-8k-v2 |
Model | Task submission RPS limit | Task query RPS limit |
paraformer-v2 | 20 | 20 |
paraformer-8k-v2 | 20 |
Fun-ASR audio file recognition
International
In the international deployment mode, the endpoint and data storage are both located in the Singapore region. The inference compute resources are dynamically scheduled worldwide (excluding Mainland China).
Model | Task submission RPS limit | Task query RPS limit |
fun-asr | 10 | 20 |
fun-asr-2025-11-07 | ||
fun-asr-2025-08-25 |
Model | Task submission RPM limit | Task query RPS limit |
fun-asr-mtl | 100 | 20 |
fun-asr-mtl-2025-08-25 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are both located in the Beijing region. The inference compute resources are limited to Mainland China.
Model | Task submission RPS limit | Task query RPS limit |
fun-asr | 10 | 20 |
fun-asr-2025-11-07 | ||
fun-asr-2025-08-25 | ||
fun-asr-mtl | ||
fun-asr-mtl-2025-08-25 |
Fun-ASR real-time speech recognition
International
In the international deployment mode, the endpoint and data storage are both located in the Singapore region. The inference compute resources are dynamically scheduled worldwide (excluding Mainland China).
Model | Task submission RPS limit |
fun-asr-realtime | 20 |
fun-asr-realtime-2025-11-07 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are both located in the Beijing region. The inference compute resources are limited to Mainland China.
Model | Task submission RPS limit |
fun-asr-realtime | 20 |
fun-asr-realtime-2025-11-07 | |
fun-asr-realtime-2025-09-15 |
Text embedding
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM/Number of tasks Includes input and output tokens | |
text-embedding-v4 | 1,800 | 1,000,000 |
text-embedding-v3 | 6,000 | 24,000,000 |
Mainland China
In the Mainland China deployment mode, the endpoint and data storage are located in the Beijing region. Inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) | |
RPS | TPM/Number of tasks Includes input and output tokens | |
text-embedding-v4 | 30 | 1,200,000 |
Multimodal embedding
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Rate limit The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM 仅输入Token | |
qwen3-vl-embedding | 1,200 | 600,000 |
multimodal-embedding-v1 | 120 | 200,000 |
Text rerank
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
gte-rerank-v2 | 5,040 | 4,980,000,000 |
Domain specific
Intent recognition
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
tongyi-intent-detect-v3 | 1,200 | 1,000,000 |
Role playing
International
In the International deployment mode, the endpoint and data storage are located in the Singapore region. Inference computing resources are dynamically scheduled worldwide, excluding Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-plus-character | 120 | 500,000 |
qwen-flash-character | ||
qwen-plus-character-ja | ||
Mainland China
Only the Mainland China deployment mode is supported. In this mode, the endpoint and data storage are located in the Beijing region, and inference computing resources are limited to Mainland China.
Model | Rate limit (triggered if any value is exceeded) The following are per-minute limits. The service may also enforce limits based on RPS (RPM/60) and TPS (TPM/60). | |
RPM | TPM Includes input and output tokens | |
qwen-plus-character | 120 | 500,000 |
Retired models
For more information, see Model unpublishing mechanism.
Retired on January 30, 2026
Category | Model | Rate limit (triggered if any value is exceeded) | |
RPM | TPM Includes input and output tokens | ||
Qwen-Plus | qwen-plus-2024-11-27 | 0 | 0 |
qwen-plus-2024-11-25 | |||
qwen-plus-2024-09-19 | |||
qwen-plus-2024-08-06 | |||
Qwen-Turbo | qwen-turbo-2024-09-19 | ||
Qwen-VL | qwen-vl-max-2024-10-30 | ||
qwen-vl-max-2024-08-09 | |||
qwen-vl-plus-2024-08-09 | |||
Retired on August 20, 2025
Category | Model | Rate limit (triggered if any value is exceeded) | |
RPM | TPM Includes input and output tokens | ||
Text generation - Qwen | qwen2-72b-instruct | 0 | 0 |
qwen2-57b-a14b-instruct | |||
qwen2-7b-instruct | |||
qwen1.5-110b-chat | |||
qwen1.5-72b-chat | |||
qwen1.5-32b-chat | |||
qwen1.5-14b-chat | |||
qwen1.5-7b-chat | |||